HBase海量数据存储
1.简介

HBase是一个基于HDFS的、分布式的、面向列的非关系型数据库。
HBase的特点
1.海量数据存储,HBase表中的数据能够容纳上百亿行*上百万列。
2.面向列的存储,数据在表中是按照列进行存储的,能够动态的增加列并对列进行各种操作。
3.准实时查询,HBase在海量的数据量下能够接近准实时的查询(百毫秒以内)
4.多版本,HBase中每一列的数据都可以有多个版本。
5.可靠性,HBase中的数据存储于HDFS中且依赖于Zookeeper进行Master和RegionServer的协调管理。
HBase与关系型数据库的区别
1.HBase中的数据类型只有String,而关系型数据库中有char、varchar、int等。
2.HBase中只有普通的增删改查操作,没有表与表之间的连接、子查询等,若想要在HBase中进行复杂的操作则应该使用Phoenix。
3.HBase是基于列进行存储的,因此在查询指定列的数据时效率会很高,而关系型数据库是基于行存储,每次查询都要查询整行。
4.HBase适合海量数据存储,而关系型数据库一般一张表不超过500M,否则就要考虑分表操作。
5.HBase中为空的列不占用存储空间,表的设计可以非常稀疏,而关系型数据库中表的设计较谨密。
6.HBase不支持事务,而非关系型数据库支持事务。
7.HBase区分大小写,而SQL不区分大小写。
2.HBase的表结构
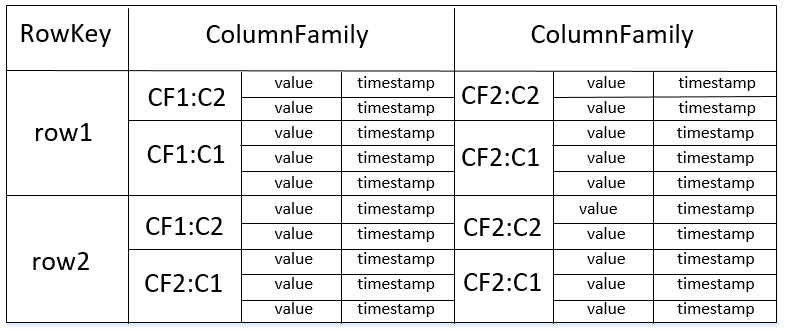
*HBase中的表由RowKey、ColumnFamily、Column、Timestamp组成。
RowKey
记录的唯一标识,相当于关系型数据库中的主键。
*RowKey最大长度为64KB且按字典顺序进行排序存储。
*HBase会自动为RowKey加上索引,当按RowKey查询时速度很快。
ColumnFamily
列簇相当于特定的一个类别,每个列簇下可以有任意数量个列,并且列是动态进行添加的,只在插入数据后存在,HBase在创建表时只需要指定表名和列簇即可。
*一个列簇下的成员有着相同的前缀,使用冒号来对列簇和列名进行分隔。
*一张表中的列簇最好不超过5个。
Column
列只有在插入数据后才存在,且列在列簇中是有序的。
*每个列簇下的列数没有限制。
Timestamp
HBase中的每个键值对都有一个时间戳,在进行插入时由HBase进行自动赋值。
3.HBase的物理模型

Master
1.处理对表的添加、删除、查询等操作。
2.进行RegionServer的负载均衡(Region与RegionServer的分配)
3.在RegionServer宕机后负责RegionServer上的Region转移(通过WAL日志)
*Master失效仅会导致meta数据和表无法被修改,表中的数据仍然可以进行读取和写入。
RegionServer
1.处理对表中数据的添加、删除、修改、查询等操作。
2.维护Region并将Region中StoreFile写入到HDFS中。
3.当Region中的数据达到一定大小时进行Region的切分。
Region
1.表中的数据存储在Region中,每个Region都由RegionServer进行管理。
2.每个Region都包含MemoryStore和StoreFile,MemoryStore中的数据位于内存,每当MemoryStore中的数据达到128M时将会生成一个StoreFile并写入到HDFS中。
3.Region中每个列簇对应一个MemoryStore,可以有多个StoreFile,当StoreFile的数量超过一定时,会进行StoreFile的合并,将多个StoreFile文件合并成一个StoreFile,当StoreFile文件的大小超过一定阀值时,会进行Region的切分,由Master将新Region分配到相应的RegionServer中,实现负载均衡。
Zookeeper在HBase中的作用
1.保证Master的高可用性,当状态为Active的Master无法提供服务时,会立刻将状态为StandBy的Master切换为Active状态。
2.实时监控RegionServer集群,当某个RegionServer节点无法提供服务时将会通知Master,由Master进行RegionServer上的Region转移以及重新进行负载均衡。
3.当HBase集群启动后,Master和RegionServer会分别向Zookeeper进行注册,会在Zookeeper中存放HBase的meta表数据,Region与RegionServer的关系、以及RegionServer的访问地址等信息。
*meta表中维护着TableName、RowKey和Region的关联关系。
HBase处理读取和写入请求的流程
HBase处理读取请求的过程
1.客户端连接Zookeeper,根据TableName和RowKey从Meta表中计算出该Row对应的Region。
2.获取该Region所关联的RegionServer,并获取RegionServer的访问地址。
3.访问RegionServer,找到对应的Region。
