kafka生产消费原理笔记
一、什么是kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
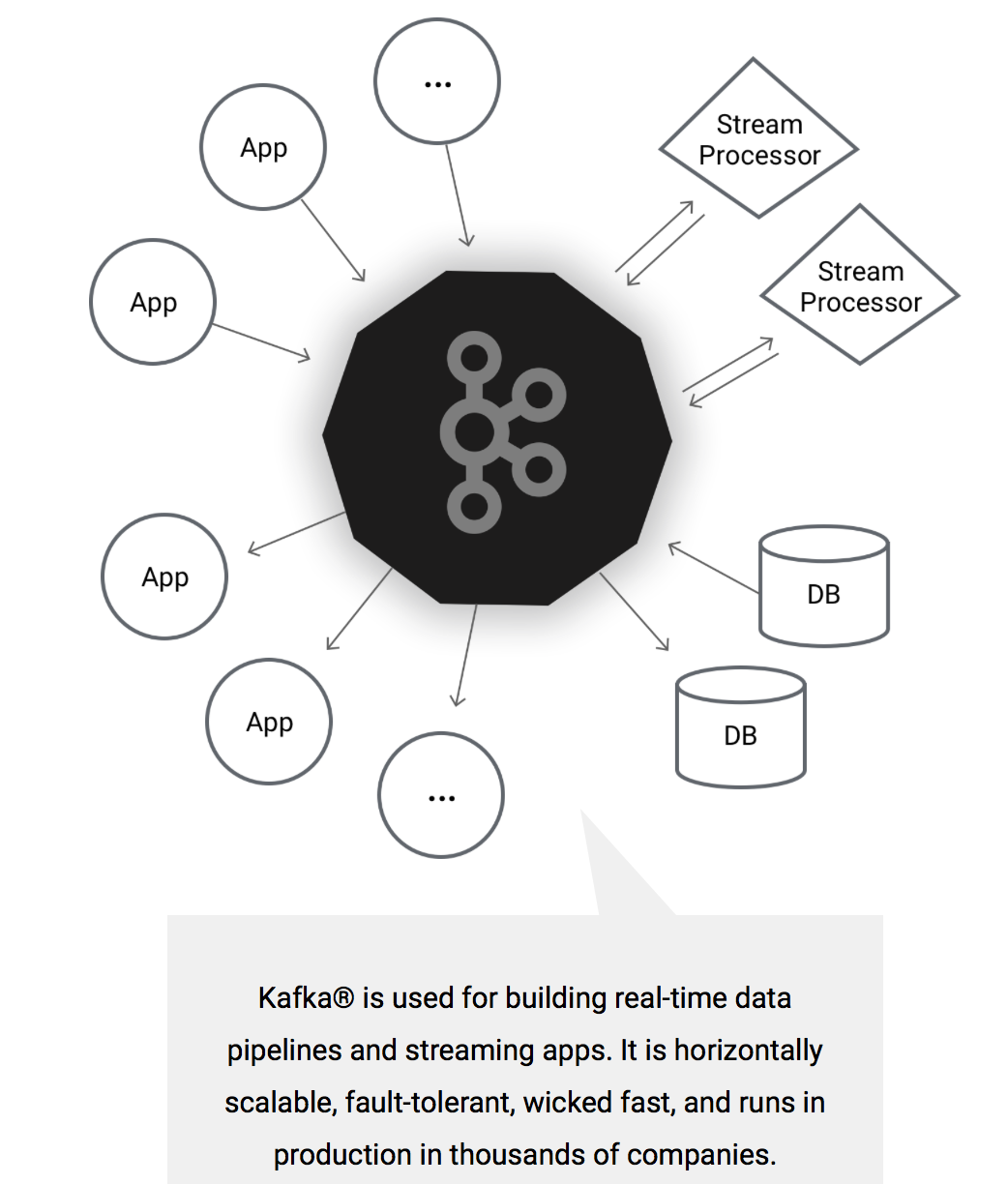
二、kafka与其他消息中间件
| Redis |
|
| RabbitMQ |
|
| ZeroMQ |
|
| ActiveMQ |
|
| Kafka/Jafka |
|
三、kafka解决了什么问题
Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台,因为以下特性而著名:
- 提供Pub/Sub方式的海量消息处理。
- 以高容错的方式存储海量数据流。
- 保证数据流的顺序。
常用场景:
四、kafka基本概念
Message(消息):传递的数据对象,主要由四部分构成:offset(偏移量)、key、value、timestamp(插入时间); 其中offset和timestamp在kafka集群中产生,key/value在producer发送数据的时候产生Broker(代理者):Kafka集群中的机器/服务被成为broker, 是一个物理概念。
Topic(主题):维护Kafka上的消息类型被称为Topic,是一个逻辑概念。
Partition(分区):具体维护Kafka上的消息数据的最小单位,一个Topic可以包含多个分区;Partition特性:
ordered & immutable。(在数据的产生和消费过程中,不需要关注数据具体存储的Partition在那个Broker上,只需要指定Topic即可,由Kafka负责将数据和对应的Partition关联上)
Producer(生产者):负责将数据发送到Kafka对应Topic的进程
Consumergroup:各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group )中的一个consumer(consumer 线程)消费,如果一个message可以被多个consumer(consumer 线程)消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的同一个consumer group下的consumer thread来处理,除非再启动一个新的consumer group。所以如果想同时对一个topic做消费的话,启动多个consumer group就可以了,但是要注意的是,这里的多个consumer的消费都必须是顺序读取partition里面的message,新启动的consumer默认从partition队列最头端最新的地方开始阻塞的读message。它不能像AMQ那样可以多个BET作为consumer去互斥的(for update悲观锁)并发处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观所(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许同一个consumer group下的一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。如果想多个不同的业务都需要这个topic的数据,起多个consumer group就好了,大家都是顺序的读取message,offsite的值互不影响。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
当启动一个consumer group去消费一个topic的时候,无论topic里面有多个少个partition,无论我们consumer group里面配置了多少个consumer thread,这个consumer group下面的所有consumer thread一定会消费全部的partition;即便这个consumer group下只有一个consumer thread,那么这个consumer thread也会去消费所有的partition。因此,最优的设计就是,consumer group下的consumer thread的数量等于partition数量,这样效率是最高的。
同一partition的一条message只能被同一个Consumer Group内的一个Consumer消费。不能够一个consumer group的多个consumer同时消费一个partition。
