Python 下载网络mp4视频资源
最近着迷化学, 特别是古代的冶炼技术,感叹古人的聪明。




春秋时期的炼铁方法是块炼铁,即在较低的冶炼温度下,将铁矿石固态还原获得海绵铁,再经锻打成的铁块。冶炼块炼铁,一般采用地炉、平地筑炉和竖炉3种。铁矿石在温度较高的炼铁炉中高温还原并渗碳,得到含碳达到3~4%的液态生铁。战国初期,我国已掌握了脱碳、热处理技术方法,发明了韧性铸铁。
在中国,钢铁的总产量在唐代年产已达到1200吨,宋朝为4700吨,明朝最多达到4万吨。在13世纪,中国是世界上最大的铁的生产国和消费国,直到17世纪仍保持着这一领先地位。从汉代到明朝,中国人不仅在数量上处于领先地位,而且还拥有世界上最先进的钢铁冶炼技术。
铸铁脱碳钢 将含碳3~4%的低硅铸铁器在氧化气氛中加热,在适当条件下,特别是厚度不大的情况下,可以避免石墨的形成。早期炼铁温度较低,含硅量低,石墨析出较慢,有利于脱碳,使制造韧性铸铁的工艺发展成为铸铁脱碳成钢的方法。这种钢称为铸铁脱碳钢,这类钢板可加工成的铁镞、环首刀。
炒钢 向熔化的生铁鼓风,同时进行搅拌促使生铁中的碳氧化。用这种方法可将生铁制成熟铁,再经过渗碳锻打成钢。也可有控制地把生铁含碳量炒到需要的程度,再锻制成钢制品。这种钢中含有的硅酸铁夹杂物成分比较一致而数量较少。炒钢技术始于西汉末年,到东汉已相当普及。江苏出土新莽残剑,徐州出土建初二年(77)五十炼钢剑,山东临沂苍山出土的永初六年(112)三十炼钢刀等所用的原料都属于这一类型。曹操(155~220)在《内诫令》提到“百炼利器”,孙权(182~252)有以“百炼”命名的宝刀。初步可以认为百炼钢是用炒钢反复叠打变形,细化晶粒和夹杂物而成的,甚至可以用不同含碳钢材复合组成。炼数大致相当于反复折叠锻打后最后的层数。炼数增多,表明加工量加大,晶粒和夹杂进一步细化,质量提高。炒钢技术的发明是炼钢史上的一次革命。
来源:http://wenku.baidu.com/view/7c9bd28d84868762caaed5ed.html
哎! 就在查找古人是如何冶炼金属、铸造钱币、分离金属元素时,找到了这个大连理工大学讲的“化学与社会”公开课。讲的很有调理,让读者很容易理解,越看越觉的这个公开课是一个经典课程,想收藏页面怕以后链接会失效,所以决定把这个经典的公开课下载下来。
那么问题来了,下载网页嵌入的flash 视频,不是容易的事。试了网上好多视频下载插件(DownLoad Helper 、 VDownLoad嗅探器、flv视频下载、ImovieBox)也么有分析出网页的链接视频。好吧,我使用F12 调试网页工具查看网络响应,发现有type=video/mp4,然后另存为就可以了,但问题是课程有近100个,不可能一个个打开链接,查看网页Network点击视频让其加载出type=video/mp4 类型,再另存为。这样太麻烦了。开动脑筋想用程序直接把视频下载链接分析出来,然后保存在本地。
