Hadoop【Hadoop-HA搭建(HDFS、YARN)】
0.HDFS-HA的工作机制
问题:因为hdfs的中心就是namenode,而我们的集群只有一台服务器安装了nn,如果这台服务器挂掉,整个集群瘫痪,这个就是典型的单点故障,搭建HA其实就是为了解决单点故障问题
解决办法:安装多台nn
此方案有如下问题需要解决?
a)多个nn内部元数据的数据一致性的问题?
引入三台journalnode,来存储nn产生的edits文件,保证多个nn的内部数据一致性问题
b)对外提供服务问题?
多个nn不能同时对外服务,同一时刻仅仅有一个NameNode对外提供服务,当这台工作的nn挂掉以后,剩下的 备胎nn直接顶上给nn定义两个状态,active和standby
c)多个Standby的nn上位问题?
自动故障转移
d)节点状态管理功能?
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brainsplit现象的发
生。
工作机制原理图
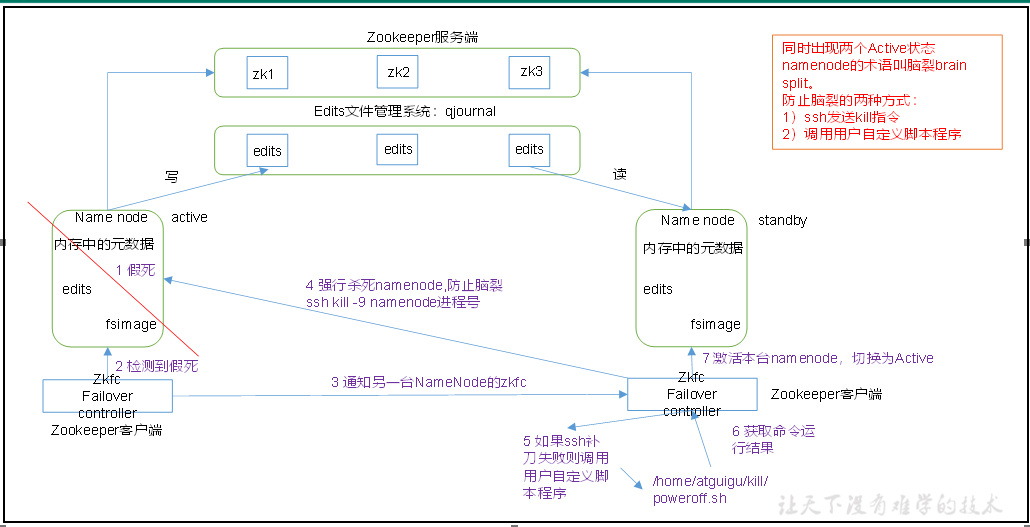
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程,如图3-20所示。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
1.故障检测
集群中的每个NameNode在ZooKeeper中维护了一个会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
2.现役NameNode选择
ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
1)健康监测
ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper会话管理
当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
3)基于ZooKeeper的选择
如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。
1. HDFS-HA集群配置
1.1 环境准备
集群搭建
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
1.2 规划集群
Zookeeper分布式本身就是高可用
-HDFS HA:namenode高可用
Yarn HA:rcemanager高可用
