Mycat问题总结
Mycat问题总结
一丶自增主键设置
Mycat提供了几种设置自增主键的方式
- 本地文件方式
- 数据库方式
- 服务器时间戳方式
- 分布式ZK-ID生成器
第一种和第二种只适合单点设置,对于集群不适用。第四种方式适用,但是需要增加zk服务器,维护成本较高,或者由于某些原因不能用zk,此方式也会受到约束,故采用服务器时间戳的方式生成自增主键ID。以下为配置方法
- 修改server.xml,设置为时间戳格式
<property name="sequnceHandlerType">2</property>
- 修改sepuence_time_conf.properties,设置组合形式
WORKID=0-31 任意整数
DATAACENTERID=0-31 任意整数
- 修改schema.xml,设置主键ID为自增
<table name="sam_test" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="sharding-by-pattern" />
二丶按日期(天)分片
- 在查询时,应该具体到某一天去查询
```
例如:SELECT * FROM table WHERE create_time = '2019-01-01';
```
这样查询数据只会去查某一个节点
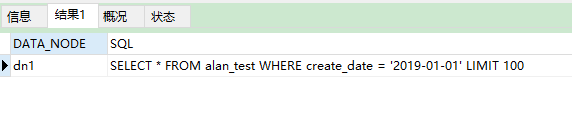
2. 如果需要查询时间段,应该用between...and,不能用>=或者<=,区别如下
```
SELECT * from alan_test WHERE create_date = '2019-01-01';
```

SELECT * FROM table WHERE create_time between '2019-01-01' and '2019-01-12';

按天分片,需要创建结束时间,到结束时间之后的数据会循环计算,具体存到哪个分片。
三丶固定分片Hash算法和取模分片的区别
- 固定分片Hash算法类似于十进制的求模运算,区别在于是二进制的操作,是取id的二进制低10位,即id二进制&1111111111。
此算法的优点在于如果按照 10 进制取模运算,在连续插入 1-10 时候 1-10会被分到1-10个分片,增大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。但是该方法插入时计算量大,效率较低。 - 取模运算这种配置非常明确即根据 id进行十进制求模预算,相比固定分片hash。
此种在批量插入时可能存在批量插入单事务插入多数据分片,增大事务一致性难度,效率高。
四丶修改配置文件注意
注意:修改server.xml等配置文件时,一定要注意编码格式。如果增加注释或者增加中文注释,一定要确保编码格式和之前的编码一样,一般都为UTF-8,否则会出现以下异常
WrapperSimpleApp: Encountered an error running main: java.lang.ExceptionInInitializerError
INFO | jvm 1 | 2019/01/17 08:26:35 | java.lang.ExceptionInInitializerError
INFO | jvm 1 | 2019/01/17 08:26:35 | at io.mycat.MycatStartup.main(MycatStartup.java:53)
INFO | jvm 1 | 2019/01/17 08:26:35 | at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
INFO | jvm 1 | 2019/01/17 08:26:35 | at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
INFO | jvm 1 | 2019/01/17 08:26:35 | at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
INFO | jvm 1 | 2019/01/17 08:26:35 | at java.lang.reflect.Method.invoke(Method.java:606)
INFO | jvm 1 | 2019/01/17 08:26:35 | at org.tanukisoftware.wrapper.WrapperSimpleApp.run(WrapperSimpleApp.java:240)
INFO | jvm 1 | 2019/01/17 08:26:35 | at java.lang.Thread.run(Thread.java:744)
INFO | jvm 1 | 2019/01/17 08:26:35 | Caused by: io.mycat.config.util.ConfigException: com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: Invalid byte 1 of 1-byte UTF-8 sequence.
