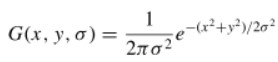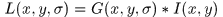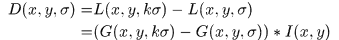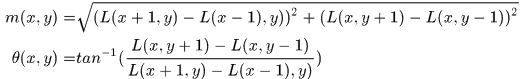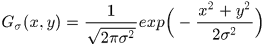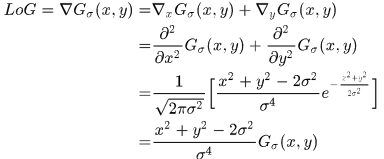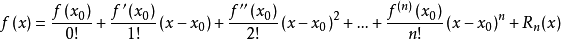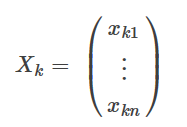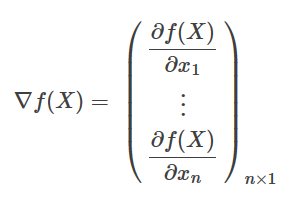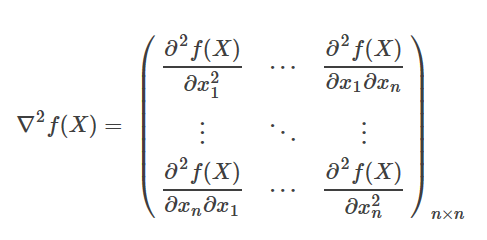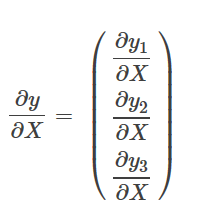SIFT(Scale-Invariant Feature Transform)是一种具有尺度不变性和光照不变性的特征描述子,也同时是一套特征提取的理论,首次由D. G. Lowe于2004年以《Distinctive Image Features from Scale-Invariant Keypoints[J]》发表于IJCV中。开源算法库OpenCV中进行了实现、扩展和使用。
本文主要依据原始论文和网络上相关专业分析,对SIFT特征提取的算法流程进行简单分析。由于涉及到的知识概念较多,本人能力经验有限,如果有错误的地方麻烦帮助指出,大家一起维护文档的正确性;有一些内容和图片来自网络,文章最后会给出原文地址,侵删。
一、本文结构
依据原始论文,SIFT算法流程分为4个部分:
1、DoG尺度空间构造(Scale-space extrema detection)
2、关键点搜索与定位(Keypoint localization)
3、方向赋值(Orientation assignment)
4、关键点描述(Keypoint descriptor)
此外再添加第5个部分,用于说明一些需要特殊说明的重要内容。类似游戏攻略的主线和分线。
以上内容分别对应二至六章,第七章用来放置一些参考文献。
二、DoG尺度空间构造(Scale-space extrema detection)
2.1"尺度"简介
图像处理中的"尺度"可以理解为图像的模糊程度,类似眼睛近视的度数。尺度越大细节越少,SIFT特征希望提取所有尺度上的信息,也就是无论图像是否经过放大缩小都能够提取特征。这种思考,是和人的生理特征类似的,比如我们即使是在模糊的情况下仍然能够识别物体的种类,生理上人体对物体的识别和分类和其尺度(模糊程度)没有直接关系。
高斯函数在图像处理中得到了广泛的运用,源于其本身具有的优良特性(高斯函数的优良特性放在6.1节);在图像处理中对图像构建尺度空间的方法,是使用不同sigma值的高斯核对图像进行卷积操作(注意,sigma就是“尺度”)。

是高斯核,其数学表述为:
整个高斯卷积表示为:
其中
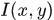
是原图像,*是卷积符号,

对应尺度下的尺度图像,这里简单了解一下,我们看一下在OpenCV中实现不同sigma的高斯卷积的代码和结果
Mat matSrc ,),);
imshow(,),);
imshow(,),);
imshow("sigma是5",matDst);
