(第二章第一部分)TensorFlow框架之文件读取流程
本章概述:在第一章的系列文章中介绍了tf框架的基本用法,从本章开始,介绍与tf框架相关的数据读取和写入的方法,并会在最后,用基础的神经网络,实现经典的Mnist手写数字识别。
有四种获取数据到TensorFlow程序的方法:
- tf.dataAPI:轻松构建复杂的输入管道。(优选方法,在新版本当中)
- QueueRunner:基于队列的输入管道从TensorFlow图形开头的文件中读取数据(这里主要介绍这种)
- Feeding:运行每一步时,Python代码提供数据。(在第一章简单介绍了,配合占位符placeholder给model训练时feed数据)
- 预加载数据:TensorFlow图中的常量或变量包含所有数据(对于小数据集)。
1、文件读取流程
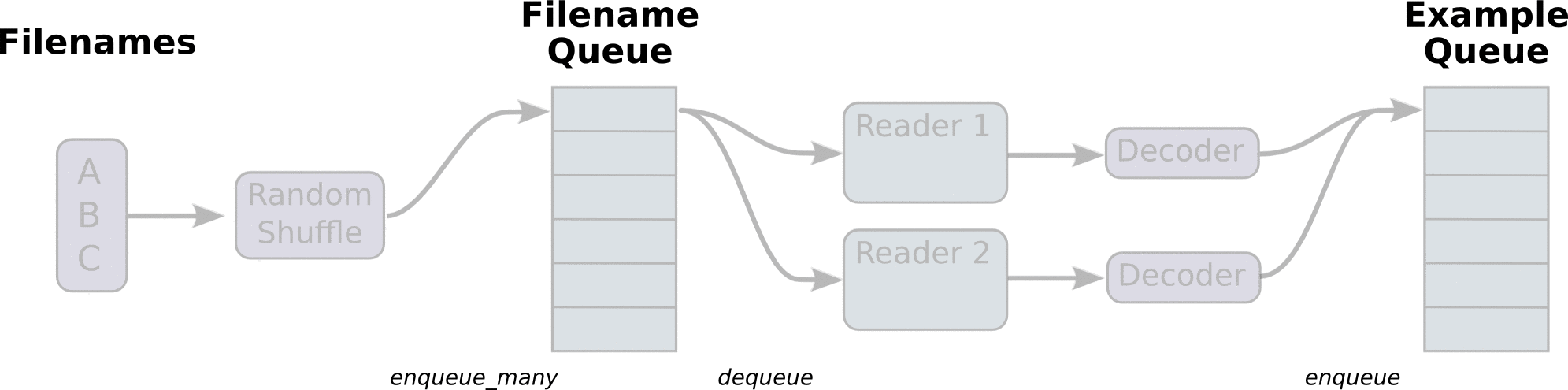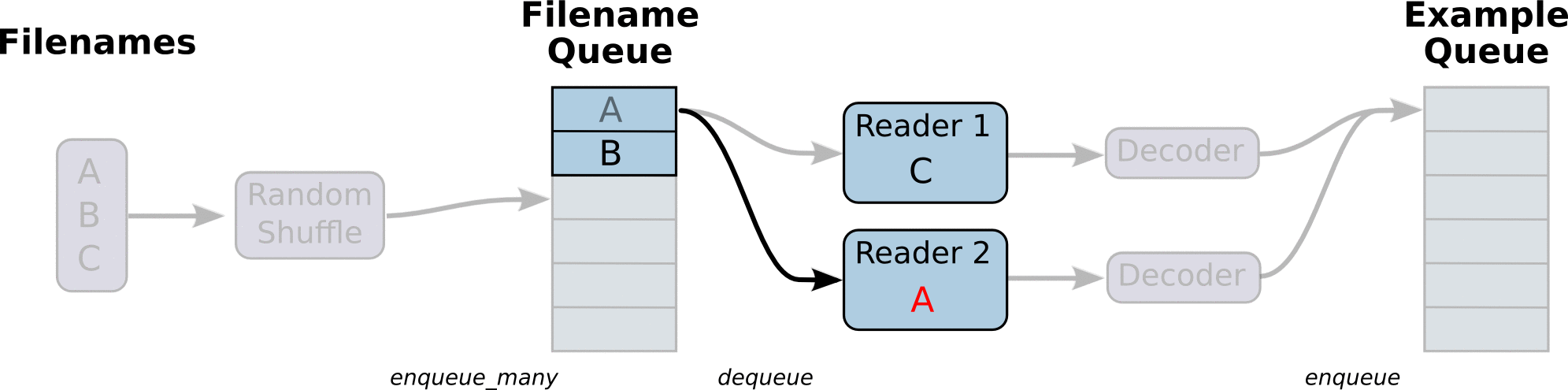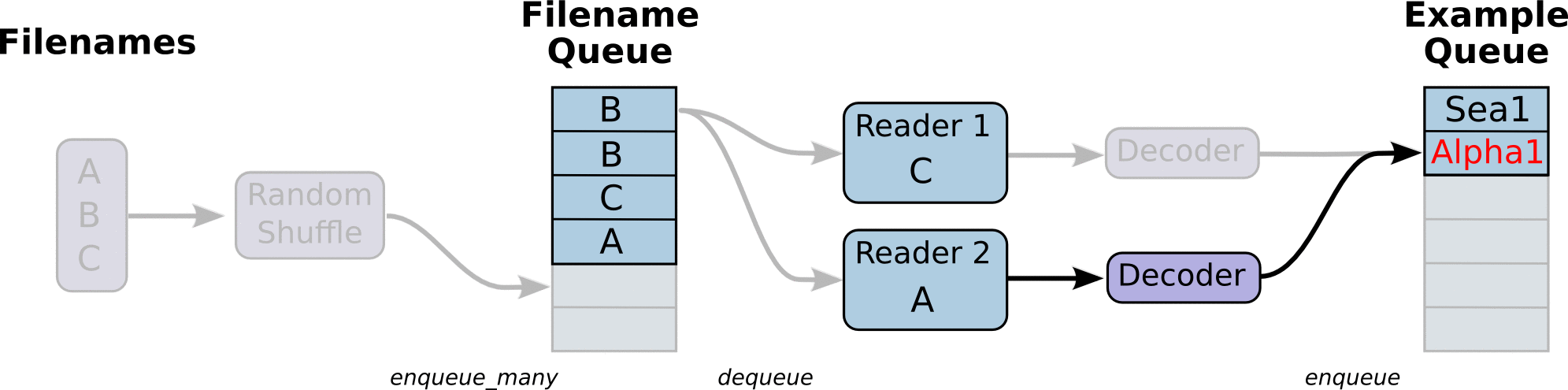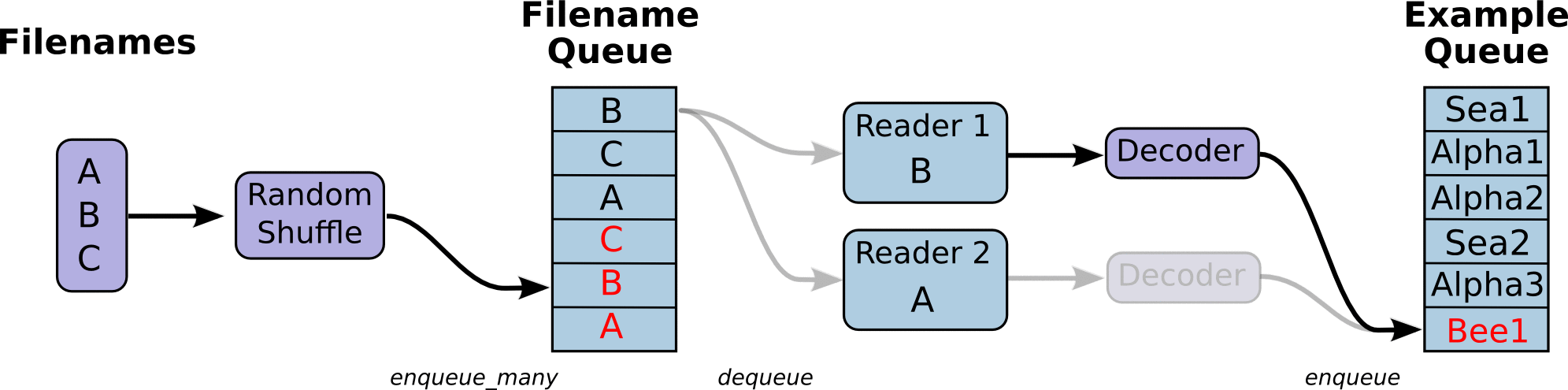
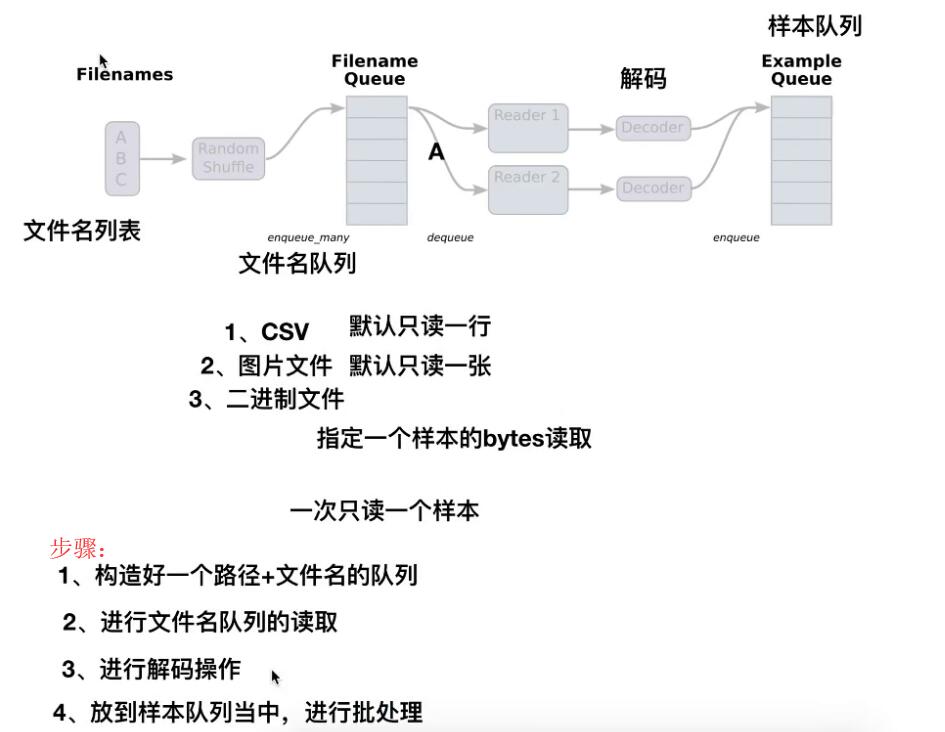
- 第一阶段将生成文件名来读取它们并将它们排入文件名队列。
- 第二阶段对于文件名的队列,进行出队列实例,并且实行内容的解码
第三阶段重新入新的队列,这将是新的样本队列。
注:这些操作需要启动运行这些排队操作的线程(因为这些操作不在主线程,需要开始执行这些操作的子线程),以便我们的训练循环可以将队列中的内容入队出队操作。
1.1 第一阶段