一个consumer group下,无论有多少个consumer,这个consumer group一定回去把这个topic下所有的partition都消费了。当consumer group里面的consumer数量小于这个topic下的partition数量的时候,如下图groupA,groupB,就会出现一个conusmer thread消费多个partition的情况,总之是这个topic下的partition都会被消费。如果consumer group里面的consumer数量等于这个topic下的partition数量的时候,如下图groupC,此时效率是最高的,每个partition都有一个consumer thread去消费。当consumer group里面的consumer数量大于这个topic下的partition数量的时候,如下图GroupD,就会有一个consumer thread空闲。因此,我们在设定consumer group的时候,只需要指明里面有几个consumer数量即可,无需指定对应的消费partition序号,consumer会自动进行rebalance。
多个Consumer Group下的consumer可以消费同一条message,但是这种消费也是以o(1)的方式顺序的读取message去消费,,所以一定会重复消费这批message的,不能向AMQ那样多个BET作为consumer消费(对message加锁,消费的时候不能重复消费message)
Consumer: Consumer处理partition里面的message的时候是o(1)顺序读取的。所以必须维护着上一次读到哪里的offsite信息。high level API,offset存于Zookeeper中,low level API的offset由自己维护。一般来说都是使用high level api的。Consumer的delivery gurarantee,默认是读完message先commmit再处理message,autocommit默认是true,这时候先commit就会更新offsite+1,一旦处理失败,offsite已经+1,这个时候就会丢message;也可以配置成读完消息处理再commit,这种情况下consumer端的响应就会比较慢的,需要等处理完才行。
一般情况下,一定是一个consumer group处理一个topic的message。Best Practice是这个consumer group里面consumer的数量等于topic里面partition的数量,这样效率是最高的,一个consumer thread处理一个partition。如果这个consumer group里面consumer的数量小于topic里面partition的数量,就会有consumer thread同时处理多个partition(这个是kafka自动的机制,我们不用指定),但是总之这个topic里面的所有partition都会被处理到的。。如果这个consumer group里面consumer的数量大于topic里面partition的数量,多出的consumer thread就会闲着啥也不干,剩下的是一个consumer thread处理一个partition,这就造成了资源的浪费,因为一个partition不可能被两个consumer thread去处理。所以我们线上的分布式多个service服务,每个service里面的kafka consumer数量都小于对应的topic的partition数量,但是所有服务的consumer数量只和等于partition的数量,这是因为分布式service服务的所有consumer都来自一个consumer group,如果来自不同的consumer group就会处理重复的message了(同一个consumer group下的consumer不能处理同一个partition,不同的consumer group可以处理同一个topic,那么都是顺序处理message,一定会处理重复的。一般这种情况都是两个不同的业务逻辑,才会启动两个consumer group来处理一个topic)。
五、消息如何生产消费
官网的图解可以直观看出消费概览
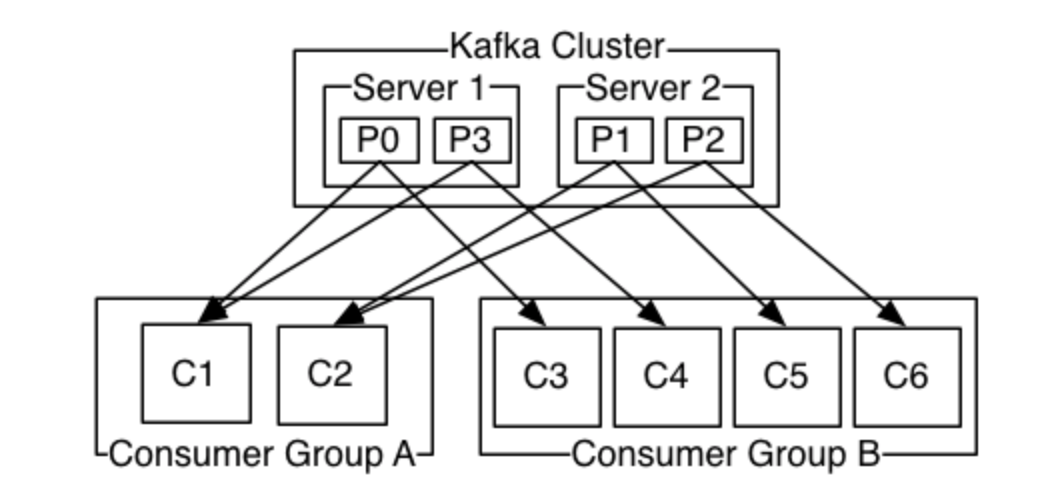
