HashMap、HashTable、ConcurrentHashMap的区别
一、相关概念
1、Map的概念
javadoc中对Map的解释如下:
An objectthat maps keys to values . Amap cannot contain duplicatekeys; each key can map to at most one value.
This interface takes the place of the Dictionary class, which was atotally abstract class rather than an interface.
The Map interface provides three collection views, which allow amap's contents to be viewed as a set of keys, collection of values,or set of key-value mappings.
从上可知,Map用于存储“key-value”元素对,它将一个key映射到一个而且只能是唯一的一个value。
Map可以使用多种实现方式,HashMap的实现采用的是hash表;而TreeMap采用的是红黑树。
2、HashMap
实现了Map接口,实现了将唯一键隐射到特定值上。允许一个NULL键和多个NULL值。非线程安全。
3、HashTable
类似于HashMap,但是不允许NULL键和NULL值,比HashMap慢,因为它是同步的。HashTable是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占。
4、ConcurrentHashMap
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的Hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
JDK1.7的实现
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
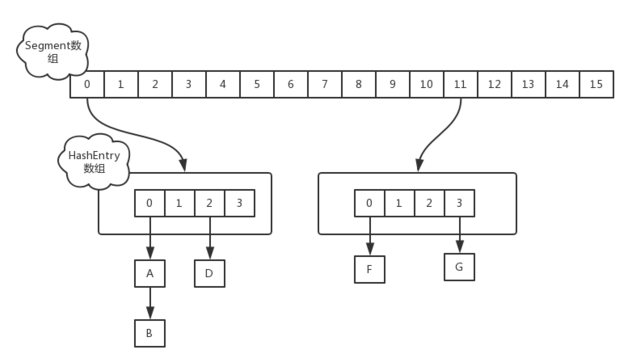
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
JDK1.8的实现
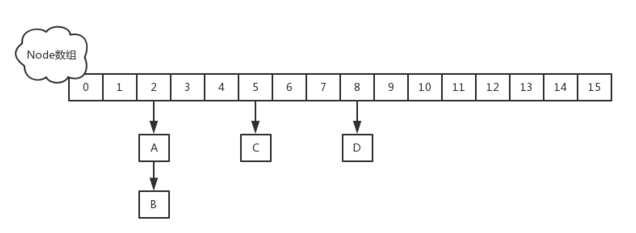
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
二、解决HashMap的线程安全问题
有两种方法可以解决HashMap的线程安全问题:
- Java的
Collections库中的synchronizedMap()方法 - 使用
ConcurrentHashMap
译者注:其实还有第三种方法,使用Hashtable。不过Hashtable是Java 1.1提供的旧有类,从性能上和使用上都不如其他的替代类,因此已经不推荐使用
//Hashtable
Map<String, String> normalMap = new Hashtable<String, String>();
//synchronizedMap
synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
//ConcurrentHashMap
concurrentHashMap = new ConcurrentHashMap<String, String>();
ConcurrentHashMap
- 当你程序需要高度的并行化的时候,你应该使用
ConcurrentHashMap - 尽管没有同步整个Map,但是它仍然是线程安全的
- 读操作非常快,而写操作则是通过加锁完成的
- 在对象层次上不存在锁(即不会阻塞线程)
- 锁的粒度设置的非常好,只对哈希表的某一个key加锁
ConcurrentHashMap不会抛出ConcurrentModificationException,即使一个线程在遍历的同时,另一个线程尝试进行修改。ConcurrentHashMap会使用多个锁
SynchronizedHashMap
- 会同步整个对象
- 每一次的读写操作都需要加锁
- 对整个对象加锁会极大降低性能
- 这相当于只允许同一时间内至多一个线程操作整个Map,而其他线程必须等待
- 它有可能造成资源冲突(某些线程等待较长时间)
SynchronizedHashMap会返回Iterator,当遍历时进行修改会抛出异常
三、 Hashtable 和 HashMap
1、不同点
这两个类主要有以下几方面的不同:
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
这两个类最大的不同在于Hashtable是线程安全的,它的方法是同步了的,可以直接用 在多线程环境中。而HashMap则不是线程安全的。在多线程环境中,需要手动实现同步机制。因此,在Collections类中提供了一个方法返回一个 同步版本的HashMap用于多线程的环境:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<K,V>(m);
}
该方法返回的是一个SynchronizedMap的实例。SynchronizedMap类是定义在Collections中的一个静态内部类。它实现了Map接口,并对其中的每一个方法实现,通过synchronized关键字进行了同步控制。