4.如果Region的MemoryStore中有该Row则直接进行获取,否则从StoreFile中进行查询。
HBase处理写入请求的过程
1.客户端连接Zookeeper,根据TableName找到其Region列表。
2.通过一定算法计算出要写入的Region。
3.获取该Region所关联的RegionServer并进行连接。
4.把数据分别写到HLog和MemoryStore中。
5.每当MemoryStore中的大小达到128M时,会生成一个StoreFile。
6.当StoreFile的数量超过一定时,会进行StoreFile的合并,将多个StoreFile文件合并成一个StoreFile,当StoreFile的文件大小超过一定阈值时,会进行Region的切分,由Master将新Region分配到相应的RegionServer中,实现负载均衡。
*在第一次读取或写入时才需要连接Zookeeper,会将Zookeeper中的相关数据缓存到本地,往后直接从本地进行读取,当Zookeeper中的信息发生变化时,再通过通知机制通知客户端进行更新。
HBase在HDFS中的目录
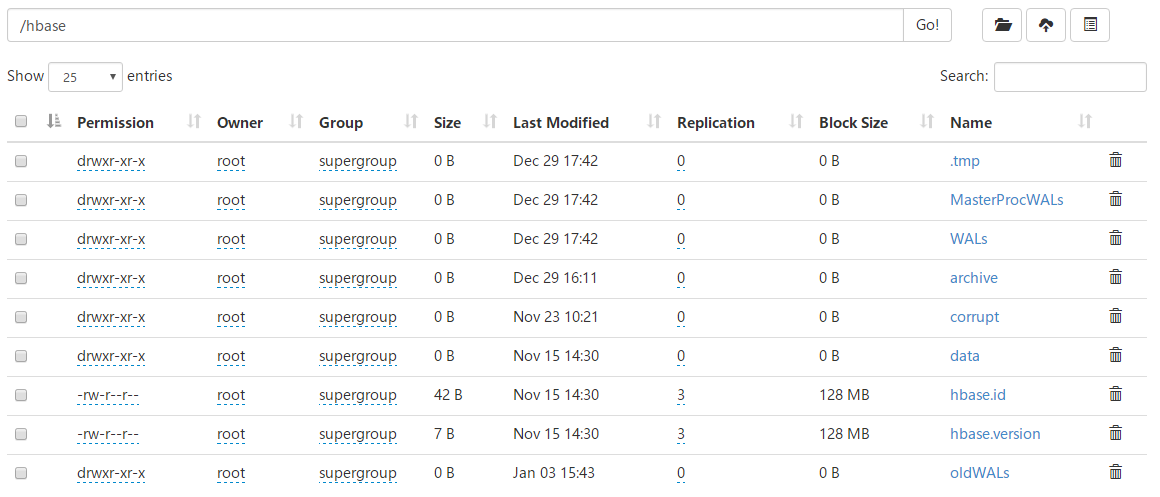
1.tmp目录:当对HBase的表进行创建和删除时,会将表移动到该目录中进行操作。
2.MasterProcWALs目录:预写日志目录,主要用于存储Master的操作日志。
3.WALs目录:预写日志目录,主要用于存储RegionServer的操作日志。
4.data目录:存储Region中的StoreFile。
5.hbase.id文件:HBase集群的唯一标识。
6.hbase.version文件:HBase集群的版本号。
7.oldWALs目录:当WALs目录下的日志文件超过一定时间后,会将其移动到oldWALs目录中,Master会定期进行清理。
4.HBase集群的搭建
1.安装JDK和Hadoop
由于HBase是通过JAVA语言编写的,且HBase是基于HDFS的,因此需要安装JDK和Hadoop,并配置好JAVA_HOME环境变量。


由于HDFS一般都以集群的方式运行,因此需要搭建HDFS集群。
*在搭建HDFS集群时,需要相互配置SSH使之互相信任并且开放防火墙相应的端口,或者直接关闭防火墙。
2.安装Zookeeper并进行集群的搭建
由于HDFS HA依赖于Zookeeper,且HBase也依赖于Zookeeper,因此需要安装Zookeeper并进行集群的搭建。



3.安装HBase
1.从CDH中下载HBase并进行解压:http://archive.cloudera.com/cdh5/cdh/5/
2.修改hbase-env.sh配置文件
#设置JDK的安装目录
export JAVA_HOME=/usr/jdk8/jdk1.8.0_161 #true则使用hbase自带的zk服务,false则使用外部的zk服务.
export HBASE_MANAGES_ZK=flase
3.修改hbase-site.xml配置文件
<!-- 指定HBase日志的存放目录 -->
<property>
<name>hbase.tmp.dir</name>
<value>/usr/hbase/hbase-1.2.8/logs</value>
</property>
<!-- 指定HBase中的数据存储在HDFS中的目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://nameservice:8020/hbase</value>
</property>
<!-- 设置是否是分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定HBase使用的ZK地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.1.80:2181,192.168.1.81:2181,192.168.1.82:2181</value>
</property>
4.修改regionservers文件,配置充当RegionServer的节点

*值可以是主机名或者IP地址
*如果Hadoop配置了HDFS HA高可用集群,那么就会有两个NameNode和一个NameService,此时就需要将HDFS的core-site.xml和hdfs-site.xml配置文件复制到HBase的conf目录下,且hbase-site.xml配置文件中的hbase.rootdir配置项的HDFS地址指向NameService的名称。
5.NTP时间同步
NTP是一个时间服务器,作用是使集群中的各个节点的时间都保持一致。
由于在HBase集群中,Zookeeper与HBase对时间的要求较高,如果两个节点之间的时间相差过大时,那么整个集群就会崩溃,因此需要使各个节点的时间都保持一致。
#查看是否安装了NTP服务
rpm -qa|grep ntp #安装NTP服务
yum install ntp -y #从NTP服务器中获取时间并同步本地
