Spark分布式集群的搭建和运行
集群共三台CentOS虚拟机,一个Matser,主机名为master;三个Worker,主机名分别为master、slave03、slave04。前提是Hadoop和Zookeeper已经安装并且开始运行。
1. 在master上下载Scala-2.11.0.tgz,复制到/opt/下面,解压,在/etc/profile加上语句:
export SCALA_HOME=/opt/scala-2.11.0
export PATH=$PATH:$SCALA_HOME/bin
然后运行命令:
source /etc/profile
在slave03、slave04上也执行相同的操作。
2. 在master上下载spark-2.1.0-bin-hadoop2.6,复制到/opt/下面。解压,在/etc/profile加上语句:
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
然后运行命令:
source /etc/profile
3. 编辑${SPARK_HOME}/conf/spark-env.sh文件,增加下面的语句:
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_121
# SCALA_HOME
export SCALA_HOME=/opt/scala-2.11.0
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
# Master主机名
export SPARK_MASTER_HOST=master
# Worker的内存大小
export SPARK_WORKER_MEMORY=1g
# Worker的Cores数量
export SPARK_WORKER_CORES=1
# SPARK_PID路径
export SPARK_PID_DIR=$SPARK_HOME/tmp
# Hadoop配置文件路径
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0-cdh5.9.0/etc/hadoop
# Spark的Recovery Mode、Zookeeper URL和路径
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:12181,slave03:12181,slave04:12181 -Dspark.deploy.zookeeper.dir=/spark"
在${SPARK_HOME}/conf/slaves中增加:
matser
slave03
slave04
这样就设置了三个Worker。
修改文件结束以后,将${SPARK_HOME}用scp复制到slave03和slave04。
4. 在master上进入${SPARK_HOME}/sbin路径,运行:
./start-master.sh
这是启动Master。
再运行:
./start-slaves.sh
这是启动Worker。
5. 在master上运行jps,如果有Master和Worker表明启动成功:
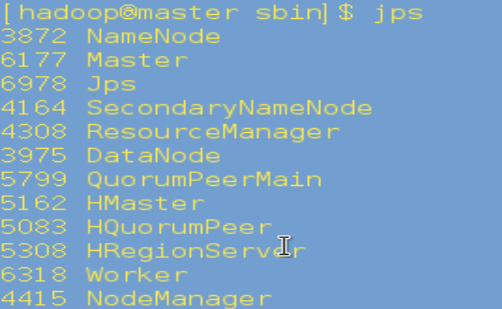
在slave03、slave04上运行jps,有Worker表明启动成功:
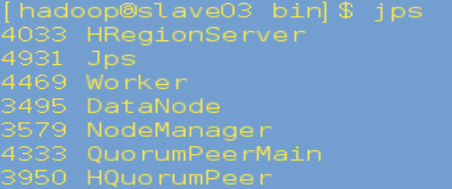
