15-Transfer Learning
介绍
迁移学习指的就是,假设你手上有一些跟你现在要进行的task没有直接相关的data,那你能不能用这些没有直接相关的data来帮助我们做一些什么事情。比如说:你现在做的是猫跟狗的classifer,那所谓没有什么直接相关的data是什么意思呢?没有什么直接相关其实是有很多不同的可能。
比如说input distribution 是类似的(一样时动物的图片),但是你的label是无关的(domain是类似的,task是不像的)。
还有另外的一个可能是:input domain是不同的,但是task是相同的(猫跟狗的分类,一个招财猫图片,一个是高非狗的图片)
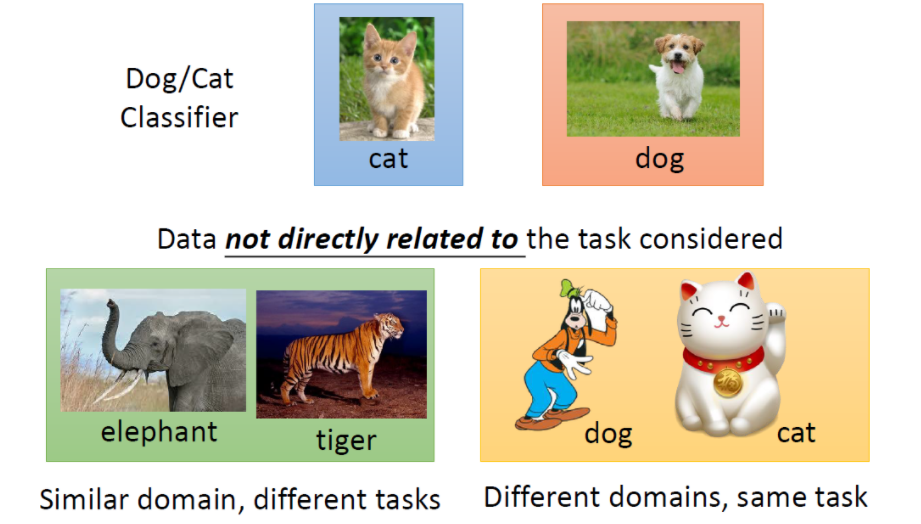
迁移学习问的问题是:我们能不能再有一些不想关data的情况下,然后帮助我们现在要做的task。
为什么我要考虑迁移学习这样的task呢?举例来说:在speech recognition里面(台语的语音辨识),台语的data是很少的(但是语音的data是很好收集的,中文,英文等)。那我们能不能用其他语音的data来做台语这件事情。或许在image recongnition里面有一些是medical images,这种medical image其实是很少的,但是image data是很不缺的。

用不相干的data来做domain其他的data,来帮助现在的task,是有可能的。
我们在现实生活中,我们在不断的做迁移学习。比如说:你可能是是一名研究生,你可能想知道研究生咋样过日子,你就可以参考爆漫王里面的例子。在保漫王里面漫画家就是研究生,责编就等同于指导教授。漫画家每周画分镜去给责编看,跟责编讨论(就跟指导教授每周去汇报报告一样),画分镜就是跑实验。目标就是投稿就等于投稿期刊。
虽然我们没有一个研究生的守则,但是从爆漫王里面我们可以知道说:身为一个研究生应该要做什么样的事情。那你可能会说:拿漫画跟学术做类比,有点不伦不类的(漫画也是拿生命来做的)。
迁移学习有很多的方法,它是很多方法的集合。
下面你有可能会看到我说的terminology可能跟其他的有点不一样,不同的文献用的词汇其实是不一样的,有些人说算是迁移学习,有些人说不算是迁移学习,所以这个地方比较混乱,你只需要知道那个方法是什么就好了。
overview
迁移学习是很多方法的集合,这里介绍一些概念:
- Target Data:和task直接相关的data
- Source Data:和task没有直接关系的data
按照labeled data和unlabeled data又可以划分为四种:
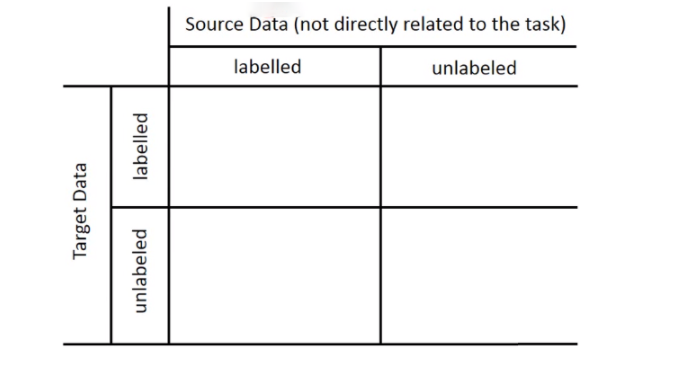
我们现在有一个我们想要做的task,有一些跟这个task有关的数据叫做target data,有一些跟这个task无关的data,这个data叫做source data。这个target data有可能是有label的,也有可能是没有label的,这个source data有可能是有label的,也有可能是没有label的,所以现在我们就有四种可能,所以之后我们会分这四种来讨论。