我们称之为构造文件队列,将需要读取的文件装入到一个固定的队列当中
- tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True)
- string_tensor:含有文件名+路径的1阶张量
- num_epochs: 过几遍数据,默认无限过数据
- return 文件队列
1.2、第二阶段
这里需要从队列当中读取文件内容,并且进行解码操作。关于读取内容会有一定的规则
1.2.1 读取文件内容
TensorFlow默认每次只读取一个样本,具体到文本文件读取一行、二进制文件读取指定字节数(最好一个样本)、图片文件默认读取一张图片、TFRecords默认读取一个example
- tf.TextLineReader :
- 阅读文本文件逗号分隔值(CSV)格式, 默认按行读取
- return:读取器实例
- tf.WholeFileReader:
- 用于读取图片文件
- tf.TFRecordReader:
- 读取TFRecords文件
- tf.FixedLengthRecordReader: 二进制文件
- 要读取每个记录是固定数量字节的二进制文件
- record_bytes:整型,指定每次读取(一个样本)的字节数
- return:读取器实例
1、他们有共同的读取方法:read(file_queue):从队列中指定数量内容返回一个Tensors元组(key文件名字,value默认的内容(一个样本))
2、由于默认只会读取一个样本,所以通常想要进行批处理。使用tf.train.batch或tf.train.shuffle_batch进行多样本获取,便于训练时候指定每批次多个样本的训练
