MySQL 大数据量使用limit分页,随着页码的增大,查询效率越低下。
数据表结构
CREATE TABLE `ad_keyword` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`plan_goods_id` int(11) DEFAULT NULL,
`impr_num` int(11) DEFAULT NULL,
`click_num` int(11) DEFAULT NULL,
`total_spend` int(11) DEFAULT NULL,
`pay_gmv` int(11) DEFAULT NULL,
`orders_num` int(11) DEFAULT NULL,
`roi` double DEFAULT NULL,
`clk_rate` double DEFAULT NULL,
`word` varchar(200) DEFAULT NULL,
`date` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `word_index` (`word`),
KEY `date_index` (`date`),
KEY `ad_id_index` (`plan_goods_id`)
) ENGINE=InnoDB AUTO_INCREMENT=127133688 DEFAULT CHARSET=utf8;
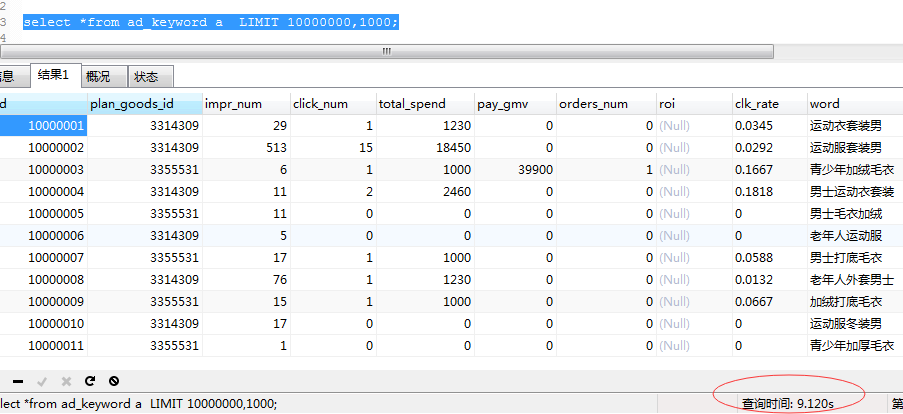
select *from ad_keyword a LIMIT 10000000,1000;
数据库表中数据大概为1.2亿,每次查询都要花上10多秒。而且分页大小是1000.
优化后:
select *from ad_keyword a JOIN (select id from ad_keyword LIMIT 10000000,1000) b on a.id=b.id ;
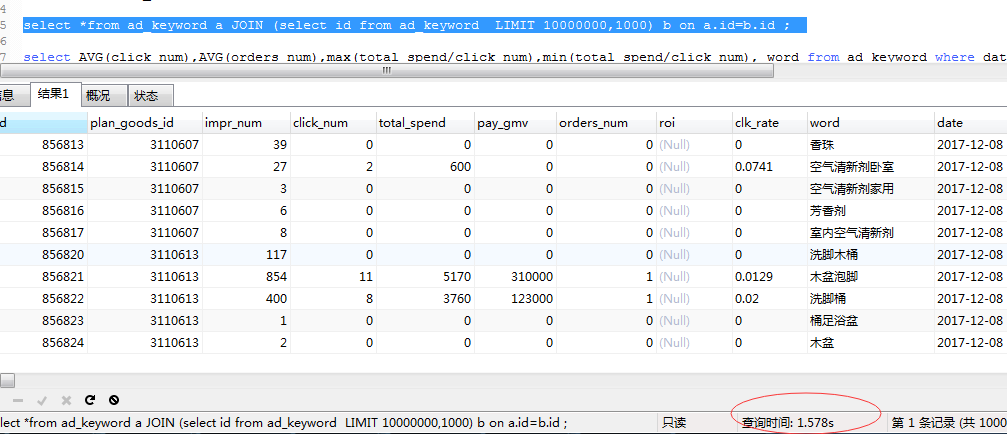
从中我们也能总结出两件事情:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2. 对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列)只用了1.57秒。
MySQL 大数据量使用limit分页,随着页码的增大,查询效率越低下。的更多相关文章
- mysql大数据量使用limit分页,随着页码的增大,查询效率越低下
1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from product limit start, count当起始页较小时,查询没有性能问题 ...
- mysql大数据量下的分页
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- mysql大数据量之limit优化
背景:当数据库里面的数据达到几百万条上千万条的时候,如果要分页的时候(不过一般分页不会有这么多),如果业务要求这么做那我们需要如何解决呢?我用的本地一个自己生产的一张表有五百多万的表,来进行测试,表名 ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL 大数据量快速插入方法和语句优化
MySQL大数据量快速插入方法和语句优化是本文我们主要要介绍的内容,接下来我们就来一一介绍,希望能够让您有所收获! INSERT语句的速度 插入一个记录需要的时间由下列因素组成,其中的数字表示大约比例 ...
- Mysql 大数据量导入程序
Mysql 大数据量导入程序<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" ...
随机推荐
- c++模板函数作为参数的疑惑
为什么22行只能传一个模板函数作为参数,而非模板却编译失败,求解释.
- MongoDB警告信息
更多内容推荐微信公众号,欢迎关注: MongoDB警告信息: 1. WARNING: Using the XFS filesystem is strongly recommended with the ...
- 软件测试工程师人手必备的一只:TOM猫,可以带你装逼带你飞!
Hi,你来了? 其实没有猫,为了让你们好好学习,天天向上!我可真的是拼了命了! 写这篇文章的缘由是,近期有同学经常问到一个这样的问题: 老师,tomcat是啥? 老师,Linux是啥? 老师,xshe ...
- [转]使用 C++11 编写 Linux 多线程程序
前言 在这个多核时代,如何充分利用每个 CPU 内核是一个绕不开的话题,从需要为成千上万的用户同时提供服务的服务端应用程序,到需要同时打开十几个页面,每个页面都有几十上百个链接的 web 浏览器应用程 ...
- 编写高效的JavaScript程序
作者: Addy Osmani 来源: CSDN 发布时间: 2013-01-10 14:15 阅读: 7952 次 推荐: 15 原文链接 [收藏] 英文原文:Writing Fas ...
- AtCoder ARC 090 E / AtCoder 3883: Avoiding Collision
题目传送门:ARC090E. 题意简述: 给定一张有 \(N\) 个点 \(M\) 条边的无向图.每条边有相应的边权,边权是正整数. 小 A 要从结点 \(S\) 走到结点 \(T\) ,而小 B 则 ...
- 彻底搞懂字符编码(unicode,mbcs,utf-8,utf-16,utf-32,big endian,little endian...)[转]
最近有一些朋友常问我一些乱码的问题,和他们交流过程中,发现这个编码的相关知识还真是杂乱不堪,不少人对一些知识理解似乎也有些偏差,网上百度, google的内容,也有不少以讹传讹,根本就是错误的(例如说 ...
- Virut样本取证特征
1.网络特征 ant.trenz.pl ilo.brenz.pl 2.文件特征 通过对文件的定位,使用PEID查看文件区段,如果条件符合增加了7个随机字符区段的文件,则判定为受感染文件. 3.受感染特 ...
- WPF中ListBox的绑定
WPF中列表式控件派生自ItemsControl类,继承了ItemsSource属性.ItemsSource属性可以接收一个IEnumerable接口派生类的实例作为自己的值(所有可被迭代遍历的集合都 ...
- Python之协程(coroutine)
Python之协程(coroutine) 标签(空格分隔): Python进阶 coroutine和generator的区别 generator是数据的产生者.即它pull data 通过 itera ...