Case 1

Model Fine-tuning
Introduction
模型微调的基本思想:用source data去训练一个model,再用target data对model进行微调(fine tune)
所谓“微调”,类似于pre-training,就是把用source data训练出的model参数当做是参数的初始值,再用target data继续训练下去即可,但当直接相关的数据量非常少时,这种方法很容易会出问题
所以训练的时候要小心,有许多技巧值得注意
Conservation Training(保守训练)
有一个技巧叫做:conservative training,你现在有大量的source data,(比如说:在语音辨识里面就是很多不同speaker的声音),那你拿来做neural network。target data是某个speaker的声音,如果你直接拿这些去train的话就坏掉了。你可以在training的时候加一些constraint(regularization),让新的model跟旧的model不要差太多。你会希望新的model的output跟旧的model的output在看同一笔data的时候越接近越好。或者说新的model跟旧的model L2-Norm差距越小越好(防止overfitting的情形)
如果现在有大量的source data,比如在语音识别中有大量不同人的声音数据,可以拿它去训练一个语音识别的神经网络,而现在你拥有的target data,即特定某个人的语音数据,可能只有十几条左右,如果直接拿这些数据去再训练,肯定得不到好的结果。
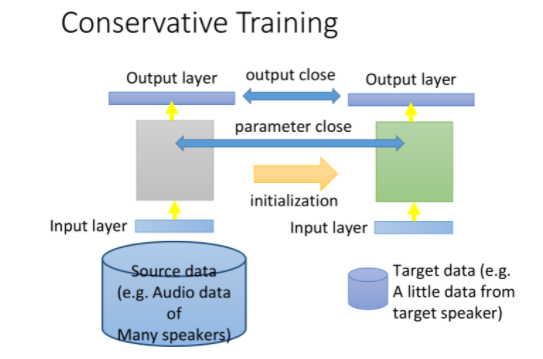
此时我们就需要在训练的时候加一些限制,让用target data训练前后的model不要相差太多:
- 我们可以让新旧两个model在看到同一笔data的时候,output越接近越好
- 或者让新旧两个model的L2 norm越小越好,参数尽可能接近
- 总之让两个model不要相差太多,防止由于target data的训练导致过拟合
注:这里的限制就类似于regularization
Layer Transfer(层迁移)
现在我们已经有一个用source data训练好的model,此时把该model的某几个layer拿出来复制到同样大小的新model里,接下来只用target data去训练余下的没有被复制到的layer
这样做的好处是target data只需要考虑model中非常少的参数,这样就可以避免过拟合。当然之后你的source data够多了,那之后可能还是要fine-tune整个model。
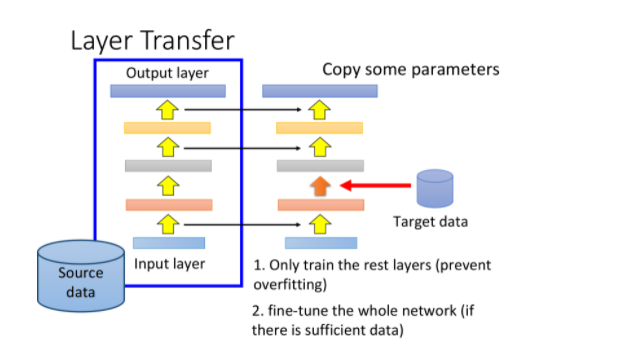
这个对部分layer进行迁移的过程,就体现了迁移学习的思想,接下来要面对的问题是,哪些layer需要被复制迁移,哪些不需要呢?
