【pyhon】理想论坛爬虫1.08
#------------------------------------------------------------------------------------
# 理想论坛爬虫1.08,用于爬取主贴再爬子贴,数据存到文件里,再由insertDB.py读取插DB
# 增加同网址访问五次异常后退出机制
# 2018年4月27日
#------------------------------------------------------------------------------------
from bs4 import BeautifulSoup
import requests
import threading
import re
import time
import datetime
import os
import json
import colorama
from colorama import Fore, Back, Style
colorama.init()
user_agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
headers={'User-Agent':user_agent}
# 存储数据文件的目录
folder=""
# 主帖数组
topics=[]
#------------------------------------
# 在论坛页中寻找主贴
# pageUrl:论坛页url
#------------------------------------
def findTopics(pageUrl):
print("\n开始读取页面"+pageUrl+"的帖子");
try:
rsp=requests.get(pageUrl,headers=headers)
rsp.encoding = 'gb18030' #解决中文乱码问题的关键
soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='gb2312')
for tbodys in soup.find_all('tbody'):
pageCount=1
url='none'
title='none'
for spans in tbodys.find_all('span',class_="forumdisplay"):
for link in spans.find_all('a'):
if link and link.get("href"):
url="http://www.55188.com/"+link.get("href")
title=link.text
for spans in tbodys.find_all('span',class_="threadpages"):
for link in spans.find_all('a'):
pageCount=link.text
if url!='none' and title!='none':
topic={'pageCount':pageCount,'url':url,'title':title}
#print("topic="+str(topic))
topics.append(topic)
#print("读取页面"+pageUrl+"的帖子完毕");
except Exception as e:
log("findTopics出现异常:"+str(e),'red')
#------------------------------------
# 以不同颜色在控制台输出文字
# pageUrl:论坛页url
#------------------------------------
def log(text,color):
if color=='red':
print(Fore.RED + text+ Style.RESET_ALL)
elif color=='green':
print(Fore.GREEN + text+ Style.RESET_ALL)
elif color=='yellow':
print(Fore.YELLOW + text+ Style.RESET_ALL)
else:
print(text)
#------------------------------------
# 找到并保存帖子的细节
# index:序号,url:地址,title:标题
#------------------------------------
def saveTopicDetail(index,url,title):
infos=[] # 找到的子贴信息
tried=0; # 尝试次数
while(len(infos)==0):
try:
rsp=requests.get(url,headers=headers)
rsp.encoding = 'gb18030' #解决中文乱码问题的关键
soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='gb2312')
session = requests.session()
session.keep_alive = False
for divs in soup.find_all('div',class_="postinfo"):
# 用正则表达式将多个空白字符替换成一个空格
RE = re.compile(r'(\s+)')
line=RE.sub(" ",divs.text)
arr=line.split(' ')
arrLength=len(arr)
if arrLength==7:
info={'楼层':arr[1],
'作者':arr[2].replace('只看:',''),
'日期':arr[4],
