为了彻底搞懂 hashCode,我钻了一下 JDK 的源码
今天我们来谈谈 Java 中的 hashCode() 方法——通过源码的角度。众所周知,Java 是一门面向对象的编程语言,所有的类都会默认继承自 Object 类,而 Object 的中文意思就是“对象”。
Object 类中就包含了 hashCode() 方法:
@HotSpotIntrinsicCandidate
public native int hashCode();
意味着所有的类都会有一个 hashCode() 方法,该方法会返回一个 int 类型的值。由于 hashCode() 方法是一个本地方法(native 关键字修饰的方法,用 C/C++ 语言实现,由 Java 调用),意味着 Object 类中并没有给出具体的实现。
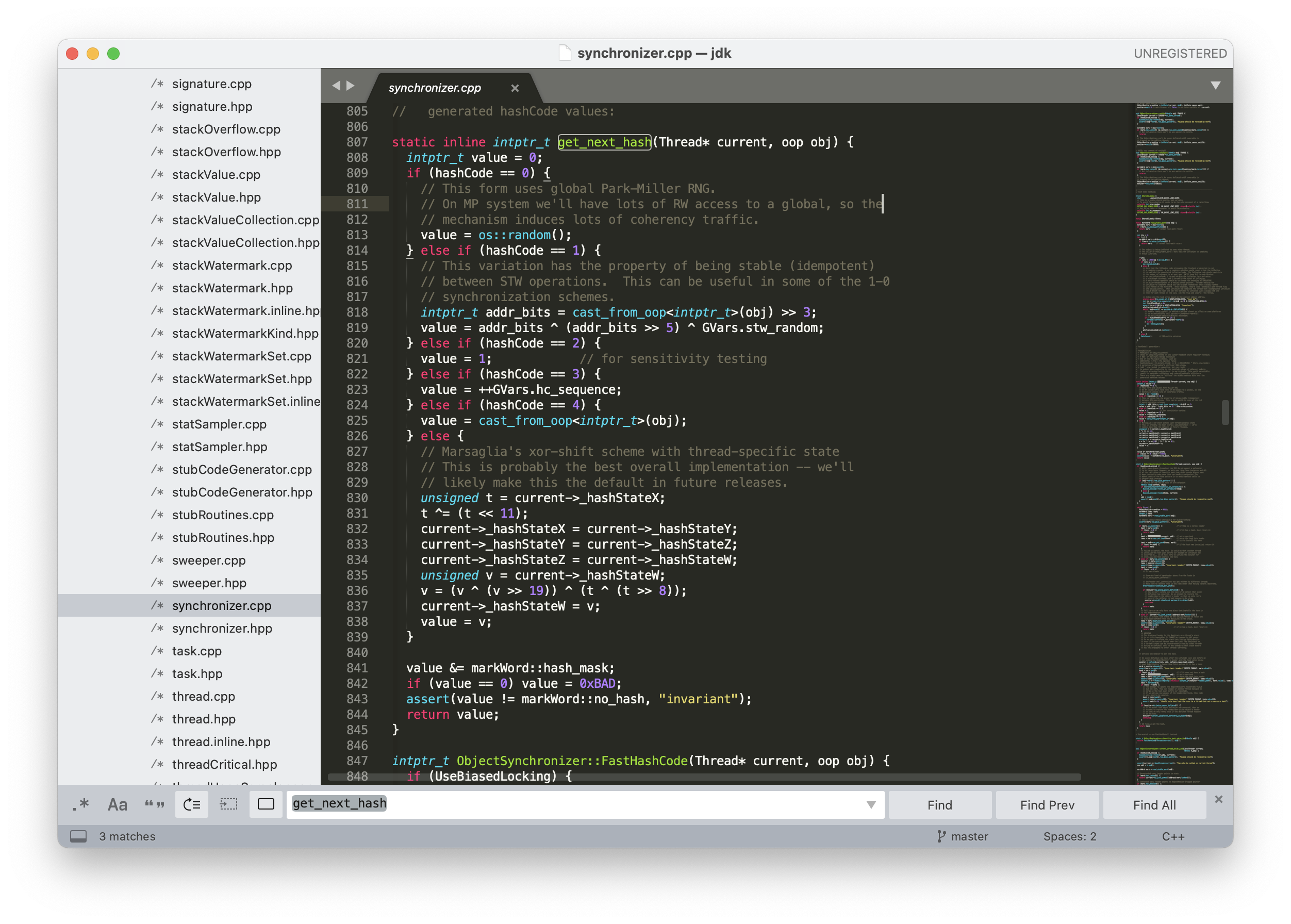
具体的实现可以参考 jdk/src/hotspot/share/runtime/synchronizer.cpp(源码可以到 GitHub 上 OpenJDK 的仓库中下载)。get_next_hash() 方法会根据 hashCode 的取值来决定采用哪一种哈希值的生成策略。
并且 hashCode() 方法被 @HotSpotIntrinsicCandidate 注解修饰,说明它在 HotSpot 虚拟机中有一套高效的实现,基于 CPU 指令。
我在 博客园 共输出了 100 多篇 Java 方面的文章,总字数超过 30 万字, 内容风趣幽默、通俗易懂,收获了很多初学者的认可和支持,内容包括 Java 语法、Java 集合框架、Java 并发编程、Java 虚拟机等核心内容。
为了帮助更多的 Java 初学者,我“一怒之下”就把这些文章重新整理并开源到了 GitHub,起名《教妹学 Java》,听起来是不是就很有趣?
