TreeMap实现原理及源码分析之JDK8
转载 Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例
一、TreeMap 简单介绍
什么是Map?
在数组中我们通过数组下标来对数组内容进行索引的,而在Map中我们通过对象来对 对象进行索引,用来索引的对象叫做key,其对应的对象叫做value。这就是我们平时说的键值对。
什么是TreeMap?
TreeMap是一个有序的key-value集合,是非线程安全的,基于红黑树(Red-Black tree)实现。其映射根据键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。其基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
当自定义比较器时,需要自定义类实现java.lang.Comparable接口,并重写compareTo()方法。
TreeMap与HashMap的区别:
- 数据结构不同:
- HashMap是基于哈希表,由 数组+链表+红黑树 构成。
- TreeMap是基于红黑树实现。
- 存储方式不同:
- HashMap是通过key的hashcode对其内容进行快速查找。
- TreeMap中所有的元素都保持着某种固定的顺序。
- 排列顺序:
- HashMap存储顺序不固定。
- TreeMap存储顺序固定,可以得到一个有序的结果集。
二、TreeMap源码分析
1.TreeMap类继承图:
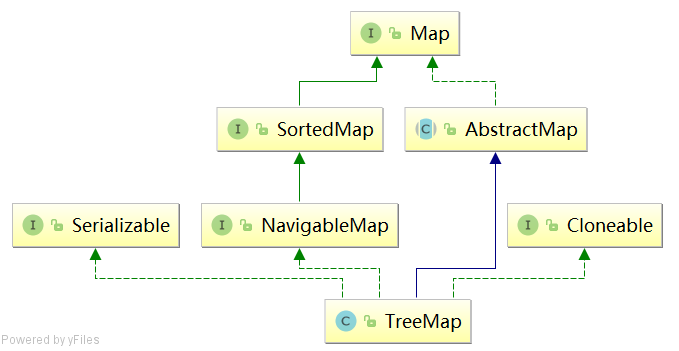
TreeMap类定义:
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
- TreeMap<K,V>:TreeMap是以key-value形式存储数据的。
- extends AbstractMap<K,V>:继承了AbstractMap,大大减少了实现Map接口时需要的工作量。
- implements NavigableMap<K,V>:实现了SortedMap,支持一系列的导航方法。比如返回有序的key集合。
- implements Cloneable:表明其可以调用克隆方法clone()来返回实例的field-for-field拷贝。
- implements Serializable:表明该类是可以序列化的。
2.类成员变量和静态内部类Entry:
// 比较器对象
private final Comparator<? super K> comparator; // 根节点
private transient Entry<K,V> root; // 集合大小
private transient int size = 0; // 树结构被修改的次数
private transient int modCount = 0;
// 红黑树节点颜色
private static final boolean RED = false;
private static final boolean BLACK = true;
// 静态内部类用来表示节点类型
static final class Entry<K,V> implements Map.Entry<K,V> {
K key; // 键
V value; // 值
Entry<K,V> left; // 指向左子树的引用(指针)
Entry<K,V> right; // 指向右子树的引用(指针)
Entry<K,V> parent; // 指向父节点的引用(指针)
boolean color = BLACK;
}
关键字transient的作用:
transient是Java语言的关键字,它被用来表示一个域中不是该对象串行化的一部分。
Java的 serialization 提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
当一个对象被串行化的时候,transient型的变量值 不包括在串行化的表示中,而 非transient型的变量 是被包括进去的。
3.TreeMap的构造函数:
// 默认构造函数。使用默认比较器比较key的大小,TreeMap中的元素按照自然排序进行排列。
public TreeMap() {
// 默认比较机制
comparator = null;
} // 带比较器的构造函数
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
} // 带Map的构造函数,Map会成为TreeMap的子集
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
} // 带SortedMap的构造函数,SortedMap会成为TreeMap的子集
public TreeMap(SortedMap<K, ? extends V> m) {
// 使用已知对象的比较器
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
putAll(Map<? extends K, ? extends V> map) 方法:
/**
* Map中的所有元素添加到TreeMap中
*/
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
// TreeMap的size为0,map的size不为0,并且map是SortedMap的实例
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
// 默认比较器等于map的比较器,或者map的比较器不为null,并且与默认比较器相等
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
// 使用父类putAll()
super.putAll(map);
} /**
* Map中的所有元素添加到TreeMap中
*/
public void putAll(Map<? extends K, ? extends V> m) {
// 遍历map一个一个添加到TreeMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
buildFromSorted(int size, Iterator<?> it, java.io.ObjectInputStream str, V defaultVal) 方法:
/**
* SortedMap(有序的map)中的所有元素添加到TreeMap中
*/
private void buildFromSorted(int size, Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
} /**