'时间':arr[5],'title':title,'url':url}
infos.append(info)
elif arrLength==8:
info={'楼层':arr[1],
'作者':arr[2].replace('只看:',''),
'日期':arr[5],
'时间':arr[6],'title':title,'url':url}
infos.append(info)
#存文件
filename=folder+"/"+str(index)+'.json'
with open(filename,'w',encoding='utf-8') as fObj:
json.dump(infos,fObj)
except Exception as e:
log("saveTopicDetail访问"+url+"时出现异常:"+str(e),'red')
time.sleep(5) # 如果出现异常,休息五秒后再试
tried=tried+1
if(tried>4):
log("尝试5次仍无法访问:"+url+",只得跳过此页",'yellow')
break
continue
#------------------------------------
# 入口函数
# start:起始页,end:终止页
#------------------------------------
def main(start,end):
# 创建目录
currTime=time.strftime('%H_%M_%S',time.localtime(time.time()))
global folder
folder="./"+currTime
os.makedirs(folder)
print("目录"+folder+"创建完成")
# 获取主贴
print('\n将从以下页面获取主贴:');
for i in range(start,end+1):
pageUrl='http://www.55188.com/forum-8-'+str(i)+'.html' # 这个页是论坛页,即第1页,第2页等
findTopics(pageUrl);
n=len(topics)
log("共读取到:"+str(n)+"个主贴",'green')
# 获取主贴及其子贴
finalTopics=[]
index=0
for topic in topics:
end=int(topic['pageCount'])+1
title=topic['title']
for i in range(1,end):
pattern='-(\d+)-(\d+)-(\d+)'
newUrl=re.sub(pattern,lambda m:'-'+m.group(1)+'-'+str(i)+'-'+m.group(3),topic['url'])
#print(newUrl)
newTopic={'index':index,'url':newUrl,'title':title}
finalTopics.append(newTopic)
index=index+1
n=len(finalTopics)
log("共读取到:"+str(n)+"个帖子",'green')
# 遍历finalTopics
for newTopic in finalTopics:
saveTopicDetail(newTopic['index'],newTopic['url'],newTopic['title']);
# 开始
main(1,10)
用得到的数据再用以下数据进行一次统计:
# 对发帖时间进行统计
import re
import pymysql
# 入口函数
def main():
dic={':0}
conn=pymysql.connect(host=',db='test',charset='utf8')
cs=conn.cursor()
cs.execute("select * from topic0426")
results = cs.fetchall()
for row in results:
ttime=row[4]
hour=ttime.split(':')[0]
dic[hour]=dic[hour]+1
conn.close()
print(dic)
# 开始
main()
输出为:
C:\Users\horn1\Desktop\python\28>python sum.py
{': 10736}
C:\Users\horn1\Desktop\python\28>
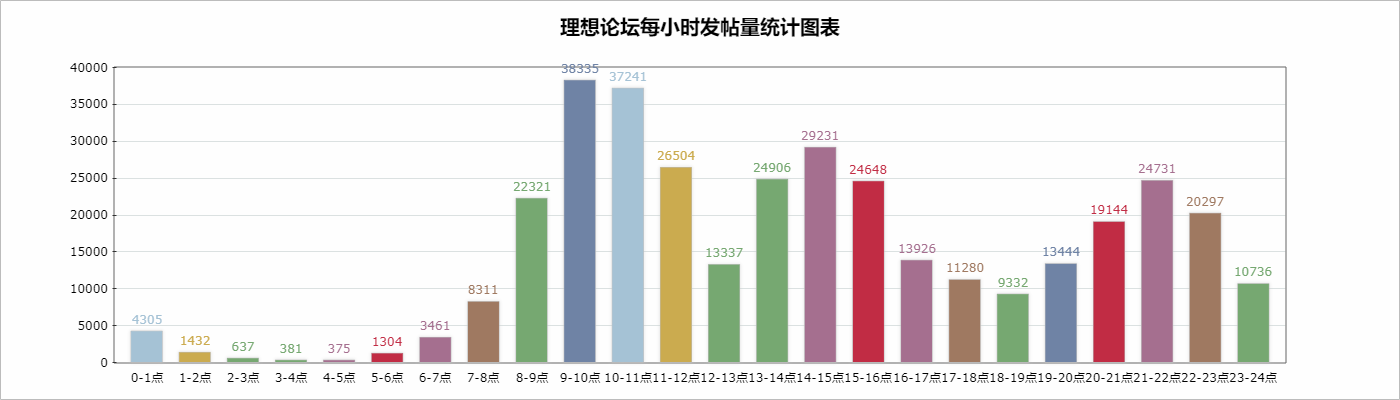
统计图生成代码为:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title> New Document </title>
<meta name="Generator" content="EditPlus">
<meta name="Author" content="">
<meta name="Keywords" content="">
<meta name="Description" content="">
</head>
<script src="ichart.1.2.min.js"></script>
<body>
<div id='canvasDiv'></div>
</body>
</html>
<script type="text/javascript">
<!--