需要注意如下几点:
1)一组(类)消息通常由某个topic来归类,我们可以把这组消息“分发”给若干个分区(partition),每个分区的消息各不相同;
2)每个分区都维护着他自己的偏移量(Offset),记录着该分区的消息此时被消费的位置;
3)一个消费线程可以对应若干个分区,但一个分区只能被具体某一个消费线程消费;
4)group.id用于标记某一个消费组,每一个消费组都会被记录他在某一个分区的Offset,即不同consumer group针对同一个分区,都有“各自”的偏移量。
六、消息投递
一个消息如何算投递成功,Kafka提供了三种模式:
- 第一种是啥都不管,发送出去就当作成功,这种情况当然不能保证消息成功投递到broker;
- 第二种是Master-Slave模型,只有当Master和所有Slave都接收到消息时,才算投递成功,这种模型提供了最高的投递可靠性,但是损伤了性能;
- 第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型
消息在broker上的可靠性,因为消息会持久化到磁盘上,所以如果正常stop一个broker,其上的数据不会丢失;但是如果不正常stop,可能会使存在页面缓存来不及写入磁盘的消息丢失,这可以通过配置flush页面缓存的周期、阈值缓解,但是同样会频繁的写磁盘会影响性能,又是一个选择题,根据实际情况配置。
消息消费的可靠性,Kafka提供的是“At least once”模型,因为消息的读取进度由offset提供,offset可以由消费者自己维护也可以维护在zookeeper里,但是当消息消费后consumer挂掉,offset没有即时写回,就有可能发生重复读的情况,这种情况同样可以通过调整commit offset周期、阈值缓解,甚至消费者自己把消费和commit offset做成一个事务解决,但是如果你的应用不在乎重复消费,那就干脆不要解决,以换取最大的性能。
- Partition ack:当ack=1,表示producer写partition leader成功后,broker就返回成功,无论其他的partition follower是否写成功。当ack=2,表示producer写partition leader和其他一个follower成功的时候,broker就返回成功,无论其他的partition follower是否写成功。当ack=-1[parition的数量]的时候,表示只有producer全部写成功的时候,才算成功,kafka broker才返回成功信息。这里需要注意的是,如果ack=1的时候,一旦有个broker宕机导致partition的follower和leader切换,会导致丢数据。
七、副本
.png)

分析过程分为以下4个步骤:
- topic中partition存储分布
- partiton中文件存储方式 (partition在linux服务器上就是一个目录(文件夹))
- partiton中segment文件存储结构
- 在partition中如何通过offset查找message
通过上述4过程详细分析,我们就可以清楚认识到kafka文件存储机制的奥秘。
八、zookeeper
kafka leader
Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
Kafka的核心是日志文件,日志文件在集群中的同步是分布式数据系统最基础的要素。
如果leaders永远不会down的话我们就不需要followers了!一旦leader down掉了,需要在followers中选择一个新的leader.但是followers本身有可能延时太久或者crash,所以必须选择高质量的follower作为leader.必须保证,一旦一个消息被提交了,但是leader down掉了,新选出的leader必须可以提供这条消息。大部分的分布式系统采用了多数投票法则选择新的leader,对于多数投票法则,就是根据所有副本节点的状况动态的选择最适合的作为leader.Kafka并不是使用这种方法。