* 将map中的元素逐个添加到TreeMap中,并返回map的中间元素作为根节点
*/
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException { if (hi < lo) return null; // 获取中间元素
int mid = (lo + hi) >>> 1; Entry<K,V> left = null; // 若lo小于mid,则递归调用获取(middel的)左孩子。
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal); // 从Iterator或stream中获取middle节点对应的key和value
K key;
V value;
if (it != null) {
if (defaultVal==null) {
Map.Entry<?,?> entry = (Map.Entry<?,?>)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
} else { // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
} // 创建middle节点
Entry<K,V> middle = new Entry<>(key, value, null); // 若当前节点的深度==红色节点的深度,则将节点着色为红色
if (level == redLevel)
middle.color = RED; // 设置middle为left的父亲,left为middle的左孩子
if (left != null) {
middle.left = left;
left.parent = middle;
} if (mid < hi) {
// 递归调用获取(middel的)右孩子
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
// 设置middle为right的父亲,right为middle的右孩子
middle.right = right;
right.parent = middle;
} return middle;
}
添加到红黑树中时,只将level == redLevel的节点设为红色。表示第level级节点,实际上是用buildFromSorted方法转换成红黑树后 的最底端的节点(假设根节点在最上方);只将红黑树最底端的级别 着色为红色,其余都是黑色。
4.核心方法:
红黑树相关的方法:
rotateLeft(Entry<K,V> p) 方法:
/**
* 左旋
*/
private void rotateLeft(Entry<K,V> p) {
if (p != null) { Entry<K,V> r = p.right; // 令p节点右孩子为r节点
p.right = r.left; // 令r节点的左孩子为 p节点的右孩子
if (r.left != null)
r.left.parent = p; // 当r节点的左孩子不为null时,令p节点为 r节点的左孩子 的父节点
r.parent = p.parent; // 令p节点的父节点为 r节点的父节点
if (p.parent == null)
root = r; // 当p节点的父节点为null时,令r节点为根节点
else if (p.parent.left == p)
p.parent.left = r; // 当p节点的父节点的左孩子为p节点时,令r节点为 p节点的父节点的左孩子
else
p.parent.right = r; // 当p节点的父节点的右孩子为p节点时,令r节点为 p节点的父节点的右孩子
r.left = p; // 令p节点为 r节点的左孩子
p.parent = r; // 令r节点为 p节点的父节点
}
}
put(K key, V value) 方法:
/**
* 插入操作
*/
public V put(K key, V value) {
Entry<K,V> t = root; // 获取根节点
if (t == null) {
compare(key, key); // 检查key的类型,是否为null root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent; // 获取比较器
Comparator<? super K> cpr = comparator;
// 比较器不为null时,即自定义了比较器
if (cpr != null) {
// 循环比较插入节点的key与根节点的key的大小,确定插入节点的位置,即找到插入节点的父节点
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value); // 插入节点与根节点的key的大小相同,直接覆盖
} while (t != null);
}
// 比较器为null时,使用默认的比较器
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
// 循环比较插入节点的key与根节点的key的大小,确定插入节点的位置,即找到插入节点的父节点
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 在插入节点的父节点后创建节点
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 插入修正操作,使插入节点后,TreeMap还是红黑树结构
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
与红黑树有关的方法还有:
- 右旋-rotateRight(Entry<K,V> p)
- 插入修正为红黑树-fixAfterInsertion(Entry<K,V> x)
- 删除-deleteEntry(Entry<K,V> p)
- 删除修正为红黑树-fixAfterDeletion(Entry<K,V> x)
都是根据算法翻译成代码,具体可参考这里。
TreeMap中Entry相关的方法:
TreeMap的 firstEntry()、 lastEntry()、 lowerEntry()、 higherEntry()、 floorEntry()、 ceilingEntry()、 pollFirstEntry() 、 pollLastEntry() 原理类似,以下讲解firstEntry()方法。
firstEntry() 方法:
/**
* 获取第一个节点
*/
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
} /**
* 获取第一个节点
*/
final Entry<K,V> getFirstEntry() {
// 获取根节点