1.2.2 内容解码
对于读取不通的文件类型,内容需要解码操作,解码成统一的Tensor格式
- tf.decode_csv:解码文本文件内容
- tf.decode_raw:解码二进制文件内容
- 与tf.FixedLengthRecordReader搭配使用,二进制读取为uint8格式
- tf.image.decode_jpeg(contents)
- 将JPEG编码的图像解码为uint8张量
- return:uint8张量,3-D形状[height, width, channels]
- tf.image.decode_png(contents)
- 将PNG编码的图像解码为uint8张量
- return:张量类型,3-D形状[height, width, channels]
解码阶段,默认所有的内容都解码成tf.uint8格式,如果需要后续的类型处理继续处理
1.3 第三阶段
在解码之后,我们可以直接获取默认的一个样本内容了,但是如果想要获取多个样本,这个时候需要结合管道的末尾进行批处理
- tf.train.batch(tensors, batch_size, num_threads = 1, capacity = 32, name=None)
- 读取指定大小(个数)的张量
- tensors:可以是包含张量的列表, 批处理的内容放到列表当中
- batch_size: 从队列中读取的批处理大小
- num_threads:进入队列的线程数
- capacity:整数,队列中元素的最大数量
- return: tensors
- tf.train.shuffle_batch
2、线程操作
