【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验十四:储存模块
实验十四比起动手笔者更加注重原理,因为实验十四要讨论的东西,不是其它而是低级建模II之一的模块类,即储存模块。接触顺序语言之际,“储存”不禁让人联想到变量或者数组,结果它们好比数据的暂存空间。
. int main()
. {
. int VarA;
. char VarB;
. VarA = ;
. VarB = ;
. }
代码14.1
如代码14.1所示,主函数内一共声明两个变量VarA与VarB(第3~4行)。VarA是两个字节的整型变量,VarB是一个字节的字符变量,然后VarA赋值20(第5行),VarB则赋值5(第6行)。,其中 int 与 char 等字眼用来表示字节,即暂存空间的位宽,然后储存的内容仅局限于二进制,非0即1。
. int main()
. {
. int VarC[];
. VarC[] = ;
. for( int i = ; i < ; i++ ) VarC[i] = i;
. VarC[] = VarC[];
. }
代码14.2
除了变量以外,顺序语言也有数组这个玩意,亦即一连串的变量。如代码14.2所示,主函数内声明数组VarC,数组的成员位宽是两个字节的int,数组的成员长度则是20(第3行)。然而数组常见的赋值方法除了成员直接赋值以外(第4行),也有使用for循环为逐个成员赋值的方法(第5行)。此外,还有某个数组成员为某个数组成员直接赋值的方法(第6行)。目前为止,顺序语言还有储存之间的故事就圆满结束。
人是一种自虐的生物,事情越是顺利,越是容易萌起疑心 ... 然后暗道:“储存是不是太容易理解呢?容易到让人觉得恶心!“。没错,事实的确如此。“储存”一旦投入描述语言之中,话题便会严肃起来。顺序语言是一件懒人多得的语言,它有许多底层工作都交由编译器处理,相较之下描述语言是一件多劳多得的语言,许多底层工作都必须交由我们自己声明与定义。
. reg [:]D1 = ’d1;
. reg [:]D2 ;
. reg [:]D3;
.
. initial begin D2 = ’d2; end
.
. always @ ( posedge CLOCK or negedge RESET )
. if( !RESET )
. D3 <= ’d3;
. ......
代码14.3
首先让我们来理解一下初始化与复位化之间的区别。我们知道顺序语言的变量只有初始化,没有复位化这一回事 ... 反之,描述语言却不同。如代码14.3所示,笔者在第1~3行声明D1~D3三个寄存器,其中D1声明不久便立即赋予初值 4’d1。换之,D2则在第5行赋予初值 4’d2,最后D3则在第8~9行赋予复位值4’d3。
所谓初值就是初始化所给予的起始内容,反之复位值就是复位触发所给予的内容。初始化一般都是编译器的赋值活动,第1行的D1还有第5行的D2都是经由编译器的活动给予初值。反观之下,复位化不是编译器活动而是硬件活动,也是俗称的RESET,即电平变化所引起的复位触发。
如代码行第7~9所示,敏感区种含有 negedge RESET的字眼表示,如果RESET的电平由高变低并且产生下降沿触发,结果就执行一下 always 的内容。其中的内容便是复位操作,最终 D3 赋予复位值 4’d3。
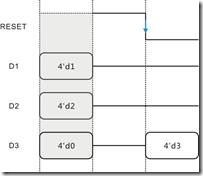
图14.1 初始化与复位化的时序图。
如果用时序来表示的话 ... 如图14.1所示,灰色区域表示初始化状态又或者未上电状态
,当中D1与D2都赋予初值4’d1与4’d2,同样D3也给予初值 4’d0。虽然D3在代码14.3之间并没有任何初始化的痕迹,不过默认下编译器都会一视同仁,将所有暂存声明都给予初值0,除非有特别声明,例如第1行的D1与第5行的D2。上电以后,RESET电平又高变低便产生下降沿,结果复位发生了,然后D3被赋予复位值4’d3。
我们知道容器有大有小,所以储存空间也有大小之分,然而决定空间大小就是位宽这种东西。位宽一般是指数据的长度,顺序语言会用 int 或者 char 等关键字表示位宽,反之描述语言会直接声明位宽的大小,如 reg[3:0]D1。在此,顺序语言的位宽区别都是一个字节一个字节比较,反之描述语言比较随意。
. reg [:]D1; // Verilog
. reg var [:]D2; // Sytem Verilog
. logic var [:]D3; // System Verilog
代码14.4
除了位宽以外,我们还要理解什么是储存内容。描述语言相较顺序语言,储存内容的花样较多一些 ... 顺序语言由于比较比较偏向软件,所以储存内容仅有两态,即1与0而已。反之描述语言是介于硬件与软件之间,所以储存内容除了0与1两态之外,也有高阻态z与切开x。
如代码14.4所示,当我们声明D1的时候,除了需要强调位宽以外,我们还要强调储存内容 ... 以Verilog为例的话,关键字 reg 的用意并非强调储存资源是基于寄存器,而是表示储存内容有0有1,还有z与x等四个状态。相反的,SystemVerilog在这方面却做得很好,如代码行2~3所示,var 关键字表示对象是储存空间,reg 关键字表示对象的储存内容有4态,logic关键字则表示对象的储存内容有2态。
