学习笔记-ResNet网络
ResNet网络
- ResNet原理和实现
- 总结
一、ResNet原理和实现
神经网络第一次出现在1998年,当时用5层的全连接网络LetNet实现了手写数字识别,现在这个模型已经是神经网络界的“helloworld”,一些能够构建神经网络的库比如TensorFlow、keras等等会把这个模型当成第一个入门例程。后来卷积神经网络(Convolutional Neural Networks, CNN)一出现就秒杀了全连接神经网络,用卷积核代替全连接,大大降低了参数个数,网络因此也能延伸到十几层到二十几层,2012年的8层AlexNet获得ILSVRC 2012比赛冠军,2014年22层的GooLeNet获得ILSVRC 2014亚军,19层VGG获得亚军,但层数也只能到这了,因为研究者们发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。为什么?
这得从神经网络的传播算法开始说起。神经网络用反向传播算法通过计算参数的梯度,从而将总误差E分配到各个待调整的参数w上,以此来指导参数的更新。但如果层数过高(比如二十层),梯度变化值会逐渐衰减,以sigmoid函数为例,由于其求导结果等于f(x) *(1-f(x)),且其值域为(0,1),这意味着导数值小于等于0.25,而每经过一层神经元,都要再上一个偏导数的基础上乘以这个求导结果,因此每经过一层,误差就会衰减为原来的至少0.25倍,显然只需经过十几层二十几层,误差就会变的极小以至于趋近于0,这就是限制网络深度的问题之一:梯度消失。而在另一种极端情况下,每层计算出的梯度值即使乘以f(x) *(1-f(x))后仍然大于1,梯度值以指数级增加最终溢出,这是梯度爆炸。正是这两个问题导致梯度变得不稳定,网络难以训练了。
梯度消失和梯度爆炸都有一定的缓解方法,比如换成使用ReLU函数作为激活函数,或者是在每层输入之后添加正则化层。正则化可以使数据分布重新回到标准正态分布,在数学上解释为“防止输入分布变动”,一定程度上解决了梯度消失问题,也提高了训练速度和收敛速度,网络因此能训练到几十层。
但是即使用了正则化等手段,随着层数加深,但神经网络在训练集的准确度仍然会发生饱和甚至精度下降的问题。这个问题无法解释为过拟合,因为过拟合是在训练集上的准确率很高,在测试集上要低。而现在是神经网络在训练集上的准确率都下降了。研究者把这种现象称之为网络退化。
如何解决退化问题?Kaiming He等人做了实验:假设现有一个浅层网络已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(输入=输出的层),这样可以增加网络的深度,并且误差不应该增加。而实验结果不是这样,这说明现有的神经网络似乎很难学习恒等映射函数,也就是去拟合y=x。残差网络就是为了解决这个问题而诞生的:让神经网络具有学习恒等映射的能力。如果神经网络的某一层被训练为恒等映射层,那么这层是否存在对结果不会有影响。换句话说,如果神经网络能学习恒等映射,那么网络就具有了自行选择是否需要某层神经的能力。(思路上似乎与dropout层有一定的共性,只不过dropout层更笨一些:随机使得一定比例的神经元失效来减小过拟合效果。)
那么残差网络是如何实现学习恒等映射的能力呢?目标函数是H(x)=x,其中H(x)是神经网络。如果把目标函数设计为H(x)=F(x) + x,当F(x)=0时就能构成一个恒等映射。转换一下我们需要学F(x) = H(x) - x。按照论文中给出的图,具体的残差层可以这样设计:(这个图不够直观,下面我会画一个更直观的)
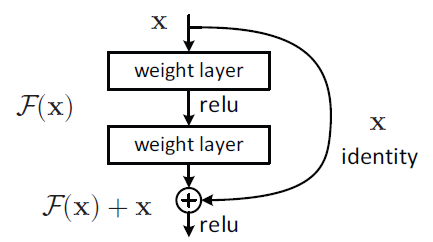
举个例子:输入 , 经过拟合后的输出为
,那么残差就是
;
假设 从
经过两层卷积层之后变为
,普通网络模块相比较于之前的输出,其变化率为
,而残差模块的变化率为
放大变化有助于网络更加敏感,学得更快。如何放大变化?减去基数x,只让网络学习在x上所叠加的波动,也就是残差。如果把残差层画的更清晰一点,应该是这样的: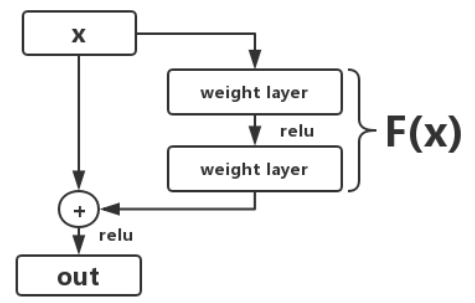
通过上图我们更容易理解,残差网络将要学习叠加在输入x上的波动信息,这也是残差网络为什么称之为残差网络:残差就是波动。将波动与输入x本身分割开来,这能使得残差网络更容易学习与输入本身无关的、更一般的特征。
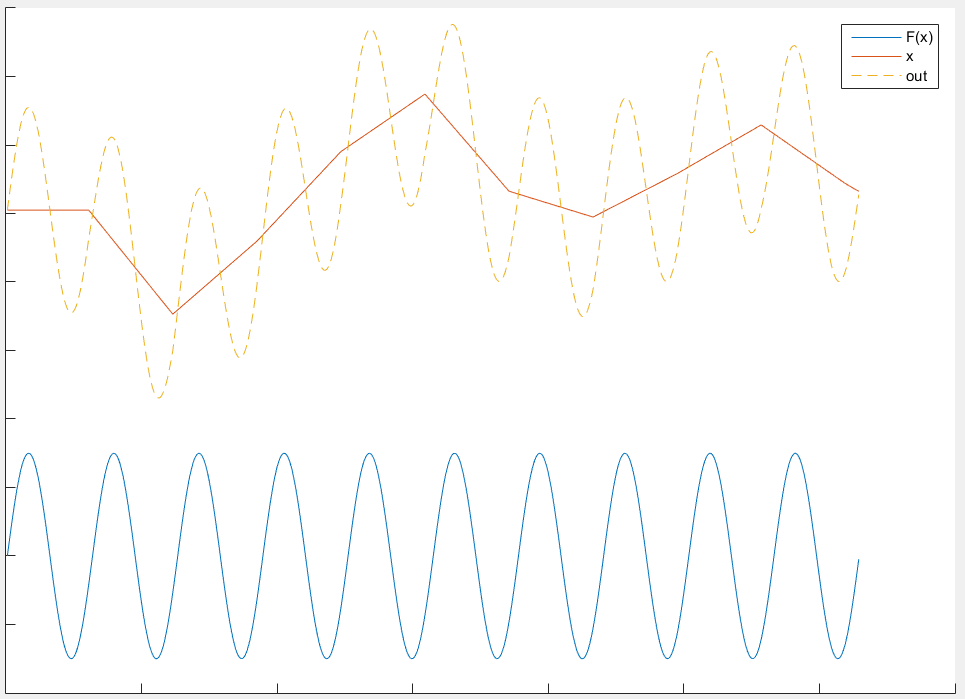
这个图更直观的表现为什么残差是“输入本身无关的、更一般的特征”。普通的网络只能直接学习橙色虚线(神经网络的输出结果),但如果在输出结果中减去输入x得到残差曲线(蓝色实线)后再学习,可以预见网络将更快的收敛,精度也会更高。
回忆前面所说的“学习恒等映射”,在残差网络结构中,这个问题就转换为“学习获得0输出”,神经网络更擅长拟合这类非线性问题。
这部分的实现体现在下面的代码中,其中考虑了一个细节问题:如果输入与输出的通道数相同,则将输入的x与输出结果进行相加作为下一层的输出;如果输入与输出的图像的通道数不同,那么输入将会经过一个分支层(conv->bn)转换其通道数,再与输出相加。
downsample = None
# 在前后通道数不一样的时候,对输入进行conv->bn来变换通道数,与输出相加,实现残差结构
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(nn.Conv2d(self.in_channels, out_channels,kernel_size=3, stride=stride, padding=1,bias=False),
nn.BatchNorm2d(out_channels))
def forward(self, input):
# input->conv1->bn1->relu->conv2->bn2=out->out+input->out
x = input