ntpdate 192.168.1.80
*在实际的应用场景中,可以自己搭建NTP服务器,也可以使用第三方开源的NTP服务器,如阿里等。
使用 “ntpdate NTP服务器地址” 命令从NTP服务器中获取时间并同步本地,一般配合Linux的crontab使用,每隔5分钟进行一次时间的同步。
4.启动集群
使用bin目录下的start-hbase.sh命令启动集群,那么会在当前节点中启动一个Master和RegionSever进程,并通过SSH访问其它节点,启动RegionServer进程。
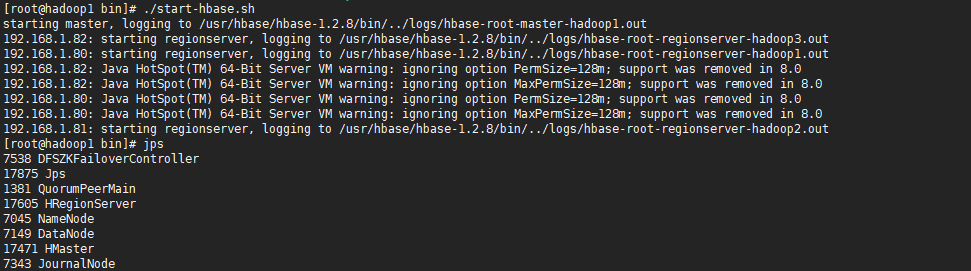


由于HBase的Master HA集群是通过Zookeeper进行协调的,需要手动在其他节点中启动Master,Zookeeper能保证当前HBase集群中有且只有一个Master处于Active状态,当状态为Active的Master无法正常提供服务时,会将处于StandBy的Master的状态修改为Active。
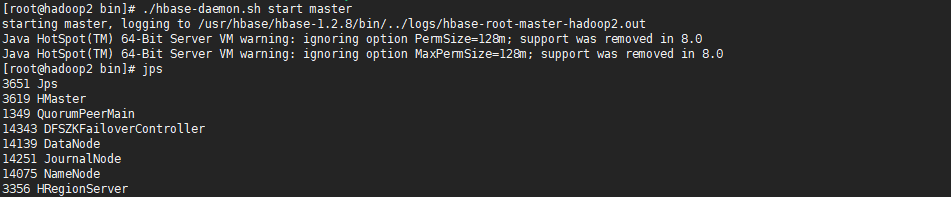
*当HBase集群启动后,可以访问http:/localhost:16030,进入HBase的Web监控页面。
5.使用Shell操作HBase
使用bin/hbase shell命令进行HBase的Shell操作
#创建表
create 'tableName' , 'columnFamily' , 'columnFamily...' #添加记录
put 'tableName' , 'rowkey' , 'columnFamily:column' , 'value' #查询记录
get 'tableName' , 'rowkey' #统计表的记录数
count 'tableName' #删除记录
deleteall 'tableName' , 'rowkey' #删除记录的某一列
delete 'tableName' , 'rowkey' ,'columnFamily:column' #禁用表
disable 'tableName' #启动表
enable 'tableName' #查看表是否被禁用
is_disabled 'tableName' #删除表
drop 'tableName' #查看表中的所有记录
scan 'tableName' #查看表中指定列的所有记录
scan 'tableName' , {COLUMNS=>'columnFamily:column'} #检查表是否存在
exists 'tableName' #查看当前HBase中的表
list
*在删除表时需要禁用表,否则无法删除。
*使用put相同rowkey的一条数据来进行记录的更新,仅会更新列相同的值。
6.使用JAVA操作HBase
1.导入相关依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.8</version>
</dependency>
2.初始化配置
使用HBaseConfiguration的create()静态方法创建一个Configuration实例,用于封装环境配置信息。
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","192.168.1.80,192.168.1.81,192.168.1.82");
config.set("hbase.zookeeper.property.clientPort","2181");
*此方法会默认加载classpath下的hbase-site.xml配置文件,如果没有此配置文件则需要手动进行环境的配置。
3.创建HBase连接对象
Connection conn = ConnectionFactory.createConnection(config);
4.进行表的管理
*使用Admin类进行HBase表的管理,通过Connection实例的getAdmin()静态方法返回一个Admin实例。
//判断表是否存在
boolean tableExists(TableName); //遍历HBase中的表定义
HTableDescriptor [] listTables(); //遍历HBase中的表名称
TableName [] listTableNames(); //根据表名获取表定义
HTableDescriptor getTableDescriptor(TableName); //创建表
void createTable(HTableDescriptor); //删除表
void deleteTable(TableName); //启用表
void enableTable(TableName); //禁用表
void disableTable(TableName); //判断表是否是启用状态
boolean isTableEnabled(TableName); //判断表是否是禁用状态
boolean isTableDisabled(TableName); //为表添加列簇