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | NameNode | NameNode |
| ZKFC | ZKFC | ZKFC |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |
1.3 配置Zookeeper集群
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper
2. 配置HDFS-HA集群
2.1官方地址:http://hadoop.apache.org/
2.2在opt目录下创建一个ha文件夹
sudo mkdir ha
sudo chown atguigu:atguigu /opt/ha
2.3 将/opt/module/下的 hadoop-3.1.3拷贝到/opt/ha目录下(记得删除/data 和 /logs目录)
cp -r /opt/module/hadoop-3.1.3 /opt/ha/
2.4 配置hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
2.5 配置core-site.xml
<configuration>
<!-- 把多个NameNode的地址组装成一个集群mycluster;mycluster:完全分布式集群名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/ha/hadoop-3.1.3/data</value>
</property>
</configuration>
2.6 配置hdfs-site.xml
<configuration>
<!-- NameNode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<!-- 节点名称可以自定义 -->
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop104:8020</value>
</property>
<!-- NameNode的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop103:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop104:9870</value>
</property>
<!-- 指定NameNode共享edits文件元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<!-- 访问代理类:client用于确定哪个NameNode为Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh秘钥登录,需要集群之间节点任意两台ssh免密登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/atguigu/.ssh/id_rsa</value>
</property>
</configuration>
2.7 分发配置好的hadoop环境到其他节点
[atguigu@hadoop102 hadoop-3.1.3]$ sudo xsync /opt/ha/hadoop-3.1.3
3. 启动HDFS-HA集群
1.将HADOOP_HOME环境变量更改到HA目录
sudo vim /etc/profile.d/my_env.sh
将HADOOP_HOME部分改为如下
##HADOOP_HOME
export HADOOP_HOME=/opt/ha/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
将该文件分发至各个节点
sudo xsync /etc/profile.d/my_env.sh
各个节点=source一下
source /etc/profile.d/my_env.sh
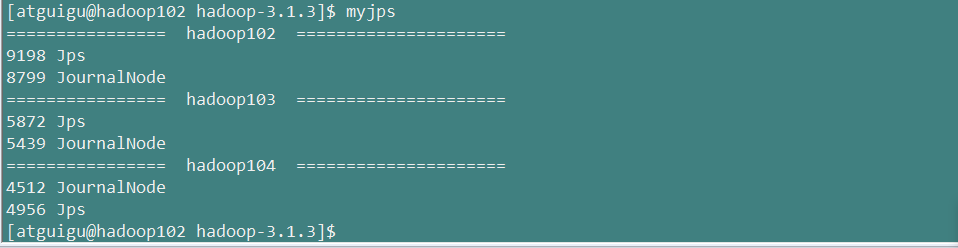
2.在各个JournalNode节点上,输入以下命令启动journalnode服务
hdfs --daemon start journalnode
查看下JournalNode进程
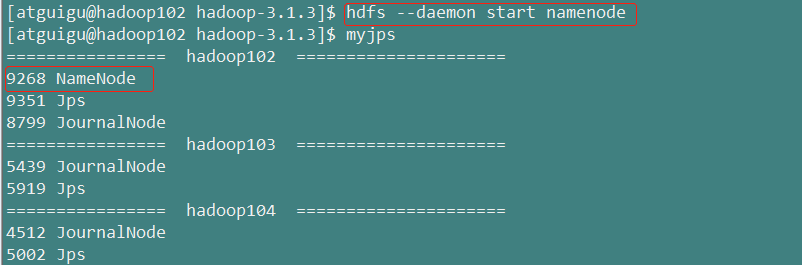
3.在【nn1】上,对其进行格式化,并启动
hdfs namenode -format
hdfs --daemon start namenode
查看【nn1】节点上的namenode进程
查看各个节点数据
[atguigu@hadoop103 hadoop-3.1.3]$ tree /opt/ha/hadoop-3.1.3/data/
【nn1】 【nn2】 【nn3】

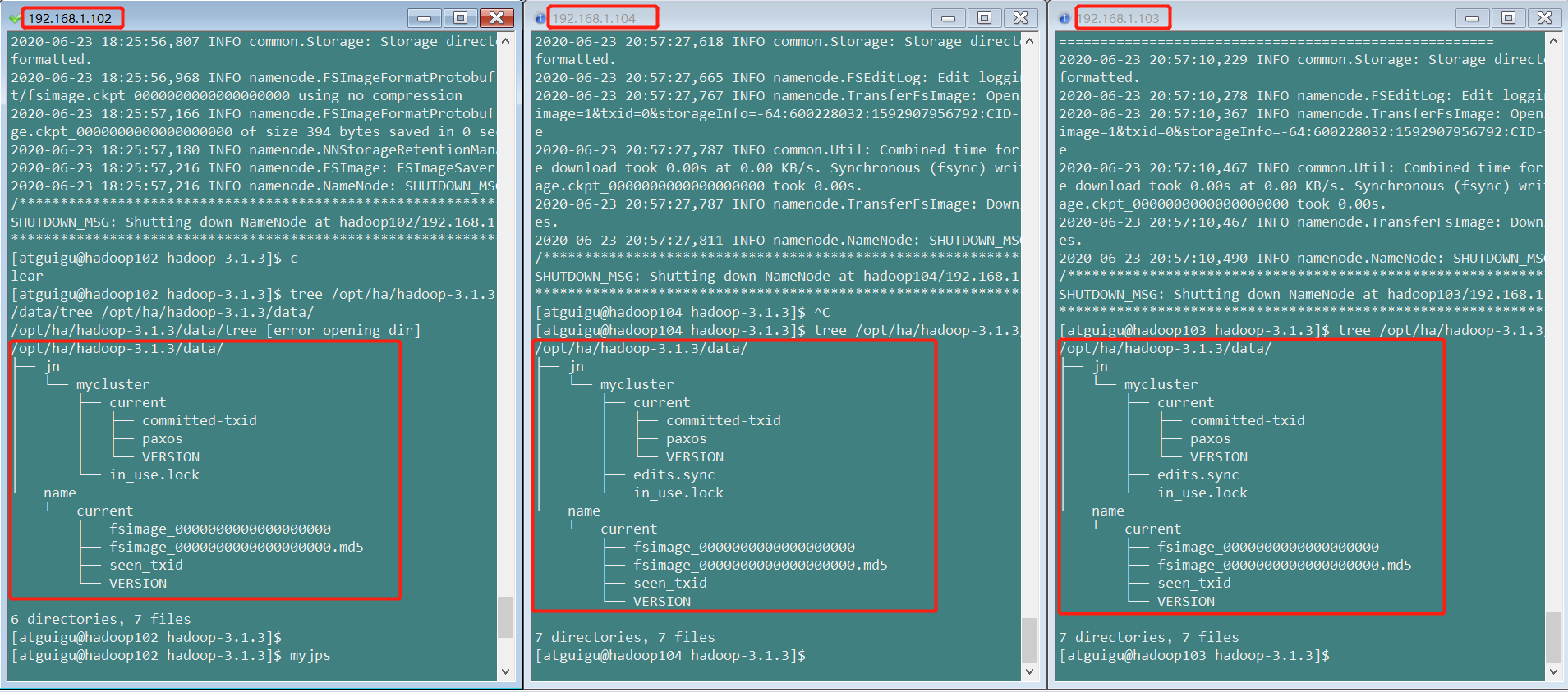
4.在【nn2】和【nn3】上,分别同步【nn1】的元数据信息
[atguigu@hadoop104 hadoop-3.1.3]$ hdfs namenode -bootstrapStandby
