训练/验证/测试集设置;偏差/方差;high bias/variance;正则化;为什么正则化可以减小过拟合
1. 训练、验证、测试集
对于一个需要解决的问题的样本数据,在建立模型的过程中,我们会将问题的data划分为以下几个部分:
- 训练集(train set):用训练集对算法或模型进行训练过程;
- 验证集(development set):利用验证集或者又称为简单交叉验证集(hold-out cross validation set)进行交叉验证,选择出最好的模型;
- 测试集(test set):最后利用测试集对模型进行测试,获取模型运行的无偏估计。
小数据时代
在小数据量的时代,如:100、1000、10000的数据量大小,可以将data做以下划分:
无验证集的情况:70% / 30%;
有验证集的情况:60% / 20% / 20%;
通常在小数据量时代,以上比例的划分是非常合理的。
大数据时代
但是在如今的大数据时代,对于一个问题,我们拥有的data的数量可能是百万级别的,所以验证集和测试集所占的比重会趋向于变得更小。
验证集的目的是为了验证不同的算法哪种更加有效,所以验证集只要足够大能够验证大约2-10种算法哪种更好就足够了,不需要使用20%的数据作为验证集。如百万数据中抽取1万的数据作为验证集就可以了。
测试集的主要目的是评估模型的效果,如在单个分类器中,往往在百万级别的数据中,我们选择其中1000条数据足以评估单个模型的效果。
- 100万数据量:98% / 1% / 1%;
- 超百万数据量:99.5% / 0.25% / 0.25%(或者99.5% / 0.4% / 0.1%)
Notation
建议验证集要和训练集来自于同一个分布,可以使得机器学习算法变得更快;
如果不需要用无偏估计来评估模型的性能,则可以不需要测试集。
2. 偏差、方差
对于下图中两个类别分类边界的分割:

从图中我们可以看出,在欠拟合(underfitting)的情况下,出现高偏差(high bias)的情况;在过拟合(overfitting)的情况下,出现高方差(high variance)的情况。
在bias-variance tradeoff 的角度来讲,我们利用训练集对模型进行训练就是为了使得模型在train集上使 bias 最小化,避免出现underfitting的情况;
但是如果模型设置的太复杂,虽然在train集上 bias 的值非常小,模型甚至可以将所有的数据点正确分类,但是当将训练好的模型应用在dev 集上的时候,却出现了较高的错误率。这是因为模型设置的太复杂则没有排除一些train集数据中的噪声,使得模型出现overfitting的情况,在dev 集上出现高 variance 的现象。
所以对于bias和variance的权衡问题,对于模型来说是一个十分重要的问题。
例子:
几种不同的情况:

以上为在人眼判别误差在0%的情况下,该最优误差通常也称为“贝叶斯误差”,如果“贝叶斯误差”大约为15%,那么图中第二种情况就是一种比较好的情况。
High bias and high variance的情况
上图中第三种bias和variance的情况出现的可能如下:

没有找到边界线,但却在部分数据点上出现了过拟合,则会导致这种高偏差和高方差的情况。
虽然在这里二维的情况下可能看起来较为奇怪,出现的可能性比较低;但是在高维的情况下,出现这种情况就成为可能。
3. 机器学习的基本方法
在训练机器学习模型的过程中,解决High bias 和High variance 的过程:

- 1.是否存在High bias ?
增加网络结构,如增加隐藏层数目;
训练更长时间;
寻找合适的网络架构,使用更大的NN结构;- 2.是否存在High variance?
获取更多的数据;
正则化( regularization);
寻找合适的网络结构;
在大数据时代,深度学习对监督式学习大有裨益,使得我们不用像以前一样太过关注如何平衡偏差和方差的权衡问题,通过以上方法可以使得再不增加另一方的情况下减少一方的值。
4. 正则化(regularization)
利用正则化来解决High variance 的问题,正则化是在 Cost function 中加入一项正则化项,惩罚模型的复杂度。
Logistic regression


5. 为什么正则化可以减小过拟合
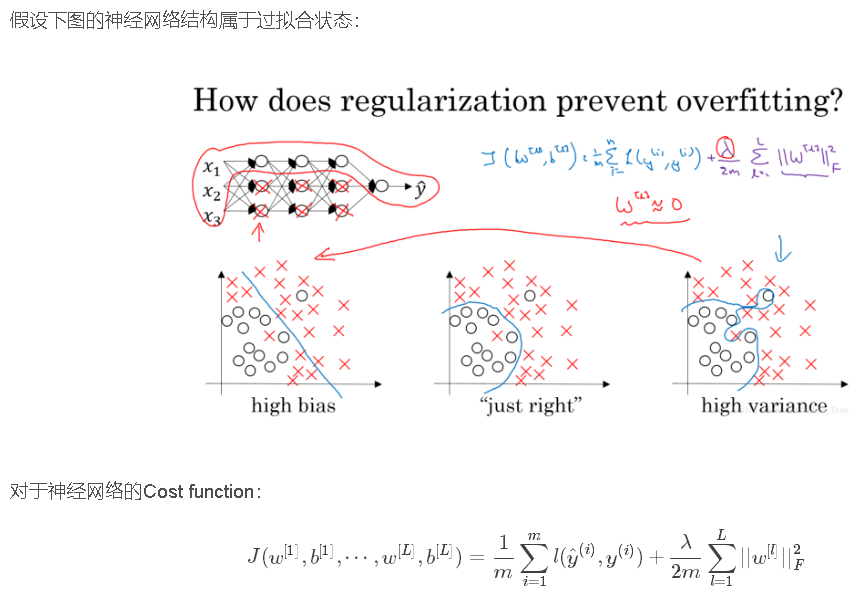
加入正则化项,直观上理解,正则化因子λ设置的足够大的情况下,为了使代价函数最小化,权重矩阵W就会被设置为接近于0的值。则相当于消除了很多神经元的影响,那么图中的大的神经网络就会变成一个较小的网络。
当然上面这种解释是一种直观上的理解,但是实际上隐藏层的神经元依然存在,但是他们的影响变小了,便不会导致过拟合。
数学解释