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
} /**
* 获取第一个节点
*/
static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) {
// 如果节点为null,创建AbstractMap.SimpleImmutableEntry类型的对象,并返回
return (e == null) ? null :
new AbstractMap.SimpleImmutableEntry<>(e);
}
public static class SimpleImmutableEntry<K,V>
implements Entry<K,V>, java.io.Serializable
{
private static final long serialVersionUID = 7138329143949025153L; private final K key;
private final V value; public SimpleImmutableEntry(K key, V value) {
this.key = key;
this.value = value;
} public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) {
this.key = entry.getKey();
this.value = entry.getValue();
} public K getKey() {
return key;
} public V getValue() {
return value;
} public V setValue(V value) {
throw new UnsupportedOperationException();
} public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return eq(key, e.getKey()) && eq(value, e.getValue());
} public int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
} public String toString() {
return key + "=" + value;
} }
SimpleImmutableEntry 类的实现
从上面,我们可以看出 firstEntry() 和 getFirstEntry() 都是用于获取第一个节点。但是,firstEntry() 是对外接口; getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。那为什么外界不能直接调用 getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。因为exportEntry()方法所在类 SimpleImmutableEntry 的 setValue()方法会抛出 UnsupportedOperationException() 异常。
TreeMap中key相关方法:
TreeMap的firstKey()、lastKey()、lowerKey()、higherKey()、floorKey()、ceilingKey()原理都是类似的,下面以ceilingKey()来进行详细说明。
ceilingKey(K key) 方法:
/**
* 获取大于/等于key的最小节点所对应的key,没有的话返回null
*/
public K ceilingKey(K key) {
return keyOrNull(getCeilingEntry(key));
}
/**
* 寻找大于/等于key的最小节点
*/
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
// 如果根节点的key大于给定key
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
} else if (cmp > 0) { // 如果根节点的key小于给定key
if (p.right != null) {
p = p.right;
} else { // 如果根节点的右孩子为null
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
} else
return p;
}
return null;
}
/**
* 如果节点不为null,返回节点的key值,否则返回null
*/
static <K,V> K keyOrNull(TreeMap.Entry<K,V> e) {
return (e == null) ? null : e.key;
}
TreeMap中value()方法:
value() 方法返回 TreeMap中值的集合:
/**
* 通过 new Values() 来实现,返回TreeMap中值的集合
* Values() 是集合类Value的构造函数
*/
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new Values();
values = vs;
}
return vs;
} /**
* 集合类Value
*/
class Values extends AbstractCollection<V> {
// 返回迭代器
public Iterator<V> iterator() {
// iterator() 通过ValueIterator() 返回迭代器
return new ValueIterator(getFirstEntry());
} // 返回个数
public int size() {
return TreeMap.this.size();
} // TreeMap的值的集合中 是否包含 对象o
public boolean contains(Object o) {
return TreeMap.this.containsValue(o);
} // 删除TreeMap的值的集合中的对象o
public boolean remove(Object o) {
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) {
if (valEquals(e.getValue(), o)) {
deleteEntry(e);
return true;
}
}
return false;
} // 清空TreeMap的值的集合
public void clear() {
TreeMap.this.clear();
} public Spliterator<V> spliterator() {