2. 潜在的线程安全问题
上面提到Collections为HashMap提供了一个并发版本SynchronizedMap。这个版本中的方法都进行了同步,但是这并不等于这个类就一定是线程安全的。在某些时候会出现一些意想不到的结果。
如下面这段代码:
// shm是SynchronizedMap的一个实例
if(shm.containsKey('key')){
shm.remove(key);
}
这段代码用于从map中删除一个元素之前判断是否存在这个元素。这里的 containsKey和reomve方法都是同步的,但是整段代码却不是。考虑这么一个使用场景:线程A执行了containsKey方法返回 true,准备执行remove操作;这时另一个线程B开始执行,同样执行了containsKey方法返回true,并接着执行了remove操作;然 后线程A接着执行remove操作时发现此时已经没有这个元素了。要保证这段代码按我们的意愿工作,一个办法就是对这段代码进行同步控制,但是这么做付出 的代价太大。
在进行迭代时这个问题更改明显。Map集合共提供了三种方式来分别返回键、值、键值对的集合:
Set<K> keySet(); Collection<V> values(); Set<Map.Entry<K,V>> entrySet(); 在这三个方法的基础上,我们一般通过如下方式访问Map的元素:
Iterator keys = map.keySet().iterator();
while(keys.hasNext()){
map.get(keys.next());
}
在这里,有一个地方需要注意的是:得到的keySet和迭代器都是Map中元素的一个“视图”,而不是“副本”。问题也就出现在这里,当一个线程正在迭代Map中的元素时,另一个线程可能正在修改其中的元素。此时,在迭代元素时就可能会抛出ConcurrentModificationException异常。为了解决这个问题通常有两种方法,一是直接返回元素的副本,而不是视图。这个可以通过
集合类的 toArray()方法实现,但是创建副本的方式效率比之前有所降低,特别是在元素很多的情况下;另一种方法就是在迭代的时候锁住整个集合,这样的话效率就更低了。
四、Hashtable 和ConcurrentHashMap
效率低下的HashTable容器
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况 下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞 或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把 锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是 ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据 的时候,其他段的数据也能被其他线程访问。
java5中新增了ConcurrentMap接口和它的一个实现类 ConcurrentHashMap。ConcurrentHashMap提供了和Hashtable以及SynchronizedMap中所不同的锁机 制。Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是 一次锁住一个桶。ConcurrentHashMap默认将hash表分为16个桶,诸如get,put,remove等常用操作只锁当前需要用到的桶。 这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
上面说到的16个线程指的是写线程,而读操作大部分时候都不需要用到锁。只有在size等操作时才需要锁住整个hash表。
在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。
HashMap、HashTable、ConcurrentHashMap的区别的更多相关文章
- HashMap,HashTable,concurrentHashMap,LinkedHashMap 区别
HashMap 不是线程安全的 HashTable,concurrentHashMap 是线程安全 HashTable 底层是所有方法都加有锁(synchronized) 所以操作起来效率会低 con ...
- [Java集合] 彻底搞懂HashMap,HashTable,ConcurrentHashMap之关联.
注: 今天看到的一篇讲hashMap,hashTable,concurrentHashMap很透彻的一篇文章, 感谢原作者的分享. 原文地址: http://blog.csdn.net/zhanger ...
- HashMap, HashTable, CurrentHashMap的区别
转载:http://www.jianshu.com/p/c00308c32de4 HashMap vs ConcurrentHashMap 引入ConcurrentHashMap是为了在同步集合Has ...
- 彻底搞懂HashMap,HashTable,ConcurrentHashMap之关联.
注: 今天看到的一篇讲hashMap,hashTable,concurrentHashMap很透彻的一篇文章, 感谢原作者的分享. 原文地址: http://blog.csdn.net/zhange ...