. char VarA; // 变量(内存)
. char VarB[] // 数组(内存)
. reg [:] D1; // 寄存器
. reg [:] D2; // 寄存器
代码14.5
我们知道顺序语言有所谓的变量与数组,储存资源一般都是基于内存,例如第1行的VarA与第2行的VarB。反之,描述语言不仅可以用寄存器资源建立变量,寄存器资源也能建立数组,例如与第3行的D1与第4行的D2。(虽然顺序语言偶尔也会用到寄存器型的储存资源,不过该储存资源对处理器来说太珍贵了,如果不是特殊条件,一般都不会随意使用)
. reg [:] RAM [:]; // 片上内存
代码14.6
此外,描述语言还有另外一种叫做片上内存的储存资源,声明方法如代码14.6所示。FPGA的片上内存与单片机的内存虽然都是内存,但是两者之间却是不同性质的内存。简单而言,单片机的内存是经过烧烤的熟肉,随时可以享用 ... 反之,FPGA的片上内存则是未经过烧烤的生肉,享用之前必须做好事先准备。为此,FPGA的片上内存无法像级单片机内存那样,随便赋值,随意调用。
. int main()
. {
. char VarC[];
. for( int i = ; i < ; i++ ) VarC[i] = VarC[i+]
. }
代码14.7
如代码14.7所示,笔者先建立一个 char 类型的数组 VarC长度并且为4,紧接着利用for循环为数组的整组成员赋值,其中VarC[i] 的赋予内容是 VarC[i+1] 的结果。代码
14.7算是顺序语言常见的例子,期间初始化也好,还是利用for循环为数组赋值也好,许多底层的工作都交由编译器去作,我们只要翘脚把代码照顾好就行。
. reg [:] RAM [:] . reg [:]i; . . always @ ( posedge CLOCK ) // 错误 . for( i = ; i < ; i = i + ) RAM[i] = RAM[i+];
代码14.8
换做描述语言,如代码14.8所示 ... 笔者在第1~2行当中先声明位宽为8长度为4的RAM,随之又声明i。假设RAM要实现代码14.7同样的赋值操作,首先最常见的错误就是第4~5行的例子 ... 许多人会直接将关键字for套用在 always 块里,这种赋值操作有两种问题:
其一,编译器并不清楚我们到底要利用空间实现for,还是利用时钟实现for。默认下,编译器会选择前者,后果就是吃光逻辑资源。
其二,RAM[i] = RAM[i+1] 这种赋值操作会搞砸综合,结果片上内存的布线状况会变得非常复杂,从而导致综合失败。
代码14.8算是新手最容易犯下的问题之一,代码14.8虽然没有语法上的错误,而且仿真也会通过,但是综合却万万不可。为此,代码14.8需要更动一下。
. reg [:] RAM [:] . reg [:]i; . . always @ ( posedge CLOCK ) // 错误 . case( i ) . ,,: . begin RAM[i] <= RAM[i+]; i <= i + ’b1; end . endcase
代码14.9
如代码14.9所示,笔者舍弃关键字 for,取而代之却利用仿顺序操作充当循环,这是一种利用时钟实现for的方法 (伪循环)。不过代码14.9依然不被综合器接受,结果报错 ... 因为片上内存并不支持类似 RAM[i] <= RAM[i+1] 的赋值方式,因为综合期间会导致布线复杂化,并且进一步搞砸综合。为此,代码14.9需要继续更动。
. reg [:] RAM [:] . reg [:]i; . reg [:]D1; . . always @ (posedge CLOCK) // 正确 . case( i ) . ,,: . begin D1 <= RAM[i<<]; i <= i + ’b1; end . ,,: . begin RAM[ (i<<)+ ] <= D1; i <= i + ’b1; end . endcase
代码14.10
如代码14.10所示,笔者多建立一个作为暂存作用的寄存器D1,然后利用两组步骤移动RAM之间的数据。步骤0,2与4将RAM[i] 的内容暂存至D1,步骤1,3与5则将D1的内容赋予 RAM[i+1]。如此一来,片上内存成员与成员之间的数据移动便大功告成。事实上代码14.7也干同样的事情,不过事实却被编译器隐藏了 ... 如果读者读者打开代码14.7的编译结果,读者会看见类似的汇编语言,结果如代码14.11所示:
T0 Load RAM[] => R0; T1 Load R0 => RAM[]; T2 Load RAM[] => R0; T3 Load R0 => RAM[]; T4 Load RAM[] => R0; T5 Load R0 => RAM[];
代码14.11
如代码14.11所示,汇编内容会重复使用 Load 指令将某个RAM的内容先暂存至通用寄存器R0,然后又从R0移至另某个RAM当中。至于代码14.11的正确性,笔者不能确保什么,毕竟距离上一次接触汇编语言已经是N年前的事情。不过感觉上差不多就是那样 ... 这就是被编译器所隐藏的底层工作之一,代码14.10不过是将其模仿而已。
