【一】,python简单爬虫实现
一:
1.获取当前页的课程名称,地址:https://www.ichunqiu.com/courses/webaq
2.选取其中一门课程名称查看源代码:
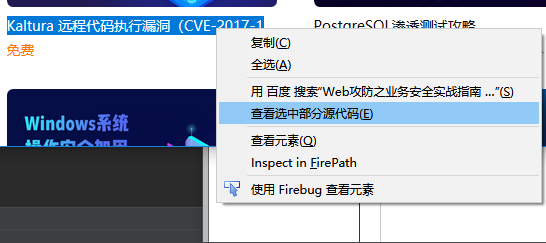
代码如下:
<p class="coursename" title="Kaltura 远程代码执行漏洞(CVE-2017-14143)" onclick="javascript:window.open
3.正则表达式获取课程名称:
#coding=utf-8 import re html = ''' <!DOCTYPE html> <html> #此处为需要爬去页面的源代码 </html> ''' title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html) print (title)
执行结果如下:页面所以课程名称获取到
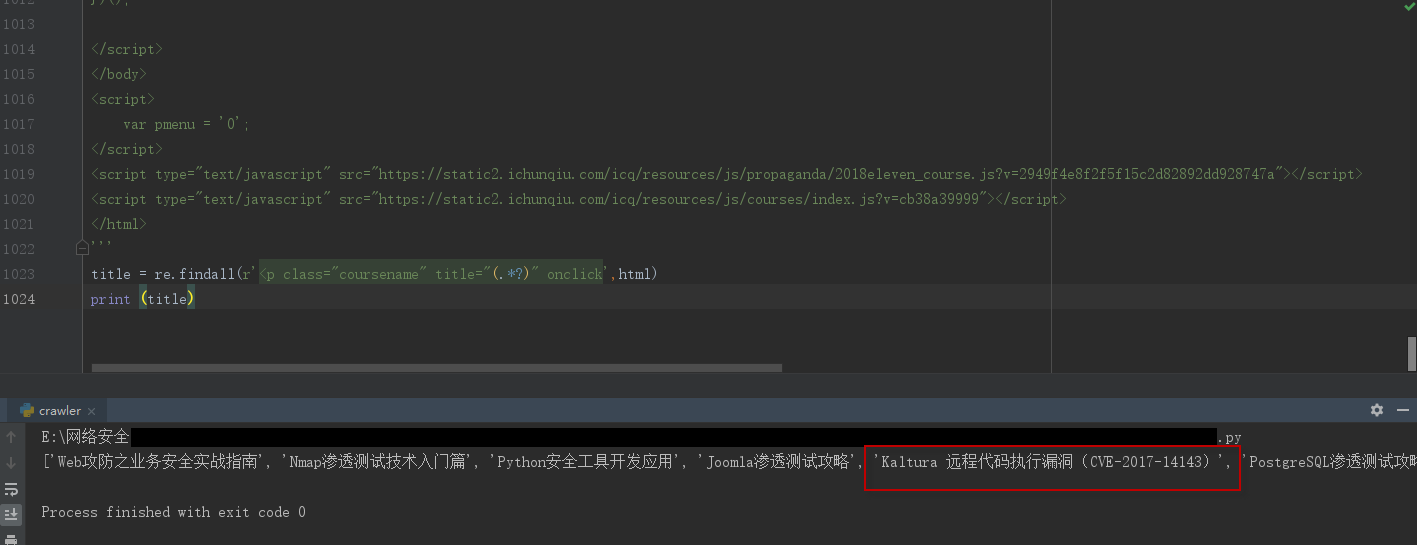
遍历:
#coding=utf-8
import re
html = '''
<!DOCTYPE html>
<html>
#此处为需要爬去页面的源代码
</html>
'''
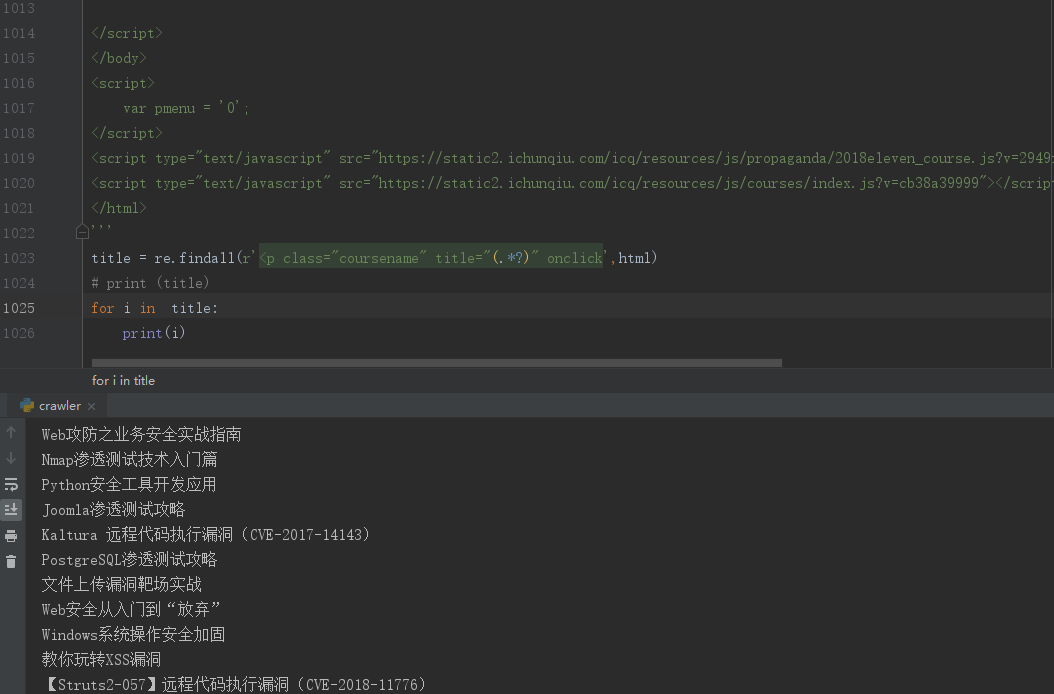
title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html)
# print (title)
for i in title:
print(i)
效果如下:
二:urllib使用
(注:此处python为3.7,与2.x有点区别)
定制请求头:urllib.urlopen() 下载文件:urllib.urlretrieve()
