Java:volatile笔记
Java:volatile笔记
本笔记是根据bilibili上 尚硅谷 的课程 Java大厂面试题第二季 而做的笔记
1. volatile 和 JMM 内存模型的可见性
JUC 下的三个包
- java.util.concurrent
- java.util.concurrent.atomic
- java.util.concurrent.locks
谈谈对 volatile 的理解
volatile 在日常的单线程环境是应用不到的
volatile 是 Java 虚拟机提供的轻量级的同步机制(三大特性)
- 保证可见性
- 不保证原子性
- 禁止指令重排
JMM是什么
JMM 是 Java 内存模型,也就是 Java Memory Model,简称 JMM,本身是一种抽象的概念,实际上并不存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM 关于同步的规定:
- 线程解锁前,必须把共享变量的值刷新回主内存
- 线程加锁前,必须读取主内存的最新值,到自己的工作内存
- 加锁和解锁是同一把锁
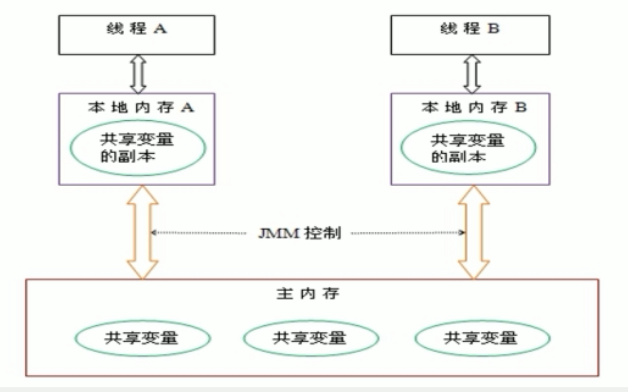
由于 JVM 运行程序的实体是线程,而每个线程创建时 JVM 都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而 Java 内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程:
数据传输速率:硬盘 < 内存 < cache < CPU
上面提到了两个概念:主内存 和 工作内存
主内存:就是计算机的内存,也就是经常提到的8G内存,16G内存
工作内存:当我们实例化
new Student(),那么age = 25也是存储在主内存中- 当同时有三个线程同时访问 student 中的 age 变量时,那么每个线程都会拷贝一份,到各自的工作内存,从而实现了变量的拷贝
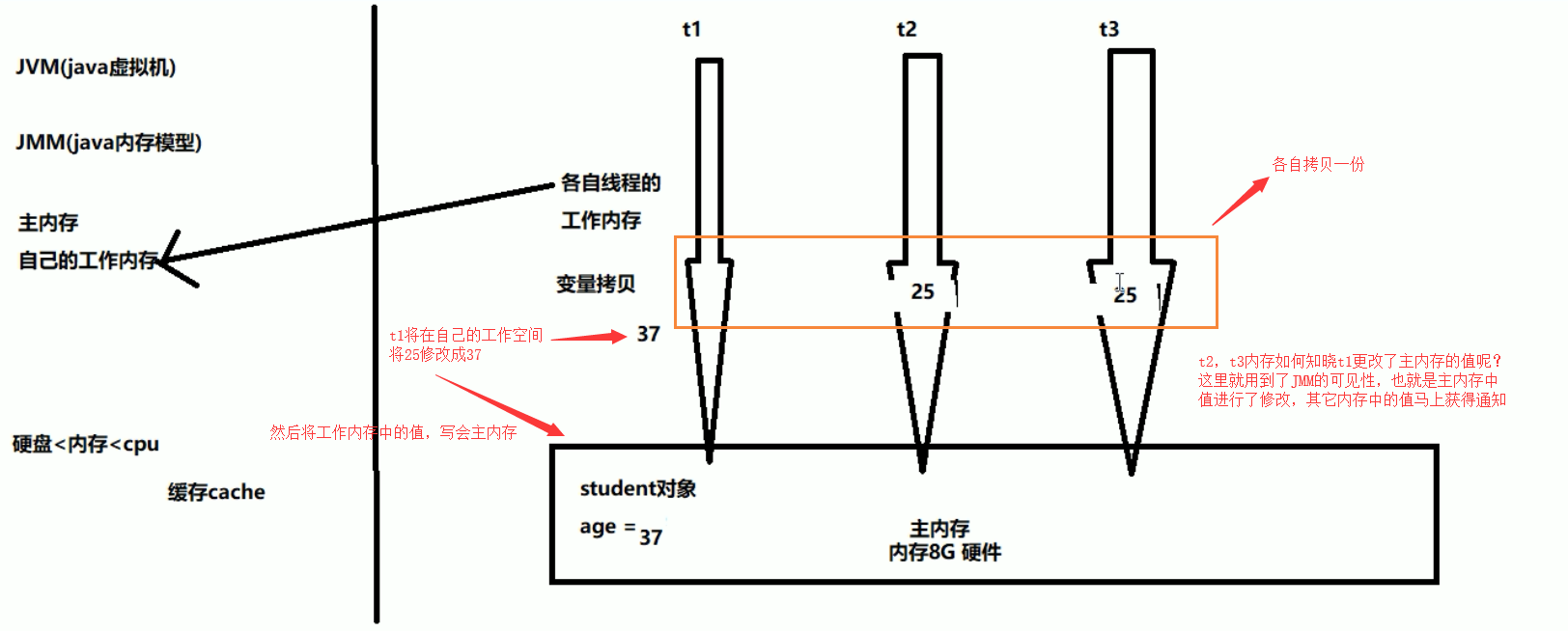
即:JMM 内存模型的可见性,指的是当主内存区域中的值被某个线程写入更改后,其它线程会马上知晓更改后的值,并重新得到更改后的值。
JMM的特性
JMM的三大特性,volatile只保证了两个,即可见性和有序性,但不满足原子性
可见性代码验证
但我们对于成员变量没有添加任何修饰时,是无法感知其它线程修改后的值
/**
* volatile Java虚拟机提供的轻量级同步机制
*
* 可见性(及时通知)
* 不保证原子性
* 禁止指令重排
*/
import java.util.concurrent.TimeUnit;
/**
* 假设是主物理内存
*/
class MyData {
int number = 0;
public void addTo60() {
this.number = 60;
}
}
/**
* 验证volatile的可见性
* 1. 假设int number = 0, number变量之前没有添加volatile关键字修饰
*/
public class volatileDemo {
public static void main(String args []) {
// 资源类
MyData myData = new MyData();
// AAA线程 实现了Runnable接口的,lambda表达式
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t come in");
// 线程睡眠3秒,假设在进行运算
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 修改number的值
myData.addTo60();
// 输出修改后的值
System.out.println(Thread.currentThread().getName() + "\t update number value:" + myData.number);
}, "AAA").start();
while(myData.number == 0) {
// main线程就一直在这里等待循环,直到number的值不等于零
}
// 按道理这个值是不可能打印出来的,因为主线程运行的时候,number的值为0,所以一直在循环
// 如果能输出这句话,说明AAA线程在睡眠3秒后,更新的number的值,重新写入到主内存,并被main线程感知到了