讲到这里,我们开始接触重点了。上述的例子告诉我们,编译器不会帮忙描述语言处理底层操作。所以,变量与数组之间的储存操作不及顺序语言那么便捷,而且模仿起来也非常麻烦 ... 不过,我们也不用那么灰心,良驹有良驹的跑法,歪驹有歪驹的走法,我们只要换个角度去面对情况,不视问题,问题自然迎刃而解。
根据笔者的妄想,储存有“储存资源“ 还有“储存方式”之分。描述语言可用的储存资源有寄存器还有片上内存,然而变量与数组也是最简单也是最基础的“储存方式”。基于这些 ... 事实上,描述语言可以描述各种各样的“储存方式”。
. module rom( input [:]iAddr, output [:]oData ); . reg [:]D1; . always @ (*) . if( iAddr == ’b00 ) D1 = ’hA; . else if( iAddr == ’b01 ) D1 = ’hB; . else if( iAddr == ’b10 ) D1 = ’hC; . else if( iAddr == ’b11 ) D1 = ’hD; . else D1 = ’dx; . . assign oData = D1; . . endmodule
代码14.12
例如一个简单的静态ROM模块,它可以基于寄存器或者片上内存,结果如代码14.12与14.13所示。代码14.12是基于寄存器的静态ROM,它有2位iAddr与8位的oData
,其中第3~8行是ROM的内容定义,第10行则是输出驱动,为此oData会根据iAddr的输入产生不同的输出。
. module rom( input [:]iAddr, output [:]oData ); . reg [:] RAM [:]; . initial begin . RAM[] = ’hA; . RAM[] = ’hB; . RAM[] = ’hC; . RAM[] = ’hD; . end . . assign oData = RAM[ iAddr ]; . . endmodule
代码14.13
反之,代码14.13是基于片上内存的静态ROM,它也有2位iAddr与8位oData,第3~7行是内容的定义也是初始化片上内存,第10行则是输出驱动,oData会根据iAddr的输出产生不同的输出。
代码14.12与代码14.13虽然都是静态ROM,不过却有根本性的不同,因为两者源于不同的储存资源,其中最大的证据就是第10行的输出驱动,前者由寄存器驱动,后者则由片上内存驱动。不同的储存资源也有不同的性质,例如寄存器操作简单,而且布线有余,不过不支持大容量的储存行为。换之,片上内存虽然操作麻烦,布线也紧凑,可是却支持大容量的储存行为。
储存方式相较储存资源理解起来稍微抽象一点,而且想象范围也非常广大 ... 如果储存资源是“容器的种类”,那么储存方式就是“容器的用法”。举例而言,一个简单静态ROM,根据需要它还可以演变成为其它亚种,例如常见的单口ROM或者双口ROM或等。
. module rom( input CLOCK,input [:]iAddr, output [:]oData ); . reg [:] RAM [:]; . initial begin . RAM[] = ’hA; . RAM[] = ’hB; . RAM[] = ’hC; . RAM[] = ’hD; . end . . reg [:] D1; . always @ ( posedge CLOCK) . D1 <= iAddr; . . assign oData = RAM[ D1 ]; . . endmodule
代码14.14
如代码14.14所示,那是单口ROM的典型例子,然而单口ROM与静态ROM之间的差别就在于前者有时钟信号,后者没有时钟信号。期间,代码14.14用D1暂存iAddr,然后再由D1充当RAM的寻址工具。
. module rom( input CLOCK,input [:]iAddr1, iAddr2,output [:]oData1,oData2 ); . reg [:] RAM [:]; . initial begin . RAM[] = ’hA; . RAM[] = ’hB; . RAM[] = ’hC; . RAM[] = ’hD; . end . . reg [:] D1; . always @ ( posedge CLOCK) . D1 <= iAddr1; . . assign oData1 = RAM[ D1 ]; . . reg [:] D2; . always @ ( posedge CLOCK) . D2 <= iAddr2; . . assign oData2 = RAM[ D2 ]; . . endmodule
代码14.15
如代码14.15所示,那是双口ROM的典型例子,如果将其比较单口ROM,它则多了一组 iAddr与oData而已,即iAddr1与oData1,iAddr2与oData2。第10~14行是第一组(第一口),第16~20行则是第二组(第二口),不过两组 iAddr 与 oData 都从同样的RAM资源哪里读取结果。
事实上,ROM还会根据更多不同要求产生更多亚种,而且亚种的种类也绝非局限在于专业规范,因为亚种的储存模块会依照设计者的欲望——有多畸形就多畸形,死守传统只会固步自封而已。无论模块对象是静态ROM,单口ROM还是双口ROM等 ... 笔者眼中,它们都是任意的“储存方式”而已。
