Apache Storm 核心概念
前言:
Storm读取实时数据流,并传递给处理单元,最终输出处理后的数据。
下图描述了storm的处理数据的主要结构。
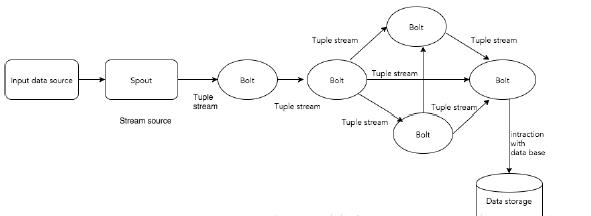
元组(Tuple) :
元组是Storm提供的一个轻量级的数据格式,可以用来包装你需要实际处理的数据。元组是一次消息传递的基本单元。一个元组是一个命名的值列表,其中的每个值都可以是任意类型的。元组是动态地进行类型转化的(字段的类型不需要事先声明)。在Storm中编程时,就是在操作和转换由元组组成的流。通常,元组包含整数,字节,字符串,浮点数,布尔值和字节数组等类型。要想在元组中使用自定义类型,就需要实现自己的序列化方式。
流(Stream) :
一个流由无限的元组序列组成,这些元组会被分布式并行地创建和处理。通过流中元组包含的字段名称来定义这个流。
每个流声明时都被赋予了一个ID。只有一个流的Spout和Bolt非常常见,所以OutputFieldsDeclarer提供了不需要指定ID来声明一个流的函数(Spout和Bolt都需要声明输出的流)。这种情况下,流的ID是默认的“default”。
Spouts :
Spout(喷嘴)是Storm中流的来源。通常Spout从外部数据源,如消息队列中读取元组数据并吐到拓扑里。Spout可以是可靠的(reliable)或者不可靠(unreliable)的。可靠的Spout能够在一个元组被Storm处理失败时重新进行处理,而非可靠的Spout只是吐数据到拓扑里,不关心处理成功还是失败了。
Spout可以一次给多个流吐数据。此时需要通过OutputFieldsDeclarer的declareStream函数来声明多个流并在调用SpoutOutputCollector提供的emit方法时指定元组吐给哪个流。
Spout中最主要的函数是nextTuple,Storm框架会不断调用它去做元组的轮询。如果没有新的元组过来,就直接返回,否则把新元组吐到拓扑里。nextTuple必须是非阻塞的,因为Storm在同一个线程里执行Spout的函数。
Spout中另外两个主要的函数是ack和fail。当Storm检测到一个从Spout吐出的元组在拓扑中成功处理完时调用ack,没有成功处理完时调用fail。只有可靠型的Spout会调用ack和fail函数。
Bolts :
storm是一种分布式实时计算系统,而storm topology中,所有的实时计算的业务逻辑都是定义在bolt中的。bolt中可以做任何计算逻辑,比如过滤、执行自定义的函数、聚合、join、访问数据库,等等。简而言之,bolt实际上就是我们实现或者继承了storm提供的接口或基类,自己开发的类。
接着看一个实例,如何通过Apache Storm来构建Twitter Analysis。结构如下图所示。

通过Twitter Streaming API为Twitter Analysis提供输入数据。Spout通过Twitter Streaming API读取数据,并以tuple流的形式输出。随后tuple将转发给bolt,bolt将会对tuple进行处理。
Topology(拓扑):
storm topology和mapreduce job是有些类似的。唯一关键的区别就在于,mapreduce job是肯定会结束运行的;但是storm topology是永远会运行的,除非你自己手动杀了它。
使用storm开发的实时计算应用程序,所有的计算逻辑都在topology中。一个topology,其实就是逻辑上的计算流向图,由spout和bolt组成。一个topology可以包含一个或者多个spout和bolt。而spout和bolt,就是topology这个计算流向图种的一个一个的计算节点,其中包含了我们自己编写的计算代码。spout和bolt之间的关系和联系,其实就定义了实时计算的数据流向。可以想象成,数据从外部读入spout,然后传输到后面一个一个的bolt;而bolt之间的数据流向,可能是交叉层叠的,看起来整个topology就像一个DAG(有向无环图)一样。 简而言之,topology,就是逻辑上的实时计算拓扑图。
Tasks(任务):
Spout 和 bolt是topology中的最小逻辑单元。topology是通过一个spout和一组bolt构建。逻辑单元需要按特定的顺序来执行。Storm所执行的每个spout和bolt称为task。简而言之,spout或bolt的执行称为task。每个spout和bolt都可以有多个不同的实例运行在不同的线程中。(每一个task对应到一个线程)。
Workers:
toplogy是在分布式环境下,多个worker节点上运行。storm将任务均匀分配在所有worker节点上。work节点的作用是监听任务(jobs),当有新任务来时,启动或停止任务的处理。每个worker是一个物理JVM并且执行整个topology的一部分。
Stream Grouping:
流分组,是拓扑定义中的一部分,为每个bolt指定应该接收哪个流作为输入。流分组定义流/元组如何在bolt的任务之间进行分发。
感谢您阅读上海大数据培训文章,
更多推荐阅读:
【上海大数据培训】storm集群架构;
【上海大数据培训】storm如何分配任务和负载均衡
Apache Storm 核心概念的更多相关文章
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- Storm 系列(二)—— Storm 核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑).它是一个是由 Spouts 和 Bolts 通过 Stre ...