值得注意的是,在不同的task上,需要被复制迁移的layer往往是不一样的:
在语音识别中,往往迁移的是最后几层layer,再重新训练与输入端相邻的那几层
由于口腔结构不同,同样的发音方式得到的发音是不一样的,NN的前几层会从声音信号里提取出发音方式,再用后几层判断对应的词汇,从这个角度看,NN的后几层是跟特定的人没有关系的,因此可做迁移
在图像处理中,往往迁移的是前面几层layer,再重新训练后面的layer
CNN在前几层通常是做最简单的识别,比如识别是否有直线斜线、是否有简单的几何图形等,这些layer的功能是可以被迁移到其它task上通用的
主要还是具体问题具体分析
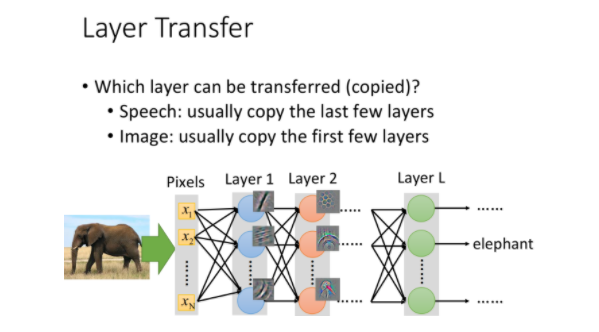
所以在做语音辨识的时候,常见的做法是把neural network的后几层是copy。但是在image的时候发现是不一样的,在image的时候是copy前面几层,只train最后几层。
在image的时候你会发现数说,当你source domain上learn了一network,你learn到CNN通常前几层做的就是deceide最简单的事情(比如前几层做的就是decide有么有直线,有么有简单的几何图形)。所以在image上面前几层learn的东西,它是可以被transfer到其他的task上面。而最后几层learn的东西往往是没有办法transfer到其他的东西上面去。所以在做影像处理的时候反而是会copy前面几层。
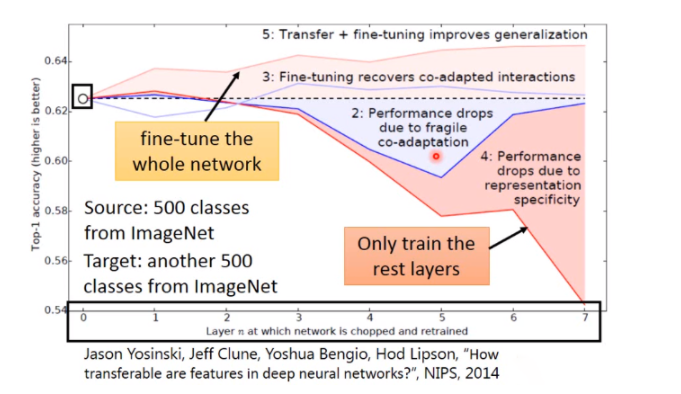
这是一个image在layer transfer上的实验, 120多wimage分成source跟target,分法是按照class来分的(500 class归为source data,500classes归为target data)。横轴的意思是:我们在做迁移学习的时候copy了几个layer(copy 0个layer,就是说完全没有做迁移学习),纵轴时候top-1 accuracy,越高越好。
假设source跟target是没关系的,把这个Imagenet分为source data跟target data的时候,把自然界的东西通通当成source,target都是人造的东西,这样的迁移学习会有什么样的影响。如果source data跟target data是差很多的,那在做迁移学习的时候,你的性能会掉的非常多(如果只是copy前面几个layer的话,性能仍然跟没有跟copy是持平的)。这意味着说:即使source domain跟target domain是非常不一样的,在neural network的第一个layer,他们仍然做的事情仍然可能是一样的。绿色的这条线:假设我前面几个layer的参数random会坏掉了。
接下来是多任务学习,多任务学习跟fine tuning不同是:在fine tuning里面我们care target domain做的好不好,那在多任务学习里面我们同时care target domain跟source domain做的好不好。