1. 获取链接地址
查看:http://ptr.chaoxing.com/course/2533204.html 源码,课程的list写在了clas=“p20” ul里面的li标签列表中
通过PyQuery可以获取所有课程的视频播放地址

d = self.pq('http://ptr.chaoxing.com/course/2533204.html')
DomTree = d('.p20 ul li a')
for my_div in DomTree.items():
URL = 'http://ptr.chaoxing.com' + my_div.attr('href') # 课时detail URL
l = my_div.find('.l').html() # 课时章节NO
r = my_div.find('.r').html() # 课时Name
self.LessonList.append({'url': URL, "name": l + r})
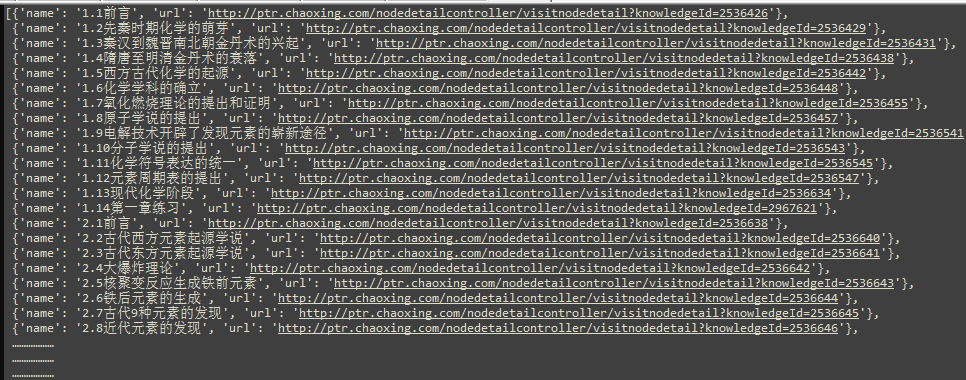
2. 分析下载地址
打开一个课程视频播放时,都会XHR请求加载一个链接,该链接的内容是:

然而我们发现,每一个视频地址页面都会请求一个类似于这样的地址:http://ptr.chaoxing.com/ananas/status/************?k=&_dc=1476770383911
该地址返回一个带有视频mp4路径的Json格式字符串。其中filename为当前视频课程的名称,http为(standard)标准清晰视频 sd.mp4, httphd为(high)高清视频 hd.mp4
进一步的分析我们发现,在该地址请求之前有一个类型为Document的html加载出页面内容区域的html flash播放器
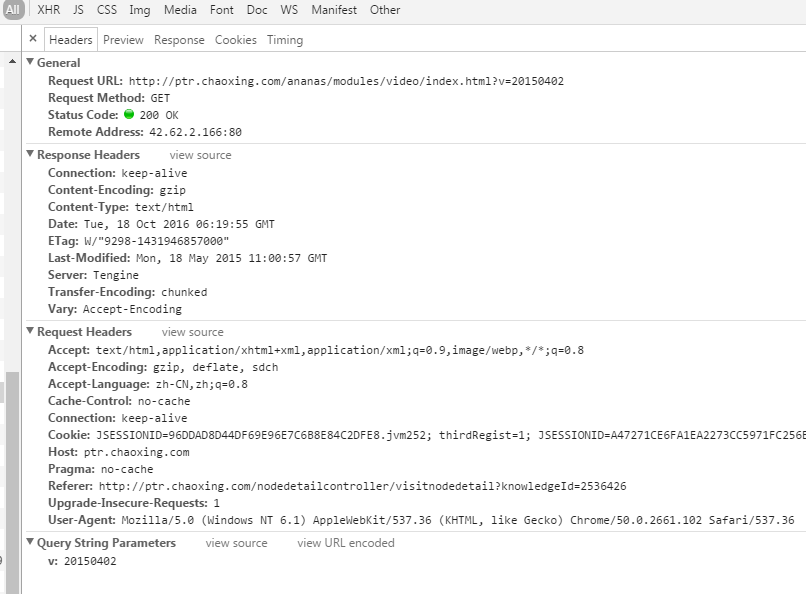
当这个播放器加载完成通过all-classes.js?v=20141027:1的Ajax请求http://ptr.chaoxing.com/ananas/status/************?k=&_dc=***。查看网页源代码,查找status后的这一串字符串发现这个字符串应该是视频播放的objectID

在iframe标签的data属性里面。试着复制一个视频的objectID去模拟请求http://ptr.chaoxing.com/ananas/status/************发现居然成功了!不知道此方法是否也使用其他flash视频下载。
这样下载课程视频的思路就出来了:在第一步获取下载链接,通过每一个视频页面源码中的objectID去请求http://ptr.chaoxing.com/ananas/status/************ 获取下载地址。然后下载视频教程。so easy!
