Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案
随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战。下面分享下对实际10万+峰值的平台的数据库优化方案。与大家一起讨论,互相学习提高!
案例:游戏平台.
1、解决高并发
当客户端连接数达到峰值的时候,服务端对连接的维护与处理这里暂时不做讨论。当多个写请求到数据库的时候,这时候需要对多张表进行插入,尤其一些表 达到每天千万+的存储,随着时间的积累,传统的同步写入数据的方式显然不可取,经过试验,通过异步插入的方式改善了许多,但与此同时,对读取数据的实时性也需要做一定的牺牲。
异步的方式有很多,目前采取的方式是通过作业每隔一段时间(5min、10min..看需求设定)将临时表的数据转到真实表。
1.已有原始表A 也是在读取的时候真正用到的表。
2.建立与原始表A同结构的B和C,用来作数据的中转处理,同步流程是C->B->A。
3.建立同步数据的作业Job1和记录Job1运行状态的表,在同步的时候比较关键的是需要检查Job1的当前状态,如果当前正在将B的数据同步到A,则把服务端过来的数据存到C,然后再把数据导入到B,等到下一次Job执行的时候再将这批数据转到A。如图1:
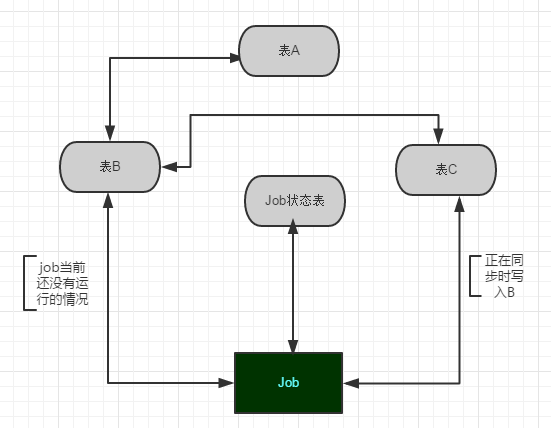 图1
图1
同时,为保万无一失和便于排查问题,应该用一个记录整个数据库实例的存储过程,在较短的时间检查作业执行结果,如果遇到异常失败的,应该及时通过其他方式通知到相关人员。如写入到发邮件和短信表,让一个Tcp的通知程序定时读取发送等等。
注:如果一天的数据达到几十个G,如果又对这个表有查询要求(分区下面会提到),下策之一:
可将B同时同步到多台服务器分担下查询压力,减少资源的竞争。因为整个数据库的资源是有限的,如插入操作,会先获得一个共享锁,然后通过聚集索引定位到某一行数据,再升级为意向锁,而sqlserver对锁的维护根据数据的大小需要申请不同的内存,造成了资源的竞争。所以应该尽可能的将读和写分开,可根据业务模型分,可根据设定的规则分;在平台性的项目中应该优先保证数据能有效的插入。
在不可避免的查询大数据肯定会耗用大量的资源,如遇到批量删除的时候,可以换成以循环分批次(如一次2000条)的方式,这样不至于这个进程导致整个库挂掉,衍生出一些无法预计的bug。经实践,有效可行,只是牺牲了存储空间。也可根据查询需求将表里数据量大的字段拆分出来到新表,当然这些也要根据每个业务场景结合需求来设定,设计出适合而并不需要华丽的方案即可。
2、解决存储问题
如果每天单表的数据都达到了几十个G,改善存储方案自然迫不及待了。现分享下自有的方案,在暴涨的数据摧残之下,仍坚守在一线!现举例对自有环境分享拙见:
现有数据表A,单表每天新增数据30G,在存储的时候采用异步将数据同步的方式,有的不能清除数据的表,在分区后还可分文件组,将文件组分配到不同的磁盘中,减少IO资源的竞争,保障现有资源的正常运行。现结合需求保留历史数据5天:
1这时需要通过作业job根据分区函数去生成分区方案,如根据userid或者时间字段来分区;
· 2.将表分区后,查询可以通过对应的索引,快速定位到某一段分区;
3通过作业合并分区将不要的分区数据转移到相同结构和索引的表,然后清除这个表的数据。
如图2:
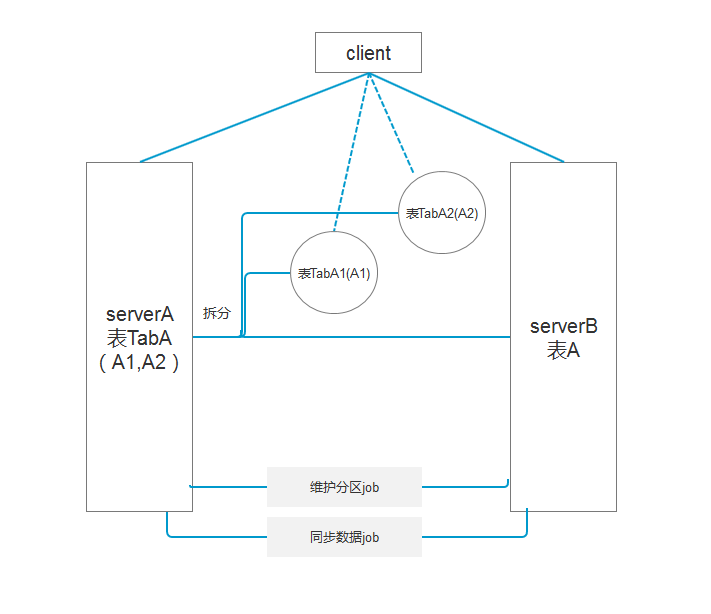
图2
通过sql查询跟踪捕捉到查询耗时长的,以及通过sql自带的存储过程sp_lock或视图dm_tran_locks、dblockinfo查看当前实例存在的锁的类型和粒度。
定位到具体的查询语句或者存储过程之后,对症下药!药到病除!