查看各个节点数据变化,各个节点元数据信息一致
【nn1】 【nn2】 【nn3】
5.启动【nn2】和【nn3】的namenode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode

6.查看web页面显示
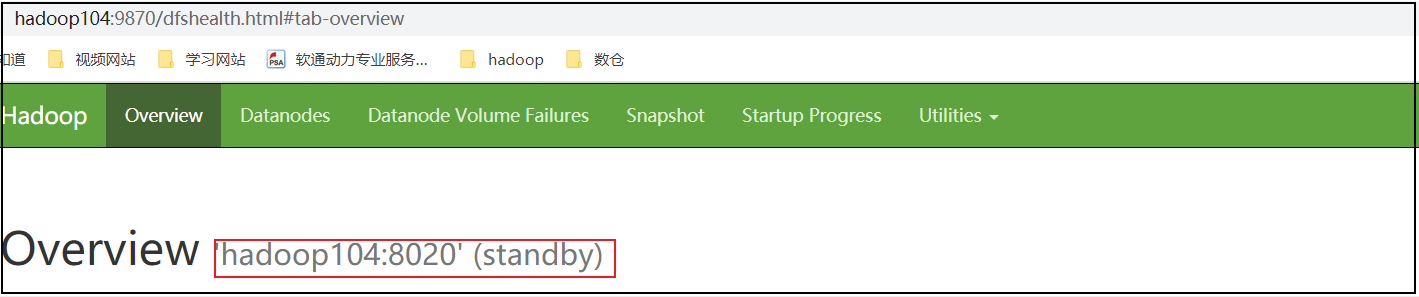
hadoop102(standby)
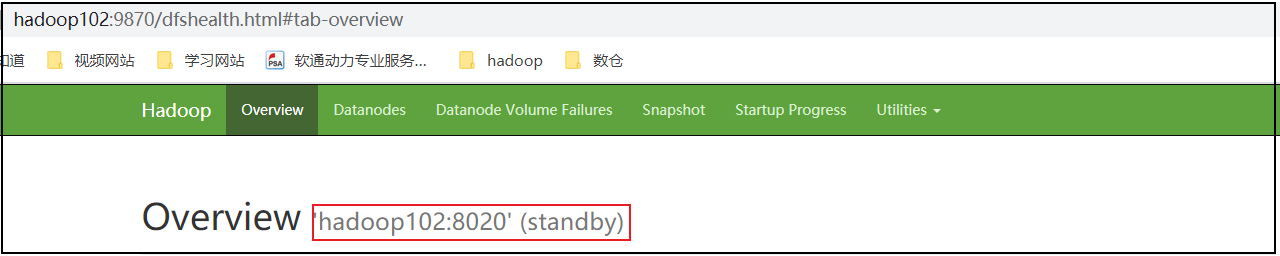
hadoop103(standby)

hadoop104(standby)
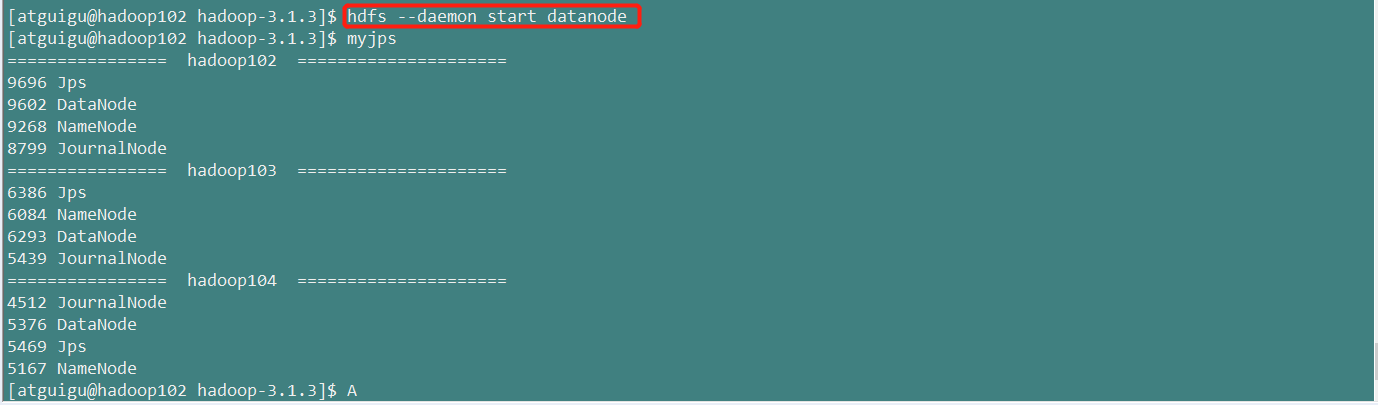
7.在所有节点上,启动datanode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs --daemon start datanode
8.手动将【nn1】切换为Active,查看是否Active
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs haadmin -transitionToActive nn1
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs haadmin -getServiceState nn1

查看【nn1】web界面

目前还不能实现故障自动转移
4.配置HDFS-HA自动故障转移
1.具体配置
(1)在hdfs-site.xml中增加
<!-- 启用nn故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)在core-site.xml文件中增加
<!-- 指定zkfc要连接的zkServer地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
(3)将hdfs-site.xml和core-site.xml分发到其他节点
[atguigu@hadoop102 hadoop-3.1.3]$ xsync etc/hadoop/
2.启动
(1)关闭所有HDFS服务:
[atguigu@hadoop102 hadoop-3.1.3]$ stop-dfs.sh

(2)启动Zookeeper集群,各个节点启动zkServer,可以用群起脚本
zkServer.sh start

(3)在【nn1】初始化HA在Zookeeper中状态:
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs zkfc -formatZK
另外开个shell窗口,启动zookeeper客户端
[atguigu@hadoop102 ~]$ zkCli.sh
zookeeper多了一个hadoop-ha/mycluster节点
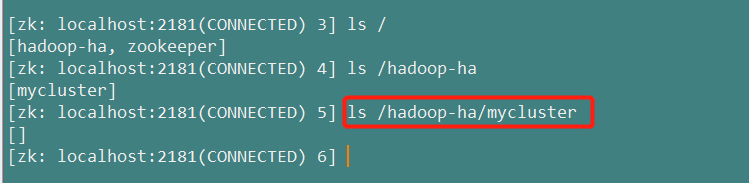
(4)启动HDFS服务:
[atguigu@hadoop102 hadoop-3.1.3]$ start-dfs.sh
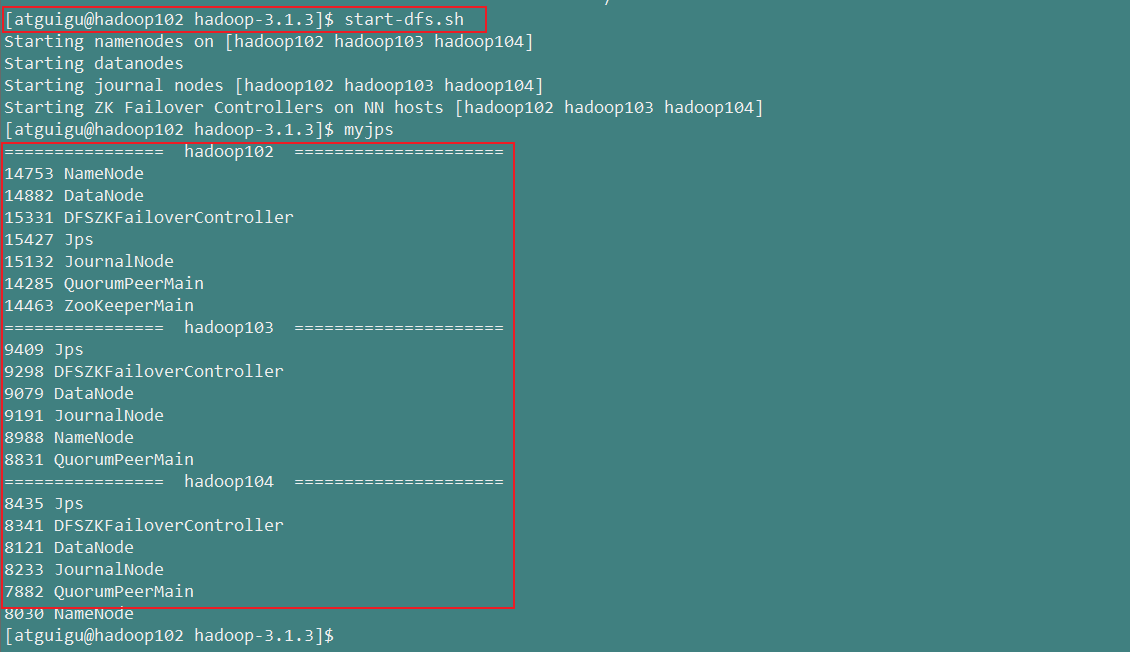
如果各个节点进程如上图所示,则证明HDFS的HA自动故障转移搭建成功

)
3.验证
(1)查看web页面
hadoop102(standby)

hadoop103(active)

hadoop104(standby)
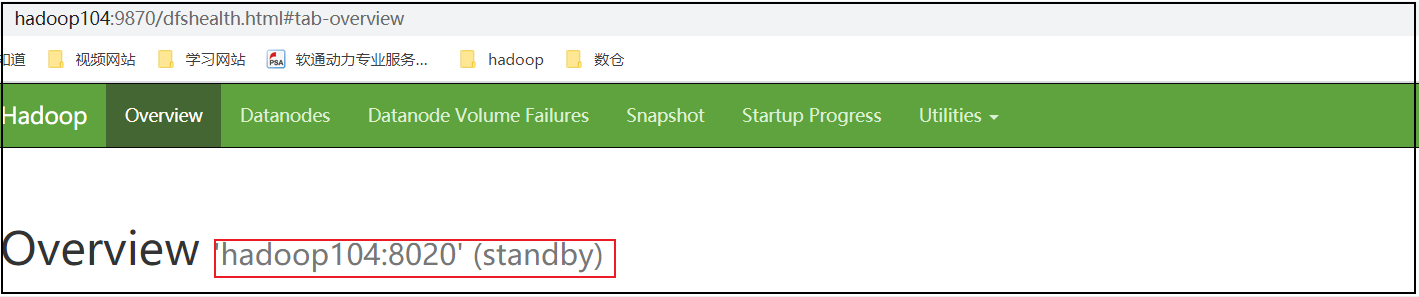
(2)在Active的节点将NameNode进程kill
[atguigu@hadoop103 hadoop-3.1.3]$ kill -9 8988
(3)查看web页面
此时hadoop102从standby状态变为active,hadoop104状态依然是standby

5. YARN-HA配置
5.1YARN-HA工作机制
1)官方文档:
http://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
2)YARN-HA工作机制
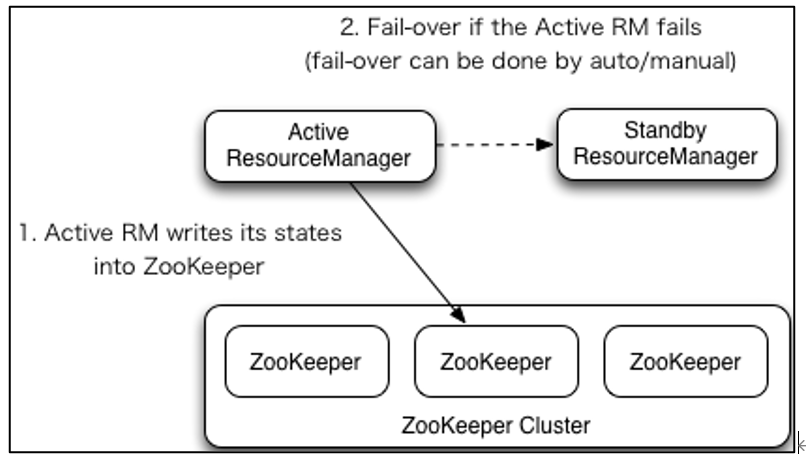
4.4.2 配置YARN-HA集群
1)环境准备
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
(6)配置Zookeeper集群
2)规划集群
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
3)具体配置
(1)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定resourcemanager的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- ========== rm1的配置 ========== -->
<!--指定rm1的主机名-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop102</value>
