Java并发容器——ConcurrentSkipListMap和ConcurrentHashMap
一:ConcurrentSkipListMap
TreeMap使用红黑树按照key的顺序(自然顺序、自定义顺序)来使得键值对有序存储,但是只能在单线程下安全使用;多线程下想要使键值对按照key的顺序来存储,则需要使用ConcurrentSkipListMap。
ConcurrentSkipListMap的底层是通过跳表来实现的。跳表是一个链表,但是通过使用“跳跃式”查找的方式使得插入、读取数据时复杂度变成了O(logn)。
跳表(SkipList):使用“空间换时间”的算法,令链表的每个结点不仅记录next结点位置,还可以按照level层级分别记录后继第level个结点。在查找时,首先按照层级查找,比如:当前跳表最高层级为3,即每个结点中不仅记录了next结点(层级1),还记录了next的next(层级2)、next的next的next(层级3)结点。现在查找一个结点,则从头结点开始先按高层级开始查:head->head的next的next的next->。。。直到找到结点或者当前结点q的值大于所查结点,则此时当前查找层级的q的前一节点p开始,在p~q之间进行下一层级(隔1个结点)的查找......直到最终迫近、找到结点。此法使用的就是“先大步查找确定范围,再逐渐缩小迫近”的思想进行的查找。
例如:有当前的跳表存储如下:有4个层级,层级1为最下面的level,是一个包含了所有结点的普通链表。往上数就是2,3,4层级。
(注:图来自 http://blog.csdn.net/sunxianghuang/article/details/52221913,如有冒犯,请见谅)

现在,我们查找结点值为19的结点:

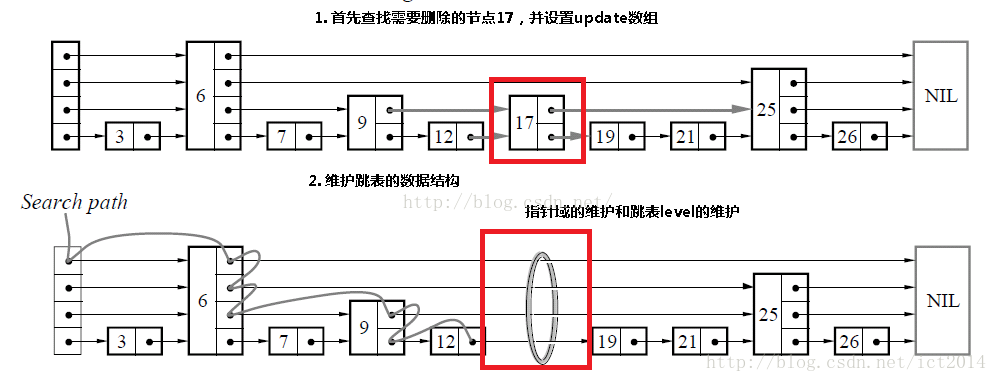
明白了查找的原理后,插入、删除就容易理解了。为了保存跳表的有序性,所以分三步:查找合适位置——进行插入/删除——更新跳表指针,维护层级性。
插入结点:
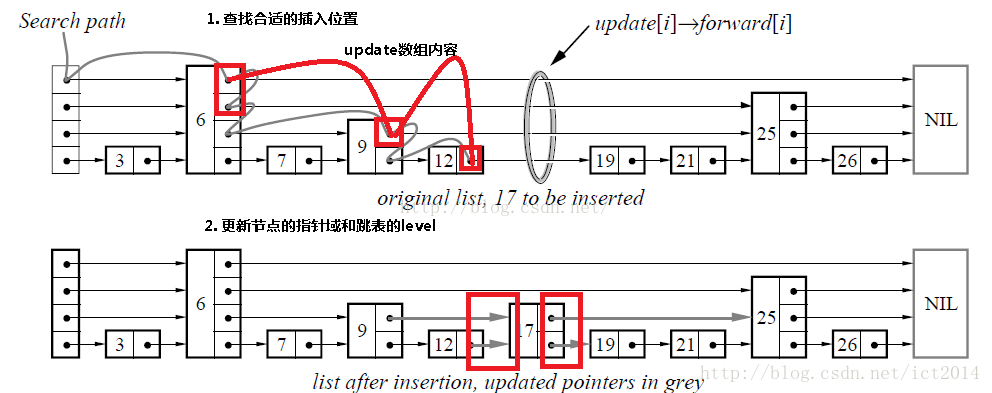
删除结点:
知道了底层所用数据结构的原理后,我们来看看concurrentskiplistmap的部分源码:
插入:
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为“key的前继节点的后继节点”,即n应该是“插入节点”的“后继节点”
Node<K,V> n = b.next;
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
// 如果两次获得的b.next不是相同的Node,就跳转到”外层for循环“,重新获得b和n后再遍历。
if (n != b.next)
break;
// v是“n的值”
Object v = n.value;
// 当n的值为null(意味着其它线程删除了n);此时删除b的下一个节点,然后跳转到”外层for循环“,重新获得b和n后再遍历。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// 如果其它线程删除了b;则跳转到”外层for循环“,重新获得b和n后再遍历。
if (v == n || b.value == null) // b is deleted
break;
// 比较key和n.key
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
// 新建节点(对应是“要插入的键值对”)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 设置“b的后继节点”为z
if (!b.casNext(n, z))
break; // 多线程情况下,break才可能发生(其它线程对b进行了操作)
// 随机获取一个level
// 然后在“第1层”到“第level层”的链表中都插入新建节点
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
删除:
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key的前继节点”
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
// f是“当前节点n的后继节点”
Node<K,V> f = n.next;
// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (n != b.next) // inconsistent read