System.out.println(Thread.currentThread().getName() + "\t mission is over");
}
}
// 最后输出结果:
// AAA come in
// AAA update number value:60
// 最后线程没有停止,并行没有输出 mission is over 这句话,说明没有用volatile修饰的变量,是没有可见性
最后线程没有停止,并行没有输出 mission is over 这句话,说明没有用 volatile 修饰的变量,是没有可见性的
当我们修改 MyData 类中的成员变量时,并且添加 volatile 关键字修饰
/**
* 假设是主物理内存
*/
class MyData {
/**
* volatile 修饰的关键字,是为了增加主线程和线程之间的可见性,只要有一个线程修改了内存中的值,其它线程也能马上感知
*/
volatile int number = 0;
public void addTo60() {
this.number = 60;
}
}
/**
* 最后输出结果:
* AAA come in
* AAA update number value:60
* main mission is over
*/
主线程也执行完毕了,说明 volatile 修饰的变量,是具备JVM轻量级同步机制的,能够感知其它线程的修改后的值。
2. volatile 不保证原子性
前言
通过前面对 JMM 的介绍,我们知道,各个线程对主内存中共享变量的操作都是各个线程各自拷贝到自己的工作内存进行操作后在写回到主内存中的。
这就可能存在一个线程 A 修改了共享变量 X 的值,但是还未写入主内存时,另外一个线程 B 又对主内存中同一共享变量 X 进行操作,但此时 A 线程工作内存中共享变量 X 对线程 B 来说是不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题。
原子性
不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被加塞或者被分割,需要具体完成,要么同时成功,要么同时失败。
数据库也经常提到事务具备原子性。
代码测试
为了测试 volatile 是否保证原子性,我们创建了 20 个线程,然后每个线程分别循环 1000 次,来调用 number++ 的方法
MyData myData = new MyData();
// 创建20个线程,线程里面进行1000次循环
for (int i = 0; i < 20; i++) {
new Thread(() -> {
// 里面
for (int j = 0; j < 1000; j++) {
myData.addPlusPlus();
}
}, String.valueOf(i)).start();
}
最后通过 Thread.activeCount(),来感知 20 个线程是否执行完毕,这里判断线程数是否大于2,为什么是2?因为默认是有两个线程的,一个 main 线程,一个 GC 线程
// 需要等待上面20个线程都计算完成后,在用main线程取得最终的结果值
while(Thread.activeCount() > 2) {
// yield表示不执行
Thread.yield();
}
然后在线程执行完毕后,我们在查看 number 的值,假设 volatile 保证原子性的话,那么最后输出的值应该是:20 * 1000 = 20000
完整代码如下所示:
import java.util.concurrent.TimeUnit;
/**
* 假设是主物理内存
*/
class MyData {
/**
* volatile 修饰的关键字,是为了增加 主线程和线程之间的可见性,只要有一个线程修改了内存中的值,其它线程也能马上感知
*/
volatile int number = 0;
public void addTo60() {
this.number = 60;
}
/**
* 注意,此时number 前面是加了volatile修饰
*/
public void addPlusPlus() {
number ++;
}
}
public class volatileDemo {
public static void main(String args []) {