Multitask Learning
Introduction
fine-tune仅考虑在target data上的表现,而多任务学习,则是同时考虑model在source data和target data上的表现
如果两个task的输入特征类似,则可以用同一个神经网络的前几层layer做相同的工作,到后几层再分方向到不同的task上,这样做的好处是前几层得到的data比较多,可以被训练得更充分
有时候task A和task B的输入输出都不相同,但中间可能会做一些类似的处理,则可以让两个神经网络共享中间的几层layer,也可以达到类似的效果
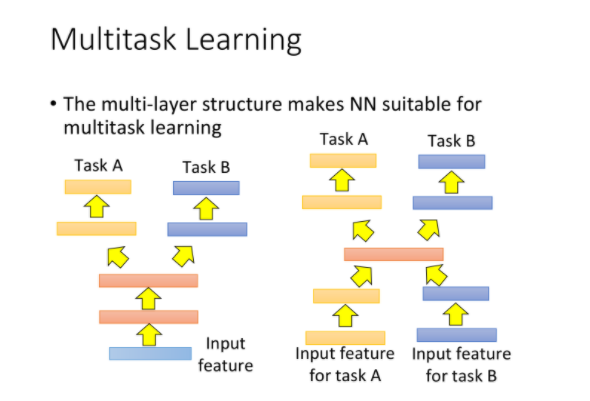
注意,以上方法要求不同的task之间要有一定的共性,这样才有共用一部分layer的可能性
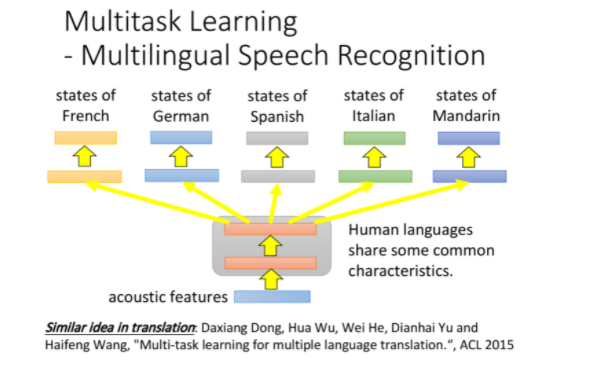
Multilingual Speech Recognition
多任务学习在语音识别上比较有用,可以同时对法语、德语、西班牙语、意大利语训练一个model,它们在前几层layer上共享参数,而在后几层layer上拥有自己的参数
在机器翻译上也可以使用同样的思想,比如训练一个同时可以中翻英和中翻日的model。
注意到,属于同一个语系的语言翻译,比如欧洲国家的语言,几乎都是可以做迁移学习的;而语音方面则可迁移的范围更广。
下图展示了只用普通话的语音数据和加了欧洲话的语音数据之后得到的错误率对比,其中横轴为使用的普通话数据量,纵轴为错误率,可以看出使用了迁移学习后,只需要原先一半的普通话语音数据就可以得到几乎一样的准确率。
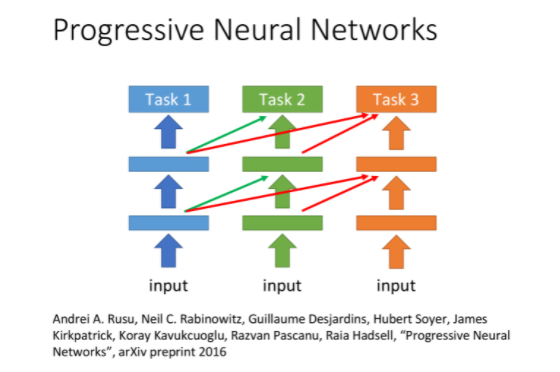
Progressive Neural Network(渐进神经网络)
如果两个task完全不相关,硬是把它们拿来一起训练反而会起到负面效果
而在Progressive Neural Network中,每个task对应model的hidden layer的输出都会被接到后续model的hidden layer的输入上,这样做的好处是:
- task 2的data并不会影响到task 1的model,因此task 1一定不会比原来更差
- task 2虽然可以借用task 1的参数,但可以将之直接设为0,最糟的情况下就等于没有这些参数,也不会对本身的表现产生影响
- task 3也做一样的事情,同时从task 1和task 2的hidden layer中得到信息
Case 2
这里target data不带标签,而source data带标签:
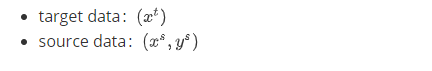
Domain-adversarial Training
如果source data是有label的,而target data是没有label的,该怎么处理呢?