break;
// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// 如果“前继节点b”被删除(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c < 0)
return null;
if (c > 0) {
b = n;
n = f;
continue;
}
// 以下是c=0的情况
if (value != null && !value.equals(v))
return null;
// 设置“当前节点n”的值为null
if (!n.casValue(v, null))
break;
// 设置“b的后继节点”为f
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // Retry via findNode
else {
// 清除“跳表”中每一层的key节点
findPredecessor(key); // Clean index
// 如果“表头的右索引为空”,则将“跳表的层次”-1。
if (head.right == null)
tryReduceLevel();
}
return (V)v;
}
}
}
查找:
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
// 如果“n为null”,则跳转中不存在key对应的节点,直接返回null。
if (n == null)
return null;
Node<K,V> f = n.next;
// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (n != b.next) // inconsistent read
break;
Object v = n.value;
// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
// 若n是当前节点,则返回n。
int c = key.compareTo(n.key);
if (c == 0)
return n;
// 若“节点n的key”小于“key”,则说明跳表中不存在key对应的节点,返回null
if (c < 0)
return null;
// 若“节点n的key”大于“key”,则更新b和n,继续查找。
b = n;
n = f;
}
}
}
通过上面的源码可以发现:ConcurrentSkipListMap线程安全的原理与非阻塞队列ConcurrentBlockingQueue的原理一样:利用底层的插入、删除的CAS原子性操作,通过死循环不断获取最新的结点指针来保证不会出现竞态条件。
二:ConcurrentHashMap【本文concurrentHashMap是jdk1.7中的实现,jdk1.8中使用的不是Segment,特此说明】
快速存取<Key, Value>键值对使用HashMap;多线程并发存取<Key, Value>键值对使用ConcurrentHashMap;
我们知道,HashTable和和Collections类中提供的同步HashTable是线程安全的,但是他们线程安全是通过在进行读写操作时对整个map加锁来实现的,故此性能比较低。那既然是由于锁粒度(加锁的范围叫锁粒度)太大造成的性能低下,可不可以从锁粒度着手去改良呢?由此,就引申出了ConcurrentHashMap。
ConcurrentHashMap采取了“锁分段”技术来细化锁的粒度:把整个map划分为一系列被成为segment的组成单元,一个segment相当于一个小的hashtable。这样,加锁的对象就从整个map变成了一个更小的范围——一个segment。ConcurrentHashMap线程安全并且提高性能原因就在于:对map中的读是并发的,无需加锁;只有在put、remove操作时才加锁,而加锁仅是对需要操作的segment加锁,不会影响其他segment的读写,由此,不同的segment之间可以并发使用,极大地提高了性能。
1:结构分析
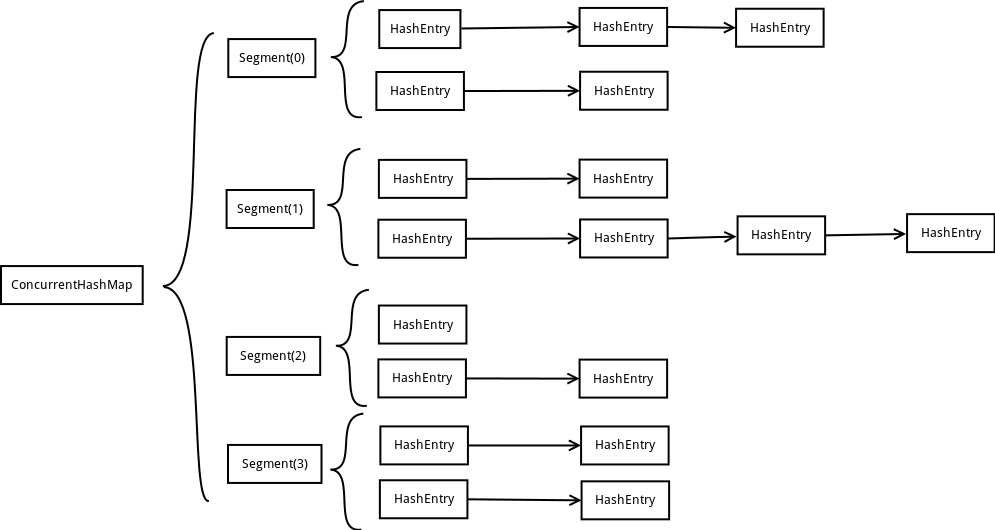
Segment的结构:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile int count;
transient int modCount;
transient int threshold;