其中左上角为原图,右上角为sigma=1尺度下的图像,下行左右分别是sigma=3,sigma=5的图像,尺度越大,图像越模糊,这是直观印象。但是即使sigma=5,你也能够勉强认出这是一个人像;如果你的头脑中有lena这个模型,见过lena的图片,你就能够很快识别出这是lena的图片变模糊的结果。这就是基本上一个人脑的识别流程。“尺度”就是这些。
2.2"图像金字塔"简介
图像金字塔也是图像处理中的常用的概念,一般通过对原始图像逐步进行下(降)采样(每隔2个像素抽取一个像素)得到x和y都为原始图像1/2的缩小图像。

对于二维图像,一个传统的金字塔中,每一层图像由上一层分辨率的长、宽各一半,也就是四分之一的像素组成;注意金字塔上一个上小下大的东西,它的层数是由下向上来数的,底层叫做第0层,然后往上依次为1、2、3层。
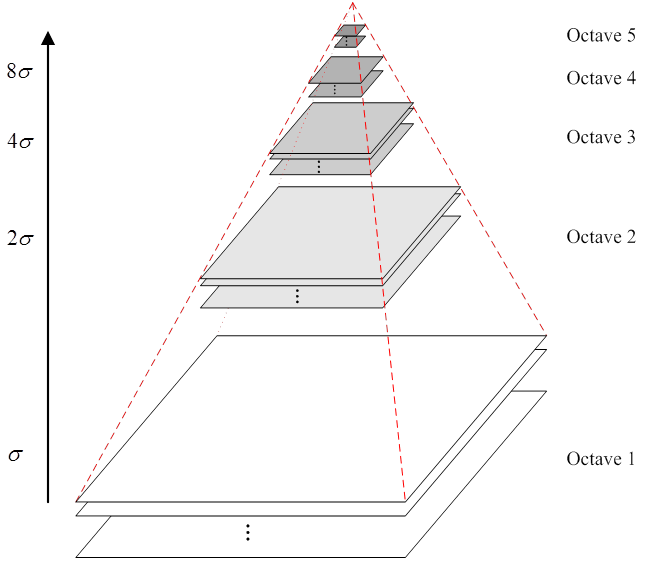
2.3“高斯金字塔”
现在我们已经知道,金字塔就能够用来解决大小的变化;而不同尺度的gauss核用来解决模糊程度的变化。聪明的计算机工程师想到把这两者结合起来。
因为有高斯和金字塔嘛,直来直往的就叫做“高斯金字塔”吧。它的模型应该是看上去这样的:大体看上去是一个金字塔,但是每层都是“复合”结构,是有若干张不同尺度的处理结果叠加起来的。
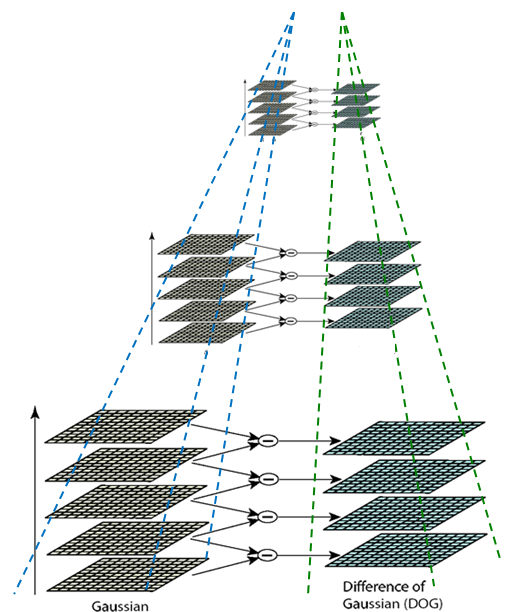
按照论文里面的叫法,金字塔每层多张图像合称为一组(Octave/'ɔktiv/),每组有多张(也叫层Interval/'intəvəl/)图像。
高斯金字塔在多分辨率金字塔简单
降采样基础上加了高斯滤波,但是具体来做的时候有细节在里面:令每一层金字塔(octave)中尺度变化范围为

,每层金字塔测量s个尺度。那么第t层金字塔的尺度范围就是

,第
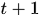
层金字塔的第一幅图像由上层塔中尺度下的下(降)采样的到,下采样比例为0.5。降采样时,金字塔上边一组图像的第一张图像(最底层的一张)是由前一组(金字塔下面一组)图像的倒数第三张下(降)采样得到。这里有些小混乱,聪明如你一定会提出一些问题,我们把这个叫做“尺度变化连续性”,并放在6.2中结合OpenCV实现的代码进行讲解。
2.4“高斯差分金字塔”
所谓图像差分,简单的说就是两幅图像不一样的地方;差分运算就是对两个图像做一个相减的运算。之所以这样做,是因为拍摄连续动作图像序列,或者是同一场景下不同时刻的图像,其绝大部分都是相同点。直接相减留下来的就可能特征。
在图像增强中有一种非常简单的特征提取方法,就是用原始图像减去经过高斯模糊后的图像,能够得到特征信息;从信号理论这块来说明,模糊后的图像保存的是低频信息,原始图像减去低频信息留下高频信息。
前面已经有了高斯金字塔,下面可以进一步计算高斯差分金字塔。再次强调:差分就是相减
它有一个比较有名的名字Difference of Gaussian,简称dog(和狗这种生物没有什么关系)。如果对于前面的尺度和金字塔的概念比较清楚,那么一定能够很快接受下面这幅DOG图:
或者缩小一些,原始论文中的这张图看的清楚一些,但是实际上是一个意思:
原文中特别支持这里DoG近似等于尺度归一化的高斯拉普拉斯算子
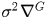
