Sequence Model-week1编程题2-Character level language model【RNN生成恐龙名 LSTM生成莎士比亚风格文字】
Character level language model - Dinosaurus land
为了构建字符级语言模型来生成新的名称,你的模型将学习不同的名字,并随机生成新的名字。
任务清单:
如何存储文本数据,以便使用RNN进行处理。
如何合成数据,通过采样在每个time step预测,并通过下一个RNN-cell unit。
如何构建字符级文本,生成循环神经网络(RNN)。
为什么梯度修剪(clipping the gradients)很重要?
import numpy as np
import random
import time
import cllm_utils
1. 问题描述(Problem Statement)
1.1 数据集与预处理(Dataset and Preprocessing)
data = open('datasets/dinos.txt', 'r').read()
# 单词全转换为小写
data= data.lower()
# 转化为无序且不重复的元素列表
chars = list(set(data))
print(chars)
data_size, vocab_size = len(data), len(chars)
print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
['i', '\n', 'd', 'e', 'v', 'f', 'l', 'g', 'u', 'm', 'y', 'q', 'w', 's', 'k', 't', 'a', 'h', 'o', 'n', 'r', 'x', 'j', 'z', 'c', 'b', 'p']
There are 19909 total characters and 27 unique characters in your data.
这些字符是a-z(26个英文字符)加上“\n”(换行字符),在这里换行字符起到了在视频中类似的EOS(句子结尾)的作用, 这里表示了名字的结束而不是句子的结尾。下面我们将创建一个字典,每个字符映射到0-26的索引,然后再创建一个字典,该字典每个索引映射相应的字符,它会帮助我们找出softmax层的概率分布输出中的字符。下面创建 char_to_ix 和 ix_to_char 字典。
char_to_ix = { ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = { i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
{0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm', 14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}
1.2 模型概述(Overview of the model)
模型结构如下:
初始化参数
运行optimization循环:
前向传播 计算 loss function
反向传播 计算关于 loss function 的梯度
修建梯度(Clip the gradients) 避免梯度爆炸
用梯度下降更新规则 更新参数
返回学习好的参数
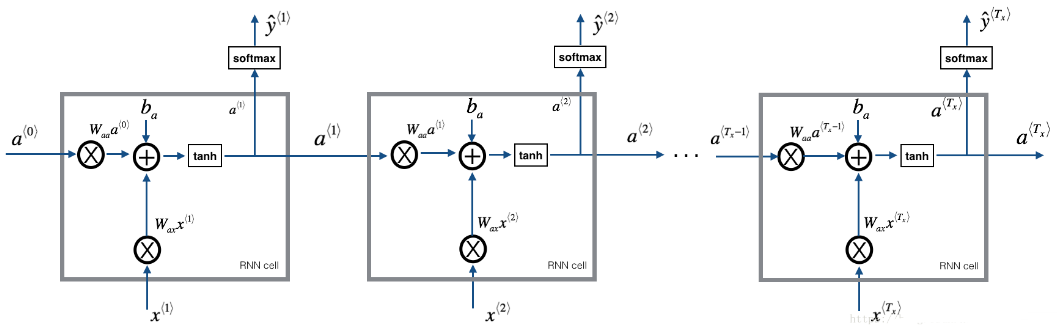
Figure 1: Recurrent Neural Network.
在每个时间步, RNN 会预测给定字符的下一个字符是什么。数据集 \(X = (x^{\langle 1 \rangle}, x^{\langle 2 \rangle}, ..., x^{\langle T_x \rangle})\) 在训练集是字符的列表, 同时 \(Y = (y^{\langle 1 \rangle}, y^{\langle 2 \rangle}, ..., y^{\langle T_x \rangle})\) 在每个time-step \(t\) 也是如此。 我们有:\(x^{\langle t+1 \rangle} = y^{\langle t \rangle}\).