根据笔者的妄想,储存方式的覆盖范围非常之广。简单而言,凡是模块涉及数据的储存操作,低级建模II都视为储存类。举例而言,ROM模块储存自读不写的数据; RAM模块储存又读又写的数据;FIFO模块储存先写先读的数据。
为此,我们可以这样命名它们:
rom_savemod.v // rom储存模块
ram_savemod.v // ram储存模块
fifo_savemod.v // fifo储存模块
好奇的朋友一定会觉得疑惑,笔者究竟是为了定义储存类呢?事情说来话长,笔者也是经过多番考虑以后才狠下心肠去决定的。首先,让我们继续从顺序语言的角度去理解吧:
. unsigned char Variable;
. void FunctionA( unsinged char A ) { Variable = A; }
. unsinged char FunctionB( void ) { return Variable; }
. int main()
. {
. unsigned char D1;
. FunctionA( 0x0A );
. D1 =FunctionB();
. ......
. }
代码14.16
假设有N个函数想共享数据,一般而言我们都会建立全局变量(数组)。如代码14.16所示,笔者先建立全局变量Variable,然后又声明函数A为Variable 赋值,反之函数B则返回Variable的内容。完后,再编辑主函数的操作 ... 期间,主函数先声明变量D,然后调用函数A,并且传递参数 0x0A,完后便调用函数B,并且将返回的内容赋予D。
函数之间之所以可以共享数据,那是因为编译器在后面大力帮忙,并且处理底层操作才得以实现。换之,描述语言虽然没有类似的好处,但是描述语言可以模仿。
. reg [:]Variable; . reg [:]T,D1; . reg [:]i,Go; . always @ ( posedge CLOCk ) // 核心操作 . case(i) . : // 主操作 . begin T <= ’h0A; i <= ’d8; Go <= i + ’b1; end . : . begin i <= ’d9; Go <= i + ’b1; end . : . begin D1 <= T; i <= i + ’b1; end . ...... . :// Fake Function A 伪函数A . begin Variable = T; i <= Go; end . : // Fake Function B 伪函数B . begin T = Variable; i <= Go; end . endcase
代码14.17
如代码14.17所示,笔者先建立Variable,然后又建立T与D,还有i与Go。Variable模仿全局变量,T则是伪函数的暂存空间(数据传递),i指向步骤,Go则是指向返回步骤。步骤0~2,我们可以视为主函数,步骤8~9则是伪函数A与伪函数B。
步骤0,i将指向伪函数A的入口,T赋予 8’h0A,Go则指向下一个步骤。
步骤8,Variable 赋予 T 的内容,然后返回步骤。
步骤1,i将指向伪函数B的入口,Go则指向下一个步骤。
步骤9,T赋予Varibale 的内容,然后返回步骤。
步骤2,D1赋予Varibale的内容,然后操作结束。
如果我们将代码14.16与代码14.17互相比较的话,它们存在几处区别甚微的地方。
其一,代码14.17的代码量比代码14.16还要多;
其二,代码14.16的Variable是真正意义上的全局变量,反之代码14.17则是山寨。
除此之外,代码14.17还是一只核心操作组成,或者代码14.17是有一只函数而已。
如果主函数,函数A还有函数B之间只有简单操作,而且数据的传递量也不多的话,那么仅有一只核心操作也没有什么问题。相反的,如果函数之间不仅有复杂的操作,而且数据的传递量也很多的话,独秀的核心操作就要举白旗投降了。为此,我们必须借助多模块的力量来解决复杂的操作,但是多模块之间又如何共享数据呢?首先,让我们换个思路思考问题。
. unsigned char Variable; // 储存类
. void FunctionA( unsinged char A ) { Variable = A; } // 功能类
. unsinged char FunctionB( void ) { return Variable; } // 功能类
. int main() { ...... } // 控制类
代码14.18
如代码14.18所示,全局变量视为储存类,函数A与函数B视为功能类,至于主函数视为控制类。
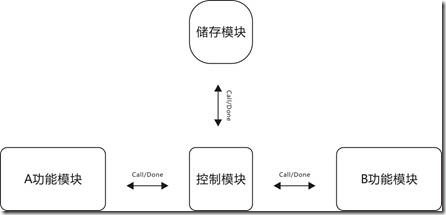
图14.2 代码14.18的建模图。
代码14.18经过分类以后,大致的建模布局如图14.2所示。一只名为main的控制模块充当中介,次序调度,协调者等角色。其中,A功能模块与B功能模块负责最基本的操作,variable储存模块则负责储存操作。余下,所有模块都经由问答信号联系起来,至于Verilog则可以这样表示:
. module ( ... );
.