,而尺度归一化的高斯拉普拉斯算子相较于其他角点检测算子,如梯度,Hessian或Harris焦点特征能够更稳定的图像特征。这个算子光是看名字就很厉害,不但有高斯还有拉普拉斯最后还归一化了。但这块内容和算法主线关系不大,我们放到6.3中进行说明吧。
到目前位置,第一节DoG尺度空间构造结束了,希望你能够知道什么事DoG尺度空间。是不是内容很多?这里还只是原理主要流程简析,我们还有几个比较重要的知识点要在第六章中具体说明;在变成算法的过程中,图像处理工程师们还做出了更多工作,比如这些层取多少比较合适?有没有简化算法?这些都是可以拿来说事的,因为算法没有效率就和没有这个理论差不多,这一点的观点还是要建立。
二、关键点搜索与定位(Keypoint localization)
2.1初略寻找
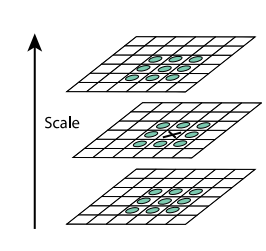
像“扫雷”游戏一样,除了边缘点外,每个点有8个相联的位置(最多有8个地雷);那么在已经建立起来的DoG空间中,除了边缘的点,每个点有9*3-1 = 26 个领域。在这个26个领域里面寻找最大最小的点,认为可能是关键点。如下图
标注的点要和周围26个绿色的点比较。
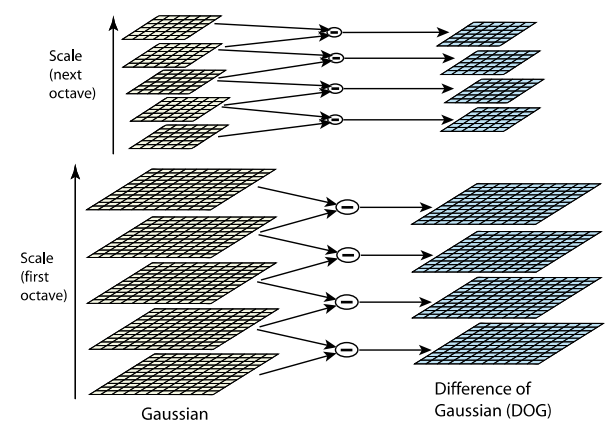
在做卷积运算的时候,专门要考虑边缘问题,也有很多种解决方法。对于这里存在边缘问题,如何来处理了?论文中采用了比较直接的方法,就是边缘的都不要。反过来,我们也需要知道对于某一层来说,如果我们想获得s个极值,那么一共需要s+2个dog值(最前面和最后面多两个),而由于1个dog至少需要2个gauss尺度才能够计算出来,所以结论是如果想获得s个极值,那么需要s+3个gauss(这也是为什么“高斯金字塔”在降采样的时候,选用第3个层来做抽值运算)。下面这幅图能够帮助你理解这个概念。
从27个点中找一个极值点,这是比价简单的运算;所以这里的特征点初略的寻找是比较简单的,我们很快能从DoG空间中粗略的找到了关键点。
2.2细化寻找
下一步是细化,要去除干扰就要分别处理这两种情况。
2.2.1、较小的极值
对关键点进行3D二次函数的拟合(可以类比最优化里牛顿法的做法),然后对函数求极值。
将每个关键点的一段函数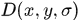 进行泰勒二次展开:
进行泰勒二次展开:
注意,泰勒公式是最为基本的连续函数量化(离散化)的相似公式。
其中x是相对于关键点的距离。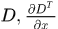 和
和 分别表示函数在关键点的取值和一阶导数,二阶导数。这个展开就是在关键点周围拟合出的3D二次曲线。学导数的时候学过,当导数为0的时候原函数取极值。那么这里二次泰勒的导数为(这种怪异的函数如何求导?放在6.6节,读正文的时候你就先接受这个结果就可以了,但应该知道这里的这些数学问题)
分别表示函数在关键点的取值和一阶导数,二阶导数。这个展开就是在关键点周围拟合出的3D二次曲线。学导数的时候学过,当导数为0的时候原函数取极值。那么这里二次泰勒的导数为(这种怪异的函数如何求导?放在6.6节,读正文的时候你就先接受这个结果就可以了,但应该知道这里的这些数学问题)
此时的极值为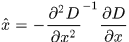

,
当这个极值过小的时候,被去除。原始论文中剔除
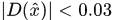
的点。
2.2.2、边缘噪声