out = self.conv1(input)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# F(x)+ x 部分,当输入输出通道数一样,则直接与输入相加,不一样则经过conv->bn来变换通道数再相加。
if self.downsample:
x = self.downsample(input)
out = out + x # F(x)+ x
out = self.relu(out) # 经过relu
return out
为什么加x而不是x/2等其他形式?这个问题再何凯明大神的另一篇文章里提到了,如果x前有系数λ会导致梯度里多一项 ,反向传播的时候碰上极端情况(all λ>1)会导致梯度爆炸,而(all λ<1)会使得网络退化为普通网络,所以只能是1,更详细的解释和实验都在链接里。
,反向传播的时候碰上极端情况(all λ>1)会导致梯度爆炸,而(all λ<1)会使得网络退化为普通网络,所以只能是1,更详细的解释和实验都在链接里。
到这里,残差网络的学习就差不多了,我借用两个大神的代码实现了18层的残差网络,结构图如下:

最后附上全部代码(使用Pytorch框架,强烈推荐):
import torch # 1.0.1
import torch.nn as nn
import torchvision # 0.2.2
import torchvision.transforms as transforms # 图像预处理模块
transform = transforms.Compose([transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()]) # CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='./data',
train=True,
transform=transform,
download=True) test_dataset = torchvision.datasets.CIFAR10(root='./data',
train=False,
transform=transforms.ToTensor()) # Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=100,
shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=100,
shuffle=False) # 残差块 conv->BN->relu->conv->BN
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__() # 继承父类init()
# print("---------------残差块开始-------------------------")
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
# print("---------------残差块结束-------------------------") def forward(self, input):
# input->conv1->bn1->relu->conv2->bn2=out->out+input->out
x = input
out = self.conv1(input)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# F(x)+ x 部分,当输入输出通道数一样,则直接与输入相加,不一样则经过conv->bn来变换通道数再相加。
if self.downsample:
x = self.downsample(input)
out = out + x # F(x)+ x
out = self.relu(out) # 经过relu
return out # ResNet
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64 # 输入通道
self.conv = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn = nn.BatchNorm2d(64) # BN
self.relu = nn.ReLU(inplace=True) # relu self.layer1 = self.make_layer(block, 64, layers[0], 1)
self.layer2 = self.make_layer(block, 128, layers[1], 2)
self.layer3 = self.make_layer(block, 256, layers[2], 2)
self.layer4 = self.make_layer(block, 512, layers[3], 2)
self.avg_pool = nn.AvgPool2d(4) # 平均池化
self.fc = nn.Linear(512, num_classes) def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
# 在前后通道数不一样的时候,对输入进行conv->bn来变换通道数,与输出相加,实现残差结构
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(nn.Conv2d(self.in_channels, out_channels,
kernel_size=3, stride=stride, padding=1,bias=False),
nn.BatchNorm2d(out_channels))
layers = [] # 声明list
layers.append(block(self.in_channels, out_channels, stride, downsample)) # 构建残差模块