MyData myData = new MyData();
// 创建20个线程,线程里面进行1000次循环
for (int i = 0; i < 20; i++) {
new Thread(() -> {
// 里面
for (int j = 0; j < 1000; j++) {
myData.addPlusPlus();
}
}, String.valueOf(i)).start();
}
// 需要等待上面20个线程都计算完成后,在用main线程取得最终的结果值
// 这里判断线程数是否大于2,为什么是2?因为默认是有两个线程的,一个main线程,一个gc线程
while(Thread.activeCount() > 2) {
// yield表示不执行
Thread.yield();
}
// 查看最终的值
// 假设volatile保证原子性,那么输出的值应该为:20 * 1000 = 20000
System.out.println(Thread.currentThread().getName() + "\t finally number value: " + myData.number);
}
}
最终结果我们会发现,number输出的值并没有20000,而且是每次运行的结果都不一致的,这说明了volatile修饰的变量不保证原子性
为什么出现数值丢失
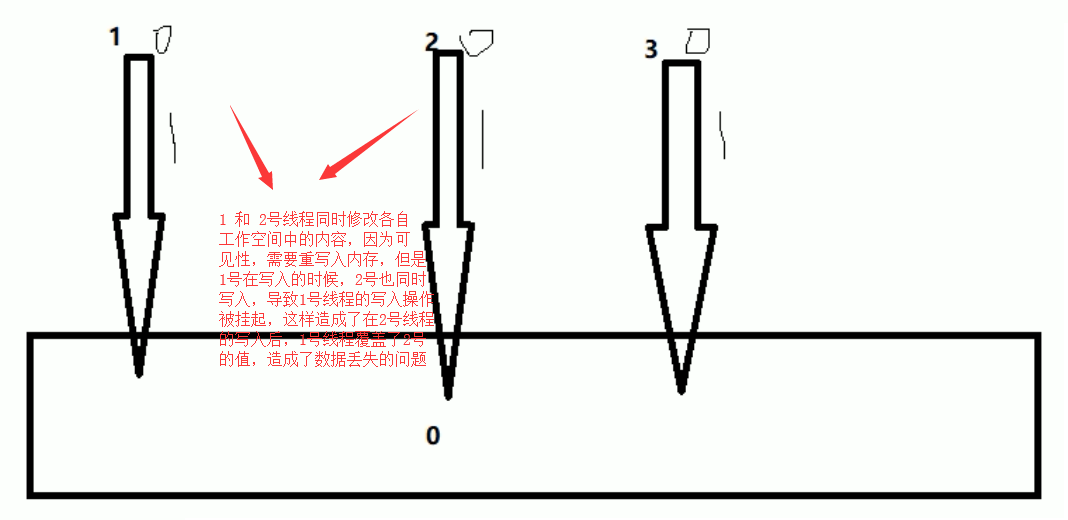
各自线程在写入主内存的时候,出现了数据的丢失,而引起的数值缺失的问题
下面我们将一个简单的 number++ 操作,转换为字节码文件一探究竟
public class T1 {
volatile int n = 0;
public void add() {
n++;
}
}
转换后的字节码文件
public class com.moxi.interview.study.thread.T1 {
volatile int n;
public com.moxi.interview.study.thread.T1();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_0
6: putfield #2 // Field n:I
9: return
public void add();
Code:
0: aload_0
1: dup
2: getfield #2 // Field n:I,拿到n
5: iconst_1 // 准备好1
6: iadd // 给n加上去
7: putfield #2 // Field n:I,在把n放回去
10: return
}
这里查看字节码的操作,是用到了 IDEA 的 javap 命令
我们首先,使用 IDEA 提供的 External Tools,来扩展 javap 命令
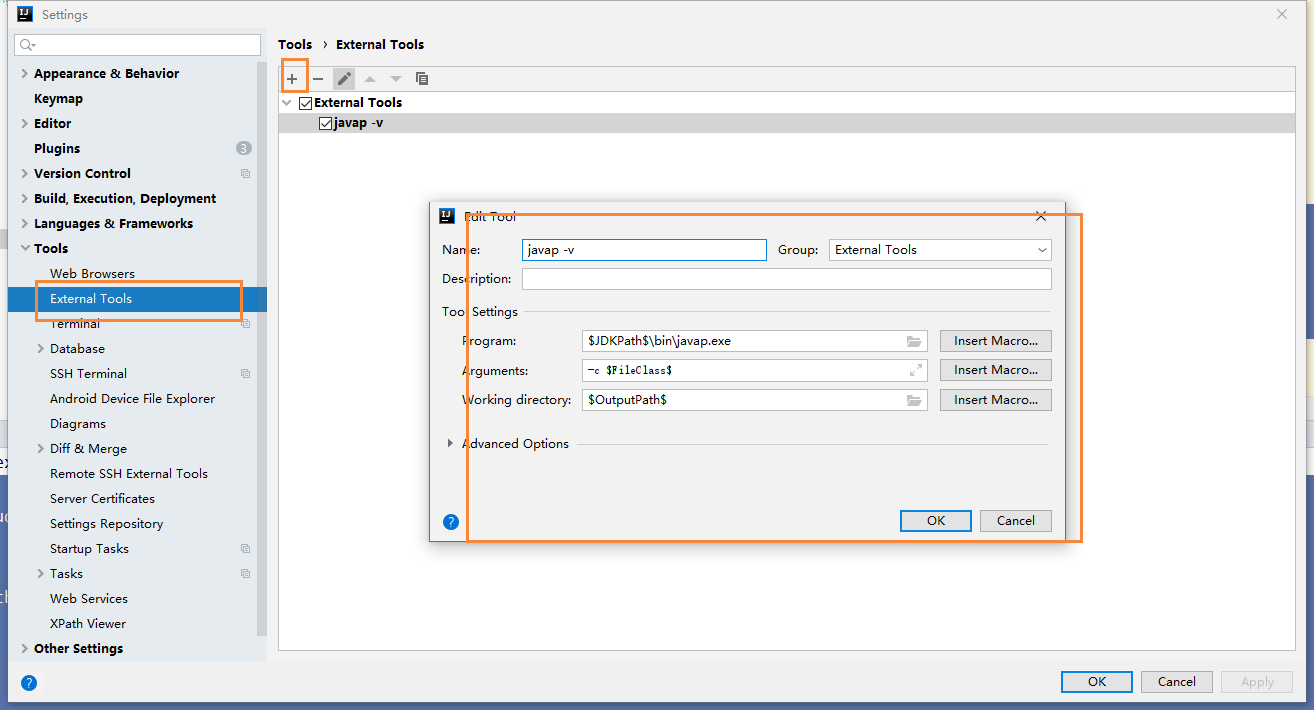
完成上述操作后,我们在需要查看字节码的文件下,右键选择 External Tools 即可
移动到底部,有一份字节码指令对照表,方便我们进行阅读
下面我们就针对 add() 这个方法的字节码文件进行分析
public void add();
Code:
0: aload_0
1: dup
2: getfield #2 // Field n:I
5: iconst_1
6: iadd
7: putfield #2 // Field n:I
10: return
我们能够发现 n++ 这条命令,被拆分成了4个指令
- 执行
getfield从主内存拿到原始n - 执行
iconst_1准备常量1 - 执行
iadd进行加1操作 - 执行
putfileld把累加后的值写回主内存
假设我们没有加 synchronized那么第一步就可能存在着,三个线程同时通过 getfield 命令,拿到主存中的 n 值,然后三个线程,各自在自己的工作内存中进行加 1 操作,但他们并发进行 iadd 命令的时候,因为只能一个进行写,所以其它操作会被挂起,假设1线程,先进行了写操作,在写完后,volatile 的可见性,应该需要告诉其它两个线程,主内存的值已经被修改了,但是因为太快了,其它两个线程,陆续执行 iadd命令,进行写入操作,这就造成了其他线程没有接受到主内存 n 的改变,从而覆盖了原来的值,出现写丢失,这样也就让最终的结果少于 20000
如何解决
因此这也说明,在多线程环境下 number++ 在多线程环境下是非线程安全的,解决的方法有哪些呢?