. wire [:]CallU1;
. main_ctrlmod U1
. (
. .oCall( CallU1 ),
. .iDone( { DoneU1, DoneU2, DoneU3 } ),
. ...
. );
.
. wire DoneU2;
. a_funcmod U2
. (
. .iCall( CallU1[] ),
. .oDone( DoneU2 ),
. ...
. );
.
. wire DoneU3;
. b_funcmod U3
. (
. .iCall( CallU1[] ),
. .oDone( DoneU3 ),
. ...
. );
.
. wire DoneU4;
. varibale_savemod U1
. (
. .iCall( CallU1[] ),
. .oDone( DoneU4 ),
. ...
. );
.
. endmodule
代码14.18
如代码14.18所示,组合模块的内容包含,main控制模块为实例U1,a功能模块与b功能模块为实例U2~U3,variable储存模块为实例 U4。最后,各个模块经由问答信号 Call/Done 联系起来。
前面的例子告诉我们,描述语言在变量上的运用,远远不及顺序语言那么便捷,毕竟描述语言没有底层补助,而且模仿它人也超麻烦。话虽如此,这是描述语言的缺点也是优点 ... 优点?笔者有没有搞错?那么麻烦还称为优点,笔者是不是脑子进水了?这位同学别猴急,笔者会慢慢解释的。
. unsigned char LUT[] = { , , , };
. int main()
. {
. int D1;
. D1 = LUT[] + LUT[];
. ...
. }
代码14.19
如代码14.19所示,第1行声明位宽为8,长度为4的LUT查表,第2~7行则是查表的运用。表面上,顺序语言虽有惊人的便捷性,不过底子里却是一片死残,尤其是时钟的利用率更是惨不忍睹。那些写过算法的同学一定知道,查表常常用来优化算法的运算速度 ... 简单来说,查表就是顺序语言“空间换速度”的优化手段。
查表既是ROM也是一种储存方式。如果把话说难听一点,所谓查表也不过是顺序语言在利用数组模仿ROM而已,它除了便捷性好以外,无论是资源的消耗,还是时钟的消耗等效率都远远不及描述语言的ROM。顺序语言偶尔虽然也有山寨的FIFO,Shift等储存方式,不过性能却是差强人意。
顺序语言之所以那么逊色,那是因为被钢铁一般坚固的顺序结构绑得死死。述语言是自由的语言,结构也是自由。虽然自由结构为人们带来许多麻烦,但是“储存方式”可以描述的范畴,绝对超乎人们的估量。归根究底,究竟是顺序语言好,还是描述语言模比较厉害呢?除了见仁见智以外,答案也只有天知晓。
随着时代不断变迁,“储存方式”的需求也逐渐成长,例如50年代需要rom,60年代需要ram,70年代需要 fifo。二十一世纪的今天,保守的规范再也无法压抑“储存方式”的放肆衍生,例如rom衍生出来静态rom,单口rom,双口rom等许多亚种;此外,fifo也衍生出同步fifo或者异步fifo等亚种。至于ram的亚种,比前两者更加恐怖!不管怎么样,大伙都是笔者的好孩子,亦即 ××_savemod。
虽然伟大的官方早已准备数之不尽的储存模块,但是笔者还是强调手动建模比较好,因为官方的东西有太多限制了。此刻,可能有人跳出来反驳道:“为什么不用官方插件模块,它们既完整又便捷,那个白痴才不吃天上掉下来的馅饼!笔者是呆子!蠢货!“。话说这位同学也别那么激动,如果读者一路索取它人的东西,学习只会本末倒置而已。
除此之外,官方插件模块是商业的产物,不仅自定义有限内容也是隐性,而且还是不择不扣的快餐。快餐即美味也方便,偶尔吃下还不错,但是长期食用就会危害健康,危害学习。
“fifo插件的数据位宽能不能设为11位?”,某人求救道。
“ram插件怎样调用?怎样仿真?”,某人求救道。
类似问题每月至少出现数十次,而且还是快餐爱好者提问的。笔者也有类似的经验,所以非常明白这种心境。年轻的笔者就是爱好快餐,凡事拿来主义,伸手比吃饭更多。渐渐地,笔者愈来愈懒,能不增反降,最终变成只会求救的肥仔而已。后悔以后,笔者才脚踏实地自力建模,慢慢减肥。
在此,笔者滔滔不绝只想告知读者 ... 自由结构虽然麻烦,不过这是将想象力具体化的关键因素,储存模块的潜能远超保守的规范。规范有时候就像一粒绊脚石,让人不经意跌倒一次又一次,阻碍人们前进,限制人们想象,最后让人成为不动手即不动脑的懒人。最后,让我们建立一只不规格又畸形的储存模块作为本实验的句号。
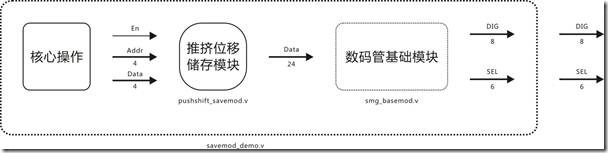
图14.3 实验十四的建模图。