Hessian矩阵的特征值和特征值所在特征向量方向上的曲率成正比(因为我做过基于hessian方面的增强,所以对于这个方面有一些多的了解,放在6.4中,我们可以多画几张图)。我们希望使用曲率的比值剔除边缘点,就可以使用Hessian的特征值的比值替代曲率的比值。
计算特征值;以及计算特征值的比例
Hessian矩阵定义如下:
可以由二阶差分计算得到,那么接下来就可以计算特征值的比值了。
先等一等,假设两个特征值分别为 ,看下面两个式子:
,看下面两个式子:
其中

分别是矩阵的迹和矩阵的行列式,这样发现特征值的比值可以通过这两个两计算得到,而不需要特征值分解,这样简单多了。
假设

为较大特征值,且
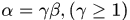
,则
当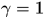 是
是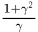 最小,所以当
最小,所以当 越大时,对应的
越大时,对应的 越大。所以我们要将
越大。所以我们要将 的点剔除就相当于将
的点剔除就相当于将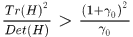 的点剔除。论文中。
的点剔除。论文中。
但是,原论文里面说这个比率理论来自另一片论文,这里计算“迹”和“行列式”就一定比计算矩阵特征值本身更为简单吗?我们放在6.5中进一步研究。这里我们需要知道进一步调用并计算hessian特征值,我们得到了特征点的精细提取。那么第二部分结束了。
这个地方,需要看到,实际上这里出现的两处“精细筛选”的算法是有相互的关系的:它们一个是去掉了特征点中不是非常“锋利”的特征点、一个是去掉了属于“边缘”的特征点。目的是统一的,都是挑选出更为合适的特征点。
三、方向赋值
在DoG空间中已经找到并细化出若干关键点,现在这些特征点还是存储在类似Mat这样结构里面的(实际上现在已经有很多可以叫做“特征点”的点了)。但原论文认为还不够,还需要考虑“旋转适应性”,就是同样一个特征,旋转后了还能够被认为是同样的特征。为了解决这个问题,首先就是需要表示“方向”。
在图像处理中,最直观的是采用“梯度”表示方向,比如sobel算子等,这里也是类似的方法。
计算图像局部方向的基本方法,那就是定义啦,理解这个公式应该没有问题
(注意原论文里这里有个1.5倍尺度重新运算的部分,和主线关系不大)得到这个角度以后,
在完成关键点邻域内高斯图像梯度计算后,使用直方图统计邻域内像素对应的梯度方向和幅值。
梯度方向直方图的横轴是梯度方向角,纵轴是剃度方向角对应的梯度幅值累加值。梯度方向直方图将0°~360°的范围分为36个柱,每10°为一个柱。下图是从高斯图像上求取梯度,再由梯度得到梯度方向直方图的例图(注意这里的直方图是8个柱的简化版本)。
既然有了直方图,那么就有高低了(两个一样高的这种细节就不要考虑了)。直方图峰值代表该关键点处邻域内图像梯度的主方向,也就是该关键点的主方向。在梯度方向直方图中,当存在另一个相当于主峰值 80%能量的峰值时,则将这个方向认为是该关键点的辅方向。
所以一个关键点可能检测得到多个方向,这可以增强匹配的鲁棒性。Lowe的论文指出大概有15%关键点具有多方向,但这些点对匹配的稳定性至为关键。
获得图像关键点主方向后,每个关键点有三个信息(x,y,σ,θ):位置(x,y)、尺度、方向。由此我们可以确定一个SIFT特征区域。通常使用一个带箭头的圆或直接使用箭头表示SIFT区域的三个值:中心表示特征点位置,半径表示关键点尺度,箭头表示主方向。具有多个方向的关键点可以复制成多份,然后将方向值分别赋给复制后的关键点。如下图(这图认真看看要懂)