void addColumn(TableName,HColumnDescriptor); //删除表中的列簇
void deleteColumn(TableName,byte); //修改表中的列簇
void modifyColumn(TableName,HColumnDescriptor);
TableName实例用于封装表名称。
HTableDescriptor实例用于封装表定义,包括表的名称、表的列簇等。
HColumnDescriptor实例用于封装表的列簇。
5.对表中的数据进行增删改查
使用Table类进行表数据的增删改查,通过Connection的getTable(TableName)静态方法返回一个Table实例。
//判断指定RowKey的数据是否存在
boolean exists(Get get); //根据RowKey获取数据
Result get(Get get); //根据多个RowKey获取数据
Result [] get(List<Get>); //获取表的扫描器
ResultScanner getScanner(Scan); //添加数据
void put(Put); //批量添加数据
void put(List<Put>); //删除数据
void delete(Delete); //批量删除数据
void delete(List<Delete>)
使用Get实例封装查询参数,使用其构建方法设置RowKey。
使用Put实例封装新增和更新参数,使用其构建方法设置RowKey,使用其addColumn(byte[] family , byte[] qualifier , byte[] value)方法分别指定列簇、列名、列值。
使用Delete实例封装删除参数,使用其构建方法设置RowKey。
使用Scan实例封装扫描器的查询条件,使用其addFamily(byte[] family)方法设置扫描的列簇,使用其addColumn(byte[] family , byte[] qualifier)方法分别指定要扫描的列簇和列名。
*在进行表的增删改查时,方法参数大多都是字节数组类型,可以使用HBase Java提供的Bytes工具类进行字符串和字节数组之间的转换。
*在进行查询操作时,会返回Result实例,Result实例包含了一个RowKey的所有键值对(cell,不区分列簇),可以通过Result实例的listCells()方法获取其包含的所有cell,借助CellUtil工具类获取Cell实例中对应的RowKey、Family、Qualifier、Value等属性信息。
*在使用getScanner扫描时,返回的ResultScanner接口继承Iterable接口,其泛型是Result,因此可以理解成ResultScanner是Result的一个集合。
6.完整的HBaseUtil
/**
* @Auther: ZHUANGHAOTANG
* @Date: 2018/11/26 11:40
* @Description:
*/
public class HBaseUtils { private static final Logger logger = LoggerFactory.getLogger(HBaseUtils.class); /**
* ZK集群地址
*/
private static final String ZK_CLUSTER_HOSTS = "192.168.1.80,192.168.1.81,192.168.1.82"; /**
* ZK端口
*/
private static final String ZK_CLUSTER_PORT = "2181"; /**
* HBase全局连接
*/
private static Connection connection; static {
//默认加载classpath下hbase-site.xml文件
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", ZK_CLUSTER_HOSTS);
configuration.set("hbase.zookeeper.property.clientPort", ZK_CLUSTER_PORT);
try {
connection = ConnectionFactory.createConnection(configuration);
} catch (Exception e) {
logger.info("初始化HBase连接失败:", e);
}
} /**
* 返回连接
*/
public static Connection getConnection() {
return connection;
} /**
* 创建表
*/
public static void createTable(String tableName, String... families) throws Exception {
Admin admin = connection.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