return new ValueSpliterator<K,V>(TreeMap.this, null, null, 0, -1, 0);
}
} /**
* ValueIterator类实现 Iterator接口实现的next()方法
*/
final class ValueIterator extends PrivateEntryIterator<V> {
ValueIterator(Entry<K,V> first) {
super(first);
}
public V next() {
return nextEntry().value;
}
}
/**
* PrivateEntryIterator类实现 Iterator接口的hasNext()和remove()方法
* ValueIterator类实现 Iterator接口实现的next()方法
*/
abstract class PrivateEntryIterator<T> implements Iterator<T> {
// 下一节点
Entry<K,V> next;
// 上一次返回的节点
Entry<K,V> lastReturned;
// 修改次数统计数
int expectedModCount; PrivateEntryIterator(Entry<K,V> first) {
expectedModCount = modCount;
lastReturned = null;
next = first;
} // 是否存在下一个节点
public final boolean hasNext() {
return next != null;
} // 返回下一个节点
final Entry<K,V> nextEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = successor(e);
lastReturned = e;
return e;
} // 返回上一节点
final Entry<K,V> prevEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = predecessor(e);
lastReturned = e;
return e;
} // 删除当前节点
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// deleted entries are replaced by their successors
if (lastReturned.left != null && lastReturned.right != null)
next = lastReturned;
deleteEntry(lastReturned);
expectedModCount = modCount;
lastReturned = null;
}
}
PrivateEntryIterator 类
TreeMap的entrySet()方法:
entrySet() 方法返回 TreeMap的键值对的集合:
/**
* 通过 new EntrySet() 来实现,返回TreeMap的键值对集合
*/
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet());
} /**
* EntrySet是TreeMap的所有键值对组成的集合,它的单位是单个键值对
*/
class EntrySet extends AbstractSet<Map.Entry<K,V>> {
// 返回迭代器
public Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator(getFirstEntry());
} // EntrySet中是否包含 键值对Object
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> entry = (Map.Entry<?,?>) o;
Object value = entry.getValue();
Entry<K,V> p = getEntry(entry.getKey());
return p != null && valEquals(p.getValue(), value);
} // 删除EntrySet中的 键值对Object
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> entry = (Map.Entry<?,?>) o;
Object value = entry.getValue();
Entry<K,V> p = getEntry(entry.getKey());
if (p != null && valEquals(p.getValue(), value)) {
deleteEntry(p);
return true;
}
return false;
} // 返回EntrySet中元素个数
public int size() {
return TreeMap.this.size();
} // 清空EntrySet
public void clear() {
TreeMap.this.clear();
} public Spliterator<Map.Entry<K,V>> spliterator() {
return new EntrySpliterator<K,V>(TreeMap.this, null, null, 0, -1, 0);
}
} /**
* EntryIterator类实现 Iterator接口实现的next()方法
*/
final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
EntryIterator(Entry<K,V> first) {
super(first);
}
public Map.Entry<K,V> next() {
return nextEntry();
}
}
TreeMap实现的Cloneable接口:
TreeMap实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个TreeMap对象并返回。
/**
* 克隆一个TreeMap,并返回Object对象
*/
public Object clone() {
TreeMap<K,V> clone = null;
try {
clone = (TreeMap<K,V>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
} // Put clone into "virgin" state (except for comparator)
clone.root = null;
clone.size = 0;
clone.modCount = 0;