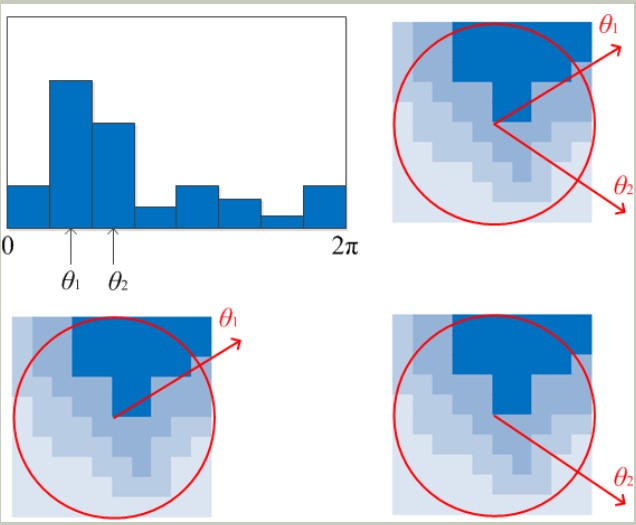
那么方向也得到了。
第四部分:关键点描述
为找到的关键点即SIFT特征点赋了值,包含位置、尺度和方向的信息。接下来的步骤是关键点描述,即用一组向量将这个关键点描述出来。图像处理必须考虑相关性,也就是你描述一个点,还必须考虑到它周围的情况。所以这个描述子不但包括关键点,也包括关键点周围对其有贡献的像素点。
特征描述子与关键点所在尺度有关,因此对梯度的求取应在特征点对应的高斯图像上进行。将关键点附近划分成d×d个子区域,每个子区域尺寸为mσ个像元(d=4,m=3,σ为尺特征点的尺度值)。考虑到实际计算时需要双线性插值,故计算的图像区域为mσ(d+1),再考虑旋转,则实际计算的图像区域为

在子区域内计算8个方向的梯度直方图,绘制每个方向梯度方向的累加值,形成一个种子点。
与求主方向不同的是,此时,每个子区域梯度方向直方图将0°~360°划分为8个方向区间,每个区间为45°。即每个种子点有8个方向区间的梯度强度信息。由于存在d×d,即4×4个子区域,所以最终共有4×4×8=128个数据,形成128维SIFT特征矢量。简单地看来,就是将第3节的部分扩展为一个更大的矩阵。128维用来表示一个特征点,那是相当大的数据量,这也就是为什么sift计算缓慢的原因吧。
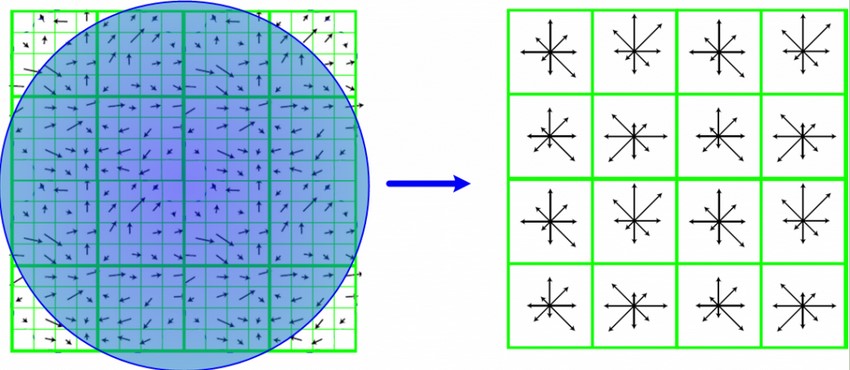
好了,这样我们已经找到并且表示出来了sift特征点,下面就是比较、存储等后续操作,相比较原理来说较为次要。后期我们结合OpenCV代码具体分析的时候进行细化。
6、辅助资料
其实我这篇博客专门将这些辅助的资料挑出来单独讲,一方面是前面的那些系统的资料,网络上已经有很多写的非常好的,我也参考了许多,其实相同的地方很多;另一方面我在“辅助资料”这块融入了许多自己项目实现的一些经验和整理,希望它能够成为独立主要内容,但是又能够帮助理解主要内容的一部分。
6.1、Gauss的优良特性
什么是Gauss?如果在一维空间里面,基本上能够理解Gauss就是“正态分布",它天生具有许多优良特性,而且并不是仅仅在图像处理这块才体现出来的。
如果整理一下:
1. Lindeberg等人已证明高斯卷积核是实现尺度变换的唯一变换核,并且是唯一的线性核 。
2.高斯函数具有旋转对称性,用其对图像进行平滑运算时在各个方向上的平滑程度相同,因此后续边缘检测等操作中不会偏袒某一方向上的图像的细节。
3.随着离高斯模板中心点越远,权值越小,这使得高斯滤波器比起普通的平滑滤波器更能更好地保留图像细节。如果距离越远的点权值越重的话,那图像就会失真。
4.高斯函数有个sigma参数可以非常容易地调节高斯函数对高低频信息的保留程度。sigma参数越大,高斯函数的图谱就越低矮平缓,表现在频谱上就是频带越宽,平滑程度高;反之,sigma参数越小,平滑程度越低。而且二维高斯函数的取值半径(即卷积核大小)越大,平滑程度越高。
举其中第二点来具体说明,我之前在实现Frangi算法的时候了解到,如果你想求整个图像的Hessian矩阵,然后再做个Gauss平滑什么的,就可以换成先”通过先对高斯函数进行偏导操作,然后利用这个核对原图像进行卷积求解(图像的二阶偏导数可以通过使用多尺度高斯核的二阶偏导数对原图像的卷积获得),因为:

我们知道,OpenCV对卷积操作能够通过FFT进行加速计算,这样的话,本来是要算整个图像的偏导的(想想800*600个像素的偏导),现在只要求一个5*5的偏导就可以,速度上就很适合,而且代码实现也能够方便一些。
6.2 尺度变化连续性
通过理解这张图,能够把问题理解的比较清楚。
假设s=3,也就是每个塔里有3层,则k=21/s=21/3,那么按照上图可得Gauss Space和DoG space 分别有3个(s个)和2个(s-1个)分量,在DoG space中,1st-octave两项分别是σ,kσ; 2nd-octave两项分别是2σ,2kσ;由于无法比较极值,我们必须在高斯空间继续添加高斯模糊项,使得形成σ,kσ,k2σ,k3σ,k4σ这样就可以选择DoG space中的中间三项kσ,k2σ,k3σ(只有左右都有才能有极值),那么下一octave中(由上一层降采样获得)所得三项即为2kσ,2k2σ,2k3σ,其首项2kσ=24/3。刚好与上一octave末项k3σ=23/3尺度变化连续起来,所以每次要在Gaussian space添加3项,每组(塔)共S+3层图像,相应的DoG金字塔有S+2层图像。虽然我也不能给理解在不同分辨率下保持尺度的连续有何意义,但是至少具备了某种程度的完备性吧。
”尺度越大,图像越模糊“,对于金字塔图像来说,分辨率越小,那么包含的信息越少,通过模糊而初略的提取方法提取主要特征。
6.3、尺度归一化的高斯拉普拉斯算子
首先理解什么是“高斯拉普拉斯算子”,它的名字也很有名“LoG,Laplacian of Gaussian"
假设对图像 ,使用尺度为
,使用尺度为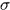 的高斯平滑
的高斯平滑
然后再使用Laplace算子检测边缘
其中*是卷积符号,这是因为
定义高斯拉普拉斯算子
相当于对高斯模板先进行Laplace再与图像进行平滑。重点在这里,前面是对高斯模板先进行Hessian求导,再和图像平滑
将LoG展开,看其具体形式(就是二次偏导求和)
所以
定量计算的话,就可以直接认为LoG模板可以为
然后我们进一步理解
先来看看归一化之后的LoG算子(该过程将高斯函数带入化简可得),归一的意思就是定下单位来的意思。
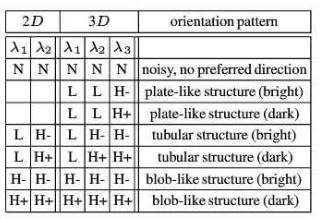
6.4Hessian矩阵的特征值和特征值所在特征向量方向上的曲率成正比
我当时最主要的跨越就是这幅图:
那么应该能够曲率的概念。Hessian矩阵的特征值分别对应了原始图像的点垂直于线条方向和平行线条的方向。
Frangi的截图
这个结果就是Hessian的结果,看左边,当两个特征值一个比较大,一个比较小的时候是直线(发分明亮和黑暗)
6.5计算“迹”和“行列式”就一定比计算矩阵特征值本身更为简单吗
我找到了1988这篇

里面关于使用矩阵的迹和行列式来简化计算的描述是这样的,也是只给了一个解雇。
在线性代数中,一个n×n矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)。

而“行列式”的定义:是两个特征值的乘法,是比较常见的。应该是有什么简化算法吧。
6.6 二阶泰勒级数相关知识
一阶泰勒函数表述方式
这个公式很好理解呀,但是原文中是这样表述
“
将每个关键点的一段函数进行泰勒二次展开:
其中x是相对于关键点的距离。和分别表示函数在关键点的取值和一阶导数,二阶导数。求导得到极值为,此时
,
当这个极值过小的时候,被去除。原始论文中剔除
的点。
”那么这里面的这许多符号是从哪里来的?