五丶应用指定某个分片
此规则是在运行阶段,由应用自主决定数据存到哪个分片上面,此方法为直接根据字符子串(必须是数字)计算分区号。配置规则如下,修改rule.xml
<tableRule name="sharding-by-substring">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property><!-- zero-based -->
<property name="size">2</property>127
<property name="partitionCount">8</property>
<property name="defaultPartition">0</property>
</function>
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数
此方法为直接根据字符子串(必须是数字)计算分区号(由应用传递参数,显式指定分区号)。
例如 id=05-100000002
在此配置中代表根据 id 中从 startIndex=0,开始,截取 siz=2 位数字即 05,05 就是获取的分区,如果没传默认分配到 defaultPartition
注意:由于字符子串必须为数字,所以在存入该字段值且该字段为int或者long类型时,首字符不能为0,在配置截取规则时,也不能配置从0开始。
六丶使用EXPLAIN查看路由结果
Mycat提供的EXPLAIN语句并不是用来查看执行计划的,而是用来查看路由结果的,如果要查询真正的执行计划,拿到路由结果里面的sql语句,到具体的实例上面查看就行了。例如下面的语句,就被路由到了3个库
explain SELECT * from alan_test WHERE create_date > '2019-01-01 10:00:00' and create_date < '2019-01-12 18:00:00';

EXPLAIN不支持查看insert语句并且使用Mycat生成id的sql语句。这个很好理解,因为无法路由。如果使用会报如下异常
insert sql using mycat seq,you must provide primaryKey value for explain
七丶根据按日期(天)分片,在mycat中执行以下sql报错
INSERT INTO item(value,indate) VALUES(1,NOW());
错误信息如下:
[Err] 1064 - columnValue:'2019-01-17 09:40:01' Please check if the format satisfied.
将NOW()改为字符串可执行成功
八丶使用程序insert数据(以下过程是通过程序执行)
执行以下sql可以保存成功
insert into item (indate, value) values (?, ?)
执行查询语句
select item0_.id as id1_0_, item0_.indate as indate2_0_, item0_.value as value3_0_ from item item0_
再次执行第一步sql保存失败,错误信息如下:
Caused by: java.sql.SQLException: Connection is read-only. Queries leading to data modification are not allowed
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:957) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:896) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:885) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:860) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2040) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2009) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.PreparedStatement.executeLargeUpdate(PreparedStatement.java:5094) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1994) ~[mysql-connector-java-5.1.38.jar:5.1.38]
at org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.executeUpdate(ResultSetReturnImpl.java:204) ~[hibernate-core-5.0.11.Final.jar:5.0.11.Final]
... 117 common frames omitted
9.一致性Hash分片
一致性 hash 预算有效解决了分布式数据的扩容问题。
10.按单月小时拆分
分片字段必须为字符串格式,否则分片不成功,默认存到第一个分片里面;
保存的时间格式必须为‘yyyymmddHH’格式,不能多也不能少字符,否则分片不成功,默认存到第一个分片里面;
11.范围求模分片
该分片方法,有个非常大的优势,就是对扩容,原数据无需迁移
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>time_id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<function name="rang-mod"class="io.mycat.route.function.PartitionByRangeMod">
<propertyname="mapFile">partition-range-mod.txt</property>
<propertyname="defaultNode">0</property>
</function>
partition-range-mod.txt 文件中的内容:
#1451577600000 是 2016-01-01 00:00:00 的long值
#1467302399000 是 2016-06-30 23:59:59 的long值
#1483199999000 是 2016-12-31 26:59:59 的long值
1451577600000-1467302399000=2
1467302399001-1483199999000=2