- 在方法上加入
synchronized
public synchronized void addPlusPlus() {
number ++;
}
我们能够发现引入synchronized关键字后,保证了该方法每次只能够一个线程进行访问和操作,最终输出的结果也就为20000
其它解决方法
上面的方法引入synchronized,虽然能够保证原子性,但是为了解决 number++,而引入重量级的同步机制,有种 杀鸡焉用牛刀 的感觉
除了引用synchronized关键字外,还可以使用 JUC 下面的原子包装类,即刚刚的 int 类型的 number,可以使用 AtomicInteger 来代替
/**
* 创建一个原子Integer包装类,默认为0
*/
AtomicInteger atomicInteger = new AtomicInteger();
public void addAtomic() {
// 相当于 atomicInter ++
atomicInteger.getAndIncrement();
}
然后同理,继续刚刚的操作
// 创建20个线程,线程里面进行1000次循环
for (int i = 0; i < 20; i++) {
new Thread(() -> {
// 里面
for (int j = 0; j < 1000; j++) {
myData.addPlusPlus();
myData.addAtomic();
}
}, String.valueOf(i)).start();
}
// 假设 volatile 保证原子性,那么输出的值应该为: 20 * 1000 = 20000
System.out.println(Thread.currentThread().getName() + "\t finally number value: " + myData.number);
System.out.println(Thread.currentThread().getName() + "\t finally atomicNumber value: " + myData.atomicInteger);
下面的结果,一个是引入 synchronized,一个是使用了原子包装类 AtomicInteger
main finally number value: 20000
main finally atomicNumber value: 20000
字节码指令表
为了方便阅读JVM字节码文件,我从网上找了一份字节码指令表
引用:https://segmentfault.com/a/1190000008722128
表格放在文末了
3. volatile 禁止指令重排
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令重排,一般分为以下三种:
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行指令
单线程环境里面确保最终执行结果和代码顺序的结果一致
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
指令重排-1
public void mySort() {
int x = 11; // 1
int y = 12; // 2
x = x + 5; // 3
y = x * x; // 4
}
按照正常单线程环境,执行顺序是 1 2 3 4
但是在多线程环境下,可能出现以下的顺序:
- 2 1 3 4
- 1 3 2 4
上述的过程就可以当做是指令的重排,即内部执行顺序,和我们的代码顺序不一样
但是指令重排也是有限制的,即不会出现下面的顺序
- 4 3 2 1
因为处理器在进行重排时候,必须考虑到指令之间的数据依赖性
因为步骤 4:需要依赖于 y 的申明,以及 x 的申明,故因为存在数据依赖,无法首先执行
例子:
int a,b,x,y = 0
| 线程1 | 线程2 |
|---|---|
| x = a; | y = b; |
| b = 1; | a = 2; |
| 结果:x = 0; y = 0 |
因为上面的代码,不存在数据的依赖性,因此编译器可能对数据进行重排
| 线程1 | 线程2 |
|---|---|
| b = 1; | a = 2; |
| x = a; | y = b; |
| 结果:x = 2; y = 1 |
这样造成的结果,和最开始的就不一致了,这就是导致重排后,结果和最开始的不一样,因此为了防止这种结果出现,volatile 就规定禁止指令重排,为了保证数据的一致性
指令重排-2
比如下面这段代码
public class ResortSeqDemo {
int a= 0;
boolean flag = false;
public void method01() {
a = 1;
flag = true;
}
public void method02() {
if(flag) {
a = a + 5;
System.out.println("reValue:" + a);
}
}
}
我们按照正常的顺序,分别调用 method01() 和 method02() 那么,最终输出就是 a = 6
但是如果在多线程环境下,因为 method01() 和 method02(),他们之间不能存在数据依赖的问题,因此原先的顺序可能是
a = 1;
flag = true;
a = a + 5;
System.out.println("reValue:" + a);
但是在经过编译器,指令,或者内存的重排后,可能会出现这样的情况
flag = true;
a = a + 5;
System.out.println("reValue:" + a);
a = 1;
也就是先执行 flag = true 后,另外一个线程马上调用 method02(),满足 flag 的判断,最终让 a + 5,结果为 5,这样同样出现了数据不一致的问题
为什么会出现这个结果:多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
这样就需要通过 volatile 来修饰,来保证线程安全性
volatile 针对指令重排做了啥
volatile 实现禁止指令重排优化,从而避免了多线程环境下程序出现乱序执行的现象
首先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个 CPU 指令,它的作用有两个:
- 保证特定操作的顺序
- 保证某些变量的内存可见性(利用该特性实现 volatile 的内存可见性)
由于编译器和处理器都能执行指令重排的优化,如果在指令间插入一条 Memory Barrier 则会告诉编译器和CPU,不管什么指令都不能和这条 Memory Barrier 指令重排序,也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。 内存屏障另外一个作用是刷新出各种 CPU 的缓存数,因此任何 CPU 上的线程都能读取到这些数据的最新版本。

也就是过在volatile的写和读的时候,加入屏障,防止出现指令重排的
线程安全获得保证
工作内存与主内存同步延迟现象导致的可见性问题
- 可通过 synchronized 或 volatile 关键字解决,他们都可以使一个线程修改后的变量立即对其它线程可见
对于指令重排导致的可见性问题和有序性问题
- 可以使用 volatile 关键字解决,因为 volatile 关键字的另一个作用就是禁止重排序优化
4. volatile 的应用
单例模式DCL代码
DCL:Double Check Lock
首先回顾一下,单线程下的单例模式代码
/**
* SingletonDemo(单例模式)
*/
public class SingletonDemo {
private static SingletonDemo instance = null;
private SingletonDemo () {
System.out.println(Thread.currentThread().getName() + "\t 我是构造方法SingletonDemo");
}
public static SingletonDemo getInstance() {
if(instance == null) {
instance = new SingletonDemo();
}
return instance;
}
public static void main(String[] args) {
// 这里的 == 是比较内存地址
System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());
System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());
System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());
System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());
}
}
// 最后输出的结果:
// main 我是构造方法SingletonDemo
// true
// true
// true
// true
但是在多线程的环境下,我们的单例模式是否还是同一个对象了
/**
* SingletonDemo(单例模式)
*/
public class SingletonDemo {
private static SingletonDemo instance = null;
private SingletonDemo () {
System.out.println(Thread.currentThread().getName() + "\t 我是构造方法SingletonDemo");
}
public static SingletonDemo getInstance() {
if(instance == null) {
instance = new SingletonDemo();
}
return instance;
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
SingletonDemo.getInstance();
}, String.valueOf(i)).start();
}
}
}
从下面的结果我们可以看出:
// 取其中一次输出:
// 0 我是构造方法SingletonDemo
// 1 我是构造方法SingletonDemo
// 2 我是构造方法SingletonDemo
我们通过 SingletonDemo.getInstance() 获取到的对象,并不是同一个,而是被好几个线程都进行了创建
那么在多线程环境下,单例模式如何保证呢?