比如source data是labeled MNIST数字集,而target data则是加了颜色和背景的unlabeled数字集,虽然都是做数字识别,但两者的情况是非常不匹配的。
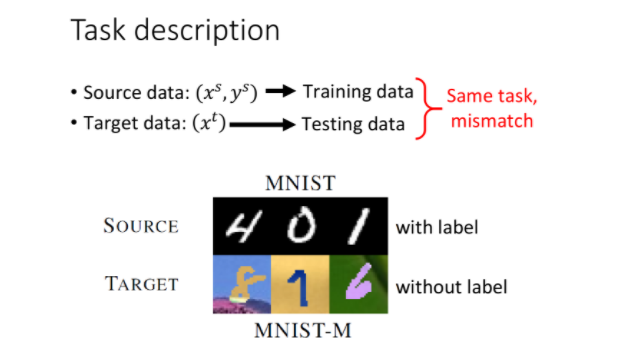
这个时候一般会把source data当做训练集,而target data当做测试集,如果不管训练集和测试集之间的差异,直接训练一个普通的model,得到的结果准确率会相当低
实际上,神经网络的前几层可以被看作是在抽取feature,后几层则是在做classification,如果把用MNIST训练好的model所提取出的feature做t-SNSE降维后的可视化,可以发现MNIST的数据特征明显分为紫色的十团,分别代表10个数字,而作为测试集的数据却是挤成一团的红色点,因此它们的特征提取方式根本不匹配。
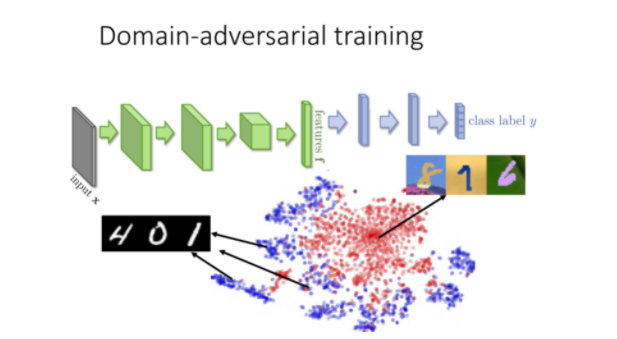
神经网络的领域对抗训练
那么这个做什么呢?这个希望做的事情是:前面的特征提取可以把领域的特性去除掉,这个招比较做领域-对抗训练。也就是特征提取输出不应该是红色跟蓝色的点两群,不同的领域应该混在一起。
那咋样学习这样的特征提取呢,这个的动作是在接一个域分类器。把特征提取输出丢给域分类器,域分类器也是一个分类任务,它要做的事情就是:根据特征提取给它的特征,判断这个特征来自于哪个域,在这个任务里面,要判断这些特征是来自 MNIST 还是来自与 MNIST-M。
有一个生成器的输出,然后还有其他识别器,那一堆的非常像GAN。跟GAN不的事情是:之前在GAN那个任务里面,你的生成器会发生的事情是生成一个图像,然后骗过判别器,这很简单。但是在这个领域对抗训练里面,要骗过领域分类器太了。有一个解决办法:不管看到什么东西,输出都是0,这样就骗了过了分类器。
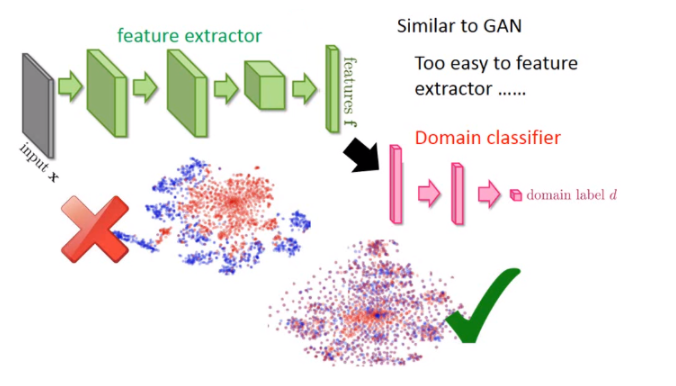
所以只是训练这个领域分类器是经典的,因为特征提取可以很轻易骗过领域分类器
所以你要在特征提取增加它任务的难度,所以特征提取它输出的特征它要骗过域分类器,同时让laebl预测器做好。这个标签预测器就吃特征提取输出,然后它的输出就是10个班级。
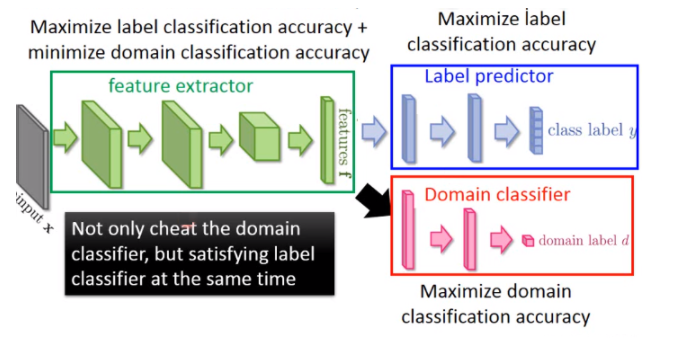
你今天的特征提取不只要经过域分类器,还有满足标签预测的需求。提取的特征所以需要域的特性消掉,同时保留原有特征的特性。那我们把这三个神经放出话说这个实际上就是一个大型的神经网络,是一个各样鬼胎的神经网络(一般的神经网络整个参数想要做的事情都一样的,要尽量减少损失),在神经网络里面的参数是各怀鬼胎的。蓝色标签预测器正确做的事情是把分类分类做的事情是把分类分类做的事情是想准确判断,域分类做的事情是正确的预测图像是属于哪个域的。特征提取器想要做的事情是:同时提高标签预测器,同时寻找最小化域分类器的准确性。
特征提取器咋样陷害队友呢?