图14.3是实验十四的建模图,组合模块 savemod_demo 的内容包括一支核心操作,一只数码管基础模块,还有一只名字帅到掉渣的储存模块。核心操作会拉高 oEn,并且将相关的 Addr 与 Data 写入储存模块,紧接着该储存模块会经由 oData驱动数码管基础模块。事不宜迟,让我们先来瞧瞧推挤位移储存模块这位帅哥。
pushshift_savemod.v

图14.4 推挤位移储存模块的建模图。
顾名思义,该模块是推挤功能再加上位移功能的储存模块,左边是储存模块常见的iEn,iAddr与iData,右边则是超乎常规的oData。
. module pushshift_savemod . ( . input CLOCK,RESET, . input iEn, . input [:]iAddr, . input [:]iData, . output [:]oData . ); 第3~7行是相关的出入端声明。 . reg [:] RAM [:]; . reg [:] D1; . . always @ ( posedge CLOCK or negedge RESET ) . if( !RESET ) . begin . D1 <= 'd0; . end 第9行是片上内存RAM的声明,第10行则是寄存器D1的声明。第15行则是D1的复位操作。 . else if( iEn ) . begin . RAM[ iAddr ] <= iData; . D1[:] <= RAM[ iAddr ]; . D1[:] <= D1[:]; . D1[:] <= D1[:]; . D1[:] <= D1[:]; . D1[:] <= D1[:]; . D1[:] <= D1[:]; . end . . assign oData = D1; . . endmodule
第17行表示 iEn不拉高该模块就不工作。第18~26行是该模块的核心操作,第19行表示RAM将iData储存至 iAddr指定的位置;第20行表示,RAM将iAddr指定的内容赋予D1[3:0]。如此一来,第19行与第20行的结合就成为推挤功能。至于第21~25行则是6个深度的位移功能(即4位宽为一个深度), iEn每拉高一个时钟,D1的内容就向左移动一个深度。
savemod_demo.v
该组合模块的连线部署根据图14.3,具体内容我们还是来看代码吧。
. module savemod_demo
. (
. input CLOCK,RESET,
. output [:]DIG,
. output [:]SEL
. );
以上内容是相关的出入端声明。
. reg [:]i;
. reg [:]D1,D2; // D1 for Address, D2 for Data
. reg isEn;
.
. always @ ( posedge CLOCK or negedge RESET ) // Core
. if( !RESET )
. begin
. i <= 'd0;
. { D1,D2 } <= 'd0;
. isEn <= 'b0;
. end
. else
以上内容是相关的寄存器声明以及复位操作。其中D1用来暂存地址数据,D2用来暂存读写数据。第12~17行是这些寄存器的复位操作。
. case( i ) . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'hA; i <= i + 1'b1; end . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'hB; i <= i + 1'b1; end . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'hC; i <= i + 1'b1; end . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'hD; i <= i + 1'b1; end . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'hE; i <= i + 1'b1; end . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'hF; i <= i + 1'b1; end . . : . begin isEn <= 'b1; D1 <= 4'd0; D2 <= 'h0; i <= i + 1'b1; end . . : . begin isEn <= 'b0; i <= i; end . . endcase .