实际上
对于高维函数的泰勒展开式为:
这个方程式就是比较像的了。迭代近视的方法叫做牛顿公式。虽然我们在图像处理中需要解决的还是二维的问题,但是既然已经出现了高纬统一的表示方式,下面我们来推到其:
f(X),X为n维列向量,表示含有n个变量。
那么它每一项的,比如第k项可以认为是:
对f(X)在Xk处泰勒二阶展开。
函数为二维时的展开公式:f(x)=f(xk)+f′(xk)(x−xk)+12f′′(xk)(x−xk)2
相应的高维展开式,符号定义:
f′′(Xk)=Gk=∇2f(Xk)
仅仅是定义而已,问题不大,那么
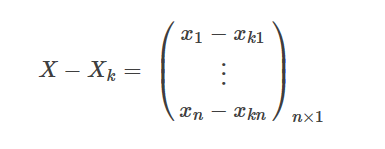
这也是很直接。
可以看出∇f(X)和X−Xk都是列向量,无法相乘取内积。所以这里要将gk转置。后面的(X−Xk)2也是一样的道理。
所以对于高维函数的泰勒展开式为:

现在就能够看到转置的用途了。函数表示出来以后,为了求极值,那么就是要求导:分为3个部分
f(X)1=f(Xk)
f(X)2=f′(Xk)(X−Xk)
f(X)3=12f′′(Xk)(X−Xk)2
(1) 对f(X)1求导,f(Xk)不含有变量X所以此项导数为0。
(2) 对f(X)2求导。
gTk不含有变量X所以为常数,不需要考虑,这时要求导的部分变成了y=(X−Xk)。
为简便,我设X为3维的列向量
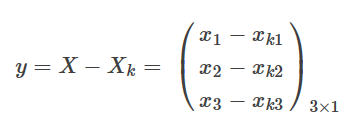
y对X求导:y为矩阵X为列向量。属于矩阵对列向量求导的那一类。
根据求导公式:
对于∂y1∂X是y1=x1−xk1对X
求导,属于元素对列向量求导的类型。
同理可得:
也就是说:
所以 f′(X)2=f′(Xk)=gk
(3) 对f(X)3求导。
与上一步类似。
f′(X)3=f′′(Xk)=Gk
所以: f′(X)=gk+Gk(X−Xk)=0
若Gk为非奇异(则矩阵可逆),解这个方程,记其解为Xk+1即得牛顿法的迭代公式:
Xk+1=Xk−G−1kgk
第七章 小结和参考文献
http://blog.csdn.net/u011310341/article/details/49496229
http://blog.csdn.net/abcjennifer/article/details/7372880
http://blog.csdn.net/abcjennifer/article/details/7365882
http://en.wikipedia.org/wiki/Scale-invariant_feature_transform#David_Lowe.27s_method
http://blog.sciencenet.cn/blog-613779-475881.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080950.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080951.html
http://blog.csdn.net/ijuliet/article/details/4640624
http://www.cnblogs.com/cfantaisie/archive/2011/06/14/2080917.htmS
- Java Android 注解(Annotation) 及几个常用开源项目注解原理简析
不少开源库(ButterKnife.Retrofit.ActiveAndroid等等)都用到了注解的方式来简化代码提高开发效率. 本文简单介绍下 Annotation 示例.概念及作用.分类.自定义. ...
