Kafka基础教程(二):Kafka安装
因为kafka是基于Zookeeper的,而Zookeeper一般都是一个分布式的集群,尽管kafka有自带Zookeeper,但是一般不使用自带的,都是使用外部安装的,所以首先我们需要安装Zookeeper,可以参考:Zookeeper基础教程(二):Zookeeper安装
Zookeeper集群地址:
# 192.168.209.133 test1
# 192.168.209.134 test2
# 192.168.209.135 test3
为了方便,我这里也使用这三个地址安装部署kafka,注意,安装kafka之前需确保已安装了jdk!
首先,前往Kafka官网下载Kafka的安装包:http://kafka.apache.org/downloads.html
可以现在windows浏览器上下载好,然后将文件发到linux服务器下,博主使用的linux服务器版本是Ubuntu16.04的server版
下载完成之后,将这个tgz压缩包传到linux上去(可以使用xshell,或者filezilla也可以)
# 在tgz压缩包所在目录进行解压,-C 表示解压后的文件所存放的路径,这里表示解压后的文件放到/opt目录下
sudo tar -zxvf kafka_2.12-2.5.0.tgz -C /opt/
# 进入kafka的配置目录
cd /opt/kafka_2.12-2.5.0/config
# 其中server.properties是kafka的主要配置文件
sudo vim server.properties
server.properties常用参数介绍:
# 当前机器在集群中的唯一标识,和zookeeper的myid性质一样,要求集群中每个broker.id都说不一样的,可以从0开始递增,也可以从1开始递增
broker.id=0
# 监听地址,需要提供外网服务的话,要设置本地的IP地址,当前kafka对外提供服务的端口默认是9092
listeners=PLAINTEXT://test1:9092
# 这个是borker进行网络处理的线程数
num.network.threads=3
# 这个是borker进行I/O处理的线程数
num.io.threads=8
# 发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
# 这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
# 消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,
# 如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/tmp/kafka-logs
# 默认的分区数,一个topic默认1个分区数
num.partitions=1
# 每个数据目录用来日志恢复的线程数目
num.recovery.threads.per.data.dir=1
# topic的offset的备份份数
offsets.topic.replication.factor=1
# 事务主题的复制因子(设置更高以确保可用性)。 内部主题创建将失败,直到群集大小满足此复制因素要求。
transaction.state.log.replication.factor=1
# 覆盖事务主题的min.insync.replicas配置。
transaction.state.log.min.isr=1
# 默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
# 日志达到删除大小的阈值。每个topic下每个分区保存数据的最大文件大小;注意,这是每个分区的上限,因此这个数值乘以分区的个数就是每个topic保存的数据总量
log.retention.bytes=1073741824
# 这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.segment.bytes=1073741824
# 每隔300000毫秒去检查上面配置的log失效时间
log.retention.check.interval.ms=300000
# 是否启用log压缩,一般不用启用,启用的话可以提高性能
log.cleaner.enable=true
# 设置zookeeper的连接端口,多个地址以逗号(,)隔开,后面可以跟一个kafka在Zookeeper中的根znode节点的路径
zookeeper.connect=localhost:2181
# 设置zookeeper的连接超时时间
zookeeper.connection.timeout.ms=18000
# 在执行第一次再平衡之前,group协调员将等待更多消费者加入group的时间
group.initial.rebalance.delay.ms=0
我们可以根据自己的情况配置,比如我这里只需要配置:
# 192.168.209.133 test1配置
broker.id=0
listeners=PLAINTEXT://test1:9092
zookeeper.connect=test1:2181,test2:2181,test3:2181/kafka
# 192.168.209.134 test2配置
broker.id=1
listeners=PLAINTEXT://test2:9092
zookeeper.connect=test1:2181,test2:2181,test3:2181/kafka
# 192.168.209.135 test3配置
broker.id=2
listeners=PLAINTEXT://test3:9092
zookeeper.connect=test1:2181,test2:2181,test3:2181/kafka
现在就可以启动Kafka了,注意,启动前保证我们的Zookeeper是正常运行的!
