Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等。并且已经安装好了hadoop集群。
如果还没有配置好的,参考我前面两篇博客:
Spark集群环境搭建——服务器环境初始化:https://www.cnblogs.com/doublexi/p/15623436.html
Spark集群环境搭建——Hadoop集群环境搭建:https://www.cnblogs.com/doublexi/p/15624246.html
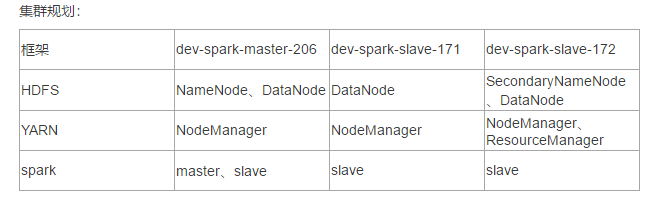
集群规划:
搭建Spark集群
1、下载:
下载地址:https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
cd /data/apps/shell/software
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz --no-check-certificate
2、解压安装:
tar xf spark-3.1.2-bin-hadoop3.2.tgz
mv spark-3.1.2-bin-hadoop3.2 /data/apps/spark-3.1.2
编辑环境变量:
vim /etc/profile
## SPARK_HOME
export SPARK_HOME=/data/apps/spark-3.1.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
加载使生效:
source /etc/profile
3、修改配置:
进入conf目录:
cd /data/apps/spark-3.1.2/conf mv spark-defaults.conf.template spark-defaults.conf
mv spark-env.sh.template spark-env.sh
mv log4j.properties.template log4j.properties
修改slaves文件,添加从机
vim slaves dev-spark-master-206
dev-spark-slave-171
dev-spark-slave-172
修改spark-defaults.conf
vim spark-defaults.conf spark.master spark://dev-spark-master-206:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
修改spark-env.sh
vim spark-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_162
export HADOOP_HOME=/data/apps/hadoop-3.2.2/
export HADOOP_CONF_DIR=/data/apps/hadoop-3.2.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/data/apps/hadoop-3.2.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=dev-spark-master-206
export SPARK_MASTER_PORT=7077
4、解决与Hadoop冲突
这里要注意,备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和 stop-all.sh 文件,如果同时加载到环境变量,会有冲突,我们选择改掉其中一个:
在输入 start-all.sh / stop-all.sh 命令时,谁的搜索路径在前面就先执行谁,此时会产生冲突。
解决方案:
- 删除一组 start-all.sh / stop-all.sh 命令,让另外一组命令生效
- 将其中一组命令重命名。如:将 $HADOOP_HOME/sbin 路径下的命令重命名为:start-all-hadoop.sh / stopall-hadoop.sh
- 将其中一个框架的 sbin 路径不放在 PATH 中
这里我们选择第二种方式,修改Hadoop的脚本文件名。
cd /data/apps/hadoop-3.2.2/sbin/
mv start-all.cmd start-all-hadoop.cmd
mv start-all.sh start-all-hadoop.sh
mv stop-all.cmd stop-all-hadoop.cmd
mv stop-all.sh stop-all-hadoop.sh
5、将spark目录分发到其他两个节点:
rsync-script spark-3.1.2/
登录其他两个从节点,添加环境变量,并加载
vim /etc/profile ## SPARK_HOME
export SPARK_HOME=/data/apps/spark-3.1.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile
6、启动集群:(standalone模式)
在master节点上:
start-all.sh
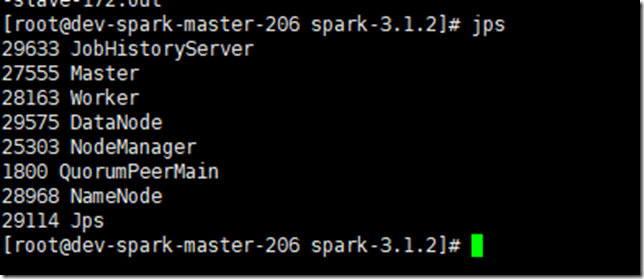
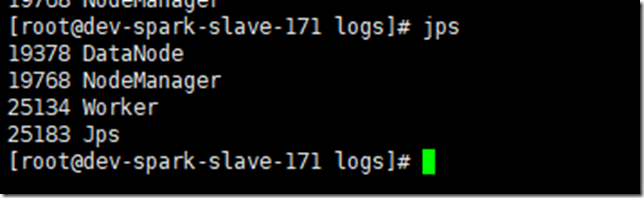
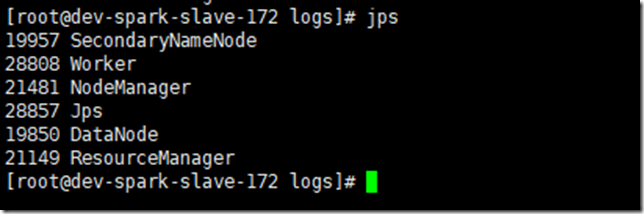
在各个节点用jps查看:
master节点是因为运行了zookeeper和kafka,所以jps多了两个进程
在web界面查看spark ui:http://192.168.90.206:8080/
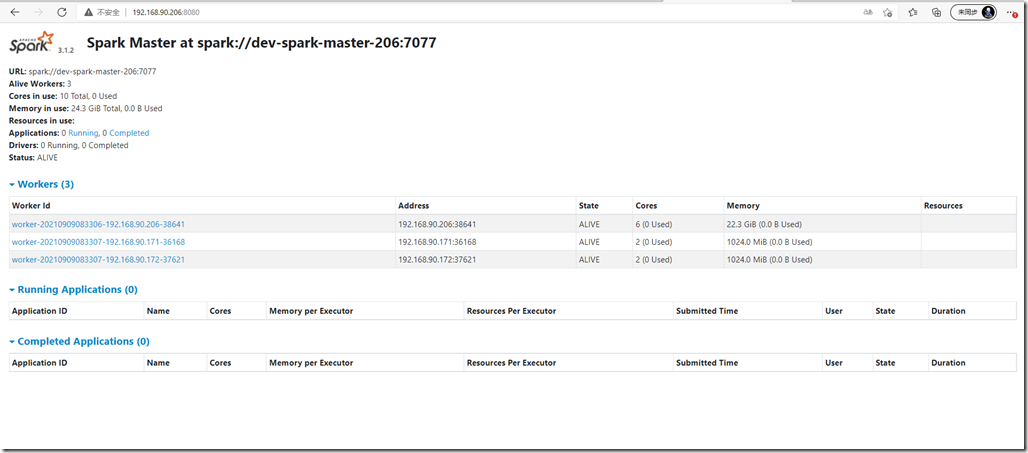
7、测试:
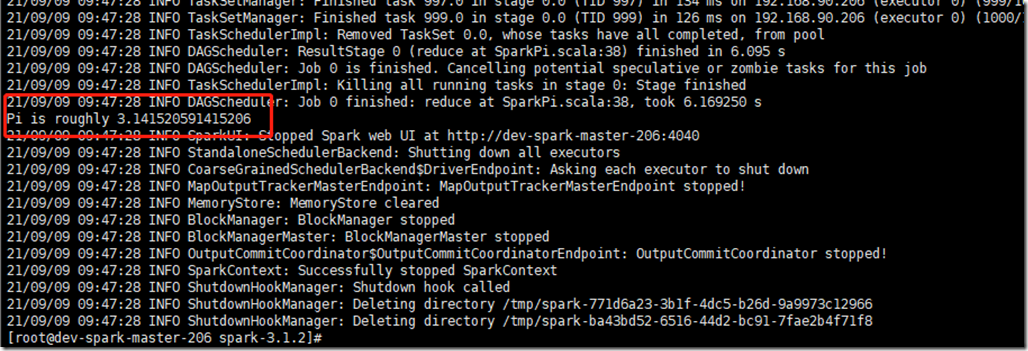
运行SparkPi案例测试:
spark-submit --class org.apache.spark.examples.SparkPi /data/apps/spark-3.1.2/examples/jars/spark-examples_2.12-3.1.2.jar 1000
最后能看到这个输出就表示OK
8、设置history
在hdfs上创建spark-eventlog目录存放历史日志:
hdfs dfs -mkdir /spark-eventlog
修改spark-default
# cd /data/apps/spark-3.1.2/conf/
# vim spark-defaults.conf spark.master spark://dev-spark-master-206:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
# 加上history server配置
spark.eventLog.enabled true
spark.eventLog.dir hdfs://dev-spark-master-206:8020/spark-eventlog
spark.eventLog.compress true
修改spark-env.sh
vim spark-env.sh export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://dev-spark-master-206:8020/spark-eventlog"