throw new UnsupportedOperationException("tableName " + tableName + " is already exists");
}
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
for (String family : families)
descriptor.addFamily(new HColumnDescriptor(family));
admin.createTable(descriptor);
} /**
* 删除表
*/
public static void deleteTable(String tableName) throws Exception {
Admin admin = connection.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
}
} /**
* 获取所有表名称
*/
public static TableName[] getTableNameList() throws Exception {
Admin admin = connection.getAdmin();
return admin.listTableNames();
} /**
* 获取所有表定义
*/
public static HTableDescriptor[] getTableDescriptorList() throws Exception {
Admin admin = connection.getAdmin();
return admin.listTables();
} /**
* 为表添加列簇
*/
public static void addFamily(String tableName, String family) throws Exception {
Admin admin = connection.getAdmin();
if (!admin.tableExists(TableName.valueOf(tableName))) {
throw new UnsupportedOperationException("tableName " + tableName + " is not exists");
}
admin.addColumn(TableName.valueOf(tableName), new HColumnDescriptor(family));
} /**
* 删除表中指定的列簇
*/
public static void deleteFamily(String tableName, String family) throws Exception {
Admin admin = connection.getAdmin();
admin.deleteColumn(TableName.valueOf(tableName), Bytes.toBytes(family));
} /**
* 为表添加一条数据
*/
public static void put(String tableName, String rowKey, String family, Map<String, String> values) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
for (Map.Entry<String, String> entry : values.entrySet())
put.addColumn(Bytes.toBytes(family), Bytes.toBytes(entry.getKey()), Bytes.toBytes(entry.getValue()));
table.put(put);
} /**
* 批量为表添加数据
*/
public static void batchPut(String tableName, String family, Map<String, Map<String, String>> values) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Put> puts = new ArrayList<>();
for (Map.Entry<String, Map<String, String>> entry : values.entrySet()) {
Put put = new Put(Bytes.toBytes(entry.getKey()));
for (Map.Entry<String, String> subEntry : entry.getValue().entrySet())
put.addColumn(Bytes.toBytes(family), Bytes.toBytes(subEntry.getKey()), Bytes.toBytes(subEntry.getValue()));
puts.add(put);
}
table.put(puts);
} /**
* 删除RowKey中的某列