以上内容为核心操作,操作过程如下:
步骤0为地址0写入数据 4’hA;,将原本的数据挤出来,并且发生位移。
步骤1为地址0写入数据 4’hB;,将4’hA挤出来,并且发生位移。
步骤2为地址0写入数据 4’hC;,将4’hB挤出来,并且发生位移。
步骤3为地址0写入数据 4’hD;,将4’hC挤出来,并且发生位移。
步骤4为地址0写入数据 4’hE;,将4’hD挤出来,并且发生位移。
步骤5为地址0写入数据 4’hF,将4’hE挤出来,并且发生位移。
步骤6为地址0写入数据 4’d0,将4’hF挤出来,并且发生位移。
步骤7结束操作。

图14.5 savemod_demo 部分时序图。
图14.5是 savemod_demo 部分重要的理想时序图,其中isEn,D1与D2 是核心操作所发送的数据,至于RAM[0]与oData是推挤位移储存模块的内部状况与输出结果。时序过程如下:
T0,核心操作拉高isEn,发送4’d0地址数据与4’hA读写数据。
T1,核心操作拉高isEn,发送4’d0地址数据与4’hB读写数据。储存模块将4’hA载入地址0。
T2,核心操作拉高isEn,发送4’d0地址数据与4’hC读写数据。储存模块将4’hB载入地址0,并且将数据 4’hA挤出,oData的结果为 24’h00000A。
T3,核心操作拉高isEn,发送4’d0地址数据与4’hD读写数据。储存模块将4’hC载入地址0,并且将数据 4’hB挤出,同时发生位移,oData的结果为 24’h0000AB。
T4,核心操作拉高isEn,发送4’d0地址数据与4’hE读写数据。储存模块将4’hD载入地址0,并且将数据 4’hC挤出,同时发生位移,oData的结果为 24’h000ABC。
T5,核心操作拉高isEn,发送4’d0地址数据与4’hF读写数据。储存模块将4’hE载入地址0,并且将数据 4’hD挤出,同时发生位移,oData的结果为 24’h00ABCD。
T6,核心操作拉高isEn,发送4’d0地址数据与4’d0读写数据。储存模块将4’hF载入地址0,并且将数据 4’hE挤出,同时发生位移,oData的结果为 24’h0ABCDE。
T7,储存模块将4’d0载入地址0,并且将数据 4’hF挤出,同时发生位移,oData的结果为 24’hABCDEF。
. wire [:]DataU1; . . pushshift_savemod U1 . ( . .CLOCK( CLOCK ), . .RESET( RESET ), . .iEn( isEn ), // < Core . .iAddr( D1 ), // < Core . .iData( D2 ), // < Core . .oData( DataU1 ) // > U2 . ); .
第47~58行是该储存模块的实例化。
. smg_basemod U2 . ( . .CLOCK( CLOCK ), . .RESET( RESET ), . .DIG( DIG ), // top . .SEL( SEL ), // top . .iData( DataU1 ) // < U1 . ); . . endmodule
第59~66行是数码管基础模块的实例化。编译完毕便下载程序,如果数码管从左至右显示“ABCDEF”,那么表示实验成功。最后还是要强调一下,推挤位移目前是没有意义的储存模块,可是实验十四的目的也非常清楚,就是解释储存模块,演示畸形的储存模块。
【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验十四:储存模块的更多相关文章
- [黑金原创教程] FPGA那些事儿《设计篇 III》- 图像处理前夕·再续
简介 一本为入门图像处理的入门书,另外还教你徒手搭建平台(片上系统),内容请看目录. 注意 为了达到最好的实验的结果,请准备以下硬件. AX301开发板, OV7670摄像模块, VGA接口显示器, ...
- [黑金原创教程] FPGA那些事儿《设计篇 II》- 图像处理前夕·续
简介 一本为入门图像处理的入门书,另外还教你徒手搭建平台(片上系统),内容请看目录. 注意 为了达到最好的实验的结果,请准备以下硬件. AX301开发板, OV7670摄像模块, VGA接口显示器, ...
- [黑金原创教程] FPGA那些事儿《设计篇 I》- 图像处理前夕
简介 一本为入门图像处理的入门书,另外还教你徒手搭建平台(片上系统),内容请看目录. 注意 为了达到最好的实验的结果,请准备以下硬件. AX301开发板, OV7670摄像模块, VGA接口显示器, ...