2. 构建模型中的模块(Building blocks of the model)
构建模型两个重要的模块:
梯度修建(Gradient clipping):避免梯度爆炸(exploding gradients)
取样(Sampling):一种用来生成字符的技术
2.1 梯度修剪(Clipping the gradients in the optimization loop)
在这里,我们将实现将调用的clip函数在优化循环中。整个循环结构包含:前向传播,计算cost,反向传播和参数更新。在更新参数之前,我们需要在需要时执行梯度修剪,以确保不会梯度爆炸。
接下来我们将实现一个修剪函数,该函数:输入一个梯度字典,输出一个已经修剪过了的梯度。有许多不同的方法进行梯度修剪。我们将使用 element-wise clipping procedure,梯度向量的每一个元素都被限制在[-N, N]的范围。例,有一个maxValue(比如10),如果梯度的任何值大于10,那么它将被设置为10,那么梯度的任何值小于-10,如果它在-10-10之间,则不变。
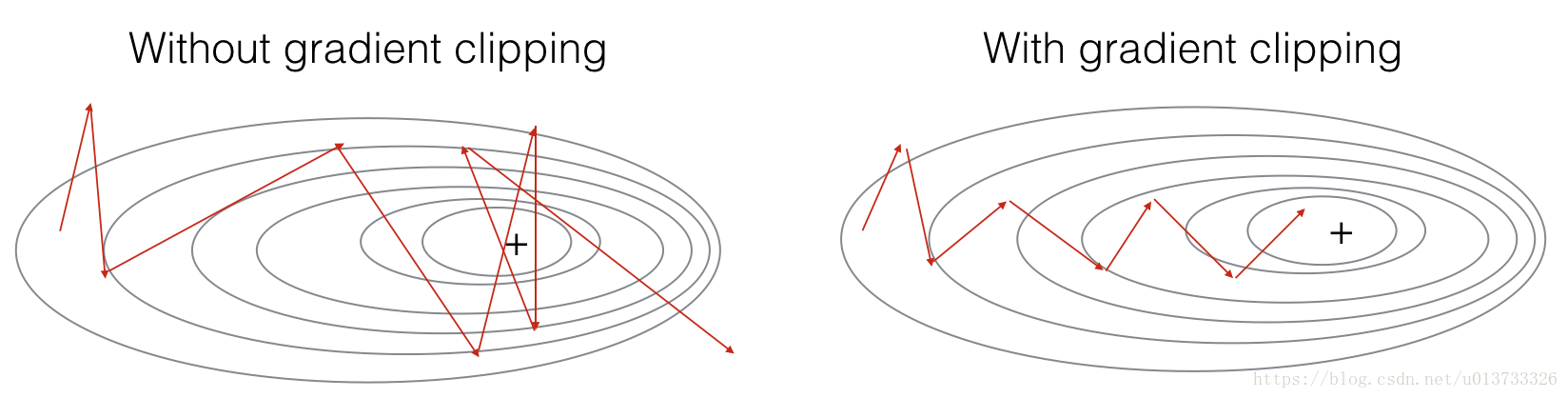
Figure 2: 在网络进入轻微的 "exploding gradient"问题,使用无梯度修剪 和 梯度修剪的可视化图。
Exercise: 实现下面的函数,返回一个修剪过后的梯度字典 gradients;函数接受 maximum threshold,并返回修剪后的梯度。
### GRADED FUNCTION: clip
def clip(gradients, maxValue):
'''
Clips the gradients' values between minimum and maximum.
Arguments:
gradients -- a dictionary containing the gradients "dWaa", "dWax", "dWya", "db", "dby"
maxValue -- everything above this number is set to this number, and everything less than -maxValue is set to -maxValue
Returns:
gradients -- a dictionary with the clipped gradients.
'''
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
### START CODE HERE ###
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines)
for gradient in [dWax, dWaa, dWya, db, dby]:
gradient.clip(-maxValue, maxValue, out=gradient)
### END CODE HERE ###
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
测试:
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
测试:
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
gradients["dWaa"][1][2] = 10.0
gradients["dWax"][3][1] = -10.0
gradients["dWya"][1][2] = 0.2971381536101662
gradients["db"][4] = [10.]