# print(self.in_channels, out_channels, stride)
self.in_channels = out_channels # 把输出通道设为输入通道
for i in range(1, blocks): # 只运行了一次 blocks=2
layers.append(block(out_channels, out_channels)) # 构建16输入 16输出的残差模块
return nn.Sequential(*layers) # 把网络层按序添加到模型 def forward(self, input):
out = self.conv(input)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
# print(out.shape)
out = self.layer3(out)
out = self.layer4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 设置GPU
torch.set_num_threads(8) # 设定用于并行化CPU操作的OpenMP线程数 windows环境下必须在main函数下运行,不然报错
# 0.定义参数
num_epochs = 1
learning_rate = 0.001 # 1.搭建网络
model = ResNet(ResidualBlock, [2, 2, 2, 2]).to(device) # 模型迁移到GPU运行
# # 查看每层参数
# for name, parameters in model.named_parameters():
# print(name, ':', parameters.size()) # # tensorboard 查看模型结构
# rand_input = torch.rand(100, 3, 32, 32)
# with SummaryWriter(comment="network") as w:
# w.add_graph(model,rand_input.to(device)) # 2.定义损失和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # adam优化 # 3.训练模型
total_step = len(train_loader) # 训练步长
curr_lr = learning_rate
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# print(images.shape)
# print(labels)
# exit()
outputs = model(images) # 前向传播
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 后向传播
optimizer.step() # 参数更新
if (i + 1) % 100 == 0:
print("Epoch [{}/{}], Step [{}/{}] Loss: {:.4f}"
.format(epoch + 1, num_epochs, i + 1, total_step, loss.item())) # 每20周期 学习率下降为原来的三分之一
if (epoch + 1) % 20 == 0:
curr_lr /= 3
for param_group in optimizer.param_groups:
param_group['lr'] = curr_lr # 4.测试模型
model.eval() # 测试模式
# eval()时,pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。
# 不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大。
with torch.no_grad(): # 无需计算梯度
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item() print('Accuracy of the model on the test images: {} %'.format(100 * correct / total)) # 5.保存模型及参数
torch.save(model.state_dict(), 'resnet.ckpt')
完整代码
代码里含有tensorboard的相关函数,用于网络结构的可视化,不需要可以注释掉。
二、总结
残差网络的设计简洁漂亮,把输出分解为输入+残差,将神经网络的学习重心全部转移到残差上,使得网络更专注的学习与输入无关的、更一般的特征。这就是残差网络的成功原因。
参考文献
梯度消失、爆炸 https://blog.csdn.net/u011734144/article/details/80164927
Batch Normalization 批标准化 https://www.cnblogs.com/guoyaohua/p/8724433.html
理解ResNet: https://www.cnblogs.com/alanma/p/6877166.html
https://blog.csdn.net/bryant_meng/article/details/81187434
https://blog.csdn.net/sunqiande88/article/details/80100891
使用TensorFlow、keras、theano、pytorch框架搭建神经网络:莫烦老师的神经网络教程
学习笔记-ResNet网络的更多相关文章
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- tensorflow学习笔记——ResNet
自2012年AlexNet提出以来,图像分类.目标检测等一系列领域都被卷积神经网络CNN统治着.接下来的时间里,人们不断设计新的深度学习网络模型来获得更好的训练效果.一般而言,许多网络结构的改进(例如 ...