spark.history.retainedApplications。设置缓存Cache中保存的应用程序历史记录的个数(默认50),如果超过这个值,旧的将被删除;
前提条件:启动hdfs服务(日志写到HDFS)
启动historyserver,使用 jps 检查,可以看见 HistoryServer 进程。如果看见该进程,请检查对应的日志。
重启服务:
stop-all.sh
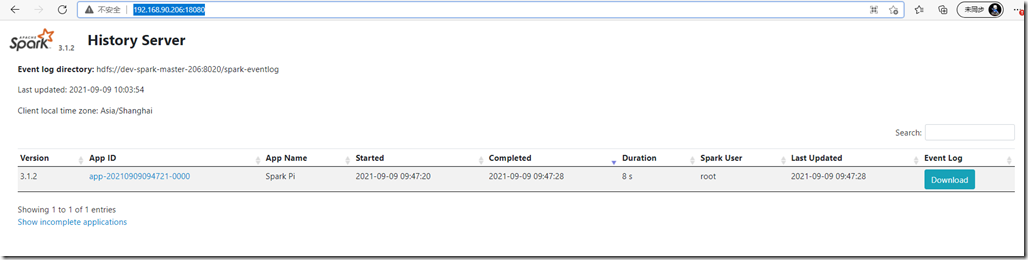
start-all.sh start-history-server.sh
web查看地址:http://192.168.90.206:18080/
集群模式--Yarn模式(可选)
上面默认是用standalone模式启动的服务,如果想要把资源调度交给yarn来做,则需要配置为yarn模式:
参考:http://spark.apache.org/docs/latest/running-on-yarn.html
需要启动的服务:hdfs服务、yarn服务
需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程),一山不容二虎!
在Yarn模式中,Spark应用程序有两种运行模式:
- yarn-client。Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
- yarn-cluster。Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
二者的主要区别:Driver在哪里
1、关闭 Standalon 模式下对应的服务;开启 hdfs、yarn、historyserver 服务
2、修改 yarn-site.xml 配置
在 $HADOOP_HOME/etc/hadoop/yarn-site.xml 中增加,分发到集群,重启 yarn 服务
# vim /data/apps/hadoop-3.2.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
备注:
yarn.nodemanager.pmem-check-enabled。是否启动一个线程检查每个任务正使用的物理内存量,如果任务
超出分配值,则直接将其杀掉,默认是true
yarn.nodemanager.vmem-check-enabled。是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务
超出分配值,则直接将其杀掉,默认是true
3、修改配置,分发到集群
# spark-env.sh 中这一项必须要有
# cd /data/apps/spark-3.1.2/conf
export HADOOP_CONF_DIR=/data/apps/hadoop-3.2.2/etc/hadoop # spark-default.conf(以下是优化)
# 与 hadoop historyserver集成
# vim spark-defaults.conf
spark.yarn.historyServer.address dev-spark-master-206:18080
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar
# 将 $SPARK_HOME/jars 下的jar包上传到hdfs
cd /data/apps/spark-3.1.2/jars
hdfs dfs -mkdir -p /spark-yarn/jars/
hdfs dfs -put * /spark-yarn/jars/
4、测试:
记得,先把Master与worker进程停掉,否则会走standalone模式