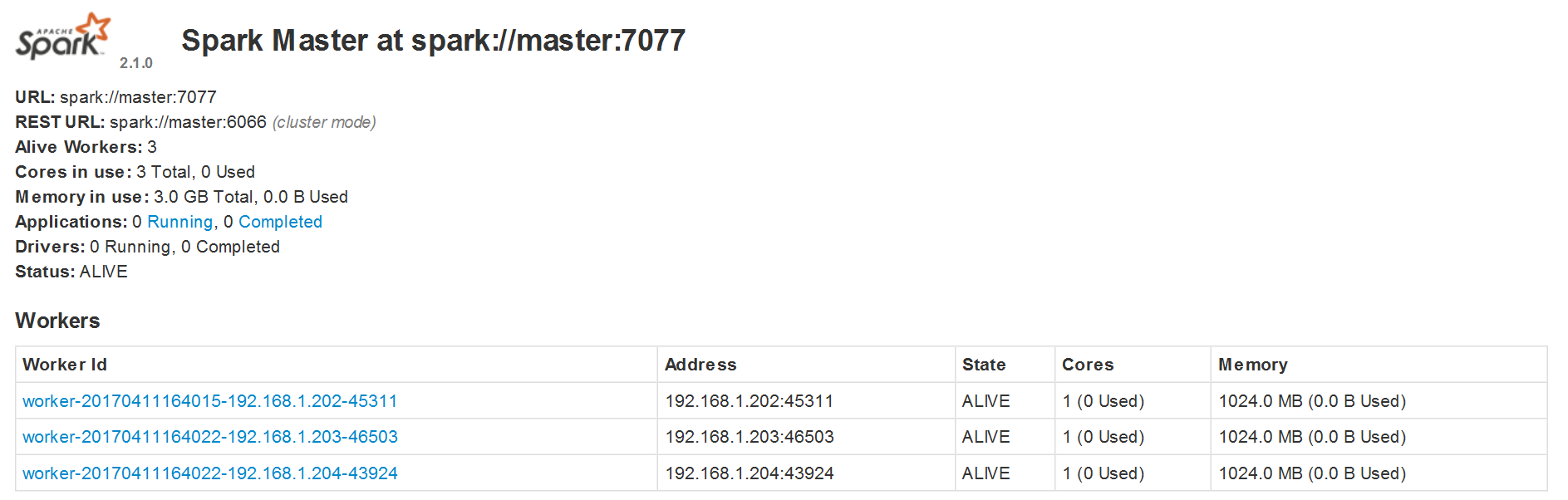
6. 访问http://master:8081,出现下面的页面表明启动成功:
Spark分布式集群的搭建和运行的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
随机推荐
- Tomcat集群下获取memcached缓存对象数量,统计在线用户数据量
项目需要统计在线用户数量,系统部署在集群环境下,使用会话粘贴的方式解决Session问题.要想得到真实在线用户数,必须是所有节点的总和. 这里考虑使用memcached存放用户登录数据,key为use ...
- 【机器学习算法-python实现】矩阵去噪以及归一化
1.背景 项目须要,打算用python实现矩阵的去噪和归一化.用numpy这些数学库没有找到非常理想的函数.所以一怒之下自己用标准库写了一个去噪和归一化的算法,效率有点低,只是还能用,大家假设有 ...
- [Linux] ubuntu各目录含义
/boot/: 启动文件,所有与系统启动有关的文件都保存在这里 /boot/grub/:grub引导器相关的配置文件都在这里 /dev/:此目录中保存了所有设备文件,例如,使用的分区:/dev/hda ...
- Kubernetes中StatefulSet介绍
StatefulSet 是Kubernetes1.9版本中稳定的特性,本文使用的环境为 Kubernetes 1.11.如何搭建环境可以参考kubeadm安装kubernetes V1.11.1 集群 ...
- Leetcode刷题记录:编码并解码短网址
题目要求 编写一个类,提供两个方法.一个可以将普通的网址编码成短网址,一个可以将短网址还原为普通网址. 参考题解 # 使用随机函数,生成短网址,保存在dict中,避免重复 import random ...
- iOS开发--知识点总结
1 .全局变量,变量名前加下划线.和系统一致. 2 . nil指针为空 @“”字符串为空 (内容为空) == 判断内存地址 基本变量 对于一些基本类型 可以使用==来判断, ...
- knockout示例
最近项目需要用到knockout js,有关knockout的介绍网上已经很多很多了,但是很少有比较全面的示例,于是乎我就自己做了一个小demo,已备以后查阅.knockout经常和knockout. ...
- SharePoint2010 对象模型 关联列表
有关列表的创建其实网上已经有很多文章了,其中练习 :利用Visual Studio 2010创建列表这篇文章个人感觉还不错,这里我强调的是对象模型来创建.在这之前我插入一点其他的东东,导入电子表格和数 ...
- [leetcode]Reverse Linked List II @ Python
原题地址:https://oj.leetcode.com/problems/reverse-linked-list-ii/ 题意: Reverse a linked list from positio ...
- {{jQuery源码分析}}jQuery对象初始化的多种传参数形式
jQuery对象初始化的传参方式包括:1.$(DOMElement)2.$('<h1>...</h1>'), $('#id'), $('.class') 传入字符串, 这是最常 ...