clone.entrySet = null;
clone.navigableKeySet = null;
clone.descendingMap = null; // Initialize clone with our mappings
try {
clone.buildFromSorted(size, entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
} return clone;
}
TreeMap实现的Serializable接口:
TreeMap实现java.io.Serializable,分别实现了串行读取和写入功能:
- 串行写入函数是writeObject(),它的作用是将TreeMap的“容量和所有的Entry”都写入到输出流中。
- 串行读取函数是readObject(),它的作用是将TreeMap的“容量和所有的Entry”依次读出。
readObject() 和 writeObject() 正好是一对,通过它们,我能实现TreeMap的串行传输。
/**
* java.io.Serializable的写入函数
* 将TreeMap的 容量和所有的Entry 都写入到输出流中
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out the Comparator and any hidden stuff
s.defaultWriteObject(); // Write out size (number of Mappings)
s.writeInt(size); // Write out keys and values (alternating)
for (Iterator<Map.Entry<K,V>> i = entrySet().iterator(); i.hasNext(); ) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
} /**
* java.io.Serializable的读取函数:根据写入方式读出
* 将TreeMap的 容量和所有的Entry 依次读出
*/
private void readObject(final java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in the Comparator and any hidden stuff
s.defaultReadObject(); // Read in size
int size = s.readInt(); buildFromSorted(size, null, s, null);
}
三、TreeMap使用例子
1.TreeMap常用方法使用Demo:
import java.util.*; /**
* @author nana
* @date 2019/2/23
*/
public class TreeMapDemo { public static void main(String[] args) {
// 测试常用的API
testTreeMapOrdinaryAPIs(); // 测试TreeMap导航函数
testNavigableMapAPIs(); // 测试TreeMap的子Map函数
testSubMapAPIs();
} /**
* 测试常用的API
*/
private static void testTreeMapOrdinaryAPIs() {
// 生成随机数
Random random = new Random(); // 创建TreeMap实例
TreeMap treeMap = new TreeMap();
treeMap.put("one", random.nextInt(10));
treeMap.put("two", random.nextInt(10));
treeMap.put("three", random.nextInt(10)); System.out.println("TreeMapDemo.testTreeMapOrdinaryAPIs-Begin"); // 打印TreeMap
System.out.printf("打印treeMap:\n%s\n", treeMap);; // 通过Iterator遍历key-value
Iterator iterator = treeMap.entrySet().iterator();
System.out.println("通过Iterator遍历key-value:");
while (iterator.hasNext()) {
Map.Entry entity = (Map.Entry) iterator.next();
System.out.printf("%s-%s\n", entity.getKey(), entity.getValue());
} // TreeMap的键值对个数
System.out.printf("TreeMap的键值对个数:%s\n", treeMap.size()); // 是否包含key
System.out.println("是否包含key:");
System.out.printf("是否包含key:one-%s\n", treeMap.containsKey("one"));
System.out.printf("是否包含key:four-%s\n", treeMap.containsKey("four")); // 删除key对应的键值对
System.out.println("删除key对应的键值对:");
treeMap.remove("one");
System.out.printf("删除key为one的键值对后,treeMap为:\n%s\n", treeMap); // 清空TreeMap的节点
System.out.println("清空treeMap的节点:");
treeMap.clear();
System.out.printf("%s\n", treeMap.isEmpty() ? "treeMap is empty!" : "treeMap is not empty!");
System.out.printf("%s\n", treeMap == null ? "treeMap is null!" : "treeMap is not null!"); System.out.println("TreeMapDemo.testTreeMapOrdinaryAPIs-End");
} /**
* 测试TreeMap导航函数
*/
private static void testNavigableMapAPIs() {
// 创建TreeMap实例,TreeMap是 NavigableMap接口的实现类
NavigableMap navigableMap = new TreeMap();