*/
public static void deleteColumn(String tableName, String rowKey, String family, String qualifier) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
table.delete(delete);
} /**
* 删除RowKey
*/
public static void delete(String tableName, String rowKey) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
table.delete(new Delete(Bytes.toBytes(rowKey)));
} /**
* 批量删除RowKey
*/
public static void batchDelete(String tableName, String... rowKeys) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Delete> deletes = new ArrayList<>();
for (String rowKey : rowKeys)
deletes.add(new Delete(Bytes.toBytes(rowKey)));
table.delete(deletes);
} /**
* 根据RowKey获取数据
*/
public static Map<String, String> get(String tableName, String rowKey) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
Result result = table.get(new Get(Bytes.toBytes(rowKey)));
List<Cell> cells = result.listCells();
Map<String, String> cellsMap = new HashMap<>();
for (Cell cell : cells) {
cellsMap.put(Bytes.toString(CellUtil.cloneQualifier(cell)), Bytes.toString(CellUtil.cloneValue(cell)));
}
return cellsMap;
} /**
* 获取全表数据
*/
public static Map<String, Map<String, String>> scan(String tableName) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
ResultScanner resultScanner = table.getScanner(new Scan());
return getResult(resultScanner);
} /**
* 获取某列数据
*/
public static Map<String, Map<String, String>> scan(String tableName, String family, String qualifier) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
ResultScanner resultScanner = table.getScanner(scan);
return getResult(resultScanner);
} private static Map<String, Map<String, String>> getResult(ResultScanner resultScanner) {
Map<String, Map<String, String>> resultMap = new HashMap<>();
for (Result result : resultScanner) {
List<Cell> cells = result.listCells();
Map<String, String> cellsMap = new HashMap<>();
for (Cell cell : cells)
cellsMap.put(Bytes.toString(CellUtil.cloneQualifier(cell)), Bytes.toString(CellUtil.cloneValue(cell)));
resultMap.put(Bytes.toString(result.getRow()), cellsMap);
}
return resultMap;
} }
HBase海量数据存储的更多相关文章
- 浅析MongoDB数据库的海量数据存储应用
[摘要]当今已进入大数据时代,特别是大规模互联网web2.0应用不断发展及云计算所需要的海量存储和海量计算发展,传统的关系型数据库已无法满足这方面的需求.随着NoSQL数据库的不断发展和成熟,可以较好 ...