3. 下载视频
通过上一步分析地址,已经知道获取flash视频objectID并Ajax 请求http://ptr.chaoxing.com/ananas/status/************ 就能获取视频地址。这一步我们就下载视频。
通过PyQuery 获取视频页面中的objectID
def getVideo(self, url):
'''
获取视频
'''
d = self.pq(url)
DomTree = d("iframe")
jsonData = DomTree.attr('data')
objectid = json.loads(jsonData)['objectid'] # 获取下载资源视频的对象
downloadUrl = self.pq('http://ptr.chaoxing.com/ananas/status/' + objectid) # 获取下载资源的URL
jsonData = json.loads(downloadUrl.html())['httphd'] # 在这里,我们要下载的是高清视频
return jsonData
在视频下载中遇到了些小问题,可参考:https://www.zhihu.com/question/41132103
完整代码:
# -*- coding: UTF8 -*-
from pyquery import PyQuery as pq
import sys, os
import json
import requests
from contextlib import closing class SaveVideo():
LessonList = [] def __init__(self):
pass # 获取课时的列表
def getLesson(self):
try:
# 该网站请求时必须带上User-Agent
d = self.pq('http://ptr.chaoxing.com/course/2533204.html')
DomTree = d('.p20 ul li a')
for my_div in DomTree.items():
URL = 'http://ptr.chaoxing.com' + my_div.attr('href') # 课时detail URL
l = my_div.find('.l').html() # 课时章节NO
r = my_div.find('.r').html() # 课时Name
self.LessonList.append({'url': URL, "name": l + r})
except Exception as e:
print(e) if (len(self.LessonList) > 0):
if not os.path.exists('./Video'):
os.makedirs('./Video') for lesson in self.LessonList:
video = self.getVideo(lesson['url'])
if video:
self.downloadVideo(video, lesson['name']) print('完成下载!!!') def getVideo(self, url):
'''
获取视频
'''
d = self.pq(url)
DomTree = d("iframe")
jsonData = DomTree.attr('data')
video=''
try:
objectid = json.loads(jsonData)['objectid'] # 获取下载资源视频的对象
downloadUrl = self.pq('http://ptr.chaoxing.com/ananas/status/' + objectid) # 获取下载资源的URL
video = json.loads(downloadUrl.html())['httphd'] # 在这里,我们要下载的是高清视频
except:
pass
return video def pq(self, url, headers=None):
'''
将PyQuery 请求写成方法
'''
d = pq(url=url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'})
return d def downloadVideo(self, url, file_name=''):
'''
下载视频
:param url: 下载url路径
:return: 文件
'''
with closing(requests.get(url, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
file_D='./Video/' + file_name + '.mp4'