# 启动 ,可以加上-daemon表示后台启动
sudo /opt/kafka_2.12-2.5.0/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.5.0/config/server.properties
# 停止kafka
sudo /opt/kafka_2.12-2.5.0/bin/kafka-server-stop.sh
等三台kafka都启动之后,使用ZooInspector连接Zookeeper可以看到多了一个路径为/kafka的znode节点,启动/kafka/brokers/ids的自己点就是我们上面配置的broker.id:
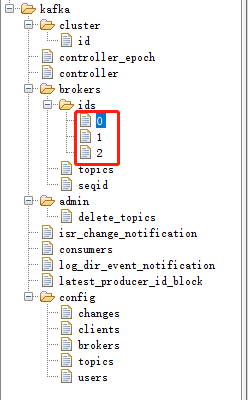
截图中/kafka节点下的所有znode节点都是kafka所生成的,可以认为记录的是kafka运行状态的一些信息
如果启动过程中报错:kafka.common.InconsistentClusterIdException: The Cluster ID XXXXXXXXXXXXXX doesn't match stored clusterId Some(XXXXXXXXXXXXXXX) in meta.properties
可以前往server.properties中配置的log.dirs目录下,找到meta.properties文件,将其中的cluster.id=XXXXXXXX给注释掉,然后重新启动kafka就可以了
创建Topic
使用kafka-topics.sh创建topic:
sudo /opt/kafka_2.12-2.5.0/bin/kafka-topics.sh --create --zookeeper test1:2181/kafka --replication-factor 3 --partitions 3 --topic test
