ElasticSearch集群的安装(windows)
首先尽量保持你的磁盘空间足够大,比如你下载的软件的放在D盘,D盘尽量保持10G以上,还有C盘也差不多10G以上比较保险
一、下载
1)目前我下载的版本是elasticsearch-7.12.0-windows-x86_64,通过搜索引擎找到ElasticSearch的官网下载软件,目前的地址如下:
https://www.elastic.co/cn/downloads/elasticsearch
二、配置
1)解压
2)复制3份解压后的文件,重命名为node-1001,node-1002,node-1003
3)分别配置各自文件下config目录下的配置文件elasticsearch.yml
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-3
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径(配置各自节点目录)
path.data: D:/software/elastic/node-1003/data
# 日志存储路径:(配置各自节点目录)
#
path.logs: D:/software/elastic/node-1003/logs
# 网关地址
network.host: 0.0.0.0
# 端口(配置各自节点端口)
http.port: 9202
# 内部节点之间沟通端口(配置各自节点端口)
transport.tcp.port: 9800
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
节点1配置具体如下:
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-1
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径
path.data: D:/software/elastic/node-1001/data
# 日志存储路径:
#
path.logs: D:/software/elastic/node-1001/logs
# 网关地址
network.host: 0.0.0.0
# 端口
http.port: 9200
# 内部节点之间沟通端口
transport.tcp.port: 9600
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
节点2配置具体如下:
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-2
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径
path.data: D:/software/elastic/node-1002/data
# 日志存储路径:
#
path.logs: D:/software/elastic/node-1002/logs
# 网关地址
network.host: 0.0.0.0
# 端口
http.port: 9201
# 内部节点之间沟通端口
transport.tcp.port: 9700
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
节点3配置如下:
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-3
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径
path.data: D:/software/elastic/node-1003/data
# 日志存储路径:
#
path.logs: D:/software/elastic/node-1003/logs
# 网关地址
network.host: 0.0.0.0
# 端口
http.port: 9202
# 内部节点之间沟通端口
transport.tcp.port: 9800
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
4)清空各自文件夹下的data和logs文件夹内容(后面重启时有必要时也要进行此操作)
5)启动(双击如:node-1001\bin\elasticsearch.bat文件,但这种方式一旦有错误时,命令行会直接关掉,所以还是以命令行的形式打开,如打开cmd文件,进入该文件夹,或在node-1001\bin\目录下的文件路径地址栏输入cmd回车即可打开命令行且切换到该路径下,再输入elasticsearch.bat)
6)全部启动后,访问http://localhost:9200/、http://localhost:9201/、http://localhost:9202/地址,结果如下

三、可视化客户端工具的安装(cerebro)
下载地址https://github.com/lmenezes/cerebro/releases
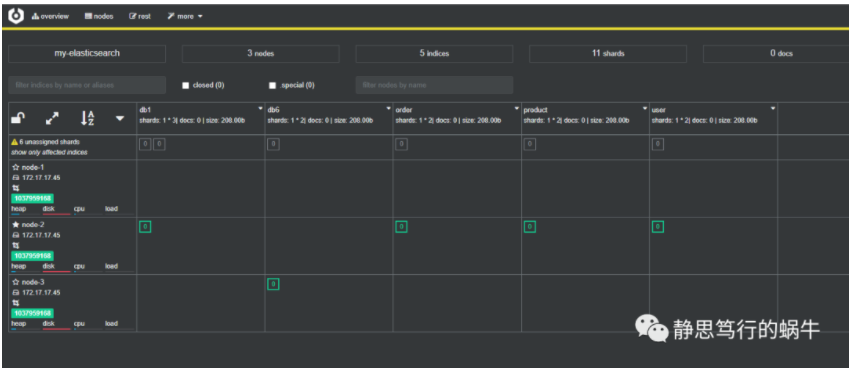
解压打开文件夹里面的bin目录,和ElasticSearch启动一样,可以直接双击,也可以命令行形式启动,默认地址端口是9000,
如果端口被占用我们可以指定一个端口,先cmd命令行进入该文件夹的bin目录下,输入命令,如cerebro -Dhttp.port=9999,就可以指定9999端口启动cerebro了,访问地址是http://localhost:9999/,输入ElasticSearch地址,如上面的http://localhost:9200/,就可以连接到ElasticSearch,可视化界面如下:
谢谢关注公众号:

ElasticSearch集群的安装(windows)的更多相关文章
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
前言 本文主要介绍的是ElasticSearch集群和kinaba的安装教程. ElasticSearch介绍 ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行 ...