navigableMap.put("aaa",1);
navigableMap.put("bbb",2);
navigableMap.put("ccc",3);
navigableMap.put("ddd",4); System.out.println("TreeMapDemo.testNavigableMapAPIs-Begin"); // 打印TreeMap
System.out.printf("打印navigableMap:\n%s\n", navigableMap); // 获取第一个key和节点
System.out.printf("First key:%s\tFirst entry:%s\n", navigableMap.firstKey(), navigableMap.firstEntry()); // 获取最后一个key和节点
System.out.printf("Last key:%s\tLast entry:%s\n", navigableMap.lastKey(), navigableMap.lastEntry()); // 获取小于/等于 key为bbb 最大的key和节点
System.out.printf("Key floor before bbb:%s\t%s\n", navigableMap.floorKey("bbb"), navigableMap.floorEntry("bbb")); // 获取小于 key为bbb 最大的key和节点
System.out.printf("Key lower before bbb:%s\t%s\n", navigableMap.lowerKey("bbb"), navigableMap.lowerEntry("bbb")); // 获取大于/等于 key为bbb 最大的key和节点
System.out.printf("Key ceiling after bbb:%s\t%s\n", navigableMap.ceilingKey("bbb"), navigableMap.ceilingEntry("bbb")); // 获取大于 key为bbb 最大的key和节点
System.out.printf("Key higher after bbb:%s\t%s\n", navigableMap.higherKey("bbb"), navigableMap.higherEntry("bbb")); System.out.println("TreeMapDemo.testNavigableMapAPIs-End");
} /**
* 测试TreeMap的子Map函数
*/
private static void testSubMapAPIs() {
// 实例化TreeMap对象
TreeMap treeMap = new TreeMap();
treeMap.put("a",1);
treeMap.put("b",2);
treeMap.put("c",3);
treeMap.put("d",4); System.out.println("TreeMapDemo.testSubMapAPIs-Begin"); // 打印TreeMap
System.out.printf("打印TreeMap:\n%s\n", treeMap); // 打印 key为c节点 前的节点(默认不包含c节点)
System.out.printf("打印 key为c节点 前的节点(默认不包含c节点):%s", treeMap.headMap("c")); System.out.printf("打印 key为c节点 前的节点(包含c节点):%s\n", treeMap.headMap("c", true));
System.out.printf("打印 key为c节点 前的节点(不包含c节点):%s\n", treeMap.headMap("c", false)); // 打印 key为c节点 后的节点(默认包含c节点)
System.out.printf("打印 key为c节点 后的节点(默认包含c节点):%s\n", treeMap.tailMap("c")); System.out.printf("打印 key为c节点 后的节点(包含c节点)%s\n", treeMap.tailMap("c", true));
System.out.printf("打印 key为c节点 后的节点(不包含c节点)%s\n", treeMap.tailMap("c", false)); // 打印 key为a与c节点 之间的节点(默认不包含c节点)
System.out.printf("打印 key为a与c节点 之间的节点(默认包含c节点):\n%s\n", treeMap.subMap("a", "c")); System.out.printf("打印 key为a与c节点 之间的节点(包含a、c节点):\n%s\n", treeMap.subMap("a", true, "c", true));
System.out.printf("打印 key为a与c节点 之间的节点(包含a节点):\n%s\n", treeMap.subMap("a", true, "c", false));
System.out.printf("打印 key为a与c节点 之间的节点(包含c节点):\n%s\n", treeMap.subMap("a", false, "c", true));
System.out.printf("打印 key为a与c节点 之间的节点(不包含a、c节点):\n%s\n", treeMap.subMap("a", false, "c", false)); // 正序打印TreeMap的key
System.out.printf("正序打印TreeMap的key:\n%s\n", treeMap.navigableKeySet());
// 倒序打印TreeMap的key
System.out.printf("倒序打印TreeMap的key:\n%s\n", treeMap.descendingKeySet()); System.out.println("TreeMapDemo.testSubMapAPIs-End");
}
}
TreeMapDemo
TreeMapDemo.testTreeMapOrdinaryAPIs-Begin
打印treeMap:
{one=2, three=5, two=1}
通过Iterator遍历key-value:
one-2
three-5
two-1
TreeMap的键值对个数:3
是否包含key:
是否包含key:one-true
是否包含key:four-false
删除key对应的键值对:
删除key为one的键值对后,treeMap为:
{three=5, two=1}
清空treeMap的节点:
treeMap is empty!
treeMap is not null!