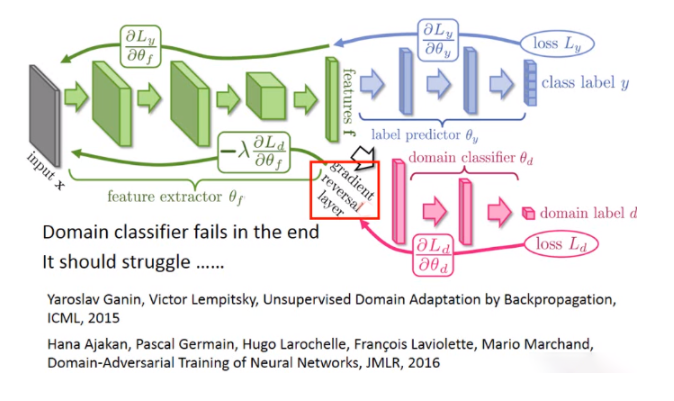
这件事情很容易的,你只要加一个梯度反转层就行了。也就是你在做反向传播的时候(feedford和backford),在做backford任务的时候你的分类器传给特征提取器显示域的值,特征提取器把它乘上负号。也就是域分类器告诉你说某个值要上升,就它故意一个下降。
域分类器看不到真正的形象,所以最终一定会失败掉。最后因为它看到的东西特征提取器告诉它的,所以它一定会识别出来的东西提取出来的特征是来自哪个地方的领域。
每天的问题就是域分类器一定要奋力的判断因为它要努力去现在的特征是来自哪个域。
这些都是很新的纸,值得看。
这是paper中的一些实验结果,看来是不同的域名转移。
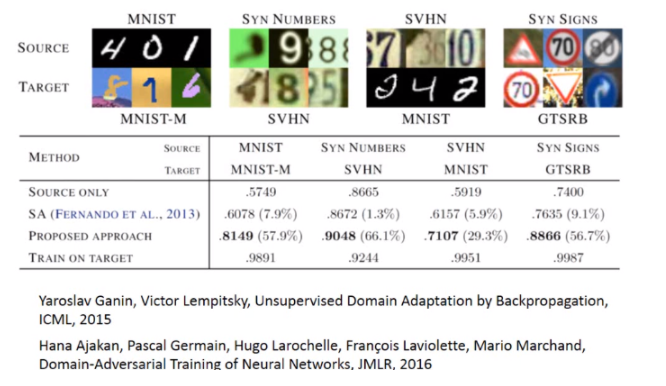
我们查看一些实验结果的话,纵轴代表用不同的方法,在这四个结果里面,你会发现:如果只使用来源的话,性能是比较差的。
接下来是零样本学习。
Zero-shot Learning(零样本学习)
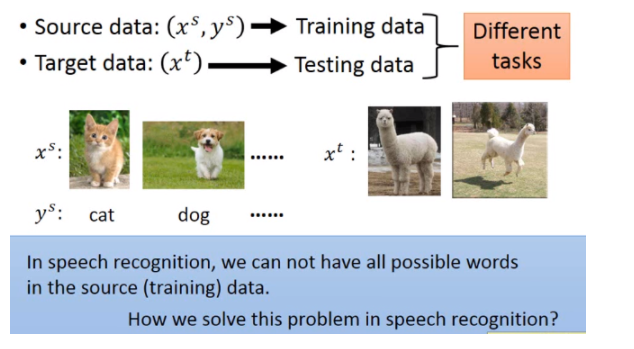
在zero-shot-learning里面呢?跟刚才讲的task是一样的,source data有label,target data每天label。在刚才task里面可以把source data当做training data,把target data当做testing data,但是实际上在zero-shot learning里面,它的difine又更加严格一点。它的difine是:今天在source data和target data里面,它的task是不一样的。
比如说在影像上面(你可能要分辨猫跟狗),你的source data可能有猫的class,也有狗的class。但是你的target data里面image是草泥马的样子,在source data里面是从来没有出现过草泥马的,如果machine看到草泥马,就未免有点强人所难了吧。但是这个task在语音上很早就有solution了,其实语音是常常会遇到zero-shot learning的问题。
假如我们把不同的word都当做一个class的话,那本来在training的时候跟testing的时候就有可能看到不同的词汇。你的testing data本来就有一些词汇是在training的时候是没有看过的。
那在语音上我们咋样来解决这个问题呢?不要直接去辨识一段声音是属于哪一个word,我们辨识的是一段声音是属于哪一个音标。然后我们在做一个音标跟table对应关系的表,这个东西也就是词典。在辨识的时候只要辨识出音标就好,再去查表说:这个音标对应到哪一个word。这样就算有一些word是没有在training data里面的,它只要在你的词典里面出现过,你的model可以正确辨识出声音是属于哪一个音标的话,你就可以处理这个问题。