以上的创建这些队列和排队操作称之为tf.train.QueueRunner。每个QueueRunner都负责一个阶段,并拥有需要在线程中运行的排队操作列表。一旦图形被构建, tf.train.start_queue_runners 函数就会要求图中的每个QueueRunner启动它的运行排队操作的线程。(这些操作需要在会话中开启)
- tf.train.start_queue_runners(sess=None, coord=None)
- 收集所有图中的队列线程,并启动线程
- sess: 所在的会话中
- coord:线程协调器
- return:返回所有线程
- tf.train.Coordinator()
- 线程协调员, 实现一个简单的机制来协调一组线程的终止
- request_stop():请求停止
- should_stop():询问是否结束
- join(threads=None, stop_grace_period_secs=120):回收线程
- return: 线程协调员实例
(第二章第一部分)TensorFlow框架之文件读取流程的更多相关文章
- Ionic 入门与实战之第二章第一节:Ionic 环境搭建之开发环境配置
原文发表于我的技术博客 本文是「Ionic 入门与实战」系列连载的第二章第一节,主要对 Ionic 的开发环境配置做了简要的介绍,本文介绍的开发环境为 Mac 系统,Windows 系统基本类似,少许 ...
- python3 第二章 - 第一个程序
1、安装 打开官网 https://www.python.org/downloads/ 下载python3.6.4 如果你是windows\mac电脑,直接双击安装包,一路next即可,如果你是lin ...