TreeMapDemo.testTreeMapOrdinaryAPIs-End
TreeMapDemo.testNavigableMapAPIs-Begin
打印navigableMap:
{aaa=1, bbb=2, ccc=3, ddd=4}
First key:aaa First entry:aaa=1
Last key:ddd Last entry:ddd=4
Key floor before bbb:bbb bbb=2
Key lower before bbb:aaa aaa=1
Key ceiling after bbb:bbb bbb=2
Key higher after bbb:ccc ccc=3
TreeMapDemo.testNavigableMapAPIs-End
TreeMapDemo.testSubMapAPIs-Begin
打印TreeMap:
{a=1, b=2, c=3, d=4}
打印 key为c节点 前的节点(默认不包含c节点):{a=1, b=2}打印 key为c节点 前的节点(包含c节点):{a=1, b=2, c=3}
打印 key为c节点 前的节点(不包含c节点):{a=1, b=2}
打印 key为c节点 后的节点(默认包含c节点):{c=3, d=4}
打印 key为c节点 后的节点(包含c节点){c=3, d=4}
打印 key为c节点 后的节点(不包含c节点){d=4}
打印 key为a与c节点 之间的节点(默认包含c节点):
{a=1, b=2}
打印 key为a与c节点 之间的节点(包含a、c节点):
{a=1, b=2, c=3}
打印 key为a与c节点 之间的节点(包含a节点):
{a=1, b=2}
打印 key为a与c节点 之间的节点(包含c节点):
{b=2, c=3}
打印 key为a与c节点 之间的节点(不包含a、c节点):
{b=2}
正序打印TreeMap的key:
[a, b, c, d]
倒序打印TreeMap的key:
[d, c, b, a]
TreeMapDemo.testSubMapAPIs-End
TreeMapDemo 运行结果
2.TreeMap遍历使用Demo:
import org.springframework.util.StringUtils; import java.util.*; /**
* @author nana
* @date 2019/2/23
*/
public class TreeMapIteratorTest { public static void main(String[] args) {
// 创建treeMap对象
TreeMap treeMap = treeMapTest(); // 通过entrySet()遍历TreeMap的节点
iteratorTreeMapByEntrySet(treeMap);
// 通过keySet()遍历TreeMap的节点
iteratorTreeMapByKeySet(treeMap);
// 遍历TreeMap的value
iteratorTreeMapByValue(treeMap);
} /**
* 创建treeMap对象
* @return
*/
private static TreeMap treeMapTest() {
String key = null;
int keyValue = 0;
Integer value = null;
Random random = new Random();
TreeMap treeMap = new TreeMap();
int i = 0;
while (i < 6) {
// 随机获取[0,50)的整数
keyValue = random.nextInt(50);
key = String.valueOf(keyValue);
value = random.nextInt(10);
// 添加到treeMap中
treeMap.put(key, value);
i++;
}
return treeMap;
} /**
* 通过entrySet()遍历TreeMap的节点
*/
private static void iteratorTreeMapByEntrySet(TreeMap treeMapTest) {
if (StringUtils.isEmpty(treeMapTest)) {
return;
}
// 遍历TreeMap
Iterator iterator = treeMapTest.entrySet().iterator();
System.out.println("通过entrySet()遍历TreeMap的节点:");
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry) iterator.next();
System.out.printf("%s-%s\t", entry.getKey(), entry.getValue());
}
} /**
* 通过keySet()遍历TreeMap的节点
*/
private static void iteratorTreeMapByKeySet(TreeMap treeMapTest) {
if(StringUtils.isEmpty(treeMapTest)) {
return;
}
String key = null;
Integer value = null;
Iterator iterator = treeMapTest.keySet().iterator();
System.out.println("\n通过keySet()遍历TreeMap的节点:");
while (iterator.hasNext()) {
key = (String) iterator.next();
value = (Integer) treeMapTest.get(key);
System.out.printf("%s-%s\t", key, value);
}
} /**
* 遍历TreeMap的value
*/
private static void iteratorTreeMapByValue(TreeMap treeMapTest) {
if (treeMapTest == null) {
return;
}
Collection collection = treeMapTest.values();
Iterator iterator = collection.iterator();
System.out.println("\n遍历TreeMap的value:");
while (iterator.hasNext()) {
System.out.printf("%s\t", iterator.next());
}
} }
TreeMapIteratorTest
通过entrySet()遍历TreeMap的节点:
19-0 2-7 20-1 22-0 34-3
通过keySet()遍历TreeMap的节点:
19-0 2-7 20-1 22-0 34-3
遍历TreeMap的value:
0 7 1 0 3
TreeMapIteratorTest 运行结果
TreeMap实现原理及源码分析之JDK8的更多相关文章
- HashMap实现原理及源码分析之JDK8
继续上回HashMap的学习 HashMap实现原理及源码分析之JDK7 转载 Java8源码-HashMap 基于JDK8的HashMap源码解析 [jdk1.8]HashMap源码分析 一.H ...