# 停掉standalone模式
stop-all.sh
client模式测试
# client
spark-submit --master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 2000
在提取App节点上可以看见:SparkSubmit、YarnCoarseGrainedExecutorBackend
在集群的其他节点上可以看见:YarnCoarseGrainedExecutorBackend
在提取App节点上可以看见:程序计算的结果(即可以看见计算返回的结果)
# cluster
spark-submit --master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 2000
在提取App节点上可以看见:SparkSubmit
在集群的其他节点上可以看见:YarnCoarseGrainedExecutorBackend、ApplicationMaster(Driver运行在此)
在提取App节点上看不见最终的结果
整合HistoryServer服务
前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;
Hadoop:JobHistoryServer
Spark:HistoryServer
修改 spark-defaults.conf,并分发到集群
# vim spark-defaults.conf
spark.master spark://dev-spark-master-206:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://dev-spark-master-206:8020/spark-eventlog
spark.eventLog.compress true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g spark.yarn.historyServer.address dev-spark-master-206:18080
spark.history.ui.port 18080
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar
发送到其他两台机器:
rsync-script spark-defaults.conf
重启/启动 spark 历史服务
stop-history-server.sh
start-history-server.sh
测试:
# client
spark-submit --master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 2000
登录yarn的地址:http://192.168.90.172:8088/
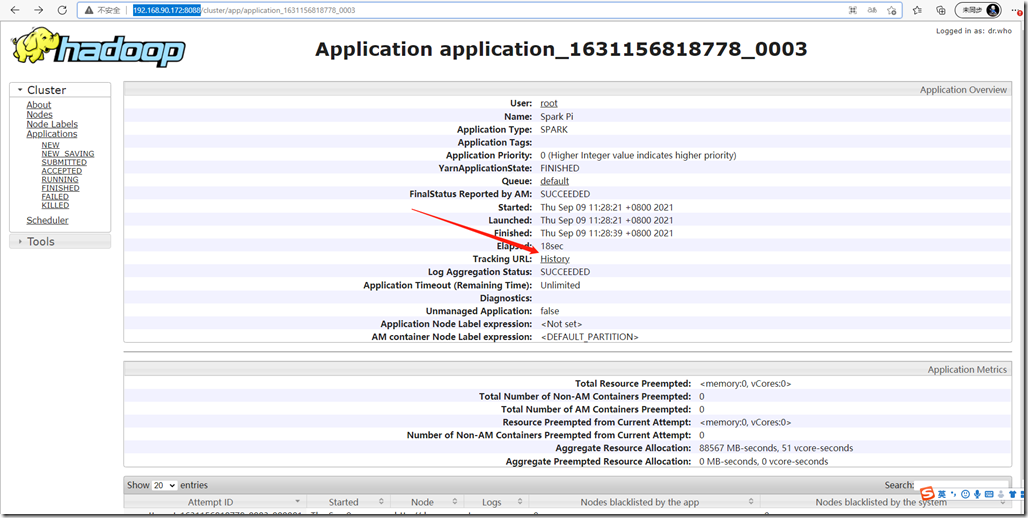
点击history会自动跳转到spark的history页面:
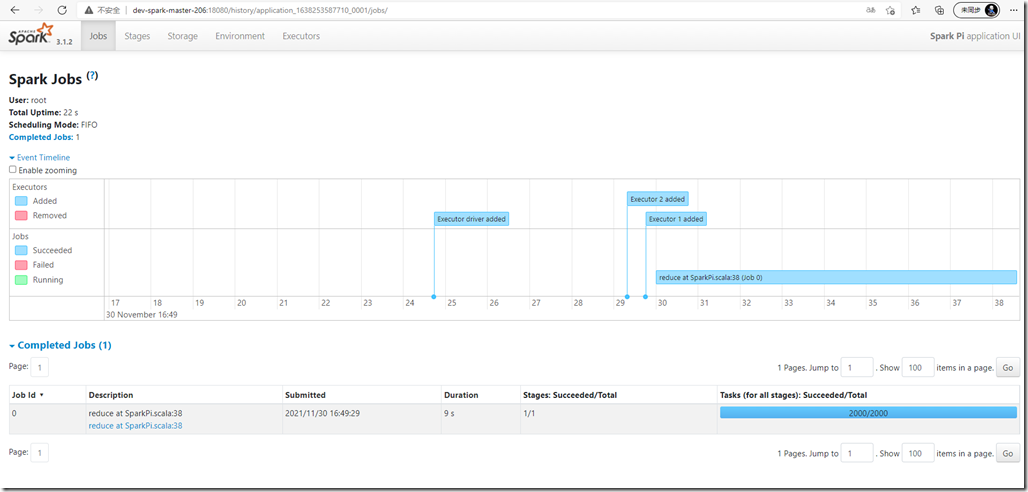
至此,spark集群搭建完成。
Spark集群环境搭建——部署Spark集群的更多相关文章
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- HBase —— 集群环境搭建
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 系列(四)—— Storm 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus ...
