Hive企业级性能优化
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。
但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hive性能调优是我们大数据从业者必须掌握的技能。本文将给大家讲解Hive性能调优的一些方法及技巧。
本文首发于公众号:五分钟学大数据
Hive性能问题排查的方式
当我们发现一条SQL语句执行时间过长或者不合理时,我们就要考虑对SQL进行优化,优化首先得进行问题排查,那么我们可以通过哪些方式进行排查呢。
经常使用关系型数据库的同学可能知道关系型数据库的优化的诀窍-看执行计划。 如Oracle数据库,它有多种类型的执行计划,通过多种执行计划的配合使用,可以看到根据统计信息推演的执行计划,即Oracle推断出来的未真正运行的执行计划;还可以看到实际执行任务的执行计划;能够观察到从数据读取到最终呈现的主要过程和中间的量化数据。可以说,在Oracle开发领域,掌握合适的环节,选用不同的执行计划,SQL调优就不是一件难事。
Hive中也有执行计划,但是Hive的执行计划都是预测的,这点不像Oracle和SQL Server有真实的计划,可以看到每个阶段的处理数据、消耗的资源和处理的时间等量化数据。Hive提供的执行计划没有这些数据,这意味着虽然Hive的使用者知道整个SQL的执行逻辑,但是各阶段耗用的资源状况和整个SQL的执行瓶颈在哪里是不清楚的。
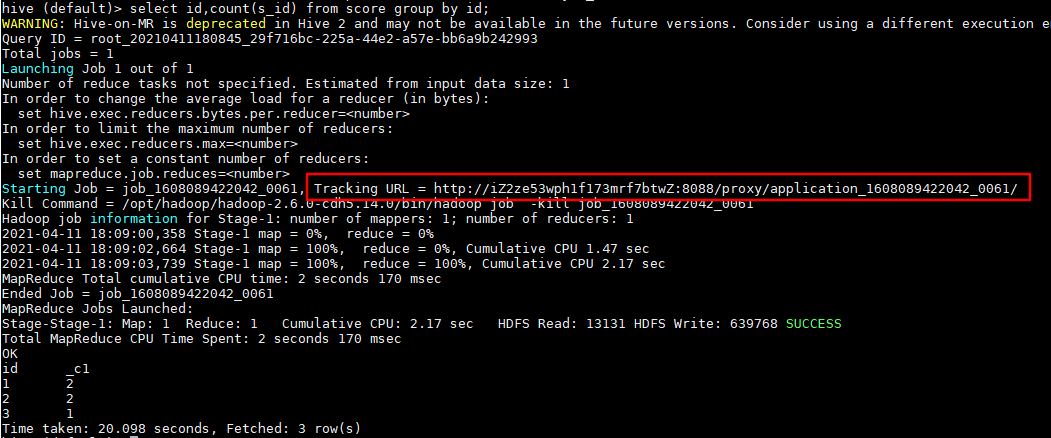
想要知道HiveSQL所有阶段的运行信息,可以查看YARN提供的日志。查看日志的链接,可以在每个作业执行后,在控制台打印的信息中找到。如下图所示:
Hive提供的执行计划目前可以查看的信息有以下几种:
- 查看执行计划的基本信息,即explain;
- 查看执行计划的扩展信息,即explain extended;
- 查看SQL数据输入依赖的信息,即explain dependency;
- 查看SQL操作相关权限的信息,即explain authorization;
- 查看SQL的向量化描述信息,即explain vectorization。
在查询语句的SQL前面加上关键字explain是查看执行计划的基本方法。 用explain打开的执行计划包含以下两部分:
- 作业的依赖关系图,即STAGE DEPENDENCIES;
- 每个作业的详细信息,即STAGE PLANS。
Hive中的explain执行计划详解可看我之前写的这篇文章:
注:使用explain查看执行计划是Hive性能调优中非常重要的一种方式,请务必掌握!