Kafka动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中了,才回通知外部这个消息已经被提交了。因此这个集合中的任何一个节点随时都可以被选为leader.ISR在ZooKeeper中维护。ISR中有f+1个节点,就可以允许在f个节点down掉的情况下不会丢失消息并正常提供服。ISR的成员是动态的,如果一个节点被淘汰了,当它重新达到“同步中”的状态时,他可以重新加入ISR.这种leader的选择方式是非常快速的,适合kafka的应用场景。
一个邪恶的想法:如果所有节点都down掉了怎么办?Kafka对于数据不会丢失的保证,是基于至少一个节点是存活的,一旦所有节点都down了,这个就不能保证了。
实际应用中,当所有的副本都down掉时,必须及时作出反应。可以有以下两种选择:
1. 等待ISR中的任何一个节点恢复并担任leader。
2. 选择所有节点中(不只是ISR)第一个恢复的节点作为leader.
这是一个在可用性和连续性之间的权衡。如果等待ISR中的节点恢复,一旦ISR中的节点起不起来或者数据都是了,那集群就永远恢复不了了。如果等待ISR意外的节点恢复,这个节点的数据就会被作为线上数据,有可能和真实的数据有所出入,因为有些数据它可能还没同步到。Kafka目前选择了第二种策略,在未来的版本中将使这个策略的选择可配置,可以根据场景灵活的选择。
这种窘境不只Kafka会遇到,几乎所有的分布式数据系统都会遇到。
分布式
kafka使用zookeeper来存储一些meta信息,并使用了zookeeper watch机制来发现meta信息的变更并作出相应的动作(比如consumer失效,触发负载均衡等)
Broker node registry: 当一个kafka broker启动后,首先会向zookeeper注册自己的节点信息(临时znode),同时当broker和zookeeper断开连接时,此znode也会被删除.
Broker Topic Registry: 当一个broker启动时,会向zookeeper注册自己持有的topic和partitions信息,仍然是一个临时znode.
Consumer and Consumer group: 每个consumer客户端被创建时,会向zookeeper注册自己的信息;此作用主要是为了"负载均衡".一个group中的多个consumer可以交错的消费一个topic的所有partitions;简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能考虑,让partition相对均衡的分散到每个consumer上.
Consumer id Registry: 每个consumer都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
Consumer offset Tracking: 用来跟踪每个consumer目前所消费的partition中最大的offset.此znode为持久节点,可以看出offset跟group_id有关,以表明当group中一个消费者失效,其他consumer可以继续消费.
Partition Owner registry: 用来标记partition正在被哪个consumer消费.临时znode。此节点表达了"一个partition"只能被group下一个consumer消费,同时当group下某个consumer失效,那么将会触发负载均衡(即:让partitions在多个consumer间均衡消费,接管那些"游离"的partitions)
当consumer启动时,所触发的操作:
A) 首先进行"Consumer id Registry";
B) 然后在"Consumer id Registry"节点下注册一个watch用来监听当前group中其他consumer的"leave"和"join";只要此znode path下节点列表变更,都会触发此group下consumer的负载均衡.(比如一个consumer失效,那么其他consumer接管partitions).
C) 在"Broker id registry"节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance.
总结:
1) Producer端使用zookeeper用来"发现"broker列表,以及和Topic下每个partition leader建立socket连接并发送消息.
2) Broker端使用zookeeper用来注册broker信息,已经监测partition leader存活性.
3) Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
协调机制
1. 管理broker与consumer的动态加入与离开。(Producer不需要管理,随便一台计算机都可以作为Producer向Kakfa Broker发消息)
3. 维护消费关系及每个partition的消费信息。
九、开发相关
Producers
Producers直接发送消息到broker上的leader partition,不需要经过任何中介或其他路由转发。为了实现这个特性,kafka集群中的每个broker都可以响应producer的请求,并返回topic的一些元信息,这些元信息包括哪些机器是存活的,topic的leader partition都在哪,现阶段哪些leader partition是可以直接被访问的。
Producer客户端自己控制着消息被推送到哪些partition。实现的方式可以是随机分配、实现一类随机负载均衡算法,或者指定一些分区算法。Kafka提供了接口供用户实现自定义的partition,用户可以为每个消息指定一个partitionKey,通过这个key来实现一些hash分区算法。比如,把userid作为partitionkey的话,相同userid的消息将会被推送到同一个partition。
以Batch的方式推送数据可以极大的提高处理效率,kafka Producer 可以将消息在内存中累计到一定数量后作为一个batch发送请求。Batch的数量大小可以通过Producer的参数控制,参数值可以设置为累计的消息的数量(如500条)、累计的时间间隔(如100ms)或者累计的数据大小(64KB)。通过增加batch的大小,可以减少网络请求和磁盘IO的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。
Producers可以异步的并行的向kafka发送消息,但是通常producer在发送完消息之后会得到一个future响应,返回的是offset值或者发送过程中遇到的错误。这其中有个非常重要的参数“acks”,这个参数决定了producer要求leader partition 收到确认的副本个数,如果acks设置数量为0,表示producer不会等待broker的响应,所以,producer无法知道消息是否发送成功,这样有可能会导致数据丢失,但同时,acks值为0会得到最大的系统吞吐量。
若acks设置为1,表示producer会在leader partition收到消息时得到broker的一个确认,这样会有更好的可靠性,因为客户端会等待直到broker确认收到消息。若设置为-1,producer会在所有备份的partition收到消息时得到broker的确认,这个设置可以得到最高的可靠性保证。
Kafka 消息有一个定长的header和变长的字节数组组成。因为kafka消息支持字节数组,也就使得kafka可以支持任何用户自定义的序列号格式或者其它已有的格式如Apache Avro、protobuf等。Kafka没有限定单个消息的大小,但我们推荐消息大小不要超过1MB,通常一般消息大小都在1~10kB之前。
发布消息时,kafka client先构造一条消息,将消息加入到消息集set中(kafka支持批量发布,可以往消息集合中添加多条消息,一次行发布),send消息时,producer client需指定消息所属的topic。
Consumers
Kafka提供了两套consumer api,分为high-level api和sample-api。Sample-api 是一个底层的API,它维持了一个和单一broker的连接,并且这个API是完全无状态的,每次请求都需要指定offset值,因此,这套API也是最灵活的。
在kafka中,当前读到哪条消息的offset值是由consumer来维护的,因此,consumer可以自己决定如何读取kafka中的数据。比如,consumer可以通过重设offset值来重新消费已消费过的数据。不管有没有被消费,kafka会保存数据一段时间,这个时间周期是可配置的,只有到了过期时间,kafka才会删除这些数据。(这一点与AMQ不一样,AMQ的message一般来说都是持久化到mysql中的,消费完的message会被delete掉)
High-level API封装了对集群中一系列broker的访问,可以透明的消费一个topic。它自己维持了已消费消息的状态,即每次消费的都是下一个消息。
High-level API还支持以组的形式消费topic,如果consumers有同一个组名,那么kafka就相当于一个队列消息服务,而各个consumer均衡的消费相应partition中的数据。若consumers有不同的组名,那么此时kafka就相当与一个广播服务,会把topic中的所有消息广播到每个consumer。
High level api和Low level api是针对consumer而言的,和producer无关。
High level api是consumer读的partition的offsite是存在zookeeper上。High level api 会启动另外一个线程去每隔一段时间,offsite自动同步到zookeeper上。换句话说,如果使用了High level api, 每个message只能被读一次,一旦读了这条message之后,无论我consumer的处理是否ok。High level api的另外一个线程会自动的把offiste+1同步到zookeeper上。如果consumer读取数据出了问题,offsite也会在zookeeper上同步。因此,如果consumer处理失败了,会继续执行下一条。这往往是不对的行为。因此,Best Practice是一旦consumer处理失败,直接让整个conusmer group抛Exception终止,但是最后读的这一条数据是丢失了,因为在zookeeper里面的offsite已经+1了。等再次启动conusmer group的时候,已经从下一条开始读取处理了。
Low level api是consumer读的partition的offsite在consumer自己的程序中维护。不会同步到zookeeper上。但是为了kafka manager能够方便的监控,一般也会手动的同步到zookeeper上。这样的好处是一旦读取某个message的consumer失败了,这条message的offsite我们自己维护,我们不会+1。下次再启动的时候,还会从这个offsite开始读。这样可以做到exactly once对于数据的准确性有保证。
借鉴:http://blog.csdn.net/ychenfeng/article/details/74980531
kafka生产消费原理笔记的更多相关文章
- kafka 生产消费原理详解
Kafka日志及Topic数据清理 https://blog.csdn.net/qiaqia609/article/details/78899298 Kafka--Consumer消费者 pastin ...