GitHub 开源地址(欢迎 star):https://github.com/itwanger/jmx-java
大家有没有想过这样一个问题:为什么 Object 类需要一个 hashCode() 方法呢?
在 Java 中,hashCode() 方法的主要作用就是为了配合哈希表使用的。
哈希表(Hash Table),也叫散列表,是一种可以通过关键码值(key-value)直接访问的数据结构,它最大的特点就是可以快速实现查找、插入和删除。其中用到的算法叫做哈希,就是把任意长度的输入,变换成固定长度的输出,该输出就是哈希值。像 MD5、SHA1 都用的是哈希算法。
像 Java 中的 HashSet、Hashtable(注意是小写的 t)、HashMap 都是基于哈希表的具体实现。其中的 HashMap 就是最典型的代表,不仅面试官经常问,工作中的使用频率也非常的高。
大家想一下,如果没有哈希表,但又需要这样一个数据结构,它里面存放的数据是不允许重复的,该怎么办呢?
要不使用 equals() 方法进行逐个比较?这种方案当然是可行的。但如果数据量特别特别大,采用 equals() 方法进行逐个对比的效率肯定很低很低,最好的解决方案就是哈希表。
拿 HashMap 来说吧。当我们要在它里面添加对象时,先调用这个对象的 hashCode() 方法,得到对应的哈希值,然后将哈希值和对象一起放到 HashMap 中。当我们要再添加一个新的对象时:
- 获取对象的哈希值;
- 和之前已经存在的哈希值进行比较,如果不相等,直接存进去;
- 如果有相等的,再调用
equals()方法进行对象之间的比较,如果相等,不存了; - 如果不等,说明哈希冲突了,增加一个链表,存放新的对象;
- 如果链表的长度大于 8,转为红黑树来处理。
就这么一套下来,调用 equals() 方法的频率就大大降低了。也就是说,只要哈希算法足够的高效,把发生哈希冲突的频率降到最低,哈希表的效率就特别的高。
来看一下 HashMap 的哈希算法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
先调用对象的 hashCode() 方法,然后对该值进行右移运算,然后再进行异或运算。
通常来说,String 会用来作为 HashMap 的键进行哈希运算,因此我们再来看一下 String 的 hashCode() 方法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
可想而知,经过这么一系列复杂的运算,再加上 JDK 作者这种大师级别的设计,哈希冲突的概率我相信已经降到了最低。
当然了,从理论上来说,对于两个不同对象,它们通过 hashCode() 方法计算后的值可能相同。因此,不能使用 hashCode() 方法来判断两个对象是否相等,必须得通过 equals() 方法。
也就是说:
- 如果两个对象调用
equals()方法得到的结果为 true,调用hashCode()方法得到的结果必定相等; - 如果两个对象调用
hashCode()方法得到的结果不相等,调用equals()方法得到的结果必定为 false;
反之:
- 如果两个对象调用
equals()方法得到的结果为 false,调用hashCode()方法得到的结果不一定不相等; - 如果两个对象调用
hashCode()方法得到的结果相等,调用equals()方法得到的结果不一定为 true;
来看下面这段代码。
public class Test {
public static void main(String[] args) {
Student s1 = new Student(18, "张三");
Map<Student, Integer> scores = new HashMap<>();
scores.put(s1, 98);
System.out.println(scores.get(new Student(18, "张三")));
}
}
class Student {
private int age;
private String name;
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public boolean equals(Object o) {
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
}
我们重写了 Student 类的 equals() 方法,如果两个学生的年纪和姓名相同,我们就认为是同一个学生,虽然很离谱,但我们就是这么草率。
在 main() 方法中,18 岁的张三考试得了 98 分,很不错的成绩,我们把张三和成绩放到了 HashMap 中,然后准备输出张三的成绩:
null
很不巧,结果为 null,而不是预期当中的 98。这是为什么呢?