# --create 表示创建,--delete 表示删除 --describe 表示获取详情 --list 表示列出所有的topic
# --zookeeper 表示创建topic时连接Zookeeper所使用的的连接,注意,后面需要带上根路径名,这个和我们在server.properties中配置zookeeper.connect节点中的根路径一致
# --replication-factor 创建的topic副本数,不能大于broker的个数,否则会抛出异常:ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: M larger than available brokers: N.
# --partitions topic的分区数,最好是等于broker数
# --topic 表示topic
这时刷新ZooInspector可以看到
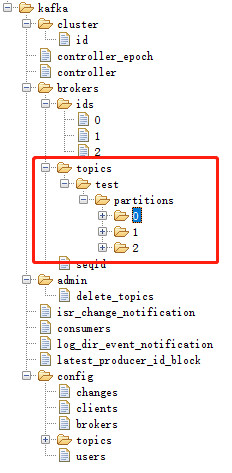
发布消费消息
发布消息使用kafka-console-producer.sh
sudo /opt/kafka_2.12-2.5.0/bin/kafka-console-producer.sh --bootstrap-server test1:9092 --topic test
# --bootstrap-server 表示连接的kafka的broker,可以在ZooInspector中查看
执行命令后即进入命令行,可以输入消息了:

消费消息使用kafka-console-consumer.sh
sudo /opt/kafka_2.12-2.5.0/bin/kafka-console-consumer.sh --bootstrap-server test1:9092 --topic test
# 可以增加--from-beginning参数表示从头开始消费
上述命令执行后,就开始接收消息了,当重新发送一条消息,就会打印出来了:

使用kafkatool连接使用Kafka
首先下载kafkatool可以前往官网:https://www.kafkatool.com/download.html
或者在百度网盘下载:https://pan.baidu.com/s/1WVbRWW5thzJ9ZCGrimDekQ (提取码: 3h88)
安装后打开,File=>New Connection创建一个新连接:
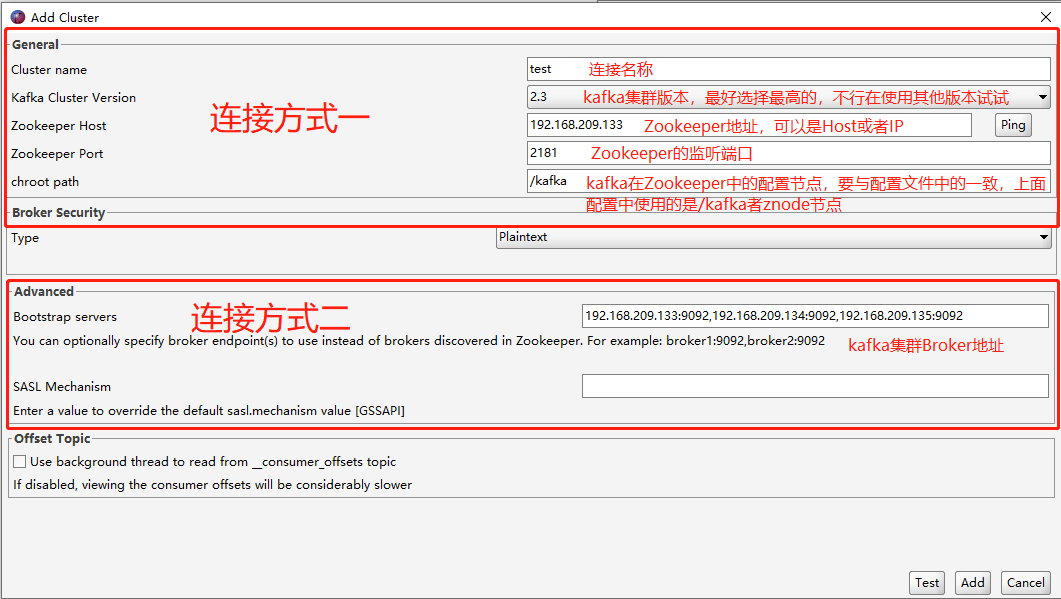