</property>
<!-- 指定rm1的web端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop102:8088</value>
</property>
<!-- 指定rm1的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop102:8032</value>
</property>
<!-- 指定AM向rm1申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop102:8030</value>
</property>
<!-- 指定供NM连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop102:8031</value>
</property>
<!-- ========== rm2的配置 ========== -->
<!--指定rm2的主机名-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop103:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop103:8031</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(2)同步更新其他节点的配置信息
xsync /opt/ha/hadoop-3.1.3/yarn-site.xml
4)启动hdfs
start-dfs.sh
5)启动YARN
(1)在hadoop102或者hadoop103中执行:
start-yarn.sh
(2)查看服务状态
yarn rmadmin -getServiceState rm1
(3)web端查看hadoop102:8088和hadoop103:8088的YARN的状态
注意:
yarn的web页面访问无论访问那个节点会重定向到active这个节点,不是错误
hdfs的web页面avtive,standby都可以访问;
Hadoop【Hadoop-HA搭建(HDFS、YARN)】的更多相关文章
- Hadoop(HDFS,YARN)的HA集群安装
搭建Hadoop的HDFS HA及YARN HA集群,基于2.7.1版本安装. 安装规划 角色规划 IP/机器名 安装软件 运行进程 namenode1 zdh-240 hadoop NameNode ...