gradients["dby"][1] = [8.45833407]
2.2 采样(Sampling)
假设你的模型已经训练好,你将生成新的文本(字符),生成的过程如下图:

Figure 3: 我们假设模型已经训练过了。我们在第一步传入 \(x^{\langle 1\rangle} = \vec{0}\),然后让网络一次对一个字符进行采样。
Exercise: 实现 sample 函数. 有4个步骤:
Step 1: 网络的第一个输入是 "dummy" input \(x^{\langle 1 \rangle} = \vec{0}\) (零向量)。 这是在生成字符之前的默认输入。 同时设置 \(a^{\langle 0 \rangle} = \vec{0}\)
Step 2: 运行一次 forward propagation,然后得到 \(a^{\langle 1 \rangle}\) and \(\hat{y}^{\langle 1 \rangle}\)。公式如下:
\]
\]
\]
注意 \(\hat{y}^{\langle t+1 \rangle }\) 是一个 (softmax) 概率向量(probability vector) (its entries are between 0 and 1 and sum to 1);\(\hat{y}^{\langle t+1 \rangle}_i\) 表示索引“i”的字符是下一个字符的概率。
- Step 3: 采样(sampling): 根据\(\hat{y}^{\langle t+1 \rangle }\) 指定的概率分布选择下一个字符的索引,假如 \(\hat{y}^{\langle t+1 \rangle }_i = 0.16\), 那么选择索引 "i" 的概率是 16%,为了实现它,你可以使用
np.random.choice.
Here is an example of how to use np.random.choice():
np.random.seed(0)
p = np.array([0.1, 0.0, 0.7, 0.2])
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
这意味着你将根据分布选择索引:
\(P(index = 0) = 0.1, P(index = 1) = 0.0, P(index = 2) = 0.7, P(index = 3) = 0.2\).
Step 4: 在
sample()中实现的最后一步是用 \(x^{\langle t + 1 \rangle }\) 的值覆盖变量x(当前存储\(x^{\langle t \rangle }\))。我们将创建一个与我们 所选择的字符(对应索引idx=1)相对应的one-hot向量([0,1,0,...]) 来表示 \(x^{\langle t + 1 \rangle }\) 作为预测。
然后在步骤1中前向传播 \(x^{\langle t + 1 \rangle }\) ,并不断重复这个过程 直到得到一个 "\n" 字符, 表明已经到达恐龙名称的末尾。
# GRADED FUNCTION: sample
def sample(parameters, char_to_ix, seed):
"""
Sample a sequence of characters according to a sequence of probability distributions output of the RNN
Arguments:
parameters -- python dictionary containing the parameters Waa, Wax, Wya, by, and b.
char_to_ix -- python dictionary mapping each character to an index.
seed -- used for grading purposes. Do not worry about it.
Returns:
indices -- a list of length n containing the indices of the sampled characters.
"""
# Retrieve parameters and relevant shapes from "parameters" dictionary
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
# print(Wya.shape, by.shape)
vocab_size = by.shape[0]
n_a = Waa.shape[1]
### START CODE HERE ###
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). (≈1 line)
x = np.zeros((vocab_size, 1))
# Step 1': Initialize a_prev as zeros (≈1 line)
a_prev = np.zeros((n_a, 1))
# 创建索引的空列表,这是包含要生成的字符的索引的列表。
indices = []
# idx是检测换行符的标志,将其初始化为-1。
idx = -1
# Loop over time-steps t. At each time-step, sample(抽取) a character from a probability distribution(概率分布)
# append its index to "indices"(将其索引附加到“indices”上). We'll stop if we reach 50 characters
# (which should be very unlikely with a well trained model),
# which helps debugging and prevents entering an infinite loop.(这有助于调试,并防止进入无限循环)
counter = 0
newline_character = char_to_ix['\n']
while (idx != newline_character and counter != 50):
# Step 2: Forward propagate x using the equations (1), (2) and (3)
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = softmax(z)
# for grading purposes
np.random.seed(counter+seed)
# Step 3: Sample the index of a character within the vocabulary from the probability distribution y
idx = np.random.choice(list(range(vocab_size)), p = y.ravel()) # y是概率, idx是概率最大的元素
# Append the index to "indices"
indices.append(idx)