1.向www.baidu.com发起请求:
import urllib.request #导入urllib和urllib2库
url = urllib.request.urlopen('http://www.baidu.com') #定义一个地址
r = url.read() #用urlib向百度发起请求
print (r)#查看发起请求的内容
结果如下:

2.下载百度图片:
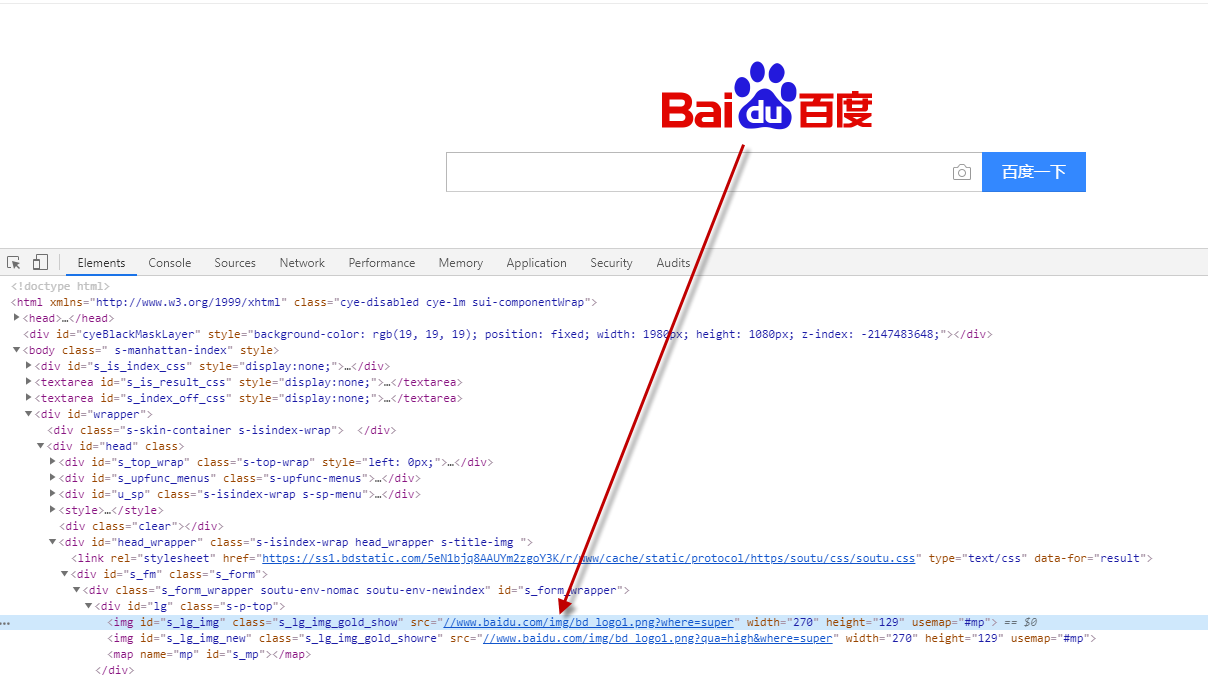
图片地址如下:
https://www.baidu.com/img/bd_logo1.png?where=super
代码:
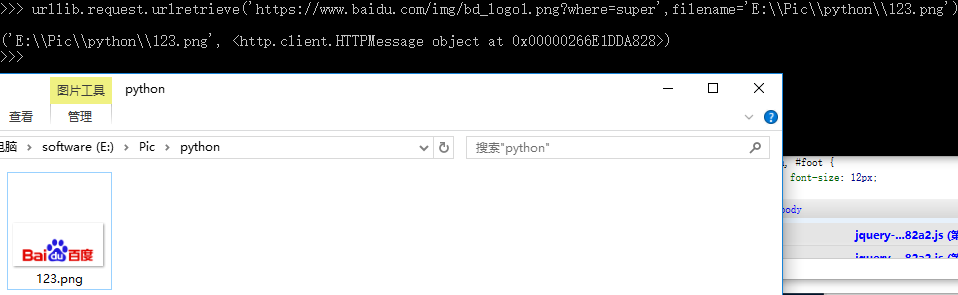
urllib.request.urlretrieve('https://www.baidu.com/img/bd_logo1.png?where=super',filename='E:\\Pic\\python\\123.png')
效果如下,图片下载成功:
三:requests
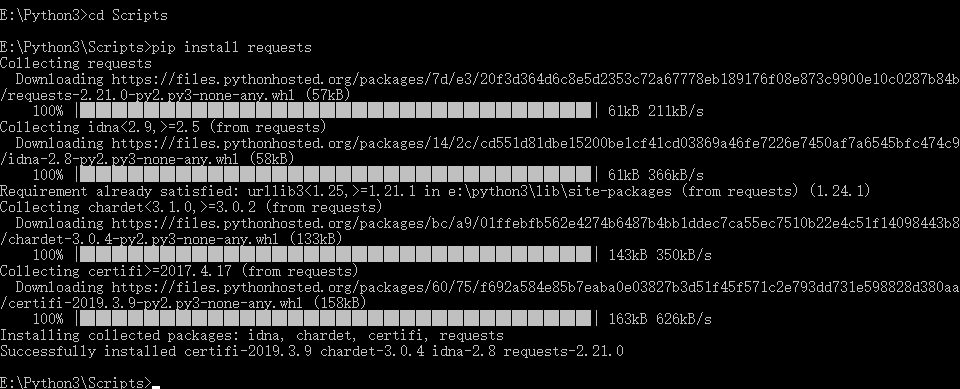
1.window 下requests安装:
查看python路径:

下载requests:
pip install requests
示例:向url发起get请求
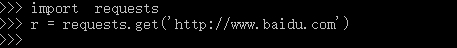
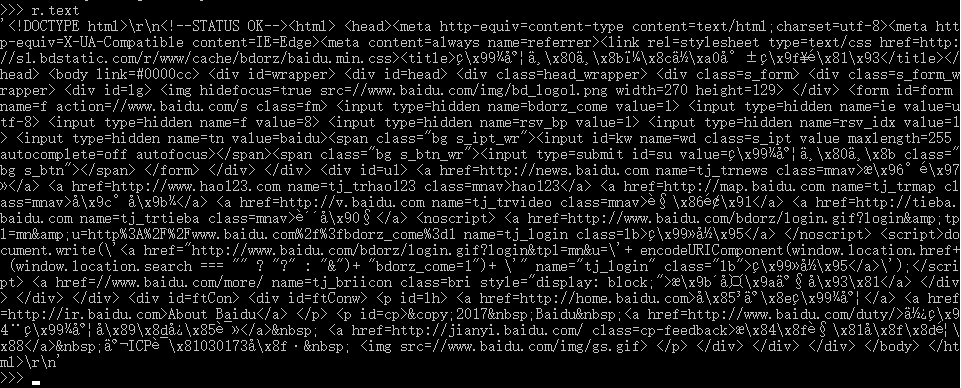
查看响应内容:
方法1:
响应内容 r.test
方法2:
二进制响应内容>>> print (r.content) 或 r.content
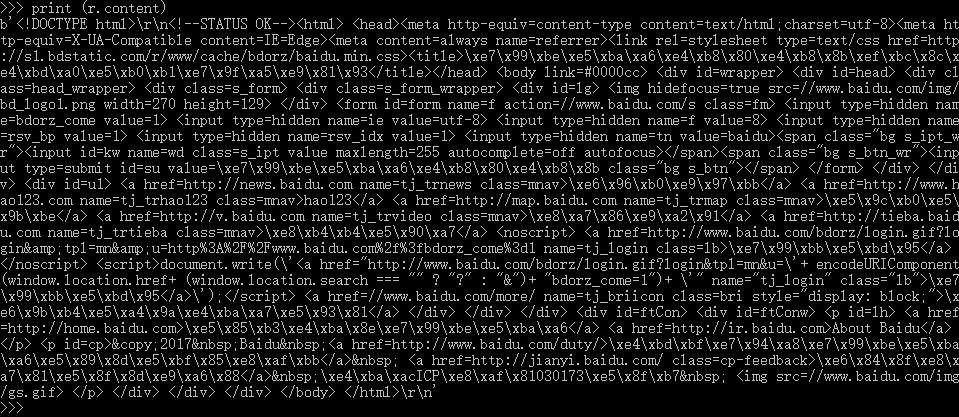
定制请求头:
url = 'http://www.baidu.con'
headers = {'content-type':'application/json'}
r = requests.get(url,headers=headers)
查看状态码:
r.status_code

查看响应头:
r.headers

查看Cookies:
r.cookies

timeout设置超时:
>>> requests.get('http://www.baidu.com',timeout=0.001)


【一】,python简单爬虫实现的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
随机推荐
- mongodb的学习-2-简介
http://www.runoob.com/mongodb/mongodb-intro.html 什么是MongoDB ? MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系 ...
- python3 unittest框架失败重跑加截图支持python2,python3
github源码地址下载:https://github.com/GoverSky/HTMLTestRunner_cn.git 解压文件后取出/HTMLTestRunner_cn.py文件丢进C:\Py ...
- PAT乙级1016
1016 部分A+B (15 分) 正整数 A 的“DA(为 1 位整数)部分”定义为由 A 中所有 DA 组成的新整数 PA.例如:给定 A=3862767,DA=6,则 ...
- 删除iptables nat 规则
删除FORWARD 规则: iptables -nL FORWARD --line-numberiptables -D FORWARD 1 删除一条nat 规则 删除SNAT规则 iptables ...
- 倒计数锁存器(CountDown Latch)和 CyclicBarrier(同步屏障)
倒计数锁存器(CountDown Latch)是异常性障碍,允许一个或多个线程等待一个或者多个其他线程来做某些事情. public static long time(Executor executor ...
- 用javascript制作2048游戏的思路(原创若 转载请附上本链接)
一.项目已上传至github,地址:https://github.com/forjuan/2048game 二.学习了javascript基础后,想要捣鼓点东西做,做了一个自己以前很爱玩的2048游戏 ...
- Linux—echo命令
echo命令的功能是在屏幕上显示一段文字,起到一个提示作用,常用在脚本语言和批处理文件中来在标准输出或者文件中显示一行文本或者字符串. 命令格式:echo [选项] 字符串 选项参数: -n:不在最后 ...
- Hibernate第三天——表间关系与级联操作
第三天,我们来使用Hibernate进行表之间一对多 多对多关系的操作: 这里我们先利用两个例子进行表关系的回顾: 一对多(重点): 例如分类和商品的关系,一个分类多个商品,一个商品属于一个分类 CR ...
- JavaWeb基础—上传与下载
1.上传(不能使用BaseServlet): 上传的作用,略 上传的要求(对表单和Servlet都有要求): 1.必须使用表单,而不能是超链接,method="post" 文件明显 ...
- 如何搭建openvpn
一.什么是openvpn Openvpn是一款基于openssl的开源vpn软件,它可以很好的运行在linux及windows各发行版本中,它的核心技术是虚拟网卡,其实它更像是一个底层的网卡驱动软件, ...