- Apache hadoop namenode ha和yarn ha ---HDFS高可用性
HDFS高可用性Hadoop HDFS 的两大问题:NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用--阶段性的合并edits和fsimage,以缩短集群启动的时 ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- Hadoop 2、配置HDFS HA (高可用)
前提条件 先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改 一.安装Zookeeper 由于环境有限,所以在仅 ...
- hadoop完全分布式搭建HA(高可用)
2018年03月25日 16:25:26 D调的Stanley 阅读数:2725 标签: hadoop HAssh免密登录hdfs HA配置hadoop完全分布式搭建zookeeper 配置 更多 个 ...
- Hadoop生产环境搭建(含HA、Federation)
Hadoop生产环境搭建 1. 将安装包hadoop-2.x.x.tar.gz存放到某一目录下,并解压. 2. 修改解压后的目录中的文件夹etc/hadoop下的配置文件(若文件不存在,自己创建.) ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
随机推荐
- JAVA笔记2__类/封闭性/构造方法/方法的重载/匿名对象
public class Main { public static void main(String[] args) { Chicken c1 = new Chicken(); Chicken c2 ...
- 20191310李烨龙作业:MySort
作业:MySort 任务详情 1. 用man sort 查看sort的帮助文档 2. sort常用选项有哪些,都有什么功能?提交相关使用的截图 3. 如果让你编写sort,你怎么实现?写出伪代码和相关 ...
- Matlab 中 arburg 函数的理解与实际使用方法
1. 理解 1.1 Matlab 帮助: a = arburg(x,p)返回与输入数组x的p阶模型相对应的归一化自回归(AR)参数. 如果x是一个向量,则输出数组a是一个行向量. 如果x是矩阵,则参数 ...
- C++ 指针的引用和指向引用的指针
指向引用的指针 简单使用指针的一个例子就是: int a = 1; int *p = &a; 预先强调: 没有指向引用的指针 原因: 因为引用 不是对象,没有地址. 但是指向引用的指针是什么形 ...
- Salesforce Consumer Goods Cloud 浅谈篇一之基础介绍
本篇参考: https://baike.baidu.com/item/%E6%B6%88%E8%B4%B9%E5%93%81/425802?fr=aladdin https://help.salesf ...
- 深入理解Spring IOC源码分析
Spring容器初始化 本文使用的是Spring 5.1.7版本 写在前面:我们看源码一般有3种方式. 第一种直接用class文件,IDEA会帮我们反编译成看得懂的java代码 第二种是用maven的 ...
- vue2与vue3的差异(总结)?
vue作者尤雨溪在开发 vue3.0 的时候开发的一个基于浏览器原生 ES imports 的开发服务器(开发构建工具).那么我们先来了解一下vite Vite Vite,一个基于浏览器原生 ES i ...
- 看动画学算法之:hashtable
目录 简介 散列表的关键概念 数组和散列表 数组的问题 hash的问题 线性探测 二次探测 双倍散列 分离链接 rehash 简介 java中和hash相关并且常用的有两个类hashTable和has ...
- [loj2978]杜老师
假设所有素数从小到大依次为$p_{1},p_{2},...,p_{k}$,我们将$x$转换为一个$k$位的二进制数,其中从低到高第$i$位为1当且仅当其$p_{i}$的幂次为奇数 不难发现以下两个性质 ...
- [bzoj4777]Switch Grass
结论:最短路径一定是单独的一条边且在最小生成树上,可以用反证法证明.那么求出最小生成树,对于每一个点建立一棵权值线段树,再对每一个权值线段树上的叶子节点开一个multiset,维护所有儿子中该种颜色的 ...