if(os.path.exists(file_D) and os.path.getsize(file_D)==content_size):
print('跳过'+file_name)
else:
progress = ProgressBar(file_name, total=content_size, unit="KB", chunk_size=chunk_size, run_status="正在下载",fin_status="下载完成")
with open(file_D, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
progress.refresh(count=len(data)) '''
下载进度
'''
class ProgressBar(object):
def __init__(self, title, count=0.0, run_status=None, fin_status=None, total=100.0, unit='', sep='/',
chunk_size=1.0):
super(ProgressBar, self).__init__()
self.info = "[%s] %s %.2f %s %s %.2f %s"
self.title = title
self.total = total
self.count = count
self.chunk_size = chunk_size
self.status = run_status or ""
self.fin_status = fin_status or " " * len(self.statue)
self.unit = unit
self.seq = sep def __get_info(self):
# 【名称】状态 进度 单位 分割线 总数 单位
_info = self.info % (
self.title, self.status, self.count / self.chunk_size, self.unit, self.seq, self.total / self.chunk_size,
self.unit)
return _info def refresh(self, count=1, status=None):
self.count += count
# if status is not None:
self.status = status or self.status
end_str = "\r"
if self.count >= self.total:
end_str = '\n'
self.status = status or self.fin_status
print(self.__get_info(), end=end_str) if __name__ == '__main__':
C = SaveVideo()
C.getLesson()
sys.exit()
通过pyinstaller打包
import sys if __name__ == '__main__':
from PyInstaller import __main__
params = ['-F','-c','--noupx', '--icon=favicon.ico', 'save.py']
__main__.run(params)
查看:


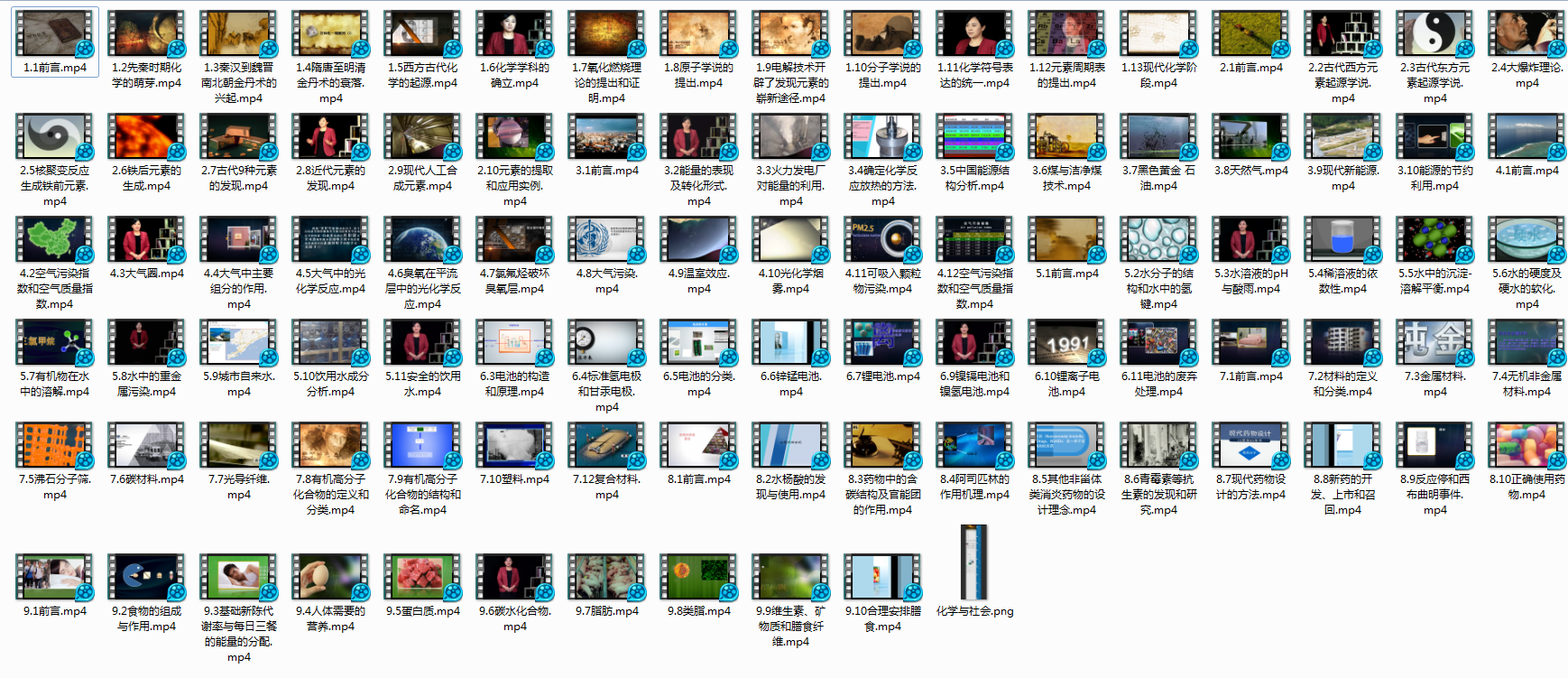

4:分享课程视频
已经将视频打包分享到云盘中,有兴趣的可以在这 下载
Python 下载网络mp4视频资源的更多相关文章
- python下载网络文件
python下载网络文件 制作人:全心全意 下载图片 #!/usr/bin/python #-*- coding: utf-8 -*- import requests url = "http ...
- 快速生成网络mp4视频缩略图技术
背景 由于网络原因,在下载视频之前我们往往会希望能够先生成一些视频的缩略图,大致浏览视频内容,再确定是否应花时间下载.如何能够快速得到视频多个帧的缩略图的同时尽量少的下载视频的内容,是一个值得研究的问 ...
- 手把手教你用 Python 下载手机小视频
今天为大家介绍使用 mitmproxy 这个抓包工具如何监控手机上网,并且通过抓包,把我们想要的数据下载下来. 启动 mitmproxy 首先我们通过执行命令 mitmweb 启动mitmproxy, ...
- python爬取快手视频 多线程下载
就是为了兴趣才搞的这个,ok 废话不多说 直接开始. 环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为htt ...