- Python往kafka生产消费数据
安装 kafka: pip install kafka-python 生产数据 from kafka import KafkaProducer import json ''' 生产者demo 向te ...
- Kafka生产消费API JAVA实现
Maven依赖: <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka- ...
- Kafka 生产消费 Avro 序列化数据
https://unmi.cc/kafka-produce-consume-avro-data/ https://unmi.cc/apache-avro-serializing-deserializi ...
- Python 基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控
基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- Kafka(三)Kafka的高可用与生产消费过程解析
一 Kafka HA设计解析 1.1 为何需要Replication 在Kafka在0.8以前的版本中,是没有Replication的,一旦某一个Broker宕机,则其上所有的Partition数据 ...
- kafka之三:kafka java 生产消费程序demo示例
kafka是吞吐量巨大的一个消息系统,它是用scala写的,和普通的消息的生产消费还有所不同,写了个demo程序供大家参考.kafka的安装请参考官方文档. 首先我们需要新建一个maven项目,然后在 ...
- kafka知识体系-kafka设计和原理分析
kafka设计和原理分析 kafka在1.0版本以前,官方主要定义为分布式多分区多副本的消息队列,而1.0后定义为分布式流处理平台,就是说处理传递消息外,kafka还能进行流式计算,类似Strom和S ...
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
随机推荐
- Arduino智能小车--仅仅是随便一搞
在某宝宝买的智能小车,挺精致的,开心的连接上打印机的线,结果port都没有反应, 查了一下发现是少了驱动,博主用的mac os10.12.3 CH34x_Install_V1.4.pkg 安装好之后我 ...
- Java 8 – Convert a Stream to LIST
Java 8 – Convert a Stream to LIST package com.mkyong.java8; import java.util.List;import java.util.s ...
- MySql(十二):MySql架构设计——可扩展设计的基本原则
一.前言 科技在发展,硬件设备的发展渐渐无法满足应用系统对处理能力的要求.不过,我们还是可以通过改造系统的架构体系,提升系统的扩展能力,通过组合多个低处理能力的硬件设备来达到一个高处理能力的系统,也就 ...
- Android 抓包并通过 Wireshark 分析
分析 Android 中 app 的网络数据交互,需要在 Android 上抓包,常用工具为 tcpdump ,用 tcpdump 生成 Wireshark 识别的 pcap 文件,把 pcap 文件 ...
- 腾讯云服务器 安装fastdfs文件服务器
上篇安装完nginx后,那么这次咱们就来安装fastdfs文件服务器,为何要使用文件服务器,这里不多说了,以前的文章有写过 首先用ftp工具把fastdfs的相关文件上传至腾讯云,如下 首先,安装基本 ...
- Atitti 固化数据库表结构方案
Atitti 固化数据库表结构方案 1. 固化数据库表结的重要意义1 2. 如何固化表结构1 2.1. 向上抽象一层,以动词有目标,以名词为存储对象.1 2.2. 数据类型datatype字段:这个用 ...
- C#整数三种强制类型转换int、Convert.ToInt32()、int.Parse()、string到object 的区别
1.int适合简单数据类型之间的转换,C#的默认整型是int32(不支持bool型); 2.int.Parse(string sParameter)是个构造函数,参数类型只支持string类型; 3. ...
- LoadingController
--local MainSceneConfig = require "res.scripts.configs.MainSceneConfig" -- 暂时添加一个临时配置文件 -- ...
- redhat7.2 安装docker
# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo # sed -i ' ...
- redis使用日志(4):如何让外部服务器访问
开启redis 允许外网IP 访问 在 Linux 中安装了redis 服务,当在客户端通过远程连接的方式连接时,报could not connect错误. 错误的原因很简单,就是没有连接上redis ...