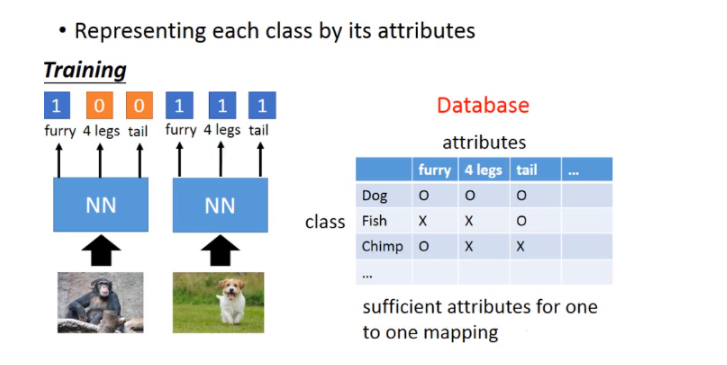
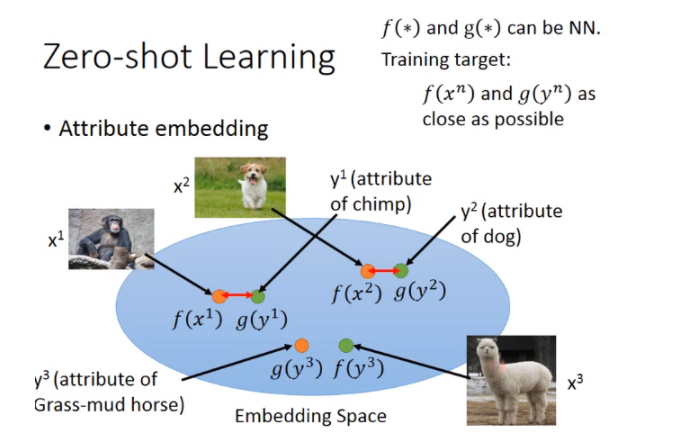
在影像上我们可以把每一个class用它的attribute来表示,也就是说:你有一个database,这个database里面会有所以不同可能的class跟它的特性。假设你要辨识的是动物,但是你training data跟testing data他们的动物是不一样的。但是你有一个database,这个database告诉你说:每一种动物它是有什么样的特性。比如狗就是毛茸茸,四只脚,有尾巴;鱼是有尾巴但不是毛茸茸,没有脚。
这个attribute要更丰富,每一个class都要有不一样的attribute(如果两个class有相同的attribute的话,方法会fail)。那在training的时候,我们不直接辨识说:每一张image是属于哪一个class,而是去辨识说:每一张image里面它具备什么样的attribute。所以你的neural network target就是说:看到猩猩的图,就要说:这是一个毛茸茸的动物,没有四只脚,没有尾巴。看到狗的图就要说:这是毛茸茸的动物,有四只脚,有尾巴。

那在testing的时候,就算今天来了你从来没有见过的image,也是没有关系的。你今天neural network target也不是说:input image它是哪一种动物,而是input这一张image它是具有什么样的attribute。所以input你从来没有见过的动物,你只要把它的attribute长出来,然后你就查表看说:在database里面哪一种动物它的attribute跟你现在model output最接近。有时可能没有一摸一样的也是没有关系的,看谁最接近,那个动物就是你要找的。
后面看不懂了???
15-Transfer Learning的更多相关文章
- (转)Understanding, generalisation, and transfer learning in deep neural networks
Understanding, generalisation, and transfer learning in deep neural networks FEBRUARY 27, 2017 Thi ...
- 论文翻译--StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning
(缺少一些公式的图或者效果图,评论区有惊喜) (个人学习这篇论文时进行的翻译[谷歌翻译,你懂的],如有侵权等,请告知) StarCraft Micromanagement with Reinforce ...