原因就在于重写 equals() 方法的时候没有重写 hashCode() 方法。默认情况下,hashCode() 方法是一个本地方法,会返回对象的存储地址,显然 put() 中的 s1 和 get() 中的 new Student(18, "张三") 是两个对象,它们的存储地址肯定是不同的。
HashMap 的 get() 方法会调用 hash(key.hashCode()) 计算对象的哈希值,虽然两个不同的 hashCode() 结果经过 hash() 方法计算后有可能得到相同的结果,但这种概率微乎其微,所以就导致 scores.get(new Student(18, "张三")) 无法得到预期的值 18。
怎么解决这个问题呢?很简单,重写 hashCode() 方法。
@Override
public int hashCode() {
return Objects.hash(age, name);
}
Objects 类的 hash() 方法可以针对不同数量的参数生成新的 hashCode() 值。
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
代码似乎很简单,归纳出的数学公式如下所示(n 为字符串长度)。
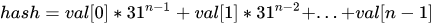
注意:31 是个奇质数,不大不小,一般质数都非常适合哈希计算,偶数相当于移位运算,容易溢出,造成数据信息丢失。
这就意味着年纪和姓名相同的情况下,会得到相同的哈希值。scores.get(new Student(18, "张三")) 就会返回 98 的预期值了。
《Java 编程思想》这本圣经中有一段话,对 hashCode() 方法进行了一段描述。
设计
hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该生成同样的值。如果在将一个对象用put()方法添加进 HashMap 时产生一个hashCode()值,而用get()方法取出时却产生了另外一个hashCode()值,那么就无法重新取得该对象了。所以,如果你的hashCode()方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()就会生成一个不同的哈希值,相当于产生了一个不同的键。
也就是说,如果在重写 hashCode() 和 equals() 方法时,对象中某个字段容易发生改变,那么最好舍弃这些字段,以免产生不可预期的结果。
好。有了上面这些内容作为基础后,我们回头再来看看本地方法 hashCode() 的 C++ 源码。
static inline intptr_t get_next_hash(Thread* current, oop obj) {
intptr_t value = 0;
if (hashCode == 0) {
// This form uses global Park-Miller RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random();
} else if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3;
value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
} else if (hashCode == 2) {
value = 1; // for sensitivity testing
} else if (hashCode == 3) {
value = ++GVars.hc_sequence;
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj);
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = current->_hashStateX;
t ^= (t << 11);
current->_hashStateX = current->_hashStateY;
current->_hashStateY = current->_hashStateZ;
current->_hashStateZ = current->_hashStateW;
unsigned v = current->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
current->_hashStateW = v;
value = v;
}
value &= markWord::hash_mask;
if (value == 0) value = 0xBAD;
assert(value != markWord::no_hash, "invariant");
return value;
}
如果没有 C++ 基础的话,不用细致去看每一行代码,我们只通过表面去了解一下 get_next_hash() 这个方法就行。其中的 hashCode 变量是 JVM 启动时的一个全局参数,可以通过它来切换哈希值的生成策略。
hashCode==0,调用操作系统 OS 的random()方法返回随机数。hashCode == 1,在 STW(stop-the-world)操作中,这种策略通常用于同步方案中。利用对象地址进行计算,使用不经常更新的随机数(GVars.stw_random)参与其中。hashCode == 2,使用返回 1,用于某些情况下的测试。hashCode == 3,从 0 开始计算哈希值,不是线程安全的,多个线程可能会得到相同的哈希值。hashCode == 4,与创建对象的内存位置有关,原样输出。hashCode == 5,默认值,支持多线程,使用了 Marsaglia 的 xor-shift 算法产生伪随机数。所谓的 xor-shift 算法,简单来说,看起来就是一个移位寄存器,每次移入的位由寄存器中若干位取异或生成。所谓的伪随机数,不是完全随机的,但是真随机生成比较困难,所以只要能通过一定的随机数统计检测,就可以当作真随机数来使用。
至于更深层次的挖掘,涉及到数学知识和物理知识,就不展开了。毕竟菜是原罪。
叨逼叨
二哥在 博客园 上写了很多 Java 方面的系列文章,有 Java 核心语法、Java 集合框架、Java IO、Java 并发编程、Java 虚拟机等,也算是体系完整了。

为了能帮助到更多的 Java 初学者,二哥把自己连载的《教妹学Java》开源到了 GitHub,尽管只整理了 50 篇,发现字数已经来到了 10 万+,内容更是没得说,通俗易懂、风趣幽默、图文并茂。
GitHub 开源地址(欢迎 star):https://github.com/itwanger/jmx-java
如果有帮助的话,还请给二哥点个赞,这将是我继续分享下去的最强动力!
为了彻底搞懂 hashCode,我钻了一下 JDK 的源码的更多相关文章
- (转)从一道面试题彻底搞懂hashCode与equals的作用与区别及应当注意的细节
背景:学习java的基础知识,每次回顾,总会有不同的认识.该文系转载 最近去面试了几家公司,被问到hashCode的作用,虽然回答出来了,但是自己还是对hashCode和equals的作用一知半解的, ...