- elasticsearch 集群的安装部署
一 介绍 elasticsearch 是居于lucene的搜素引擎,可以横向集群扩展以及分片,开发者无需关注如何实现了索引的备份,集群同步,分片等,我们很容易通过简单的配置就可以启动elasticse ...
- ElasticSearch和Kibana 5.X集群的安装
ElasticSearch和Kibana 5.X集群的安装 1.准备工作 1.1.下载安装包 1.2.系统的准备 2.ElasticSearch集群的安装 2.1.修改 config/elastics ...
- k8s上安装elasticsearch集群
官方文档地址:https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-quickstart.html yaml文件地址:https://dow ...
- Azure vm 扩展脚本自动部署Elasticsearch集群
一.完整过程比较长,我仅给出Azure vm extension script 一键部署Elasticsearch集群的安装脚本,有需要的同学,可以邮件我,我给你完整的ARM Template 如果你 ...
- Elasticsearch集群搭建及使用Java客户端对数据存储和查询
本次博文发两块,前部分是怎样搭建一个Elastic集群,后半部分是基于Java对数据进行写入和聚合统计. 一.Elastic集群搭建 1. 环境准备. 该集群环境基于VMware虚拟机.CentOS ...
- CentOS 7下ElasticSearch集群搭建案例
最近在网上看到很多ElasticSearch集群的搭建方法,本人在这人使用Elasticsearch5.0.1版本,介绍如何搭建ElasticSearch集群并安装head插件和其他插件安装方法. 一 ...
- CentOS下 elasticsearch集群安装
1.进入root目录并下载elasticsearch cd /root wget https://download.elastic.co/elasticsearch/elasticsearch/ela ...
- ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决
ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决 说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文 ...
随机推荐
- Android开发音视频方向学习路线及资源分享,学完还怕什么互联网寒冬?
接触Android音视频这一块已经有一段时间了,跟普通的应用层开发相比,的确更花费精力.期间为了学习音视频的录制,编码,处理也看过大大小小的几十个项目.总体感觉就是知识比较零散,对刚入门的朋友比较不友 ...
- 还有更惨的吗?字节面经,美团,网易,招银,360全部在HR前一面挂了
最近一朋友向我吐槽去年的秋招,字节面经,美团,网易,招银,360全部在HR前一面挂了,实在是有点惨.我把他语无伦次的话做了一个整理: 最近真的很暴躁,控制不住自己陷入情绪低落胡思乱想,每天都是在希望失 ...
- 第一个Java文件
HelloWorld 1.新建一个文件夹,用来存放java文件的 2.用subline来编辑第一个Java文件 要注意的是java的文件名为.java 我们自定义的文件名是Hello 3.编写第一个j ...
- 数据增广imgaug库的使用
记录一下这两天用imgaug库做数据增广的代码,由于是算用算学的,所以只能把代码写出来,具体每种增广算法的原理和一些参数就不得而知了,不过我觉得也没必要把这么些个算法搜搞懂,毕竟重点是扩种数据.所以, ...
- pom.xml中web.xml is missing and <failOnMissingWebXml> is set to true错误的解决
.personSunflowerP { background: rgba(51, 153, 0, 0.66); border-bottom: 1px solid rgba(0, 102, 0, 1); ...
- React脚手架配置代理
react脚手架配置代理 方法一 在package.json中追加如下配置 "proxy":"http://localhost:5000" 说明: 优点:配置简 ...
- centos7上用docker搭建简单的前后端分离项目
1. 安装docker Docker 要求 CentOS 系统的内核版本高于 3.10 ,首先验证你的CentOS 版本是否支持 Docker . 通过 uname -r 命令查看你当前的内核版本 使 ...
- Visio2013安装报错 1935 问题解决
最近安装Visio2013,奈何一直报错,出现1935的错误并且回滚 试了试网上的方法,无论是安装.netframework4.0也好,下载.net修复工具也好,都不行 最后尝试删除一个注册表路径 H ...
- 题解 Cicada 拿衣服
传送门 神仙题! 听@Yubai给我讲了半个下午,快%@Yubai 见到这些奇奇怪怪的题是不是应该试着证下状态数上界啊 首先观察题目里给的柿子,可以发现 \(or-and\) 单调增, \(min-m ...
- windows和liunx下换行符问题
区别 windows换行符是: \r\n liunx换行符是: \n 问题 程序处理的时候就会有问题,因为在Windows的文件多了一个\r 解决办法(转换文件格式) vim file :set fi ...