- Apache NiFi 核心概念和关键特性
本文来源于官方文档翻译 NiFi 的核心概念 NiFi 最早是美国国家安全局内部使用的工具,用来投递海量的传感器数据.后来由 apache 基金会开源.天生就具备强大的基因.NiFi基本设计理念与 F ...
- Apache Shiro 核心概念
转自:http://blog.csdn.net/peterwanghao/article/details/8015571 Shiro框架中有三个核心概念:Subject ,SecurityManage ...
- Apache Hudi核心概念一网打尽
1. 场景 https://hudi.apache.org/docs/use_cases.html 近实时写入 减少碎片化工具的使用 CDC 增量导入 RDBMS 数据 限制小文件的大小和数量 近实时 ...
- apache storm基本原理及使用总结
什么是Apache Storm Apache Storm是一个分布式实时大数据处理系统.Storm设计用于在容错和水平可扩展方法中处理大量数据.它是一个流数据框架,具有最高的摄取率.虽然Storm是无 ...
- apache Storm学习之二-基本概念介绍
2.1 Storm基本概念 在运行一个Storm任务之前,需要了解一些概念: Topologies Streams Spouts Bolts Stream groupings Reliability ...
- Apache Storm 与 Spark:对实时处理数据,如何选择【翻译】
原文地址 实时商务智能这一构想早已算不得什么新生事物(早在2006年维基百科中就出现了关于这一概念的页面).然而尽管人们多年来一直在对此类方案进行探讨,我却发现很多企业实际上尚未就此规划出明确发展思路 ...
- Apache Storm
作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy 背景介绍 流计算:将大规模流动数据在不断变化的运动过程中实现数据的实时分析,捕捉到可 ...
随机推荐
- HTML 文本内容居中
简单描述:使用bootstrap 的model弹出框,里边的标题内容是靠左的,想把内容居中. 操作:给标题的class加上"text-center". 另外 我发现,在使用mode ...
- 修改MySQL的数据目录
环境:CentOS Linux release 7.1.1503 (Core) 1. 安装MYSQL wget http://dev.mysql.com/get/mysql-community-rel ...
- Canvas中如何画一条清晰的线宽为奇数(如1px逻辑像素)的线?
我在开发中使用canvas的机会不是很多,但是第一次实际使用中就遇到了问题,"很久很久以前,我自己画了一个雷达图,线宽都是1像素,但是显示效果不如期望,这才发现canvas中的画线还是有坑的 ...
- nginx 常用命令
-?,-h : this help -v : show version and exit -V : show version and c ...
- UOJ#196. 【ZJOI2016】线段树 概率期望,动态规划
原文链接www.cnblogs.com/zhouzhendong/p/UOJ196.html 题解 先离散化,设离散化后的值域为 $[0,m]$ . 首先把问题转化一下,变成:对于每一个位置 $i$ ...
- 了解javascript里面的 封装
// 封装 //生成实例对象的原始模式 //假如我们把一个动物看成一个对象 var cat = { //那么它有名字和颜色两个属性 name:'', color:'' }; //接下来我们根据原形对象 ...
- excel导出使用get请求参数过长问题
遇到的问题: excel导出功能时,使用的是window.location.href=url也就是get请求.当传入参数过长的时候就报了414,地址过长的错误. 解决思路: 将get请求换为post请 ...
- 关于DataTable序列化的事儿
今天写了一个小demo,从数据库中读取到了dataTable,想序列化成json字符串,然后传到前端,进行页面展示,其实很简单的一个步骤,谁知道它出错了!!! 出错的原因是:序列化类型为XX的对象时检 ...
- Hashlib加密,内置函数,安装操作数据库
hashlib模块的md5加密: md5同样的内容加密后是一样的 md5加密后是不可逆的.即能加密,没办法解密. 撞库: 只是针对简单的,因为同样的内容加密后是一样的,难一点就不行了. 登录密码:注册 ...
- Jenkins pipeline job 根据参数动态获取触发事件的分支
此文需要有Jenkins pipeline job 的简单使用经验 场景 我们日常的测试函数, 一般是不能仅仅在本地跑的,还需要一个公共的跑测试的环境,作为合并新的PR的依据. 如果用Jenkins ...