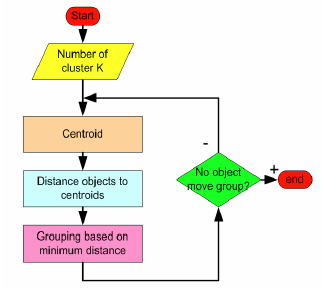
聚类:(K-means)算法
1.归类:
- 聚类(clustering) 属于非监督学习 (unsupervised learning)
- 无类别标记(class label)
2.举例:
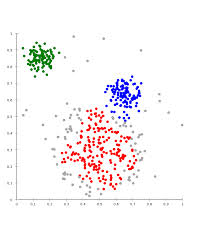
输入:k, data[n];
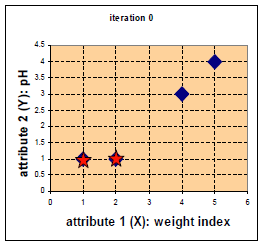
4.2 一个药物分类的例子:

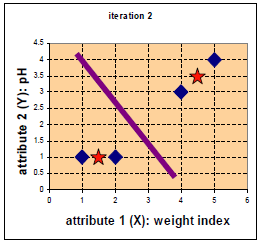
四中药物给予了 weight index 和 pH 两个特征。
在二维坐标系中的分布如下:
D0为第一次迭代,第一行为4个点到c1的距离,第二行为4个点到c2的距离。
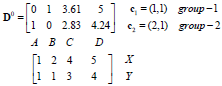
G0为第一次迭代后的归类情况,将各点到c1、c2的距离进行比较,哪个的距离小就为哪一类。
归类如下:c1为第一类,c2、c3、c4为第二类。
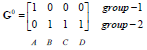
第二类的中心点更新如下:

重新计算中心点如下(星为中心点):(若该类中的点变化,则更新该类的中心点;否则不更新)
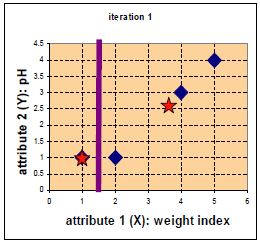
第二次迭代。
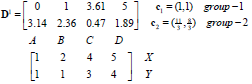
G1为第二次迭代后的归类情况。
归类如下:c1、c2为第一类,c3、c4为第二类。
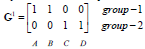
更新第一类、第二类的中心点如下:
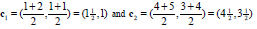

归类没有发生变化(达到终止条件)
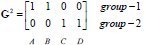
停止。

聚类:(K-means)算法的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 聚类和EM算法——K均值聚类
python大战机器学习——聚类和EM算法 注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
随机推荐
- HDU--4768
题目: Flyer 原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=4768 分析:二分.只需要注意到最多只有一个为奇数,则可以首先求出学生获得的总的传单 ...
- webservice的接口协议(HTTPClient 、RestTemplate HttpURLConnection)
HTTP协议时Internet上使用的很多也很重要的一个协议,越来越多的java应用程序需要通过HTTP协议来访问网络资源. HTTPClient提供的主要功能: 1.实现了所有HTTP的方法(GET ...
- 安装mysql-5.6版本步骤与卸载
官网下载完解压后: 1.环境变量配置Path D:\mysql-5.6.40-winx64\bin(你的mySql5.6的路径到bin)2.找到D:\mysql-5.6.40-winx64文件中的 ...
- python中__init__()、__new__()、__call__()、__del__()用法
关于__new__()的用法参考: http://www.myhack58.com/Article/68/2014/48183.htm 正文: 一.__new__()的用法: __new__()是在新 ...
- python操作mongo脚本
#!/usr/bin/python# -*- coding: utf-8 -*- import sysimport osimport jsonfrom pymongo import MongoClie ...
- Redis学习二:Redis入门介绍
一.入门概述 1.是什么 Redis:REmote DIctionary Server(远程字典服务器) 是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key/value)分布式内 ...
- 【Swift】UIAlertController使用
func clickButton1(){ 创建uialertcontroller var alertCtl : UIAlertController = UIAlertController(title: ...
- [转载]WebStorm快捷键操作
http://www.cnblogs.com/yangjinjin/archive/2013/01/30/2883172.html 1. ctrl + shift + n: 打开工程中的文件,目的是打 ...
- soj1166. Computer Transformat(dp + 大数相加)
1166. Computer Transformat Constraints Time Limit: 1 secs, Memory Limit: 32 MB Description A sequenc ...
- R爬虫实战1(学习)—基于RVEST包
这里用Hadley Wickham开发的rvest包.再次给这位矜矜业业开发各种好用的R包的大神奉上膝盖. 查阅资料如下: rvest的github rvest自身的帮助文档 rvest + CSS ...