# Step 4: Overwrite the input character as the one corresponding to the sampled index.
x = np.zeros((vocab_size, 1))
x[idx] = 1
# Update "a_prev" to be "a"
a_prev = a
# for grading purposes
seed += 1
counter +=1
### END CODE HERE ###
if (counter == 50):
indices.append(char_to_ix['\n'])
return indices
测试:
np.random.seed(2)
_, n_a = 20, 100
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indices = sample(parameters, char_to_ix, 0)
print("Sampling:")
print("list of sampled indices:", indices)
print("list of sampled characters:", [ix_to_char[i] for i in indices])
Sampling:
list of sampled indices: [12, 17, 24, 14, 13, 9, 10, 22, 24, 6, 13, 11, 12, 6, 21, 15, 21, 14, 3, 2, 1, 21, 18, 24, 7, 25, 6, 25, 18, 10, 16, 2, 3, 8, 15, 12, 11, 7, 1, 12, 10, 2, 7, 7, 11, 17, 24, 12, 3, 1, 0]
list of sampled characters: ['l', 'q', 'x', 'n', 'm', 'i', 'j', 'v', 'x', 'f', 'm', 'k', 'l', 'f', 'u', 'o', 'u', 'n', 'c', 'b', 'a', 'u', 'r', 'x', 'g', 'y', 'f', 'y', 'r', 'j', 'p', 'b', 'c', 'h', 'o', 'l', 'k', 'g', 'a', 'l', 'j', 'b', 'g', 'g', 'k', 'q', 'x', 'l', 'c', 'a', '\n']
3. 构建语言模型(Building the language model)
3.1 Gradient descent
在这里,我们将实现一个执行 随机梯度下降 的一个步骤的函数(带有梯度修剪)。我们将一次训练一个样本,所以优化算法将是随机梯度下降,这里是RNN的一个通用的优化循环的步骤:
- 通过RNN前向传播计算cost.
- 通过时间,反向传播计算关于参数的梯度损失.
- 梯度修剪.
- 使用梯度下降更新参数.
Exercise: Implement this optimization process (one step of stochastic gradient descent),下为已知函数.
def rnn_forward(X, Y, a_prev, parameters):
""" Performs the forward propagation through the RNN and computes the cross-entropy loss.
It returns the loss' value as well as a "cache" storing values to be used in the backpropagation."""
....
return loss, cache
def rnn_backward(X, Y, parameters, cache):
""" Performs the backward propagation through time to compute the gradients of the loss with respect
to the parameters. It returns also all the hidden states."""
...
return gradients, a
def update_parameters(parameters, gradients, learning_rate):
""" Updates parameters using the Gradient Descent Update Rule."""
...
return parameters
# GRADED FUNCTION: optimize
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
"""
Execute one step of the optimization to train the model.
Arguments:
X -- list of integers, where each integer is a number that maps to a character in the vocabulary.
Y -- 整数列表,与X完全相同,但向左移动了一个索引。
a_prev -- previous hidden state.
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
b -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
learning_rate -- learning rate for the model.
Returns:
loss -- value of the loss function (cross-entropy)
gradients -- python dictionary containing:
dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
dWya -- Gradients of hidden-to-output weights, of shape (n_y, n_a)
db -- Gradients of bias vector, of shape (n_a, 1)
dby -- Gradients of output bias vector, of shape (n_y, 1)
a[len(X)-1] -- the last hidden state, of shape (n_a, 1)
"""
### START CODE HERE ###
# Forward propagate through time (≈1 line)
loss, cache = rnn_forward(X, Y, a_prev, parameters)
# Backpropagate through time (≈1 line)
gradients, a = rnn_backward(X, Y, parameters, cache)
# Clip your gradients between -5 (min) and 5 (max) (≈1 line)
gradients = clip(gradients, 5)
# Update parameters (≈1 line)
parameters = update_parameters(parameters, gradients, learning_rate)
### END CODE HERE ###
return loss, gradients, a[len(X)-1]
测试:
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [12,3,5,11,22,3]
Y = [4,14,11,22,25, 26]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
print("Loss =", loss)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
print("a_last[4] =", a_last[4])
Loss = 126.503975722
gradients["dWaa"][1][2] = 0.194709315347
np.argmax(gradients["dWax"]) = 93
gradients["dWya"][1][2] = -0.007773876032
gradients["db"][4] = [-0.06809825]
gradients["dby"][1] = [ 0.01538192]
a_last[4] = [-1.]
3.2 Training the model
给定数据集 dinosaur names,我们使用数据集的每一行(一个名称)作为一个训练样本。每100步随机梯度下降,你将抽样10个随机选择的名字,看看算法是怎么做的。记住要打乱数据集,以便随机梯度下降以随机顺序访问样本。
Exercise: 实现 model().
当 examples[index] 包含一个 dinosaur name (string),为了创建example (X, Y), 可以使用:
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
注意:我们使用 index= j % len(examples), 其中 j = 1....num_iterations, 为了确保 examples[index] 总是有效 (index 小于 len(examples))。
rnn_forward() 会将 X 的第一个值 None 解释为 \(x^{\langle 0 \rangle} = \vec{0}\)。 此外,为了确保 Y 等于 X ,会向左移动一步,并添加一个附加的“\n”以表示恐龙名称的结束。
# GRADED FUNCTION: model
def model(data, ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27):
"""
Trains the model and generates dinosaur names.