训练/验证/测试集设置;偏差/方差;high bias/variance;正则化;为什么正则化可以减小过拟合的更多相关文章
- 【笔记】偏差方差权衡 Bias Variance Trade off
偏差方差权衡 Bias Variance Trade off 什么叫偏差,什么叫方差 根据下图来说 偏差可以看作为左下角的图片,意思就是目标为红点,但是没有一个命中,所有的点都偏离了 方差可以看作为右 ...
- 偏差和方差以及偏差方差权衡(Bias Variance Trade off)
当我们在机器学习领域进行模型训练时,出现的误差是如何分类的? 我们首先来看一下,什么叫偏差(Bias),什么叫方差(Variance): 这是一张常见的靶心图 可以看左下角的这一张图,如果我们的目标是 ...
- 机器学习入门06 - 训练集和测试集 (Training and Test Sets)
原文链接:https://developers.google.com/machine-learning/crash-course/training-and-test-sets 测试集是用于评估根据训练 ...
- TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集
TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集 前提是TensorFlow环境以及相关的依赖环境已经安装,可以正常运行. 一.下载FaceNet源代码工程 git clone ...
- 随机切分csv训练集和测试集
使用numpy切分训练集和测试集 觉得有用的话,欢迎一起讨论相互学习~Follow Me 序言 在机器学习的任务中,时常需要将一个完整的数据集切分为训练集和测试集.此处我们使用numpy完成这个任务. ...
- sklearn学习3----模型选择和评估(1)训练集和测试集的切分
来自链接:https://blog.csdn.net/zahuopuboss/article/details/54948181 1.sklearn.model_selection.train_test ...
- sklearn——train_test_split 随机划分训练集和测试集
sklearn——train_test_split 随机划分训练集和测试集 sklearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http: ...
- Sklearn-train_test_split随机划分训练集和测试集
klearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http://scikit-learn.org/stable/modules/gener ...
- sklearn获得某个参数的不同取值在训练集和测试集上的表现的曲线刻画
from sklearn.svm import SVC from sklearn.datasets import make_classification import numpy as np X,y ...
随机推荐
- 四、K3 WISE 开发插件《工业单据老单插件开发新手指导》
开发环境:K/3 Wise 13.0.K/3 Bos开发平台.Visual Basic 6.0 =============================================== 目录 一 ...
- 【Spring源码分析系列】bean的加载
前言 以 BeanFactory bf = new XmlBeanFactory(new ClassPathResource("beans.xml"));为例查看bean的加载过 ...
- CSS3 渐变效果
CSS3 渐变效果 background-image: -moz-linear-gradient(top, #8fa1ff, #3757fa); /* Firefox */ background-im ...
- 第四步 使用 adt-eclipse 打包 Cordova (3.0及其以上版本) + sencha touch 项目
cordova最新中文api http://cordova.apache.org/docs/zh/3.1.0/ 1.将Cordova 生成的项目导入到adt-eclipse中,如下: 项目结构如下: ...
- ssh命令远程登录
1.查看SSH客户端版本 有的时候需要确认一下SSH客户端及其相应的版本号.使用ssh -V命令可以得到版本号.需要注意的是,Linux一般自带的是OpenSSH: 下面的例子即表明该系统正在使用Op ...
- 查看docker容器的IP地址
|awk '{print $2}' |tr '"' " " |tr ',' ' ' # 可以用容器id或名称 方法二: docker inspect --fo ...
- 去掉VS2010代码中文注释的红色下划线
VS2010代码中文注释出现红色下划线,代码看上去很不美观,发现是由于安装Visual Assist X插件造成的. 解决办法:打开VAX的Options对话框,取消Advanced --> U ...
- 【读书笔记】socket描述符选项[SOL_SOCKET]
#include <sys/socket.h> int setsockopt( int socket, int level, int option_name, ...
- JiraRemoteUserAuth
配置Jira7.x版本使用REMOTE_USER的HTTP Header方式登录: 前提是已经安装好了JIRA,并且前端使用apache或者nginx拦截对应的地址进行认证,认证之后访问对应的应用的时 ...
- 【转】RTMP/RTP/RTSP/RTCP协议对比与区别介绍
用一句简单的话总结:RTSP发起/终结流媒体.RTP传输流媒体数据 .RTCP对RTP进行控制,同步. 之所以以前对这几个有点分不清,是因为CTC标准里没有对RTCP进行要求,因此在标准RTSP的代码 ...