kafkatool提供了两种连接方式:
第一种是指定kafka在Zookeeper中的节点信息,然后kafkatool根据Zookeeper上的信息去获取各个Broker的信息。
第二种方式是手动提供kafka的Broker地址和端口(不用提供全部Broker,部分也可以)。
填好信息后,可以点击右下角的Test测试连接是否正常,确认正常后点击Add添加连接。
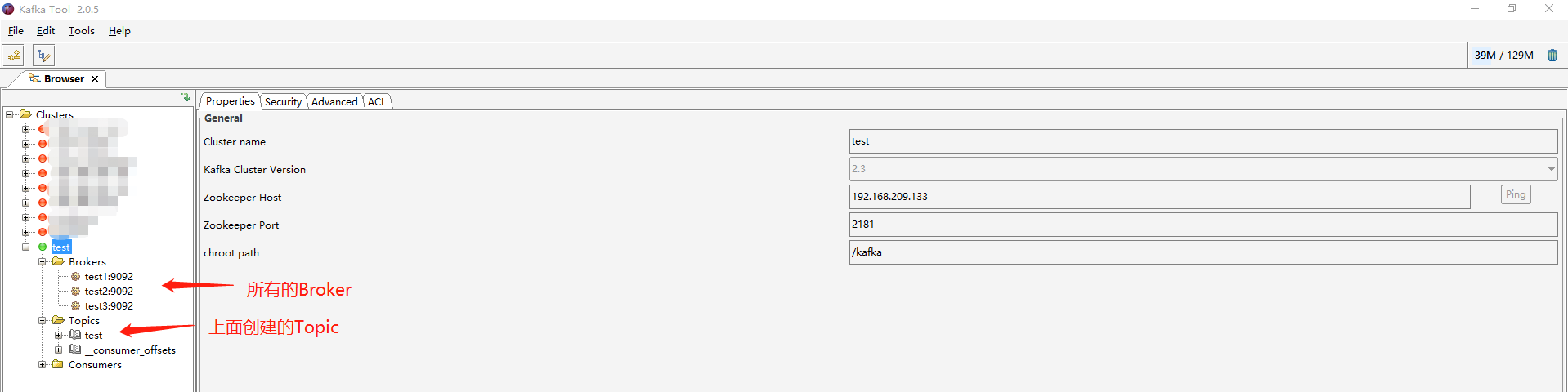
连接上后,可以看到我们的Broker还有我们创建的Topic:
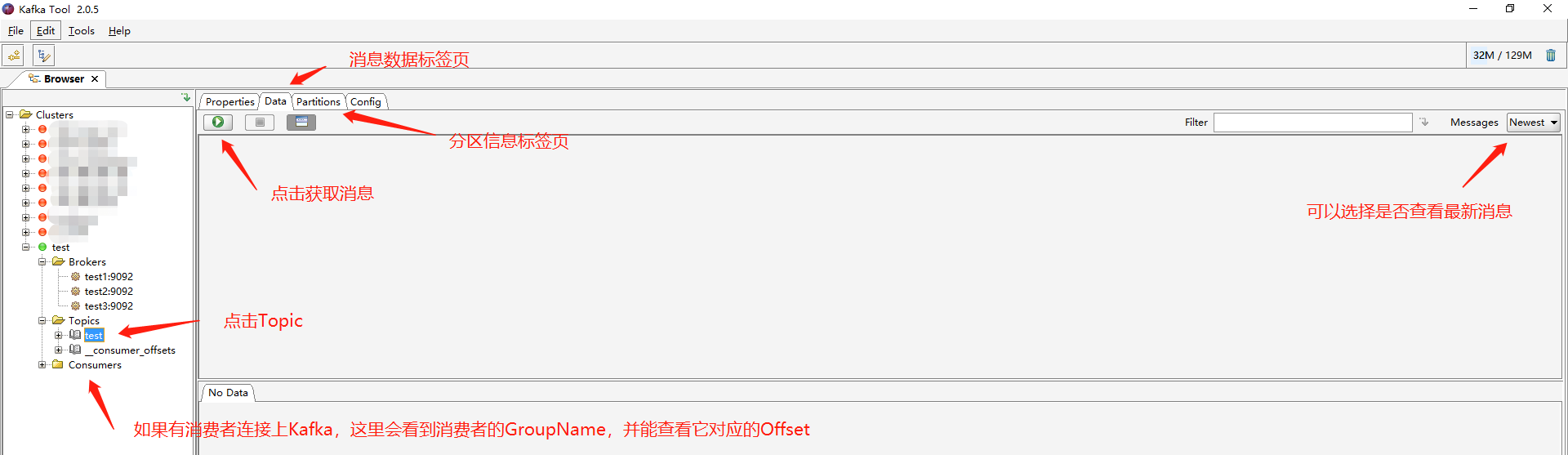
点击指定的Topic可以查看这个Topic下的分区即消息等等:
注:如果您也像我这样使用了hosts文件做了一层ip:hostname映射,可能导致在windows中无法连接或者Topic和Comsumers等操作失败,可以试试在windows的hosts中配置ip:hostname
Kafka基础教程(二):Kafka安装的更多相关文章
- Kafka基础教程(四):.net core集成使用Kafka消息队列
.net core使用Kafka可以像上一篇介绍的封装那样使用(Kafka基础教程(三):C#使用Kafka消息队列),但是我还是觉得再做一层封装比较好,同时还能使用它做一个日志收集的功能. 因为代码 ...
- Kafka入门教程(二)
转自:https://blog.csdn.net/yuan_xw/article/details/79188061 Kafka集群环境安装 相关下载 JDK要求1.8版本以上. JDK安装教程:htt ...
- Kafka学习之二 Kafka安装和使用
部署环境Linux(Centos 6.5),JDK 1.8.0,zookeeper-3.4.12,kafka_2.11-2.0.0. 1. 单机环境 官方建议使用JDK 1.8版本,因此本文使 ...
- kafka 基础知识梳理-kafka是一种高吞吐量的分布式发布订阅消息系统
一.kafka 简介 今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何及时做到如上两点 ...