- Spring3实战第二章第一小节 Spring bean的初始化和销毁三种方式及优先级
Spring bean的初始化和销毁有三种方式 通过实现 InitializingBean/DisposableBean 接口来定制初始化之后/销毁之前的操作方法: 优先级第二通过 <bean& ...
- 第二章第一个项目——关于mime
一句话就能解释清楚. MIME标注HTTP响应类型. 而后缀名标注文件类型. ---------分割线-------- http响应实质上只有数据,没有文件名. 举个例子吧. HTTP/1.1 200 ...
- tensorflow2.0学习笔记第二章第一节
2.1预备知识 # 条件判断tf.where(条件语句,真返回A,假返回B) import tensorflow as tf a = tf.constant([1,2,3,1,1]) b = tf.c ...
- 《数据结构与算法Python语言描述》习题第二章第一题(python版)
题目:定义一个表示时间的类Timea)Time(hours,minutes,seconds)创建一个时间对象:b)t.hours(),t.minutes(),t.seconds()分别返回时间对象t的 ...
- 第二章第一个项目——package.json
在其中写版本好的时候, { "name": "chatroom", "version": "0.0.1", " ...
- MyBatis从入门到精通:第二章数据的创建与插入文件
数据库表的创建: create table sys_user ( id bigint not null auto_increment, ), user_password ), user_email ) ...
- (第二章第四部分)TensorFlow框架之TFRecords数据的存储与读取
系列博客链接: (第二章第一部分)TensorFlow框架之文件读取流程:https://www.cnblogs.com/kongweisi/p/11050302.html (第二章第二部分)Tens ...
随机推荐
- MySQL单表查询(分组-筛选-过滤-去重-排序)
目录 一:单表查询 1.单表查询(前期准备) 2.插入记录(写入数据) 3.查询关键字 二:查询关键字之where 1.查询id大于等于3小于等于6的数据 2.查询薪资是20000或者18000或者1 ...
- 如何美化 Matplotlib 的工具栏和绘图风格
前言 matplotlib 功能十分强大,就是工具栏丑了点.忍了一个学期之后,还是决定自己动手,魔改一波 matplotlib 的工具栏样式.同时给大家分享一下自己按照 MATLAB 写的 matpl ...
- Lesson5——Pandas Panel三维数据结构
pandas目录 1 简介 自 Pandas 0.25 版本后, Panel 结构已经被废弃. pd.__version__ #查看pandas版本 #'1.2.4' #或者 pd.show_vers ...
- 计算机电子书 2020 CDNDrive 备份(预览版 II)
下载方式 pip install CDNDrive # 或 # pip install git+https://github.com/apachecn/CDNDrive cdrive download ...
- golang 获取当月最后一天日期
now := time.Now() year, month, day := now.Date() //fmt.Println(year, month, day) //2021 September 1 ...
- webpack打包如何统一js和css中图片资源路径
目前项目应用的是vue-cli,自行修改了部分配置.三个环境的情况跟你差不多,测试/生产环境的层级比你还深. 先说下修改了哪些配置 1-build/utils.js下的cssLoaders内的gene ...
- curl 查看接口的网络分段响应时间
示例如下 curl -o /dev/null -s -w %{time_namelookup}::%{time_connect}::%{time_starttransfer}::%{time_tota ...
- 如何按规定的格式向mysql中导入数据
1.首先我们拿到数据,数据必须按照一定的格式书写的.如用|区分字段,换行区分row 12107 | 心情1 | 今天的心情很不好啊. 12108 | 天气 | 今天天气还行. 12109 | 臭美 | ...
- 通过String获取字符数组
方法一: public void getChars(int start,int end,char c[],int offset) 作用是将当前字符串从start到end-1位置上的字符复制到字符数组c ...
- docker基础——3.存储卷
把宿主机的目录或文件链接到容器的目录或文件,可以避免写时复制对高I/O操作的影响,也避免容器销毁时数据丢失. 1. 只指定容器的目录位置,-v docker run -it --name bbox1 ...