上面的一个条目[1451577600000-1467302399000=2]代表一个分片组,开始范围--结束范围=该分片组有多少个分片(DataNode)。也就是我给出的方案是,2016上半年的数据存入分片组1,分片组1包含(dn1,dn2)两个节点,2016年下半年的数据,存入分片组2,(dn3,dn4),那2017年的数据怎么办呢,我们可以增加分片组来实现,也可修改配置文件,使用原来的1,2,3,4这样来配置,实现扩容时,不需要对原数据进行迁移。
12.日期范围hash分片
思想与范围求模一致,当由于日期在取模会有数据集中问题,所以改成 hash 方法。
先根据日期分组,再根据时间 hash 使得短期内数据分布的更均匀
优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题
要求日期格式尽量精确些,不然达不到局部均匀的目的
<tableRule name="rangeDateHash">
<rule>
<columns>col_date</columns>
<algorithm>range-date-hash</algorithm>
</rule>
</tableRule>
<function name="range-date-hash" class="io.mycat.route.function.PartitionByRangeDateHash">
<property name="sBeginDate">2014-01-01 00:00:00</property>
<property name="sPartionDay">3</property>
<property name="dateFormat">yyyy-MM-dd HH:mm:ss</property>
<property name="groupPartionSize">6</property>
</function>
- 参数说明:
-- sBeginDate 代表开始时间
-- sPartionDay 代表多少天分一个分片
-- groupPartionSize 代表分片组的大小
- 参数说明:
- 详细解释:从sBeginDate时间开始计算,每sPartionDay天的数据为一个分片组,每个分片组可以分布在groupPartionSize个分片上面。上面的例子最多可以有三天进行分片,如果超出则会抛出以下异常
Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Can't find a valid data node for specified node index :ALAN_TEST -> RANGE_DATE -> 2019-01-11 12:00:00 -> Index : 4
The error may involve com.mycat.test.model.AlanTest.insert-Inline
The error occurred while setting parameters
13.冷热数据分片
根据日期查询日志数据 冷热数据分布 ,最近 n 个月的到实时交易库查询,超过 n 个月的按照 m 天分片。
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-hotdate</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hotdate" class="io.mycat.route.function.PartitionByHotDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sLastDay">10</property>
<property name="sPartionDay">30</property>132
</function>
参数说明:
- dataFormat:时间格式化。按照给定的格式对参数进行格式化,方便计算具体的时间段
- sLastDay:热数据的天数。从当前服务器时间开始计算,之前sLastDay天的数据和之后所有的数据,全部为热数据。
- sPartionDay:冷数据的分片天数(按照天数分片)。冷数据按照这个范围进行分片,例如上面的规则配置,今天是2019年1月21日,往前推10天为2019年1月12日,则2019年1月12日之前的数据为冷数据,该批冷数据的分片规则为30天一个分片,即2018-12-12至2019-01-11的数据放入第2个分片,2018-11-12至2018-12-11的数据放入第2个分片...以此类推,如果数据库分区不够,则在保存的时候会抛出以下异常
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Can't find a valid data node for specified node index :ALAN_TEST -> CREATE_DATE -> 2018-11-09 12:00:00 -> Index : 3
14.修改数据
mycat中分片表中的分片字段是不能更新的,而Jpa(底层hibernate)默认是更新全字段。所以会产生冲突,抛出如下异常
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Sharding column can't be updated ALAN_TEST->RANGE_DATE
14.1解决方案
- 对实体类增加注解:@Column(updatable=false)
- 或者修改实体映射文件
<property name="age" update="false"></property>
15.多条件查询
多条件查询,AND语句连接,只要有一个条件为分片的字段,那么会按照分片表进行查询,和条件的顺序没有关系。
16.join语句
目前支持的规则为,只有当分片规则相同,并且两个表的数据分布到了同一个分片数据库中,那么根据join查询出来的数据是完整的。
如果分片规则相同,分片不同,查询出来的数据是不完整的,即左连接只能查询左表数据,由连接只能查询右表数据。 内连接和inner数据都不能查询出来。
17.数据库表名大小写
最好采用数据库表名小写,因为如果采用大写,逻辑库中生成的为小写表名,在分片库中生成的为大写表名,这样会导致mycat找不到表而发生错误
Mycat问题总结的更多相关文章
- MyCat源码分析系列之——结果合并
更多MyCat源码分析,请戳MyCat源码分析系列 结果合并 在SQL下发流程和前后端验证流程中介绍过,通过用户验证的后端连接绑定的NIOHandler是MySQLConnectionHandler实 ...
- MyCat源码分析系列之——SQL下发
更多MyCat源码分析,请戳MyCat源码分析系列 SQL下发 SQL下发指的是MyCat将解析并改造完成的SQL语句依次发送至相应的MySQL节点(datanode)的过程,该执行过程由NonBlo ...