- Java Annotation 及几个常用开源项目注解原理简析
PDF 版: Java Annotation.pdf, PPT 版:Java Annotation.pptx, Keynote 版:Java Annotation.key 一.Annotation 示 ...
- PHP的错误报错级别设置原理简析
原理简析 摘录php.ini文件的默认配置(php5.4): ; Common Values: ; E_ALL (Show all errors, warnings and notices inclu ...
- [转载] Thrift原理简析(JAVA)
转载自http://shift-alt-ctrl.iteye.com/blog/1987416 Apache Thrift是一个跨语言的服务框架,本质上为RPC,同时具有序列化.发序列化机制:当我们开 ...
- SIFT特征原理与理解
SIFT特征原理与理解 SIFT(Scale-invariant feature transform)尺度不变特征变换 SIFT是一种用来侦测和描述影像中局部性特征的算法,它在空间尺度中寻找极值点,并 ...
- Spring系列.@EnableRedisHttpSession原理简析
在集群系统中,经常会需要将Session进行共享.不然会出现这样一个问题:用户在系统A上登陆以后,假如后续的一些操作被负载均衡到系统B上面,系统B发现本机上没有这个用户的Session,会强制让用户重 ...
- 基于IdentityServer4的OIDC实现单点登录(SSO)原理简析
写着前面 IdentityServer4的学习断断续续,兜兜转转,走了不少弯路,也花了不少时间.可能是因为没有阅读源码,也没有特别系统的学习资料,相关文章很多园子里的大佬都有涉及,有系列文章,比如: ...
- cgroup原理简析:vfs文件系统
要了解cgroup实现原理,必须先了解下vfs(虚拟文件系统).因为cgroup通过vfs向用户层提供接口,用户层通过挂载,创建目录,读写文件的方式与cgroup交互.因为是介绍cgroup的文章,因 ...
- 【超精简JS模版库/前端模板库】原理简析 和 XSS防范
使用jsp.php.asp或者后来的struts等等的朋友,不一定知道什么是模版,但一定很清楚这样的开发方式: <div class="m-carousel"> < ...
随机推荐
- ECNU 3247 - 铁路修复计划
Time limit per test: 2.0 seconds Time limit all tests: 15.0 seconds Memory limit: 256 megabytes 在 A ...
- Springboot中静态资源和拦截器处理(踩了坑)
背景: 在项目中我使用了自定义的Filter 这时候过滤了很多路径,当然对静态资源我是直接放过去的,但是,还是出现了静态资源没办法访问到springboot默认的文件夹中得文件 说下默认映射的文件夹有 ...
- php:// — 访问各个输入/输出流(I/O streams)
PHP: php:// - Manual http://www.php.net/manual/zh/wrappers.php.php php:// php:// — 访问各个输入/输出流(I/O st ...
- hyperledger
http://hyperledger-fabric.readthedocs.io/en/latest/prereqs.html https://github.com/hyperledger/block ...
- pandas1
https://www.cnblogs.com/nxld/p/6058591.html
- 学习grunt四解决yo webapp生成的是gulpfile而不是gruntfile问题
虽然gulp慢慢取代了gruntfile,但是还有大部分的github源码保留gruntfile,另外我们开发项目也不是全用gulp,也是用grunt. 但是yeoman上generator-weba ...
- 查看win信任的证书办法机构(CA机构的公钥)
cmd mmc
- mysql python pymysql模块 增删改查 查询 fetchone
import pymysql mysql_host = '192.168.0.106' port = 3306 mysql_user = 'root' mysql_pwd = ' encoding = ...
- 万恶之源 - Python函数进阶
函数参数-动态参数 之前我们说过传参,如果我们在传参数的时候不很清楚有哪些的时候,或者说给一个函数传了很多参数,我们就要写很多,很麻烦怎么办呢,我们可以考虑使用动态参数 形参的第三种:动态参数 动态参 ...
- [js]js中原型的继承
js继承01 思路: 单例/工厂/构造函数--演进到原型 搞清原型结构 原型继承 模拟系统原型继承 实现自己的继承 观察原型继承特点 演进到原型链这一步 //单例模式: 防止变量名冲突: // 思路: ...