- 《A Survey on Transfer Learning》迁移学习研究综述 翻译
迁移学习研究综述 Sinno Jialin Pan and Qiang Yang,Fellow, IEEE 摘要: 在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据 ...
- 迁移学习( Transfer Learning )
在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型:然后利用这个学习到的模型来对测试文档进行分类与预测.然而,我们看到机器学习算法在当前的Web挖掘研究中存在着一个关 ...
- 【迁移学习】2010-A Survey on Transfer Learning
资源:http://www.cse.ust.hk/TL/ 简介: 一个例子: 关于照片的情感分析. 源:比如你之前已经搜集了大量N种类型物品的图片进行了大量的人工标记(label),耗费了巨大的人力物 ...
- 迁移学习(Transfer Learning)(转载)
原文地址:http://blog.csdn.net/miscclp/article/details/6339456 在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型 ...
- Transfer learning across two sentiment classes using deep learning
用深度学习的跨情感分类的迁移学习 情感分析主要用于预测人们在自然语言中表达的思想和情感. 摘要部分:two types of sentiment:sentiment polarity and poli ...
- 读论文系列:Deep transfer learning person re-identification
读论文系列:Deep transfer learning person re-identification arxiv 2016 by Mengyue Geng, Yaowei Wang, Tao X ...
- 迁移学习-Transfer Learning
迁移学习两种类型: ConvNet as fixed feature extractor:利用在大数据集(如ImageNet)上预训练过的ConvNet(如AlexNet,VGGNet),移除最后几层 ...
- CVPR2018: Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatio-temporal Patterns
论文可以在arxiv下载,老板一作,本人二作,也是我们实验室第一篇CCF A类论文,这个方法我们称为TFusion. 代码:https://github.com/ahangchen/TFusion 解 ...
随机推荐
- 架构师必备:MySQL主从同步原理和应用
日常工作中,MySQL数据库是必不可少的存储,其中读写分离基本是标配,而这背后需要MySQL开启主从同步,形成一主一从.或一主多从的架构,掌握主从同步的原理和知道如何实际应用,是一个架构师的必备技能. ...
- 硝烟中的Scrum和XP
硝烟中的Scrum和XP 初次接触Scrum和XP(更加准确的说是"看到"),心里不免有些疑问,软件开发为什么会有如此多的方式,难道软件开发.软件工程不就是写写代码的事儿吗?直到后 ...
- pycharm输入代码后,没有补全提示
安装pycharm后,输入代码后,没有补全提示 首先检查是否关闭了代码提示,如下图,将红框中"Power Save Mode"前的勾去掉 第二步,如果在输入某些代码时还是没有补全提 ...
- nginx搭建网站踩坑经历
为了更好的阅读体验,请访问我的个人博客 前言 早上刷抖音刷到一个只需要三步的nginx搭建教程(视频地址),觉得有些离谱,跟着复现了一遍,果然很多地方不严谨并且省略了大量步骤,对于很多不了解linux ...
- 解决GitHub访问慢
话不多说,上干货~~~ 1. 打开 http://tool.chinaz.com/dns/ ,在输入框中填写 github.com,然后点击检测按钮,会列出响应ip,如图: 2. 找到hosts文件, ...
- poi实现生成下拉选联动
在我们实际的程序开发中,经常需要用到从excel导入数据中系统中,而为了防止用户在excel中乱输入文字,有些需要用到下拉选的地方,就需要从程序中动态生成模板.本例子简单的讲解一下,如何生成级联下拉选 ...
- 2021.8.3考试总结[NOIP模拟29]
T1 最长不下降子序列 数据范围$1e18$很不妙,但模数$d$只有$150$,考虑从这里突破. 计算的式子是个二次函数,结果只与上一个值有关,而模$d$情况下值最多只有$150$个,就证明序列会出现 ...
- 反转单词顺序列 牛客网 剑指Offer
反转单词顺序列 牛客网 剑指Offer 题目描述 牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上.同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但 ...
- P2774 方格取数问题(最小割)
P2774 方格取数问题 一看题目便知是网络流,但由于无法建图.... 题目直说禁止那些条件,这导致我们直接建图做不到,既然如此,我们这是就要逆向思维,他禁止那些边,我们就连那些边. 我们将棋盘染色, ...
- Linux 限制IP远程连接
1.允许访问编辑 /etc/hosts.allow 文件,如下: sshd:all:allow #允许所有 IP 远程 ssh ...