解决方法-1
引入 synchronized 关键字
public synchronized static SingletonDemo getInstance() {
if(instance == null) {
instance = new SingletonDemo();
}
return instance;
}
我们能够发现,通过引入synchronized 关键字,能够解决高并发环境下的单例模式问题
但是 synchronized 属于重量级的同步机制,它只允许一个线程同时访问获取实例的方法,但是为了保证数据一致性,而减低了并发性,因此采用的比较少
解决方法2
通过引入DCL Double Check Lock 双端检锁机制
就是在进来和出去的时候,进行检测
public static SingletonDemo getInstance() {
if(instance == null) {
// 同步代码段的时候,进行检测
synchronized (SingletonDemo.class) {
if(instance == null) {
instance = new SingletonDemo();
}
}
}
return instance;
}
从输出结果来看,确实能够保证单例模式的正确性,但是上面的方法还是存在问题的
DCL(双端检锁)机制不一定是线程安全的,原因是有指令重排的存在,而加入volatile可以禁止指令重排
原因是在某一个线程执行到第一次检测的时候,读取到 instance 不为 null,而由于指令重拍操作,此时 instance 的引用对象可能没有完成实例化。
因为 instance = new SingletonDemo();可以分为以下三步进行完成:
memory = allocate(); // 1、分配对象内存空间
instance(memory); // 2、初始化对象
instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null
但是我们通过上面的三个步骤,能够发现,步骤2 和 步骤3之间不存在数据依赖关系,而且无论重排前还是重排后,程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
memory = allocate(); // 1、分配对象内存空间
instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null,但是对象还没有初始化完成
instance(memory); // 2、初始化对象
这样就会造成什么问题呢?出现了先赋值再进行构造的情况
所以当一条线程访问instance不为null时,由于instance实例未必已初始化完成,这就造成了线程安全的问题
所以需要引入volatile,来保证出现指令重排的问题,从而保证单例模式的线程安全性:
private static volatile SingletonDemo instance = null;
最终代码
/**
* SingletonDemo(单例模式)
*/
public class SingletonDemo {
private static volatile SingletonDemo instance = null;
private SingletonDemo () {
System.out.println(Thread.currentThread().getName() + "\t 我是构造方法SingletonDemo");
}
public static SingletonDemo getInstance() {
if(instance == null) {
// a:双重检查加锁多线程情况下会出现:线程A已经执行到d处,没有完成初始;因此此处还是为空,则线程B还是能到这里
// 然后在线程A完成初始化后,B还是能拿到这把锁,因此后续还是要在进行一次null的判断
synchronized (SingletonDemo.class) // b
{
// c:不加volitale关键字的话有可能会出现尚未完全初始化就获取到的情况。原因是内存模型允许无序写入
if(instance == null) {
// d:此时才开始初始化
instance = new SingletonDemo();
}
}
}
return instance;
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
SingletonDemo.getInstance();
}, String.valueOf(i)).start();
}
}
}
附录:字节码指令表
| 字节码 | 助记符 | 指令含义 |
|---|---|---|
| 0x00 | nop | None |
| 0x01 | aconst_null | 将null推送至栈顶 |
| 0x02 | iconst_m1 | 将int型-1推送至栈顶 |
| 0x03 | iconst_0 | 将int型0推送至栈顶 |
| 0x04 | iconst_1 | 将int型1推送至栈顶 |
| 0x05 | iconst_2 | 将int型2推送至栈顶 |
| 0x06 | iconst_3 | 将int型3推送至栈顶 |
| 0x07 | iconst_4 | 将int型4推送至栈顶 |
| 0x08 | iconst_5 | 将int型5推送至栈顶 |
| 0x09 | lconst_0 | 将long型0推送至栈顶 |
| 0x0a | lconst_1 | 将long型1推送至栈顶 |
| 0x0b | fconst_0 | 将float型0推送至栈顶 |
| 0x0c | fconst_1 | 将float型1推送至栈顶 |
| 0x0d | fconst_2 | 将float型2推送至栈顶 |
| 0x0e | dconst_0 | 将double型0推送至栈顶 |
| 0x0f | dconst_1 | 将double型1推送至栈顶 |
| 0x10 | bipush | 将单字节的常量值(-128~127)推送至栈顶 |
| 0x11 | sipush | 将一个短整型常量(-32768~32767)推送至栈顶 |
| 0x12 | ldc | 将int,float或String型常量值从常量池中推送至栈顶 |
| 0x13 | ldc_w | 将int,float或String型常量值从常量池中推送至栈顶(宽索引) |
| 0x14 | ldc2_w | 将long或double型常量值从常量池中推送至栈顶(宽索引) |
| 0x15 | iload | 将指定的int型本地变量推送至栈顶 |
| 0x16 | lload | 将指定的long型本地变量推送至栈顶 |
| 0x17 | fload | 将指定的float型本地变量推送至栈顶 |
| 0x18 | dload | 将指定的double型本地变量推送至栈顶 |
| 0x19 | aload | 将指定的引用类型本地变量推送至栈顶 |
| 0x1a | iload_0 | 将第一个int型本地变量推送至栈顶 |
| 0x1b | iload_1 | 将第二个int型本地变量推送至栈顶 |
| 0x1c | iload_2 | 将第三个int型本地变量推送至栈顶 |
| 0x1d | iload_3 | 将第四个int型本地变量推送至栈顶 |
| 0x1e | lload_0 | 将第一个long型本地变量推送至栈顶 |
| 0x1f | lload_1 | 将第二个long型本地变量推送至栈顶 |
| 0x20 | lload_2 | 将第三个long型本地变量推送至栈顶 |
| 0x21 | lload_3 | 将第四个long型本地变量推送至栈顶 |
| 0x22 | fload_0 | 将第一个float型本地变量推送至栈顶 |
| 0x23 | fload_1 | 将第二个float型本地变量推送至栈顶 |
| 0x24 | fload_2 | 将第三个float型本地变量推送至栈顶 |
| 0x25 | fload_3 | 将第四个float型本地变量推送至栈顶 |
| 0x26 | dload_0 | 将第一个double型本地变量推送至栈顶 |
| 0x27 | dload_1 | 将第二个double型本地变量推送至栈顶 |
| 0x28 | dload_2 | 将第三个double型本地变量推送至栈顶 |