- MyCat源码分析系列之——BufferPool与缓存机制
更多MyCat源码分析,请戳MyCat源码分析系列 BufferPool MyCat的缓冲区采用的是java.nio.ByteBuffer,由BufferPool类统一管理,相关的设置在SystemC ...
- MyCat源码分析系列之——前后端验证
更多MyCat源码分析,请戳MyCat源码分析系列 MyCat前端验证 MyCat的前端验证指的是应用连接MyCat时进行的用户验证过程,如使用MySQL客户端时,$ mysql -uroot -pr ...
- MyCat源码分析系列之——配置信息和启动流程
更多MyCat源码分析,请戳MyCat源码分析系列 MyCat配置信息 除了一些默认的配置参数,大多数的MyCat配置信息是通过读取若干.xml/.properties文件获取的,主要包括: 1)se ...
- 开源分布式数据库中间件MyCat源码分析系列
MyCat是当下很火的开源分布式数据库中间件,特意花费了一些精力研究其实现方式与内部机制,在此针对某些较为重要的源码进行粗浅的分析,希望与感兴趣的朋友交流探讨. 本源码分析系列主要针对代码实现,配置. ...
- mysql+mycat搭建稳定高可用集群,负载均衡,主备复制,读写分离
数据库性能优化普遍采用集群方式,oracle集群软硬件投入昂贵,今天花了一天时间搭建基于mysql的集群环境. 主要思路 简单说,实现mysql主备复制-->利用mycat实现负载均衡. 比较了 ...
- 【无私分享:ASP.NET CORE 项目实战(第十三章)】Asp.net Core 使用MyCat分布式数据库,实现读写分离
目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 MyCat2.0版本很快就发布了,关于MyCat的动态和一些问题,大家可以加一下MyCat的官方QQ群:106088787.我 ...
- mycat入门教程
github https://github.com/MyCATApache/Mycat-Server myCat介绍 myCat的诞生,要从其前身Amoeba和Cobar说起. Amoeba(变形虫) ...
- Mycat 全局系列号
标签:utf8 概述 本篇文章介绍mycat怎样在分库分表的情况下保证主键的全局唯一方法,接下来就来分析三种方法各自的优缺点. 配置 文件方式获取 1.修改server配置文件 vim server. ...
随机推荐
- Redis configuration
官方2.6配置如下: # Redis configuration file example # Note on units: when memory size is needed, it is pos ...
- Spring中使用两种Aware接口自定义获取bean
在使用spring编程时,常常会遇到想根据bean的名称来获取相应的bean对象,这时候,就可以通过实现BeanFactoryAware来满足需求,代码很简单: @Servicepublic clas ...
- 破解栅栏密码python脚本
今天遇到一个要破解的栅栏密码,写了个通用的脚本 #!/usr/bin/env python # -*- coding: gbk -*- # -*- coding: utf_8 -*- # Author ...
- pageParam要求传个JSON对象的方法
pageParam要求传个JSON对象,使用方式:api.openWin({name: 'page1',url: 'page1.html',pageParam: {x: '1000',y: '2000 ...
- JPA之@OneToMany、@ManyToOne、@JoinColumn
顾名思义,@OneToMany.@ManyToOne这两个注解就是处理一对多,多对一的关系 这两个注解是成双成对的,有了@OneToMany,一定会配置一个@ManyToOne OneToMany设置 ...
- MVC,MVP 和 MVVM 的图示(转)
作者: 阮一峰 日期: 2015年2月 1日 转自:http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html 复杂的软件必须有清晰合理的架构,否则 ...
- python Django html 一对多数据实例 模态对话框添加数据
- Enter键登录
<div class="zhuce_input_ty"> <p><a id="qianlogin" onclick="U ...
- Drupal8入门文章推荐
1.<drupal 8 入门 > 2.<初探drupal8>
- react知识点汇总
①uncontrolComponent & controlComponent If your form is incredibly simple in terms of UI feedback ...