模型融合策略voting、averaging、stacking
原文:https://zhuanlan.zhihu.com/p/25836678
1.voting
对于分类问题,采用多个基础模型,采用投票策略选择投票最多的为最终的分类。
2.averaging
对于回归问题,一方面采用简单平均法,另一方面采用加权平均法,加权平均法的思路:权值可以用排序的方法确定或者根据均方误差确定。
3.stacking
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking。假设我们有3个基模型M1、M2、M3。下面先看一种错误的训练方式:
【1】基模型M1,对训练集train训练,然后用于预测train和test的标签列,分别是P1,T1(对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3):
【2】 分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2:
【3】 再用第二层的模型M4训练train2,预测test2,得到最终的标签列:
Stacking本质上就是这么直接的思路,但是这样肯定是不行的,问题在于P1的得到是有问题的,用整个训练集训练的模型反过来去预测训练集的标签,过拟合是非常非常严重的,因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。我们以2折交叉验证得到P1为例,假设训练集为4行3列:
将其划分为两部分:
,
用traina训练模型M1,然后在trainb上进行预测得到preb3和pred4:
在trainb上训练模型M1,然后在traina上进行预测得到pred1和pred2:
然后把两个预测集进行拼接:
对于测试集T1的得到,有两种方法。注意到刚刚是2折交叉验证,M1相当于训练了2次,所以一种方法是每一次训练M1,可以直接对整个test进行预测,这样2折交叉验证后测试集相当于预测了2次,然后对这两列求平均得到T1。或者直接对测试集只用M1预测一次直接得到T1。P1、T1得到之后,P2、T2、P3、T3也就是同样的方法。理解了2折交叉验证,对于K折的情况也就理解也就非常顺利了。所以最终的代码是两层循环,第一层循环控制基模型的数目,每一个基模型要这样去得到P1,T1,第二层循环控制的是交叉验证的次数K,对每一个基模型,会训练K次最后拼接得到P1,取平均得到T1。
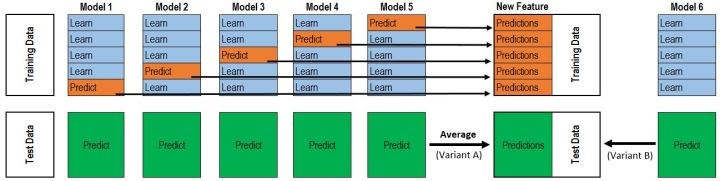
该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次,拼接得到P1,测试集预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。再分析作者的代码也就很清楚了。也就是刚刚提到的两层循环。
模型融合策略voting、averaging、stacking的更多相关文章
- 模型融合之blending和stacking
1. blending 需要得到各个模型结果集的权重,然后再线性组合. """Kaggle competition: Predicting a Biological Re ...
- 深度学习模型融合stacking
当你的深度学习模型变得很多时,选一个确定的模型也是一个头痛的问题.或者你可以把他们都用起来,就进行模型融合.我主要使用stacking和blend方法.先把代码贴出来,大家可以看一下. import ...
- 模型融合——stacking原理与实现
一般提升模型效果从两个大的方面入手 数据层面:数据增强.特征工程等 模型层面:调参,模型融合 模型融合:通过融合多个不同的模型,可能提升机器学习的性能.这一方法在各种机器学习比赛中广泛应用, 也是在比 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
- 谈谈模型融合之一 —— 集成学习与 AdaBoost
前言 前面的文章中介绍了决策树以及其它一些算法,但是,会发现,有时候使用使用这些算法并不能达到特别好的效果.于是乎就有了集成学习(Ensemble Learning),通过构建多个学习器一起结合来完成 ...
- 在Caffe中实现模型融合
模型融合 有的时候我们手头可能有了若干个已经训练好的模型,这些模型可能是同样的结构,也可能是不同的结构,训练模型的数据可能是同一批,也可能不同.无论是出于要通过ensemble提升性能的目的,还是要设 ...
- Gluon炼丹(Kaggle 120种狗分类,迁移学习加双模型融合)
这是在kaggle上的一个练习比赛,使用的是ImageNet数据集的子集. 注意,mxnet版本要高于0.12.1b2017112. 下载数据集. train.zip test.zip labels ...
- 基于sklearn的 BaseEstimator开发接口:模型融合Stacking
转载:https://github.com/LearningFromBest/CMB-credit-card-department-prediction-of-purchasing-behavior- ...
- 成功的GIT开发分支模型和策略
详细图文并茂以及git flow工具解释参考: http://danielkummer.github.io/git-flow-cheatsheet/index.zh_CN.html 原文地址:http ...
随机推荐
- 掌握 javascript 核心概念 最好的教程 系列 之一
链接 新链接 函数优先, 在扫描创建变量阶段, 会先收集函数, 如果前面有同名函数或者变量, 这个新函数会覆盖前面同名的: 而如果这时候是变量, 则不能去覆盖前面已有的值. function test ...
- Unity3D插件-自制小插件、简化代码便于使用(新手至高手进阶必经之路)
Unity3D插件-简化代码.封装功能 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) 1 FindT() ...
- struts2访问ServletAPI方式和获取参数的方式
一.访问ServletAPI的三种方式 方式1:通过让Action类去实现感知接口. 此时项目依赖:servlet-api.jar. ServletRequestAware:感知HttpServlet ...
- ES6必知必会 (三)—— 数组和对象的拓展
数组的扩展 1.拓展运算符('...'),它相当于rest参数的逆运算,用于将一个数组转换为用逗号分隔的参数序列: console.log(...[1, 2, 3]) // 1 2 3 console ...
- java安全性-引用-分层-解耦
Java不支持指针, 一切对内存的访问都必须通过对象的实例变量来实现,这样就防止程序员使用 "特洛伊"木马等欺骗手段访问对象的私有成员 访问一个对象必须通过这个对象的引用 java ...
- nexage video asset tag
video ad can't show InLine must match the example ,and xml content is Case Sensitive https:/ ...
- MySQL--lsblk命令查看块设备
lsblk命令用于列出所有可用块设备的信息,而且还能显示他们之间的依赖关系,但是它不会列出RAM盘的信息.块设备有硬盘,闪存盘,cd-ROM等等. lsblk命令包含在util-linux-ng包中, ...
- Web Js推断键盘出发事件
window.document.onkeydown = disableRefresh; function disableRefresh(evt){ evt = (evt) ? evt : wind ...
- Spring插件3.8.2的安装
主机环境:win8 64bit eclipse版本:4.5.2 MARS 插件版本:Spring Tool Suite3.8.2 安装过程:直接在线安装,没有先在官网把插件下载再安装. 主要步骤: 1 ...
- APP自动化测试各项指标分析
一.内存分析专项 启动App. DDMS->update heap 操作app,点几次GC dump heap hprof-conv转化 MAT分析 二.区分几种内存 VSS- Virtual ...