var dic={'00': 4305, '01': 1432, '02': 637, '03': 381, '04': 375, '05': 1304, '06': 3461, '07': 8311, '08': 22321, '09': 38335, '10': 37241, '11': 26504, '12': 13337, '13': 24906, '14': 29231, '15': 24648, '16': 13926, '17': 11280, '18': 9332, '19': 13444, '20': 19144, '21': 24731, '22': 20297, '23': 10736};
//定义数据
var data = [
{name : '0-1点', value : dic['00'],color:'#a5c2d5'},
{name : '1-2点', value : dic['01'],color:'#cbab4f'},
{name : '2-3点', value : dic['02'],color:'#76a871'},
{name : '3-4点', value : dic['03'],color:'#76a871'},
{name : '4-5点', value : dic['04'],color:'#a56f8f'},
{name : '5-6点', value : dic['05'],color:'#c12c44'},
{name : '6-7点', value : dic['06'],color:'#a56f8f'},
{name : '7-8点', value : dic['07'],color:'#9f7961'},
{name : '8-9点', value : dic['08'],color:'#76a871'},
{name : '9-10点', value : dic['09'],color:'#6f83a5'},
{name : '10-11点',value : dic['10'],color:'#a5c2d5'},
{name : '11-12点',value : dic['11'],color:'#cbab4f'},
{name : '12-13点',value : dic['12'],color:'#76a871'},
{name : '13-14点',value : dic['13'],color:'#76a871'},
{name : '14-15点',value : dic['14'],color:'#a56f8f'},
{name : '15-16点',value : dic['15'],color:'#c12c44'},
{name : '16-17点',value : dic['16'],color:'#a56f8f'},
{name : '17-18点',value : dic['17'],color:'#9f7961'},
{name : '18-19点',value : dic['18'],color:'#76a871'},
{name : '19-20点',value : dic['19'],color:'#6f83a5'},
{name : '20-21点',value : dic['20'],color:'#c12c44'},
{name : '21-22点',value : dic['21'],color:'#a56f8f'},
{name : '22-23点',value : dic['22'],color:'#9f7961'},
{name : '23-24点',value : dic['23'],color:'#76a871'}
];
$(function(){
var chart = new iChart.Column2D({
render : 'canvasDiv',//渲染的Dom目标,canvasDiv为Dom的ID
data: data,//绑定数据
title : '理想论坛每小时发帖量统计图表',//设置标题
width : 1400,//设置宽度,默认单位为px
height : 400,//设置高度,默认单位为px
shadow:true,//激活阴影
shadow_color:'#c7c7c7',//设置阴影颜色
coordinate:{//配置自定义坐标轴
scale:[{//配置自定义值轴
position:'left',//配置左值轴
start_scale:0,//设置开始刻度为0
end_scale:10000,//设置结束刻度为26
scale_space:5000,//设置刻度间距
listeners:{//配置事件
parseText:function(t,x,y){//设置解析值轴文本
return {text:t+""}
}
}
}]
}
});
//调用绘图方法开始绘图
chart.draw();
});
//-->
</script>
以上全体代码可以在这里下载:
https://files.cnblogs.com/files/xiandedanteng/lixiang108_20180427.rar
【pyhon】理想论坛爬虫1.08的更多相关文章
- 【python】理想论坛爬虫1.08
#------------------------------------------------------------------------------------ # 理想论坛爬虫1.08, ...
- 【pyhon】理想论坛爬虫1.05版,将读取和写DB分离成两个文件
下午再接再厉仿照Nodejs版的理想帖子爬虫把Python版的也改造了下,但美中不足的是完成任务的线程数量似乎停滞在100个左右,让人郁闷.原因还待查. 先把代码贴出来吧,也算个阶段性成果. 爬虫代码 ...
- 【pyhon】理想论坛爬虫1.07 退出问题,乱码问题至此解决,只是目前速度上还是遗憾点
在 https://www.cnblogs.com/mengyu/p/6759671.html 的启示下,解决了乱码问题,在此向作者表示感谢. 至此,困扰我几天的乱码问题和退出问题都解决了,只是处理速 ...