- 彻底搞懂hashCode与equals的作用与区别及应当注意的细节
以前写程序一直没有注意hashCode的作用,一般都是覆盖了equals,缺没有覆盖hashCode,现在发现这是埋下了很多潜在的Bug!今天就来说一说hashCode和equals的作用. 先来试想 ...
- 搞清楚Spring事件机制后:Spring的源码看起来简单多了
本文主讲Spring的事件机制,意图说清楚: 什么是观察者模式? 自己实现事件驱动编程,对标Spring的事件机制 彻底搞懂Spring中的事件机制,从而让大家 本文内容较长,代码干货较多,建议收藏后 ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- 一文搞懂所有Java集合面试题
Java集合 刚刚经历过秋招,看了大量的面经,顺便将常见的Java集合常考知识点总结了一下,并根据被问到的频率大致做了一个标注.一颗星表示知识点需要了解,被问到的频率不高,面试时起码能说个差不多.两颗 ...
- 一文搞懂 Netty 发送数据全流程 | 你想知道的细节全在这里
欢迎关注公众号:bin的技术小屋,如果大家在看文章的时候发现图片加载不了,可以到公众号查看原文 本系列Netty源码解析文章基于 4.1.56.Final版本 在<Netty如何高效接收网络数据 ...
- 彻底搞懂Javascript的“==”
本文转载自:@manxisuo的<通过一张简单的图,让你彻底地.永久地搞懂JS的==运算>. 大家知道,==是JavaScript中比较复杂的一个运算符.它的运算规则奇怪,容让人犯错,从而 ...
- [Java集合] 彻底搞懂HashMap,HashTable,ConcurrentHashMap之关联.
注: 今天看到的一篇讲hashMap,hashTable,concurrentHashMap很透彻的一篇文章, 感谢原作者的分享. 原文地址: http://blog.csdn.net/zhanger ...
- 完全搞懂傅里叶变换和小波(2)——三个中值定理<转载>
书接上文,本文章是该系列的第二篇,按照总纲中给出的框架,本节介绍三个中值定理,包括它们的证明及几何意义.这三个中值定理是高等数学中非常基础的部分,如果读者对于高数的内容已经非常了解,大可跳过此部分.当 ...
随机推荐
- Java小工具类
计时器(秒表),计算程序运行时间用的 public class Stopwatch { private static long startTime=0; private static long end ...
- 深入理解Linux文件系统与日志分析
一.inode和bolck概述 二.链接文件 三.inode节点耗尽故障处理 四.EXT类型文件恢复 五.xfs文件备份和恢复 六.日志文件 一.inode和bolck概述 1.定义 文件数据 文件数 ...
- [HTML]图像标签<img>的用法、属性及路径问题
图像标签:<img> 用法:<img src = "图像地址"> 图像标签的属性 属性 说明 src 指明图像的地址(分为相对路径和绝对路径两 ...
- 创建Akamai CDN
背景说明: XX全球版项目CDN, 原有改之前:主CDN为Akamai,备CDN为Cloudflare. 计划改之后:主CDN为Cloudflare,备CDN为Akamai. 原因:Akamai CD ...
- .Net Core:限流
一.环境 1.vs2019 2..Net Core 3.1 3.引用 AspNetCoreRateLimit 4.0.1 二.基础使用 1.设置 在Startup文件中配置如下,把配置项都放在前面: ...
- 9、ssh服务详解及优化
ssh是"secure shell protocol"的简写,在进行数据传输之前,ssh先对练级数据包通过加密技术进行加密处理, 加密后再进行数据的传输,从而确保了数据的安全: s ...
- scRNAseq benchmark 学习笔记
背景 把早年没填完的坑(单细胞测序的细胞类型鉴别)给重新拾起来 其Github描述的基本情况: 作者并不对单个分类器进行说明,统一包装在benchmark工程里,还建立了docker容器 但说明了在s ...
- 详解 MD5 信息摘要算法
对于软件研发人员来说 MD5 不是一个陌生的词汇,平时的软件研发中,经常使用 MD5 校验消息是否被篡改.验证文件完整性,甚至将MD5当作加密算法使用. MD5虽不陌生,但不是所有研发人员都了解其算法 ...
- CSS 奇思妙想 | 巧妙的实现带圆角的三角形
之前在这篇文章中 -- <老生常谈之 CSS 实现三角形>,介绍了 6 种使用 CSS 实现三角形的方式. 但是其中漏掉了一个非常重要的场景,如何使用纯 CSS 实现带圆角的三角形呢?,像 ...
- Dart学习记录(一)——对象
1. 静态成员.方法 1.1 static 声明 1.2 静态.非静态方法可访问静态成员.调用方法:静态方法不可访问静态成员.调用方法: 1.3 静态成员.方法,属于类的 ,不用实例化对象就可使用,不 ...