- Python 爬虫实例(13) 下载 m3u8 格式视频
Python requests 下载 m3u8 格式 视频 最近爬取一个视频网站,遇到 m3u8 格式的视频需要下载. 抓包分析,视频文件是多个 ts 文件,什么是 ts文件,请去百度 ...
- You-Get 一键下载全网视频资源
下载视频 无论是单纯的下载视频收藏,还是以便离线收看,都离不开“下载”,好的工具让你把注意力更好的放在视频的本身,而不用考虑要如何下载视频.下载视频从来不乏方法,之前也介绍了下载 Youtube ...
- 不用 qlv 格式转换成 mp4 - 优雅的下载腾讯视频(mp4 格式)
不用 qlv 格式转换成 mp4 - 优雅的下载腾讯视频(mp4 格式) 问题描述: 朋友说离线腾讯视频是 qlv 格式的,只能使用腾讯视频软件打开.让我帮忙想想办法,能不能将 qlv 格式转换成 m ...
- 使用原生node.js搭建HTTP服务器,支持MP4视频、图片传输,支持下载rar文件
前言 如何安装node.js,如何搭建一个简易的http服务器我这里就不再赘述了,不懂的同学可以先去学习一下.当然了,我写的也就属于简易版的增强版,大家有什么高见的欢迎提出,然后进入正题. 目录结构 ...
- [Python] 使用Python 3 下载麦子学院视频
本文基于Python 3,下载麦子学院的视频课程. 本项目只是针对某个具体课程的链接,去寻找该课程所有课时的视频链接并进行下载. 整个项目是非常简单的. 主要涉及的Python: 网络相关:reque ...
随机推荐
- leggere la nostra recensione del primo e del secondo
La terra di mezzo in trail running sembra essere distorto leggermente massima di recente, e gli aggi ...
- Opera 浏览器各版本下载地址
新版本下载地址: 正式分支: http://get.opera.com/ftp/pub/opera/desktop/ beta分支:http://get.opera.com/ftp/pub/opera ...
- zabbix监控Java 8080端口
linux下端口和服务是对应的,Java进程启动时默认监听8080端口,如果服务挂掉则8080端口就没有了. lsof -i:8080 端口,如果没有任何的输出,说明该端口不在工作. 想在zabbix ...
- ASP.MVC时间类型json数据处理
服务端返回DateTime属性如果用自带的json方法返回的数据如下: 有2种办法解决一种是采用服务端解决方案,一种是使用前端解决方案 1.前端解决方案 第一步:对Date进行扩展 // 对Date的 ...
- ThinkPHP的URL访问
url访问 http://www.kancloud.cn/manual/thinkphp5/118012 ThinkPHP5.0在没有启用路由的情况下典型的URL访问规则是: http://serve ...
- 【转载】跟随 Web 标准探究DOM -- Node 与 Element 的遍历
跟随 Web 标准探究DOM -- Node 与 Element 的遍历 这个是 Joyee 2014年更新的,可能是转战github缘故,一年多没有跟新了.这篇感觉还挺全面,就转载过来,如以前文章一 ...
- eclipse启动tomcat, http://localhost:8080无法访问
原地址 症状: tomcat在eclipse里面能正常启动,而在浏览器中访问http://localhost:8080/不能访问,且报404错误.同时其他项目页面也不能访问. 关闭eclipse里面的 ...
- jQuery EasyUI Combobox 无法获取属性 options 的值: 对象为 null 或未定义
错误的写法: $('#combobox1').combobox({ valueField: 'id', textField: 'text',data:[{id:1,text:'蚂蚁小羊'}]}); 正 ...
- (总结)隐藏PHP版本与PHP基本安全设置
为了安全起见,最好还是将PHP版本隐藏,以避免一些因PHP版本漏洞而引起的攻击. 1.隐藏PHP版本就是隐藏 “X-Powered-By: PHP/5.2.13″ 这个信息. 方法很简单:编辑php. ...
- 移动端浏览器body的overflow:hidden并没有什么作用
今天突然遇到一个问题,使用li模拟select,但是碰到一个很尴尬的问题,给body加了overflow:hidden,但是body并没有禁止滚动条,滚动条依旧顺滑. <!DOCTYPE htm ...