- ArrayList实现原理及源码分析之JDK8
转载 ArrayList源码分析 一.ArrayList介绍 Java 集合框架主要包括两种类型的容器: 一种是集合(Collection),存储一个元素集合. 一种是图(Map),存储键/值对映射. ...
- TreeMap实现原理及源码分析
TreeMap是一个有序的key-value集合,基于红黑树(Red-Black tree)实现.该映射根据其键的自然顺序进行排序,或者根据创建时提供的Comparator进行排序. 对于TreeMa ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- ConcurrentHashMap实现原理及源码分析
ConcurrentHashMap实现原理 ConcurrentHashMap源码分析 总结 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对Ha ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- (转)ReentrantLock实现原理及源码分析
背景:ReetrantLock底层是基于AQS实现的(CAS+CHL),有公平和非公平两种区别. 这种底层机制,很有必要通过跟踪源码来进行分析. 参考 ReentrantLock实现原理及源码分析 源 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
随机推荐
- 解决文字和text-decoration:underline下划线重叠问题
一.text-decoration:underline下划线的问题 CSS text-decoration:underline可以给内联文本增加下划线,但是,如果对细节要求较高,就会发现,下划线经常会 ...
- 有 a - b < c 对Java安全性的思考
软件工程中,不论使用哪种开发语言,安全性一直是一个非常棘手却又重要的问题.安全性是软件开发领域永远的主题之一,而且随着互联网的蜂拥发展而带动的新技术的兴起与革命(比如近几年火起来的node.js,py ...
- Linux 调试: systemtap
安装与配置 在ubuntu下直接用apt-get install之后不能正常使用,提示缺少调试信息或者编译探测代码时有问题. 1. 采用官网上的解决方法 2. 可以自己重新编译一次内核,然后再手工编译 ...
- HTML5实现输入密码(六个格子)
我的思路:用六个li充当六个格子,同时将input框隐藏,点击承载六个格子的容器时,使焦点聚焦在input上,可以输入.通过监听input框输入的长度,控制格子内小黑点是否显示,同时用正则替换非数字. ...
- PHP 抽象类实现接口注意事项(含PHP与.Net的区别)
最近在学习Drupal8,看到源码里面一个抽象类BlockBase实现了一个接口BlockPluginInterface,但是并没有实现该接口的所有方法.然后我就不淡定了,因为之前是做.NET的,记忆 ...
- drupal7 hook_validate
原文:function hook_validate function hook_validate($node, $form, &$form_state) { if (isset($node-& ...
- Centos7配置
1.静态ip配置 1.1 cd /etc/sysconfig/network-scripts/ 1.2 vim ifcfg-ens33 (可通过ls查看 一般为第一个) (网关DNS1可以通过V ...
- MySql 缓存查询原理与缓存监控 和 索引监控
MySql缓存查询原理与缓存监控 And 索引监控 by:授客 QQ:1033553122 查询缓存 1.查询缓存操作原理 mysql执行查询语句之前,把查询语句同查询缓存中的语句进行比较,且是按字节 ...
- Pwn with File结构体(二)
前言 本文由 本人 首发于 先知安全技术社区: https://xianzhi.aliyun.com/forum/user/5274 最新版的 libc 中会对 vtable 检查,所以之前的攻击方式 ...
- Java XML SAX 解析注意
版权声明: 欢迎转载,但请保留文章原始出处 作者:GavinCT 出处:http://www.cnblogs.com/ct2011/p/4002738.html 什么时候可以把解析值赋给对象 一般从网 ...