transient volatile HashEntry<K,V>[] table;
final float loadFactor;
}
- count:Segment中元素的数量,用于map.size()时统计整个map的大小使用
- modCount:对table的大小造成影响的操作的数量(比如put或者remove操作),用于统计size时验证结果的正确性
- threshold:阈值,Segment里面元素的数量超过这个值依旧就会对Segment进行扩容,concurrenthashmap自身不会扩容(segment的数量在map创建后不会再增加,在容量不足时只会增加segment的容量)
- table:链表数组,数组中的每一个元素代表了一个链表的头部,一个链表用于存储相同hash值的不同元素们
- loadFactor:负载因子,用于确定threshold,决定扩容的时机
2:查询
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
由上面可以看到:concurrenthashmap的查询操作经过三步:第一次hash确定key在哪个segment中;第二次hash在segment中确定key在链表数组的哪个链表中;第三步遍历这个链表,调用equals()进行比对,找到与所查找key相等的结点并读取。
3:插入
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
插入过程也分三步:首先由key值经过hash计算得到是哪个segment,如果segment大小以及到达阀值则扩容;然后再次hash确定key所在链表的数组下标,获取链表头;最后遍历链表,如果找到相同的key的结点则更新value值,如果没有则插入新结点;
4:删除
segment的链表数组中的链表结构如下:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
我们可以看到,链表中结点只有value是可修改的,因此,如果我们需要删除结点时,是不能简单地由前继结点指向被删结点的后继结点来实现。所以,我们只能重构链表。
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
删除过程:首先由key经过hash确定所在segment;然后再hash确定具体的数组下标,获得链表头;最后遍历链表,找到被删除结点后,以被删除结点的next结点开始建立新的链表,然后再把原链表头直到被删结点的前继结点依次复制、插入新链表,最后把新链表头设置为当前数组下标元素取代旧链表。
5:统计大小—Size()
统计整个map的大小时,如果在统计过程中把整个map锁住,则会造成影响读写。ConcurrentHashMap通过采用segment中的属性成员来优化这个过程。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile int count;
transient int modCount;
....
}
我们看到,每个segment中有一个count记录当前segment的元素数量,每当put/remove成功就会把这个值+1/-1。因此,在统计map的大小时,我们把每个segment的count加起来就是了。但是,如果在加的过程中,发生了修改怎么办呢?比如:把segment[2]的count加到total后,segment[2]发生了remove操作,这样就会造成统计结果不正确。此时就需要用modCount,modCount记录了segment的修改次数,这个值只增不减,无论是插入、删除都会导致该值+1.
ConcurrentHashMap在统计size时,经历了两次遍历:第一次不加锁地遍历所以segment,统计count和modCount的总和得到C1和M1;然后再次不加锁地遍历,得到C2和M2,比较M1和M2,如果修改次数没有发生变化则说明两次遍历期间map没有发生数量变化,那么C1就是可用的。如果M1不等于M2,则说明在统计过程中map的数量发生了变化,此时才采取最终手段——锁住整个map进行统计。
Java并发容器——ConcurrentSkipListMap和ConcurrentHashMap的更多相关文章
- Java并发指南14:Java并发容器ConcurrentSkipListMap与CopyOnWriteArrayList
原文出处http://cmsblogs.com/ 『chenssy』 到目前为止,我们在Java世界里看到了两种实现key-value的数据结构:Hash.TreeMap,这两种数据结构各自都有着优缺 ...