- Python 3基础教程1-环境安装和运行环境
本系列开始介绍Python3的基础教程,为什么要选中Python 3呢?之前呢,学Python 2,看过笨方法学Python,学了不到一个礼拜,就开始用Python写Selenium脚本.最近看到一些 ...
- Kafka工具教程 - Apache Kafka中的2个重要工具
1.目标 - 卡夫卡工具 在我们上一期的Kafka教程中,我们讨论了Kafka Workflow.今天,我们将讨论Kafka Tool.首先,我们将看到卡夫卡的意义.此外,我们将了解两个Kafka工具 ...
- Git 基础教程 之 Git 安装 (windows)
一,安装Git,访问下面网址进行下载 https://www.git-scm.com/download/ 或者 https://pan.baidu.com/s/19imFBVHA2Yibmw1dyza ...
- Kafka基础教程(三):C#使用Kafka消息队列
接上篇Kafka的安装,我安装的Kafka集群地址:192.168.209.133:9092,192.168.209.134:9092,192.168.209.135:9092,所以这里直接使用这个集 ...
- Kafka基础教程(一):认识Kafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,吞吐速率非常快,可以作为Hadoop的日志收集.Kafka是一个完全的分布式系统,这一点依赖于Zookeeper ...
随机推荐
- XML解析器
1.非验证解析器 检查文档格式是否良好,如用浏览器打开XML文档时,浏览器会进行检查,即格式是否符合XML(可拓展标记语言)基本概念. 2.验证解析器 使用DTD(Document Type Defi ...
- 一行配置搞定 Spring Boot项目的 log4j2 核弹漏洞!
相信昨天,很多小伙伴都因为Log4j2的史诗级漏洞忙翻了吧? 看到群里还有小伙伴说公司里还特别建了800+人的群在处理... 好在很快就有了缓解措施和解决方案.同时,log4j2官方也是速度影响发布了 ...
- C/C++ Qt 数据库与Chart历史数据展示
在前面的博文中具体介绍了QChart组件是如何绘制各种通用的二维图形的,本章内容将继续延申一个新的知识点,通过数据库存储某一段时间节点数据的走向,当用户通过编辑框提交查询记录时,程序自动过滤出该时间节 ...
- Moment.js使用笔记
零.前情提要 上个月开发了数据平台,用的框架是vue + Ant Design of Vue,其中用了组件[range-picker]日期选择框,涉及到时间方法就去看了momentJS,以此记录~ 如 ...
- Redis cluster 集群部署和配置
目录 一.集群简介 cluster介绍 cluster原理 cluster特点 应用场景 二.集群部署 环境介绍 节点部署 启动集群 三.集群测试 一.集群简介 cluster介绍 redis clu ...
- tableau绘制饼图
一.将类别拖拽至列,将销售额拖拽至行 二.点击右上角智能显示选择饼图 三.拖拽销售额至标记卡,右键快速表计算-合计百分比-细节处理最终结果如下图所示
- 搭建ELK日志平台(单机)
系统版本:Ubuntu 16.04.7 LTS 软件架构:Filebeat+Kafka+Logstash+Elasticsearch+Kibana+Nginx 软件版本:Filebeat-7.16.0 ...
- 记一次Linux bash 命令行卡顿排查之警惕LD_PRELOAD环境变量
现象: 通过屏幕或者ssh登录Linux操作系统(本例:Ubuntu)后,执行ls 需要数秒才返回 strace -c ls 查看实际命令调用耗时并不长 对比和正常执行的主机命令执行时,加载的库文件差 ...
- java 集合Collections 工具类:排序,查找替换。Set、List、Map 的of方法创建不可变集合
Collections 工具类 Java 提供1个操作 Set List Map 等集合的工具类 Collections ,该工具类里提供了大量方法对集合元素进行排序.查询和修改等操作,还提供了将集合 ...
- 创建Harbor私有仓库
前提 1.安装docker服务 参考:https://blog.csdn.net/weixin_36522099/article/details/108861134 老名字:docker.docker ...