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- HBase海量数据高效入仓解决方案
一.方案背景 现阶段部分业务数据存储在HBase中,这部分数据体量较大,达到数十亿.大数据需要增量同步这部分业务数据到数据仓库中,进行离线分析,目前主要的同步方式是通过HBase的hive映射表来实现 ...
- HBase 的存储结构
HBase 的存储结构 2016-10-17 杜亦舒 HBase 中的表常常是超级大表,这么大的表,在 HBase 中是如何存储的呢?HBase 会对表按行进行切分,划分为多个区域块儿,每个块儿名为 ...
- hbase的存储体系
一.了解hbase的存储体系. hbase的存储体系核心的有Split机制,Flush机制和Compact机制. 1.split机制 每一个hbase的table表在刚刚开始的时候,只有一个regio ...
- 海量数据存储之Key-Value存储简介
Key-value存储简介 具备高可靠性及可扩展性的海量数据存储对互联网公司来说是一个巨大的挑战,传统的数据库往往很难满足该需求,并且很多时候对于特定的系统绝大部分的检索都是基于主键的的查询,在这种情 ...
- Hbase的存储
Hbase在生态系统中的位置 Hbase存储的逻辑视图 Hbase的存储格式 Hbase写数据流程 Hbase快速响应数据 Hbase在生态系统中的位置 HBase位于结构化存储层,Hadoop HD ...
- HBase作为存储方案
HBase存储特点 * Client 1. 包含访问HBase的接口,并维护cache来加快对HBase的访问,比如region的位置信息. * Zookeeper: 1. 选举集群中的Master, ...
- HBase底层存储原理
HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已! 首先HBase不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数 ...
随机推荐
- WebSocket-java实践
websocket 主要用于 前端页面hmtl/jsp 与 后端进行socket得连接. 本例简单实现:一但后端接收到数据或者根据某些规则主动发送数据,那么可以根据不同用户等区别,发送给某个登陆得 ...
- SQLServer之创建Transact-SQL游标
什么是游标 结果集,结果集就是select查询之后返回的所有行数据的集合. 游标则是处理结果集的一种机制吧,它可以定位到结果集中的某一行,多数据进行读写,也可以移动游标定位到你所需要的行中进行操作数据 ...
- Linux(三)——Unix&Linux 的基础命令
Linux(三)--Unix&Linux 的基础命令 快捷键 Ctl-A 光标移动到行首 Ctl-C 终止命令 Ctl-D 注销登录 Ctl-E 光标移动到行尾 Ctl-U 删除光标到行首的所 ...
- jpa 解决org.hibernate.lazyinitializationexception could not initialize proxy - no session
org.hibernate.LazyInitializationException: could not initialize proxy [org.alan.entity.SysUser#1] - ...
- matlab导入txt数据画图
因为最近需要观察txt保存的一堆数据,则需要使用这些数据画图.强大的matlab分分钟解决了. 实例数据:data.txt 步骤: ①打开matlab -> HOME(主页) -> Imp ...
- DEDECMS 漏洞修复方案
目录 DEDECMS支付模块注入漏洞 漏洞文件: /include/payment/alipay.php 漏洞描述: 对输入参数$_GET['out_trade_no']未进行严格过滤 修复方案: 对 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- mybatis insertUseGeneratedKeys 返回主键为null
package tk.mybatis.mapper.common.special; import org.apache.ibatis.annotations.InsertProvider; impor ...
- js一些梳理
浏览器组成 1.Shell部分2.内核内核的组成 1.渲染引擎 负责页面显示 2.JS引擎 3. 其他模块主流内核介绍 >> * Trident(IE内核) >> * Geck ...
- flutter 监听返回键
### 监听手机返回键(双击退出) ``` import 'package:fluttertoast/fluttertoast.dart'; //提示插件 class WillPopScopeTest ...