- HashMap HashTable ConcurrentHashMap
1. Hashtable 和 HashMap (1)区别,这两个类主要有以下几方面的不同:Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽 ...
- 一、基础篇--1.2Java集合-HashMap和ConcurrentHashMap的区别【转】
http://www.importnew.com/28263.html 今天发一篇”水文”,可能很多读者都会表示不理解,不过我想把它作为并发序列文章中不可缺少的一块来介绍.本来以为花不了多少时间的,不 ...
- hashmap,hashTable concurrentHashMap 是否为线程安全,区别,如何实现的
线程安全类 在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的.在jdk1.2之后,就出现许许多多非线程安全的类. 下面是这些线程安全的同步的类: vector:就比arraylist多 ...
- Java集合——HashMap,HashTable,ConcurrentHashMap区别
Map:“键值”对映射的抽象接口.该映射不包括重复的键,一个键对应一个值. SortedMap:有序的键值对接口,继承Map接口. NavigableMap:继承SortedMap,具有了针对给定搜索 ...
- HashTable、HashMap、ConcurrentHashMap的区别
HashTable是做了同步的,HashMap未考虑同步.所以HashMap在单线程情况下效率较高:HashTable在的多线程情况下,同步操作能保证程序执行的正确性. HashMap是非线程安全的, ...
- HashMap/Hashtable/ConcurrentHashMap区别
HashMap:每个隔间都没锁门,有人想上厕所,管理员指给他一个隔间,里面没人的话正常用,里面有人的话把这个人赶出来然后用. 优点,每个人进来不耽误都能用:缺点,每一个上厕所的人都有被中途赶出来的危险 ...
随机推荐
- 安装 SQL SERVER MsiGetProductInfo 无法检索 Product Code 1605错误 解决方案
重装数据库服务器上的SQL SERVER 2008 上遇到了以下问题 标题: SQL Server 安装程序失败. SQL Server 安装程序遇到以下错误: MsiGetProductInfo 无 ...
- 利用n和nvm管理Node的版本
写在前面 Node版本的迭代速度很快,版本很多(横跨0.6到0.11),升级Node版本成为了一个问题.目前有n和nvm这两个工具可以对Node进行无痛升级,本文简单介绍一下二者的使用. n n是No ...
- Mac下使用Fiddler(转载园友小坦克)
Fiddler是用C#开发的. 所以Fiddler不能在Mac系统中运行. 没办法直接用Fiddler来截获MAC系统中的HTTP/HTTPS, Mac 用户怎么办呢? Fiddler可以允 ...
- iOS - WKWebView的使用和长按手势识别二维码并保存
WKWebView的图片二维码使用: .长按手势识别二维码并保存 .识别二维码跳转;不是链接显示内容点击网址跳转 .解决url包含中文不能编码的问题 .文字带链接网址,点击跳转 .纯文本-文字html ...
- Java IO 详解
Java IO 详解 初学java,一直搞不懂java里面的io关系,在网上找了很多大多都是给个结构图草草描述也看的不是很懂.而且没有结合到java7 的最新技术,所以自己来整理一下,有错的话请指正, ...
- 170810、spring+springmvc+Interceptor+jwt+redis实现sso单点登录
在分布式环境中,如何支持PC.APP(ios.android)等多端的会话共享,这也是所有公司都需要的解决方案,用传统的session方式来解决,我想已经out了,我们是否可以找一个通用的方案,比如用 ...
- c++从文件中读取一行数据并保存在数组中
从txt文本中读取数据存入数组中 #include <iostream> #include <fstream> #include <string> #include ...
- .windows安装使用这些偏底层的Python扩展太
.windows安装使用这些偏底层的Python扩展太不爽了,怎么彻底解决 error: Unable to find vcvarsall.bat呢? 1.不要按网上说的,安装MinGW,然后在“.. ...
- PLSQL developer开发工具相关配置
首先要安装ORACLE Windows版本32位的客户端,在这里只安装ORACLE客户端就可以了,服务端我们选择使用LINUX版本的. 选择不接受安全更新 选择仅安装数据库软件 选择单实例数据库 语言 ...
- Zhu and 772002---hdu5833(高斯消元解求异或方程组)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5833 题意:给n个数,选择一些数字乘积为平方数的选择方案数. 分析:每一个数字分解质因数.比如4, 6 ...