| 0x29 | dload_3 | 将第四个double型本地变量推送至栈顶 |
| 0x2a | aload_0 | 将第一个引用类型本地变量推送至栈顶 |
| 0x2b | aload_1 | 将第二个引用类型本地变量推送至栈顶 |
| 0x2c | aload_2 | 将第三个引用类型本地变量推送至栈顶 |
| 0x2d | aload_3 | 将第四个引用类型本地变量推送至栈顶 |
| 0x2e | iaload | 将int型数组指定索引的值推送至栈顶 |
| 0x2f | laload | 将long型数组指定索引的值推送至栈顶 |
| 0x30 | faload | 将float型数组指定索引的值推送至栈顶 |
| 0x31 | daload | 将double型数组指定索引的值推送至栈顶 |
| 0x32 | aaload | 将引用类型数组指定索引的值推送至栈顶 |
| 0x33 | baload | 将boolean或byte型数组指定索引的值推送至栈顶 |
| 0x34 | caload | 将char型数组指定索引的值推送至栈顶 |
| 0x35 | saload | 将short型数组指定索引的值推送至栈顶 |
| 0x36 | istore | 将栈顶int型数值存入指定本地变量 |
| 0x37 | lstore | 将栈顶long型数值存入指定本地变量 |
| 0x38 | fstore | 将栈顶float型数值存入指定本地变量 |
| 0x39 | dstore | 将栈顶double型数值存入指定本地变量 |
| 0x3a | astore | 将栈顶引用类型数值存入指定本地变量 |
| 0x3b | istore_0 | 将栈顶int型数值存入第一个本地变量 |
| 0x3c | istore_1 | 将栈顶int型数值存入第二个本地变量 |
| 0x3d | istore_2 | 将栈顶int型数值存入第三个本地变量 |
| 0x3e | istore_3 | 将栈顶int型数值存入第四个本地变量 |
| 0x3f | lstore_0 | 将栈顶long型数值存入第一个本地变量 |
| 0x40 | lstore_1 | 将栈顶long型数值存入第二个本地变量 |
| 0x41 | lstore_2 | 将栈顶long型数值存入第三个本地变量 |
| 0x42 | lstore_3 | 将栈顶long型数值存入第四个本地变量 |
| 0x43 | fstore_0 | 将栈顶float型数值存入第一个本地变量 |
| 0x44 | fstore_1 | 将栈顶float型数值存入第二个本地变量 |
| 0x45 | fstore_2 | 将栈顶float型数值存入第三个本地变量 |
| 0x46 | fstore_3 | 将栈顶float型数值存入第四个本地变量 |
| 0x47 | dstore_0 | 将栈顶double型数值存入第一个本地变量 |
| 0x48 | dstore_1 | 将栈顶double型数值存入第二个本地变量 |
| 0x49 | dstore_2 | 将栈顶double型数值存入第三个本地变量 |
| 0x4a | dstore_3 | 将栈顶double型数值存入第四个本地变量 |
| 0x4b | astore_0 | 将栈顶引用型数值存入第一个本地变量 |
| 0x4c | astore_1 | 将栈顶引用型数值存入第二个本地变量 |
| 0x4d | astore_2 | 将栈顶引用型数值存入第三个本地变量 |
| 0x4e | astore_3 | 将栈顶引用型数值存入第四个本地变量 |
| 0x4f | iastore | 将栈顶int型数值存入指定数组的指定索引位置 |
| 0x50 | lastore | 将栈顶long型数值存入指定数组的指定索引位置 |
| 0x51 | fastore | 将栈顶float型数值存入指定数组的指定索引位置 |
| 0x52 | dastore | 将栈顶double型数值存入指定数组的指定索引位置 |
| 0x53 | aastore | 将栈顶引用型数值存入指定数组的指定索引位置 |
| 0x54 | bastore | 将栈顶boolean或byte型数值存入指定数组的指定索引位置 |
| 0x55 | castore | 将栈顶char型数值存入指定数组的指定索引位置 |
| 0x56 | sastore | 将栈顶short型数值存入指定数组的指定索引位置 |
| 0x57 | pop | 将栈顶数值弹出(数值不能是long或double类型的) |
| 0x58 | pop2 | 将栈顶的一个(对于非long或double类型)或两个数值(对于非long或double的其他类型)弹出 |
| 0x59 | dup | 复制栈顶数值并将复制值压入栈顶 |
| 0x5a | dup_x1 | 复制栈顶数值并将两个复制值压入栈顶 |
| 0x5b | dup_x2 | 复制栈顶数值并将三个(或两个)复制值压入栈顶 |
| 0x5c | dup2 | 复制栈顶一个(对于long或double类型)或两个(对于非long或double的其他类型)数值并将复制值压入栈顶 |
| 0x5d | dup2_x1 | dup_x1指令的双倍版本 |
| 0x5e | dup2_x2 | dup_x2指令的双倍版本 |
| 0x5f | swap | 将栈顶最顶端的两个数值互换(数值不能是long或double类型) |
| 0x60 | iadd | 将栈顶两int型数值相加并将结果压入栈顶 |
| 0x61 | ladd | 将栈顶两long型数值相加并将结果压入栈顶 |
| 0x62 | fadd | 将栈顶两float型数值相加并将结果压入栈顶 |
| 0x63 | dadd | 将栈顶两double型数值相加并将结果压入栈顶 |
| 0x64 | isub | 将栈顶两int型数值相减并将结果压入栈顶 |
| 0x65 | lsub | 将栈顶两long型数值相减并将结果压入栈顶 |
| 0x66 | fsub | 将栈顶两float型数值相减并将结果压入栈顶 |
| 0x67 | dsub | 将栈顶两double型数值相减并将结果压入栈顶 |
| 0x68 | imul | 将栈顶两int型数值相乘并将结果压入栈顶 |
| 0x69 | lmul | 将栈顶两long型数值相乘并将结果压入栈顶 |
| 0x6a | fmul | 将栈顶两float型数值相乘并将结果压入栈顶 |
| 0x6b | dmul | 将栈顶两double型数值相乘并将结果压入栈顶 |
| 0x6c | idiv | 将栈顶两int型数值相除并将结果压入栈顶 |
| 0x6d | ldiv | 将栈顶两long型数值相除并将结果压入栈顶 |
| 0x6e | fdiv | 将栈顶两float型数值相除并将结果压入栈顶 |
| 0x6f | ddiv | 将栈顶两double型数值相除并将结果压入栈顶 |
| 0x70 | irem | 将栈顶两int型数值作取模运算并将结果压入栈顶 |
| 0x71 | lrem | 将栈顶两long型数值作取模运算并将结果压入栈顶 |
| 0x72 | frem | 将栈顶两float型数值作取模运算并将结果压入栈顶 |
| 0x73 | drem | 将栈顶两double型数值作取模运算并将结果压入栈顶 |
| 0x74 | ineg | 将栈顶int型数值取负并将结果压入栈顶 |
| 0x75 | lneg | 将栈顶long型数值取负并将结果压入栈顶 |
| 0x76 | fneg | 将栈顶float型数值取负并将结果压入栈顶 |
| 0x77 | dneg | 将栈顶double型数值取负并将结果压入栈顶 |
| 0x78 | ishl | 将int型数值左移指定位数并将结果压入栈顶 |
| 0x79 | lshl | 将long型数值左移指定位数并将结果压入栈顶 |
| 0x7a | ishr | 将int型数值右(带符号)移指定位数并将结果压入栈顶 |
| 0x7b | lshr | 将long型数值右(带符号)移指定位数并将结果压入栈顶 |
| 0x7c | iushr | 将int型数值右(无符号)移指定位数并将结果压入栈顶 |
| 0x7d | lushr | 将long型数值右(无符号)移指定位数并将结果压入栈顶 |
| 0x7e | iand | 将栈顶两int型数值"按位与"并将结果压入栈顶 |