- [黑金原创教程] FPGA那些事儿《数学篇》- CORDIC 算法
简介 一本为完善<设计篇>的书,教你CORDIC算法以及定点数等,内容请看目录. 贴士 这本教程难度略高,请先用<时序篇>垫底. 目录 Experiment 01:认识CORD ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】原创教程连载导读【连载完成,共二十九章】
前言: 无数昼夜的来回轮替以后,这本<驱动篇I>终于编辑完毕了,笔者真的感动到连鼻涕也流下来.所谓驱动就是认识硬件,还有前期建模.虽然<驱动篇I>的硬件都是我们熟悉的老友记,例 ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验十五:FIFO储存模块(同步)
实验十五:FIFO储存模块(同步) 笔者虽然在实验十四曾解释储存模块,而且也演示奇怪的家伙,但是实验十四只是一场游戏而已.至于实验十五,笔者会稍微严肃一点,手动建立有规格的储存模块,即同步FIFO.那 ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】连载导读
前言: 无数昼夜的来回轮替以后,这本<驱动篇I>终于编辑完毕了,笔者真的感动到连鼻涕也流下来.所谓驱动就是认识硬件,还有前期建模.虽然<驱动篇I>的硬件都是我们熟悉的老友记,例 ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验十:PS/2模块④ — 普通鼠标
实验十:PS/2模块④ - 普通鼠标 学习PS/2键盘以后,接下来就要学习 PS/2 鼠标.PS/2鼠标相较PS/2键盘,驱动难度稍微高了一点点,因为FPGA(从机)不仅仅是从PS/2鼠标哪里读取数据 ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验十八:SDRAM模块① — 单字读写
实验十八:SDRAM模块① — 单字读写 笔者与SDRAM有段不短的孽缘,它作为冤魂日夜不断纠缠笔者.笔者尝试过许多方法将其退散,不过屡试屡败的笔者,最终心情像橘子一样橙.<整合篇>之际, ...
随机推荐
- 机器学习——使用Apriori算法进行关联分析
从大规模的数据集中寻找隐含关系被称作为关联分析(association analysis)或者关联规则学习(association rule learning). Apriori算法 优点:易编码实现 ...
- Lucas-Kanade算法总结
Lucas-Kanade算法广泛用于图像对齐.光流法.目标追踪.图像拼接和人脸检测等课题中. 一.核心思想 给定一个模板和一个输入,以及一个或多个变换,求一个参数最佳的变换,使得下式最小化 在求最优解 ...
- 安卓开发笔记——WebView组件
我们专业方向本是JAVA Web,这学期突然来了个手机App开发的课设,对于安卓这块,之前自学过一段时间,有些东西太久没用已经淡忘了 准备随笔记录些复习笔记,也当做温故知新吧~ 1.什么是WebVie ...
- 使用 SharpSvn 执行 svn 操作的Demo
1. SharpSvn简介 SharpSvn.dll 是为.Net 2.0-4.0+ 应用提供的 Subversion Client API,更多详细介绍请见 https://sharpsvn.ope ...
- rlwrap安装报错You need the GNU readline 解决方法
首先大家肯定知道rlwrap是干什么的? 在linux以及unix中,sqlplus的上下左右.回退无法使用,会出现乱码情况.而rlwrap这个软件就是用来解决这个的. 这个错误曾经困扰我很久很久 ...
- express项目创建步骤
安装nodejs 安装npm 安装express npm install -g express 安装express生成器 npm install -g express-generator 查看expr ...
- “NHibernate.Cfg.Configuration 的类型初始值设定项引发异常。”的解决方法【备忘】
今天搞到NHibernate时,突然报了一个“NHibernate.Cfg.Configuration 的类型初始值设定项引发异常.”的异常. 详细异常信息“System.IO.FileLoadExc ...
- phpcms 字符截取str_cut的使用
PHPCMS中截取字符串用的是 str_cut 系统函数,通常在输出标题或者是内容摘要的时候使用来限制字符串的字符,这样就可以防止因字符串而变成的页面变形等问题. 我们来看一下这个函数,在PHPCMS ...
- 【11-13】A股主要指数的市盈率(PE)估值高度
全指材料(SH000987) - 2018-11-13日,当前值:12.4646,平均值:30.54,中位数:26.09865,当前 接近历史新低.全指材料(SH000987)的历史市盈率PE详情 内 ...
- xcode修改默认头部注释(__MyCompanyName__) (转)
打开命令行: defaults write com.apple.Xcode PBXCustomTemplateMacroDefinitions '{ "ORGANIZATIONNAME&qu ...