- 【python】理想论坛爬虫长贴版1.00
理想论坛有些长贴,针对这些长贴做统计可以知道某ID什么时段更活跃. 爬虫代码为: #---------------------------------------------------------- ...
- 【nodejs】理想论坛帖子下载爬虫1.08
//====================================================== // 理想论坛帖子下载爬虫1.09 // 使用断点续传模式,因为网络传输会因各种原因中 ...
- 【Nodejs】理想论坛帖子爬虫1.01
用Nodejs把Python实现过的理想论坛爬虫又实现了一遍,但是怎么判断所有回调函数都结束没有好办法,目前的spiderCount==spiderFinished判断法在多页情况下还是会提前中止. ...
- 【Python】理想论坛帖子读取爬虫1.04版
1.01-1.03版本都有多线程争抢DB的问题,线程数一多问题就严重了. 这个版本把各线程要添加数据的SQL放到数组里,等最后一次性完成,这样就好些了.但乱码问题和未全部完成即退出现象还在,而且速度上 ...
- 【nodejs】理想论坛帖子下载爬虫1.07 使用request模块后稳定多了
在1.06版本时,访问网页采用的时http.request,但调用次数多以后就问题来了. 寻找别的方案时看到了https://cnodejs.org/topic/53142ef833dbcb076d0 ...
- 【python】理想论坛帖子爬虫1.06
昨天认识到在本期同时起一百个回调/线程后程序会崩溃,造成结果不可信. 于是决定用Python单线程操作,因为它理论上就用主线程跑不会有问题,只是时间长点. 写好程序后,测试了一中午,210个主贴,11 ...
随机推荐
- 【贪心】Codeforces Round #480 (Div. 2) C. Posterized
题意:让你对[0,255]这个序列任意划分成一些不重叠的子段,每个子段的大小不超过K.给你n个不超过255的数,让你将每个数替换成它所在子段的任意一个元素,使得最终这个n个数的序列的字典序最小. p[ ...
- 简单的php自定义错误日志
平时经常看php的错误日志,很少有机会去自己动手写日志,看了王健的<最佳日志实践>觉得写一个清晰明了,结构分明的日志还是非常有必要的. 在写日志前,我们问问自己:为什么我们有时要记录自定义 ...
- DataTable初次使用笔记
概述:DataTable是一个jQuery插件,用于生成HTML表格,功能很强大. 使用: 使用DataTable需要引入jQuery,因为他是基于jQuery的插件,然后引入DataTable的js ...
- VC 操作 EXCEL---插入工作表(Insert.Sheet)方法
看到的资料 http://bbs.csdn.net/topics/198565 自己总结一下 //插入到nIndex工作表之前 void InsertSheet(int nIndex) { sheet ...
- SPOJ 10232. Distinct Primes
Arithmancy is Draco Malfoy's favorite subject, but what spoils it for him is that Hermione Granger i ...
- Codeforces Round #260 (Div. 2) B. Fedya and Maths
B. Fedya and Maths time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- 一个java高级工程师的进阶之路【转】
宏观方面 一. JAVA.要想成为JAVA(高级)工程师肯定要学习JAVA.一般的程序员或许只需知道一些JAVA的语法结构就可以应付了.但要成为JAVA(高级) 工程师,您要对JAVA做比较深入的研究 ...
- 使用matplotlib的示例:调整字体-设置colormap和colorbar
使用matplotlib的示例:调整字体-设置colormap和colorbar # -*- coding: utf-8 -*- #********************************** ...
- UVa11187
莫勒定理,证明如下: 请结合下图看代码: #include <iostream> #include <math.h> #include <iomanip> usin ...
- patch补丁命令 P1 P0 P2
http://fancyxinyu.blog.163.com/blog/static/1823213662013719115245699/ http://blog.chinaunix.net/uid- ...