Arguments:
data -- text corpus
ix_to_char -- dictionary that maps the index to a character
char_to_ix -- dictionary that maps a character to an index
num_iterations -- number of iterations to train the model for
n_a -- number of units of the RNN cell
dino_names -- number of dinosaur names you want to sample at each iteration.
vocab_size -- number of unique characters found in the text, size of the vocabulary
Returns:
parameters -- learned parameters
"""
# Retrieve n_x and n_y from vocab_size
n_x, n_y = vocab_size, vocab_size
# Initialize parameters
parameters = initialize_parameters(n_a, n_x, n_y)
# Initialize loss (this is required because we want to smooth our loss, don't worry about it)
loss = get_initial_loss(vocab_size, dino_names)
# Build list of all dinosaur names (training examples).
with open("./datasets/dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples] # 名字列表
# Shuffle list of all dinosaur names
np.random.seed(0)
np.random.shuffle(examples)
# Initialize the hidden state of your LSTM
a_prev = np.zeros((n_a, 1))
# Optimization loop
for j in range(num_iterations):
### START CODE HERE ###
# Use the hint above to define one training example (X,Y) (≈ 2 lines)
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix['\n']]
# Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters
# Choose a learning rate of 0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
### END CODE HERE ###
# Use a latency trick to keep the loss smooth. It happens here to accelerate the training.
loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\n')
# The number of dinosaur names to print
seed = 0
for name in range(dino_names):
# Sample indices and print them
sampled_indices = sample(parameters, char_to_ix, seed)
print_sample(sampled_indices, ix_to_char)
seed += 1 # To get the same result for grading purposed, increment the seed by one.
print('\n')
return parameters
运行全部
parameters = model(data, ix_to_char, char_to_ix)
输出:
Iteration: 0, Loss: 23.087336
Nkzxwtdmfqoeyhsqwasjkjvu
Kneb
Kzxwtdmfqoeyhsqwasjkjvu
Neb
Zxwtdmfqoeyhsqwasjkjvu
Eb
Xwtdmfqoeyhsqwasjkjvu
Iteration: 2000, Loss: 27.884160
Liusskeomnolxeros
Hmdaairus
Hytroligoraurus
Lecalosapaus
Xusicikoraurus
Abalpsamantisaurus
Tpraneronxeros
Iteration: 4000, Loss: 25.901815
Mivrosaurus
Inee
Ivtroplisaurus
Mbaaisaurus
Wusichisaurus
Cabaselachus
Toraperlethosdarenitochusthiamamumamaon
Iteration: 6000, Loss: 24.608779
Onwusceomosaurus
Lieeaerosaurus
Lxussaurus
Oma
Xusteonosaurus
Eeahosaurus
Toreonosaurus
Iteration: 8000, Loss: 24.070350
Onxusichepriuon
Kilabersaurus
Lutrodon
Omaaerosaurus
Xutrcheps
Edaksoje
Trodiktonus
Iteration: 10000, Loss: 23.844446
Onyusaurus
Klecalosaurus
Lustodon
Ola
Xusodonia
Eeaeosaurus
Troceosaurus
Iteration: 12000, Loss: 23.291971
Onyxosaurus
Kica
Lustrepiosaurus
Olaagrraiansaurus
Yuspangosaurus
Eealosaurus
Trognesaurus
Iteration: 14000, Loss: 23.382338
Meutromodromurus
Inda
Iutroinatorsaurus
Maca
Yusteratoptititan
Ca
Troclosaurus
Iteration: 16000, Loss: 23.268257
Mbutosaurus
Indaa
Iustolophulurus
Macagosaurus
Yusoclichaurus
Caahosaurus
Trodon
Iteration: 18000, Loss: 22.928870
Phytrogiaps
Mela
Mustrha
Pegamosaurus
Ytromacisaurus
Efanshie