当然,仁者见仁,智者见智-_-
Sqlserver 高并发和大数据存储方案的更多相关文章
- Web网站架构演变—高并发、大数据
转 Web网站架构演变—高并发.大数据 2018年07月25日 17:27:22 gis_morningsun 阅读数:599 前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系 ...
- 最全Java架构师130面试题:微服务、高并发、大数据、缓存等中间件
一.数据结构与算法基础 · 说一下几种常见的排序算法和分别的复杂度. · 用Java写一个冒泡排序算法 · 描述一下链式存储结构. · 如何遍历一棵二叉树? · 倒排一个LinkedList. · 用 ...
- LVS解决高并发,大数据量
http://www.360doc.com/content/14/0726/00/11962419_397102114.shtml LVS的全称Linux vitual system,是由目前阿里巴巴 ...
- 从0到N建立高性价比的大数据平台(转载)
2016-07-29 14:13:23 钱曙光 阅读数 794 原文链接:https://blog.csdn.net/qiansg123/article/details/80124521 声明:本文为 ...
- Java架构-高并发的解决实战总结方案
Java架构-高并发的解决实战总结方案 1.应用和静态资源分离 刚开始的时候应用和静态资源是保存在一起的,当并发量达到一定程度的时候就需要将静态资源保存到专门的服务器中,静态资源主要包括图片.视频.j ...
- 《连载 | 物联网框架ServerSuperIO教程》- 17.支持实时数据库,高并发保存测点数据。附:3.4 发布与版本更新说明。
1.C#跨平台物联网通讯框架ServerSuperIO(SSIO)介绍 <连载 | 物联网框架ServerSuperIO教程>1.4种通讯模式机制. <连载 | 物联网框架Serve ...
- 《连载 | 物联网框架ServerSuperIO教程》- 17.集成Golden实时数据库,高并发保存测点数据。附:3.4 发布与版本更新说明。
1.C#跨平台物联网通讯框架ServerSuperIO(SSIO)介绍 <连载 | 物联网框架ServerSuperIO教程>1.4种通讯模式机制. <连载 | 物联网框架Serve ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- MapGis如何实现WebGIS分布式大数据存储的
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢? MapGIS在传统关系型空间数据库引擎MapGIS SDE的基础之上,针对地理大数据的特点,构建了MapGIS DataStore分布式 ...
随机推荐
- jquery autocomplete ajax获取动态数据,兼容各浏览器,支持中文
jquery.autocomplete.js经过改动,支持各种浏览器.支持中文输入! 1.效果图例如以下 2.HTML和ajax代码 <!DOCTYPE html> <html xm ...
- JSTL 中<c:forEach>使用
<c:forEach 详解 博客分类: JSTL <c:forEach>标签用于通用数据循环,它有以下属性 属 性 描 述 是否必须 缺省值 items 进行循环的项目 否 无 ...
- ecshop首页调用某分类下的商品|assign_cat_goods()
ecshop首页调用分类下的商品其实很简单,也有模板设置那里可以设置,不过那个只可以用cat_goods.lib,不方便,所以我想看看怎么能简单的实现ecshop首页调用分类下的商品 只需要在inde ...
- Spring MVC helloWorld中遇到的问题及解决办法
1.java.io.FileNotFoundException: Could not open ServletContext resource不能加载ServletContext的用法是配置到web. ...
- Caused by: java.lang.ClassNotFoundException: org.apache.commons.lang3.StringUtils
1.错误叙述性说明 2014-7-10 23:12:23 org.apache.catalina.core.StandardContext filterStart 严重: Exception star ...
- JavaScript获取路径
JavaScript获取路径 1.设计源代码 <%@ page language="java" import="java.util.*" pageEnco ...
- hadoop-1.1.2 在Windows环境下的部署
1:先安装Cygwin 参考http://blog.csdn.net/wind520/article/details/9223003 2:下载 3:解压在C:\cygwin\hadoop1 4:配置 ...
- WPF动态加载3D 放大-旋转-平移
原文:WPF动态加载3D 放大-旋转-平移 WavefrontObjLoader.cs 第二步:ModelVisual3DWithName.cs public class ModelVisual3DW ...
- HTML介绍JS
首先,该脚本的链接插入HTML代码: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvU2h1aVRpYW5OYWlMdW8=/font/5a6L5L2T/f ...
- Matrix+POJ+二维树状数组初步
...