| 0x7f | land | 将栈顶两long型数值"按位与"并将结果压入栈顶 |
| 0x80 | ior | 将栈顶两int型数值"按位或"并将结果压入栈顶 |
| 0x81 | lor | 将栈顶两long型数值"按位或"并将结果压入栈顶 |
| 0x82 | ixor | 将栈顶两int型数值"按位异或"并将结果压入栈顶 |
| 0x83 | lxor | 将栈顶两long型数值"按位异或"并将结果压入栈顶 |
| 0x84 | iinc | 将指定int型变量增加指定值(如i++, i--, i+=2等) |
| 0x85 | i2l | 将栈顶int型数值强制转换为long型数值并将结果压入栈顶 |
| 0x86 | i2f | 将栈顶int型数值强制转换为float型数值并将结果压入栈顶 |
| 0x87 | i2d | 将栈顶int型数值强制转换为double型数值并将结果压入栈顶 |
| 0x88 | l2i | 将栈顶long型数值强制转换为int型数值并将结果压入栈顶 |
| 0x89 | l2f | 将栈顶long型数值强制转换为float型数值并将结果压入栈顶 |
| 0x8a | l2d | 将栈顶long型数值强制转换为double型数值并将结果压入栈顶 |
| 0x8b | f2i | 将栈顶float型数值强制转换为int型数值并将结果压入栈顶 |
| 0x8c | f2l | 将栈顶float型数值强制转换为long型数值并将结果压入栈顶 |
| 0x8d | f2d | 将栈顶float型数值强制转换为double型数值并将结果压入栈顶 |
| 0x8e | d2i | 将栈顶double型数值强制转换为int型数值并将结果压入栈顶 |
| 0x8f | d2l | 将栈顶double型数值强制转换为long型数值并将结果压入栈顶 |
| 0x90 | d2f | 将栈顶double型数值强制转换为float型数值并将结果压入栈顶 |
| 0x91 | i2b | 将栈顶int型数值强制转换为byte型数值并将结果压入栈顶 |
| 0x92 | i2c | 将栈顶int型数值强制转换为char型数值并将结果压入栈顶 |
| 0x93 | i2s | 将栈顶int型数值强制转换为short型数值并将结果压入栈顶 |
| 0x94 | lcmp | 比较栈顶两long型数值大小, 并将结果(1, 0或-1)压入栈顶 |
| 0x95 | fcmpl | 比较栈顶两float型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将-1压入栈顶 |
| 0x96 | fcmpg | 比较栈顶两float型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将1压入栈顶 |
| 0x97 | dcmpl | 比较栈顶两double型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将-1压入栈顶 |
| 0x98 | dcmpg | 比较栈顶两double型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将1压入栈顶 |
| 0x99 | ifeq | 当栈顶int型数值等于0时跳转 |
| 0x9a | ifne | 当栈顶int型数值不等于0时跳转 |
| 0x9b | iflt | 当栈顶int型数值小于0时跳转 |
| 0x9c | ifge | 当栈顶int型数值大于等于0时跳转 |
| 0x9d | ifgt | 当栈顶int型数值大于0时跳转 |
| 0x9e | ifle | 当栈顶int型数值小于等于0时跳转 |
| 0x9f | if_icmpeq | 比较栈顶两int型数值大小, 当结果等于0时跳转 |
| 0xa0 | if_icmpne | 比较栈顶两int型数值大小, 当结果不等于0时跳转 |
| 0xa1 | if_icmplt | 比较栈顶两int型数值大小, 当结果小于0时跳转 |
| 0xa2 | if_icmpge | 比较栈顶两int型数值大小, 当结果大于等于0时跳转 |
| 0xa3 | if_icmpgt | 比较栈顶两int型数值大小, 当结果大于0时跳转 |
| 0xa4 | if_icmple | 比较栈顶两int型数值大小, 当结果小于等于0时跳转 |
| 0xa5 | if_acmpeq | 比较栈顶两引用型数值, 当结果相等时跳转 |
| 0xa6 | if_acmpne | 比较栈顶两引用型数值, 当结果不相等时跳转 |
| 0xa7 | goto | 无条件跳转 |
| 0xa8 | jsr | 跳转至指定的16位offset位置, 并将jsr的下一条指令地址压入栈顶 |
| 0xa9 | ret | 返回至本地变量指定的index的指令位置(一般与jsr或jsr_w联合使用) |
| 0xaa | tableswitch | 用于switch条件跳转, case值连续(可变长度指令) |
| 0xab | lookupswitch | 用于switch条件跳转, case值不连续(可变长度指令) |
| 0xac | ireturn | 从当前方法返回int |
| 0xad | lreturn | 从当前方法返回long |
| 0xae | freturn | 从当前方法返回float |
| 0xaf | dreturn | 从当前方法返回double |
| 0xb0 | areturn | 从当前方法返回对象引用 |
| 0xb1 | return | 从当前方法返回void |
| 0xb2 | getstatic | 获取指定类的静态域, 并将其压入栈顶 |
| 0xb3 | putstatic | 为指定类的静态域赋值 |
| 0xb4 | getfield | 获取指定类的实例域, 并将其压入栈顶 |
| 0xb5 | putfield | 为指定类的实例域赋值 |
| 0xb6 | invokevirtual | 调用实例方法 |
| 0xb7 | invokespecial | 调用超类构建方法, 实例初始化方法, 私有方法 |
| 0xb8 | invokestatic | 调用静态方法 |
| 0xb9 | invokeinterface | 调用接口方法 |
| 0xba | invokedynamic | 调用动态方法 |
| 0xbb | new | 创建一个对象, 并将其引用引用值压入栈顶 |
| 0xbc | newarray | 创建一个指定的原始类型(如int, float, char等)的数组, 并将其引用值压入栈顶 |
| 0xbd | anewarray | 创建一个引用型(如类, 接口, 数组)的数组, 并将其引用值压入栈顶 |
| 0xbe | arraylength | 获取数组的长度值并压入栈顶 |
| 0xbf | athrow | 将栈顶的异常抛出 |
| 0xc0 | checkcast | 检验类型转换, 检验未通过将抛出 ClassCastException |
| 0xc1 | instanceof | 检验对象是否是指定类的实际, 如果是将1压入栈顶, 否则将0压入栈顶 |
| 0xc2 | monitorenter | 获得对象的锁, 用于同步方法或同步块 |
| 0xc3 | monitorexit | 释放对象的锁, 用于同步方法或同步块 |
| 0xc4 | wide | 扩展本地变量的宽度 |
| 0xc5 | multianewarray | 创建指定类型和指定维度的多维数组(执行该指令时, 操作栈中必须包含各维度的长度值), 并将其引用压入栈顶 |
| 0xc6 | ifnull | 为null时跳转 |
| 0xc7 | ifnonnull | 不为null时跳转 |
| 0xc8 | goto_w | 无条件跳转(宽索引) |
| 0xc9 | jsr_w | 跳转至指定的32位offset位置, 并将jsr_w的下一条指令地址压入栈顶 |
Java:volatile笔记的更多相关文章
- 《Java学习笔记(第8版)》学习指导
<Java学习笔记(第8版)>学习指导 目录 图书简况 学习指导 第一章 Java平台概论 第二章 从JDK到IDE 第三章 基础语法 第四章 认识对象 第五章 对象封装 第六章 继承与多 ...