- 深度学习之ResNet网络
介绍 Resnet分类网络是当前应用最为广泛的CNN特征提取网络. 我们的一般印象当中,深度学习愈是深(复杂,参数多)愈是有着更强的表达能力.凭着这一基本准则CNN分类网络自Alexnet的7层发展到 ...
- Android 学习笔记之网络通信基础+WebView....
PS:加快学习进度...下周一完成Android网络通信...然后正式进入实战... 学习内容: 1.Android中Http基础... 2.Android中的Socket基础... 3.Androi ...
- nodejs学习笔记之网络编程
了解一下OSI七层模型 OSI层 功能 TCP/IP协议 应用层 文件传输,电子邮件,文件服务,虚拟终端 TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet 表示层 数据格式化 ...
- python学习笔记:网络请求——urllib模块
python操作网络,也就是打开一个网站,或者请求一个http接口,可以使用urllib模块.urllib模块是一个标准模块,直接import urllib即可,在python3里面只有urllib模 ...
- python学习笔记11 ----网络编程
网络编程 网络编程需要知道的概念 网络体系结构就是使用这些用不同媒介连接起来的不同设备和网络系统在不同的应用环境下实现互操作性,并满足各种业务需求的一种粘合剂.网络体系结构解决互质性问题彩是分层方法. ...
- RHCA442学习笔记-Unit13网络性能调整
UNIT 13 Essential Network Tuning 网络性能调整 目标:1. 应用队列技术最大化网络吞吐量 2. 调整TCP和non-TCP网络soc ...
随机推荐
- FLIR 相机采集程序
https://www.ptgrey.com/Downloads/GetSecureDownloadItem/11048 Grasshopper3 4.1 MP Mono USB3 Vision (C ...
- 使用.net core构建分布式SAAS系统(目录)
一 前言 二 项目背景 三 项目架构-从单体应用到微服务 四 大数据量下的分库分表 五 缓存处理--进程内缓存与Redis的使用 六 使用MNS队列来流量削峰 七 百万Job的任务调度系统 八 每天1 ...
- input type=file的几个属性
<input type='file' /> inputDom.onchange=function (e){ e.currentTarget.files 是只有一个对象的数组 var ob ...
- scala的多种集合的使用(5)之数组Array(ArrayBuffer)的操作
1.创建和更新数组的不同方式 1)定义一个数组的初始大小和类型,随后填充值. scala> val array = new Array[String](3) array: Array[Strin ...
- [转帖] Linux 时间参数
Linux下文件的三个时间参数 https://blog.csdn.net/GGxiaobai/article/details/53609478 想用touch修改创建时间呢 发现不知道怎么修改来着. ...
- dataframe常用处理
获取列名:data.columns.values.tolist() 复制列: out['serial_number'] = out['2']这样就是新增了一列,复制了‘2’这一列,然后再del out ...
- windows无法完成安装,若要在此计算机上安装,请重新启动安装
当出现如上提示的时候,不要重启,按下shift+f10 会打开命令窗口,先输入cd oobe 进入到C:\windows\system32\oobe文件夹,输入msoobe回车然后输入msoobe即可 ...
- 完全理解 Python 迭代对象、迭代器、生成器(转)
完全理解 Python 迭代对象.迭代器.生成器 本文源自RQ作者的一篇博文,原文是Iterables vs. Iterators vs. Generators » nvie.com,俺写的这篇文章是 ...
- P4137 Rmq Problem / mex (莫队)
题目 P4137 Rmq Problem / mex 解析 莫队算法维护mex, 往里添加数的时候,若添加的数等于\(mex\),\(mex\)就不能等于这个值了,就从这个数开始枚举找\(mex\): ...
- SaltStack说明文档
SaltStack说明文档 master安装 # 安装 yum -y install salt-master salt-minion salt-ssh # 启动 systemctl start sal ...