Troma
Iteration: 20000, Loss: 23.008798
Onyusperchohychus
Lola
Lytrranfosaurus
Olaa
Ytrrcharomulus
Ehagosaurus
Trrcharonyhus
Iteration: 22000, Loss: 22.794515
Onyvus
Llecakosaurus
Mustodonosaurus
Ola
Yusodon
Eiadosaurus
Trodontorus
Iteration: 24000, Loss: 22.648635
Meutosaurus
Incaachudachus
Itntodon
Mecaessan
Yurong
Daadropachusaurus
Troenatheusaurosaurus
Iteration: 26000, Loss: 22.599152
Nixusehoenomulushapnelspanthuonathitalia
Jigaadroncansaurus
Kustodonis
Nedantrocantiteniupegyankuaeusalomarotimenmpangvin
Ytrodongoluctos
Eebdssaegoterichus
Trodolopiunsitarbilus
Iteration: 28000, Loss: 22.628455
Pnywrodilosaurus
Loca
Mustodonanethosaurus
Phabesceeatopsaurus
Ytrodonnoludosaurus
Elaishacaosaurus
Trrdilosaurus
Iteration: 30000, Loss: 22.587893
Piusosaurus
Locaadrus
Lutosaurus
Pacalosaurus
Yusochesaurus
Eg
Trraodon
Iteration: 32000, Loss: 22.314649
Nivosaurus
Jiacamisaurus
Kusplasaurus
Ncaadosaurus
Yusiandon
Eeaisilaanus
Trokalenator
Iteration: 34000, Loss: 22.445100
Mewsroengosaurus
Ilabafosaurus
Justoeomimavesaurus
Macaeosaurus
Yrosaurus
Eiaeosaurus
Trodondolus
4. 写出莎士比亚风格的文字(Writing like Shakespeare)
任务是产生莎士比亚诗歌,使用莎士比亚诗集。使用LSTM单元,我们可以学习跨越文本中许多字符的较长时间的依赖关系,例如,出现在某个序列的某个字符,会影响在该序列后面的不同字符。由于恐龙名字很短,这些长期的依赖性与恐龙名字并不那么重要。我们用Keras实现了莎士比亚诗歌生成器,我们先来加载所需的包和模型,这可能需要几分钟。

from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io
Loading text data...
Creating training set...
number of training examples: 31412
Vectorizing training set...
Loading model...
为了节省时间,我们已经为莎士比亚诗集《十四行诗》模型训练了1000代(让我们再训练一下这个模型。当它完成了一代的训练——这也需要几分钟)——你可以运行generate_output,这首诗将从你的句子开始,我们的RNN-Shakespeare将为你完成这首诗的其余部分
迭代一次:
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=1, callbacks=[print_callback])
Epoch 1/1
31412/31412 [==============================] - 27s 846us/step - loss: 2.7274
# Run this cell to try with different inputs without having to re-train the model
generate_output()
rite the beginning of your poem, the Shakespeare machine will complete it. Your input is: Forsooth this maketh no sense
Here is your poem:
Forsooth this maketh no sense.
to that i his bongy of sacu, or when thee grace.
to peirout i have sweet from thee, ald the will,
in this, as thy dealt besich whereor me hall thy dould,
and thee and creasts of the cantensed site,
my heart which that a form and ridcus forsed:
for thy coneloting thy where hors of sich,
that prow'st and thincior with with now,
as makted for thou best, and parking frank,
it place corsack thas
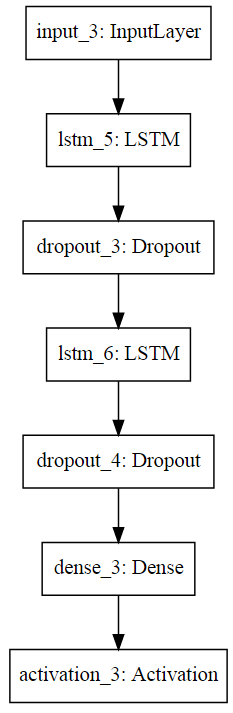
查看模型细节:
#------------用于绘制模型细节,可选--------------#
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
%matplotlib inline
plot_model(model, to_file='shakespeare.png')
SVG(model_to_dot(model).create(prog='dot', format='svg'))
#------------------------------------------------#
Sequence Model-week1编程题2-Character level language model【RNN生成恐龙名 LSTM生成莎士比亚风格文字】的更多相关文章
- Sequence Models Week 1 Character level language model - Dinosaurus land
Character level language model - Dinosaurus land Welcome to Dinosaurus Island! 65 million years ago, ...
- 改善深层神经网络-week1编程题(Regularization)
Regularization Deep Learning models have so much flexibility and capacity that overfitting can be a ...