- java 并发容器一之ConcurrentHashMap(基于JDK1.8)
上一篇文章简单的写了一下,BoundedConcurrentHashMap,觉得https://www.cnblogs.com/qiaoyutao/p/10903813.html用的并不多:今天着重写 ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
- Java 并发系列之六:java 并发容器(4个)
1. ConcurrentHashMap 2. ConcurrentLinkedQueue 3. ConcurrentSkipListMap 4. ConcurrentSkipListSet 5. t ...
- 【java并发容器】并发容器之CopyOnWriteArrayList
原文链接: http://ifeve.com/java-copy-on-write/ Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容 ...
- java并发初探ConcurrentSkipListMap
java并发初探ConcurrentSkipListMap ConcurrentSkipListMap以调表这种数据结构以空间换时间获得效率,通过volatile和CAS操作保证线程安全,而且它保证了 ...
- 《Java并发编程的艺术》第6/7/8章 Java并发容器与框架/13个原子操作/并发工具类
第6章 Java并发容器和框架 6.1 ConcurrentHashMap(线程安全的HashMap.锁分段技术) 6.1.1 为什么要使用ConcurrentHashMap 在并发编程中使用Has ...
- java 并发容器一之BoundedConcurrentHashMap(基于JDK1.8)
最近开始学习java并发容器,以补充自己在并发方面的知识,从源码上进行.如有不正确之处,还请各位大神批评指正. 前言: 本人个人理解,看一个类的源码要先从构造器入手,然后再看方法.下面看Bounded ...
- Java并发容器--ConcurrentHashMap
引子 1.不安全:大家都知道HashMap不是线程安全的,在多线程环境下,对HashMap进行put操作会导致死循环.是因为多线程会导致Entry链表形成环形数据结构,这样Entry的next节点将永 ...
随机推荐
- IIS回收后首次访问慢问题
禁用时间间隔回收 设置为0 然后设置指定时间回收 0:00:00 然后设置脚本 @echo off @echo 正在关掉所有的IE进程(需要设置默认浏览器是IE) taskkill /im iexpl ...
- Javascript 对象(object)合并
对象的合并 需求:设有对象 o1 ,o2,需要得到对象 o3 var o1 = { a:'a' }, o2 = { b:'b' }; // 则 var o3 = { a:'a', b:'b' } 方法 ...
- iOS:创建撒花动画
一.介绍 在很多的游戏中,会有这么一个桥段,就是闯关成功后,会弹出一个奖品同时出现很多的鲜花或者笑脸.例如微信中祝福生日时,出现蛋糕等等.那么,这次我就来实现这个功能. 二.实现原理 对外接收一个图片 ...
- Cesium中导入三维模型方法(dae到glft/bgltf) 【转】
http://blog.csdn.net/l491453302/article/details/46766909 目录(?)[+] Cesium中目前支持gltf和bgltf两种格式.“gltf是kh ...
- windows server 2008 r2 启用索引(转)
08r2的“windows search”服务默认是不安装的,要想启用索引执行下列步骤: 1.打开“服务器管理”——选中“角色”——右边选中“添加角色”——勾选“文件服务”. 2. ...
- Redis2.2.2源码学习——Server&Client链接的建立以及相关Event
Redis中Server和User建立链接(图中的client是服务器端用于描述与客户端的链接相关的信息) Redis Server&Client链接的建立时相关Event的建立(图中的cli ...
- 条件随机场CRF HMM,MEMM的区别
http://blog.sina.com.cn/s/blog_605f5b4f010109z3.html 首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模,像词性标 ...
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
http://blog.csdn.net/dark_scope/article/details/17228643 〇.说明 本文的所有代码均可在 DML 找到,欢迎点星星. 一.引入 推荐系统(主要是 ...
- C#字符串比较
正确写法1 bool bTemplatecontent2 = strtemplateContentInDB.Equals(strTemplateContentInDesignPanel, String ...
- 腾讯下载的视频转换为MP4
第一步:首先找到腾讯视频下载设置中的缓存目录,如下图 打开这个目录,找到最近的,就是刚才你下载的文件夹 打开最近的文件夹,如下图,copy里面的内容到D盘的qlv目录中 第二部:进入D盘的qlv目录, ...