- ZooKeeper 介绍及集群环境搭建
本篇由鄙人学习ZooKeeper亲自整理的一些资料 包括:ZooKeeper的介绍,我们要学习ZooKeeper的话,首先就要知道他是干嘛的对吧. 其次教大家如何去安装这个精巧的智慧品! 相信你能研究 ...
- ZooKeeper 系列(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 1.2 解压 1.3 配置环境变量 1.4 修改配置 1.5 启动 1. ...
随机推荐
- ASP.NET WEBAPI 跨域请求 405错误
浏览器报错 本来没有报这个错,当我在ajax中添加了请求头信息时报错 405的报错大概就是后端程序没有允许此次请求,要解决这个问题,就是在后端程序中允许请求通过.具体操作就是修改web.config配 ...
- Relocations in generic ELF (EM: 40)
最近在搞机器上的wifi热点,需要移植一大堆东西,如hostapd\wpa_suppliant.dhcp等,这些玩意又依赖其他的一大堆库的移植,比如libnl,openssl等,今天在移植编译libn ...
- Luogu P1297 [国家集训队]单选错位 | 概率与期望
题目链接 题解: 单独考虑每一道题目对答案的贡献. 设$g_i$表示gx在第$i$道题目的答案是否正确(1表示正确,0表示不正确),则$P(g_i=1)$表示gx在第$i$道题目的答案正确的概率. 我 ...
- hdu 1028 Ignatius and the Princess III(母函数)
题意: N=a[1]+a[2]+a[3]+...+a[m]; a[i]>0,1<=m<=N; 例如: 4 = 4; 4 = 3 + 1; 4 = 2 + 2; 4 = 2 + ...
- Dataworks批量刷数优化方案探讨
Dataworks批量刷数优化方案探讨 在数据仓库的日常使用中,经常会有批量补数据,或者逻辑调整后批量重跑数据的场景. 批量刷数的实现方式,因调度工具差异而各有不同. Dataworks调度批量刷数局 ...
- ssh密码登录
https://stackoverflow.com/a/16928662/8025086 https://askubuntu.com/a/634789/861079 #!/usr/bin/expect ...
- (四)DQL查询数据(最重点)
4.1 DQL Data Query Language 数据查询语言 1 所有的查询操作都用它 Select 2 简单的查询,复杂的查询它都能做 3 数据库中最核心的语言,最重要的语 ...
- 001.AD域控简介及使用
一 AD概述 1.1 AD简介 域(Domain)是Windows网络中独立运行的单位,域之间相互访问则需要建立信任关系. 当一个域与其他域建立了信任关系后,2个域之间不但可以按需要相互进行管理,还可 ...
- Qt Creator 源码学习笔记01,初识QTC
阅读本文大概需要 4 分钟 Qt Creator 是一款开源的轻量级 IDE,整个架构代码全部使用 C++/Qt 开发而成,非常适合用来学习C++和Qt 知识,这也是我们更加深入学习Qt最好的方式,学 ...
- php 图像和水印
生成图像 $img = imagecreate(400,400); imagecolorallocate($img,255,255,255); imageellipse($img,200,200,50 ...