- Sequence Model-week1编程题1(一步步实现RNN与LSTM)
一步步搭建循环神经网络 将在numpy中实现一个循环神经网络 Recurrent Neural Networks (RNN) are very effective for Natural Langua ...
- 改善深层神经网络-week1编程题(Initializaion)
Initialization 如何选择初始化方式,不同的初始化会导致不同的结果 好的初始化方式: 加速梯度下降的收敛(Speed up the convergence of gradient desc ...
- 改善深层神经网络-week1编程题(GradientChecking)
1. Gradient Checking 你被要求搭建一个Deep Learning model来检测欺诈,每当有人付款,你想知道是否该支付可能是欺诈,例如该用户的账户可能已经被黑客掉. 但是,反向传 ...
- Sequence Model-week1编程题3-用LSTM网络生成爵士乐
Improvise a Jazz Solo with an LSTM Network 实现使用LSTM生成音乐的模型,你可以在结束时听你自己的音乐,接下来你将会学习到: 使用LSTM生成音乐 使用深度 ...
- Sequence Model-week3编程题1-Neural Machine Translation with Attention
1. Neural Machine Translation 下面将构建一个神经机器翻译(NMT)模型,将人类可读日期 ("25th of June, 2009") 转换为机器可读日 ...
- Sequence Model-week3编程题2-Trigger Word Detection
1. Trigger Word Detection 我们的触发词将是 "Activate.".每当它听到你说 "Activate.",它就会发出 "c ...
- 剑指offer编程题66道题 1-25
1.二维数组中的查找 题目描述 在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. ...
随机推荐
- Walker
emmm.......随机化. 好吧,我们不熟. 考虑随机选取两组数据高斯消元消除结果后带入检验,能有超过1/2正确就输出. 其实方程就四个,手动解都没问题. 只是要注意看sin与 ...
- 为何GRE可以封装组播报文而IPSEC却不行?
Author : Email : vip_13031075266@163.com Date : 2021.01.24 Copyright : 未经同意不得 ...
- 计算机网络参考模型和5G模型的那些事
一.分层思想 二.OSI参考模型 三.TCP/IP协议族 四.数据封装和解封装过程 五.层间通讯过程 六.3GPP规范及5G协议栈 一.分层思想 享用牛奶的人未必了解其生产过程 使用网络的人未必知道数 ...
- 用Java实现红黑树
红黑树是众多"平衡的"搜索树模式中的一种,在最坏情况下,它相关操作的时间复杂度为O(log n). 1.红黑树的属性 红黑树是一种二分查找树,与普通的二分查找树不同的一点是,红黑树 ...
- 大数据最后一公里——2021年五大开源数据可视化BI方案对比
个人非常喜欢这种说法,最后一公里不是说目标全部达成,而是把整个路程从头到尾走了一遍. 大数据在经过前几年的野蛮生长以后,开始与数据中台的概念一同向着更实际的方向落地.有人问,数据可视化是不是等同于数据 ...
- SpringCloudAlibaba - 整合 Nacos 实现服务注册与发现
目录 前言 环境 Nacos是什么? 服务发现原理 搭建 Nacos Server Nacos Server 下载地址 Nacos Server 的版本选择 运行 Nacos Server Nacos ...
- 使用PHP获取图像文件的EXIF信息
在我们拍的照片以及各类图像文件中,其实还保存着一些信息是无法直观看到的,比如手机拍照时会有的位置信息,图片的类型.大小等,这些信息就称为 EXIF 信息.一般 JPG . TIFF 这类的图片文件都会 ...
- lightweight openpose 入门实操笔记(pytorch环境)
最近有个小项目要搞姿态识别,简单调研了一下2D的识别: 基本上是下面几种 (单人)single person 直接关键点回归 heatmap,感觉其实就是把一个点的标签弄成一个高斯分布 (多人)mul ...
- Oracle基本入门
一.数据的存储 1.java 程序中的对象:数组.集合保存.当运行的程序结束的时候,里面的数据就消亡. 2.文件存储系统: 存在的缺陷: 2.1)没有明确的数据类型划分. 2.2)没有用户身份验证机制 ...
- P5212-SubString【LCT,SAM】
正题 题目链接:https://www.luogu.com.cn/problem/P5212 题目大意 开始一个字符串\(S\),有\(n\)次操作 在\(S\)末尾加入一个字符串 询问一个串在\(S ...