- 瘋耔java语言笔记
一◐ java概述 1.1 ...
- Java系列笔记(6) - 并发(上)
目录 1,基本概念 2,volatile 3,atom 4,ThreadLocal 5,CountDownLatch和CyclicBarrier 6,信号量 7,Condition 8,Exchang ...
- Java系列笔记(5) - 线程
我想关注这个系列博客的粉丝们都应该已经发现了,我一定是个懒虫,在这里向大家道歉了.这个系列的博客是在我工作之余写的,经常几天才写一小节,不过本着宁缺毋滥的精神,所有写的东西都是比较精炼的.这篇文章是本 ...
- Java学习笔记之---基础语法
Java学习笔记之---基础语法 一. Java中的命名规范 (一)包名 由多个单词组成时,所有字母小写(例如:onetwo) (二)类名和接口 由多个单词组成时,所有单词首字母大写(例如:OneTw ...
- 0037 Java学习笔记-多线程-同步代码块、同步方法、同步锁
什么是同步 在上一篇0036 Java学习笔记-多线程-创建线程的三种方式示例代码中,实现Runnable创建多条线程,输出中的结果中会有错误,比如一张票卖了两次,有的票没卖的情况,因为线程对象被多条 ...
- 0035 Java学习笔记-注解
什么是注解 注解可以看作类的第6大要素(成员变量.构造器.方法.代码块.内部类) 注解有点像修饰符,可以修饰一些程序要素:类.接口.变量.方法.局部变量等等 注解要和对应的配套工具(APT:Annot ...
- Java学习笔记(04)
Java学习笔记(04) 如有不对或不足的地方,请给出建议,谢谢! 一.对象 面向对象的核心:找合适的对象做合适的事情 面向对象的编程思想:尽可能的用计算机语言来描述现实生活中的事物 面向对象:侧重于 ...
- 0032 Java学习笔记-类加载机制-初步
JVM虚拟机 Java虚拟机有自己完善的硬件架构(处理器.堆栈.寄存器等)和指令系统 Java虚拟机是一种能运行Java bytecode的虚拟机 JVM并非专属于Java语言,只要生成的编译文件能匹 ...
随机推荐
- Mysql常用sql语句(3)- select 查询语句基础使用
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 针对数据表里面的每条记录,select查询语句叫 ...
- Redis哨兵机制的实现及与SpringBoot的整合
1. 概述 前面我们聊过Redis的读写分离机制,这个机制有个致命的弱点,就是主节点(Master)是个单点,如果主节点宕掉,整个Redis的写操作就无法进行服务了. 为了解决这个问题,就需要依靠&q ...
- Vue项目-初始化之 vue-cli
1.初始化项目 a.Vue CLI 是一个基于 Vue.js 进行快速开发的完整系统,提供: 通过 @vue/cli 搭建交互式的项目脚手架. 通过 @vue/cli + @vue/cli-servi ...
- linux 下的shutdown指令
命令简介: 该命令可以安全关闭或者重新启动系统.你没有看错,shutdown命令不仅可以关闭系统.也可以重启Linux系统. 命令语法: /sbin/shutdown [-t sec] [-arkhn ...
- K8s一键安装
安装案例: 系统:Centos可以多台Master(Master不能低于3台)多台Node此案例使用三台Master两台Node,用户名root,密码均为123456 master 192.168.2 ...
- jmeter跑脚本的注意事项
指标主要看以下几点: 1.jmeter性能测试的报告,不要看平均响应时间,而是看90%响应时间,一般不能超过3s,超过3s则不符合标准2.响应时间超过3s就要优化,但不是平均响应时间,因为最小响应时间 ...
- 我在学习Blazor当中踩的巨坑!Blazor WebAssembly调试
最近嘛,看看Blazor已经蛮成熟的.顺便想在自家的框架里使用这个东西,毕竟我还是很念旧的,而且Blazor的技术栈也不麻烦.然后呢,在调试这一关我可是踩了大坑. 我的VS是2019,很早以前装的.然 ...
- 鸿蒙内核源码分析(调度机制篇) | 任务是如何被调度执行的 | 百篇博客分析OpenHarmony源码 | v7.07
百篇博客系列篇.本篇为: v07.xx 鸿蒙内核源码分析(调度机制篇) | 任务是如何被调度执行的 | 51.c.h .o 任务管理相关篇为: v03.xx 鸿蒙内核源码分析(时钟任务篇) | 触发调 ...
- NWERC2020J-Joint Excavation【构造,贪心】
正题 题目链接:https://codeforces.com/gym/103049/problem/J 题目大意 \(n\)个点\(m\)条边的一张无向图,选出一条路径后去掉路径上的点,然后将剩下的点 ...
- P4234-最小差值生成树【LCT】
正题 题目链接:https://www.luogu.com.cn/problem/P4234 题目大意 给出\(n\)个点\(m\)条边的一张图.求一棵生成树使得最大边权减去最小边权最小. \(1\l ...