总结:Hive对SQL语句性能问题排查的方式:
- 使用explain查看执行计划;
- 查看YARN提供的日志。
Hive性能调优的方式
为什么都说性能优化这项工作是比较难的,因为一项技术的优化,必然是一项综合性的工作,它是多门技术的结合。我们如果只局限于一种技术,那么肯定做不好优化的。
下面将从多个完全不同的角度来介绍Hive优化的多样性,我们先来一起感受下。
1. SQL语句优化
SQL语句优化涉及到的内容太多,因篇幅有限,不能一一介绍到,所以就拿几个典型举例,让大家学到这种思想,以后遇到类似调优问题可以往这几个方面多思考下。
1. union all
insert into table stu partition(tp)
select s_age,max(s_birth) stat,'max' tp
from stu_ori
group by s_age
union all
insert into table stu partition(tp)
select s_age,min(s_birth) stat,'min' tp
from stu_ori
group by s_age;
我们简单分析上面的SQl语句,就是将每个年龄的最大和最小的生日获取出来放到同一张表中,union all 前后的两个语句都是对同一张表按照s_age进行分组,然后分别取最大值和最小值。对同一张表相同的字段进行两次分组,这造成了极大浪费,我们能不能改造下呢,当然是可以的,为大家介绍一个语法:
from ... insert into ... ,这个语法将from前置,作用就是使用一张表,可以进行多次插入操作:
--开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
from stu_ori
insert into table stu partition(tp)
select s_age,max(s_birth) stat,'max' tp
group by s_age
insert into table stu partition(tp)
select s_age,min(s_birth) stat,'min' tp
group by s_age;
上面的SQL就可以对stu_ori表的s_age字段分组一次而进行两次不同的插入操作。
这个例子告诉我们一定要多了解SQL语句,如果我们不知道这种语法,一定不会想到这种方式的。
2. distinct
先看一个SQL,去重计数:
select count(1)
from(
select s_age
from stu
group by s_age
) b;
这是简单统计年龄的枚举值个数,为什么不用distinct?
select count(distinct s_age)
from stu;
有人说因为在数据量特别大的情况下使用第一种方式能够有效避免Reduce端的数据倾斜,但是事实如此吗?
我们先不管数据量特别大这个问题,就当前的业务和环境下使用distinct一定会比上面那种子查询的方式效率高。原因有以下几点:
上面进行去重的字段是年龄字段,要知道年龄的枚举值是非常有限的,就算计算1岁到100岁之间的年龄,s_age的最大枚举值才是100,如果转化成MapReduce来解释的话,在Map阶段,每个Map会对s_age去重。由于s_age枚举值有限,因而每个Map得到的s_age也有限,最终得到reduce的数据量也就是map数量*s_age枚举值的个数。
distinct的命令会在内存中构建一个hashtable,查找去重的时间复杂度是O(1);group by在不同版本间变动比较大,有的版本会用构建hashtable的形式去重,有的版本会通过排序的方式, 排序最优时间复杂度无法到O(1)。另外,第一种方式(group by)去重会转化为两个任务,会消耗更多的磁盘网络I/O资源。
最新的Hive 3.0中新增了 count(distinct ) 优化,通过配置
hive.optimize.countdistinct,即使真的出现数据倾斜也可以自动优化,自动改变SQL执行的逻辑。第二种方式(distinct)比第一种方式(group by)代码简洁,表达的意思简单明了,如果没有特殊的问题,代码简洁就是优!
这个例子告诉我们,有时候我们不要过度优化,调优讲究适时调优,过早进行调优有可能做的是无用功甚至产生负效应,在调优上投入的工作成本和回报不成正比。调优需要遵循一定的原则。
2. 数据格式优化
Hive提供了多种数据存储组织格式,不同格式对程序的运行效率也会有极大的影响。
Hive提供的格式有TEXT、SequenceFile、RCFile、ORC和Parquet等。
SequenceFile是一个二进制key/value对结构的平面文件,在早期的Hadoop平台上被广泛用于MapReduce输出/输出格式,以及作为数据存储格式。
Parquet是一种列式数据存储格式,可以兼容多种计算引擎,如MapRedcue和Spark等,对多层嵌套的数据结构提供了良好的性能支持,是目前Hive生产环境中数据存储的主流选择之一。
ORC优化是对RCFile的一种优化,它提供了一种高效的方式来存储Hive数据,同时也能够提高Hive的读取、写入和处理数据的性能,能够兼容多种计算引擎。事实上,在实际的生产环境中,ORC已经成为了Hive在数据存储上的主流选择之一。
我们使用同样数据及SQL语句,只是数据存储格式不同,得到如下执行时长:
| 数据格式 | CPU时间 | 用户等待耗时 |
|---|---|---|
| TextFile | 33分 | 171秒 |
| SequenceFile | 38分 | 162秒 |
| Parquet | 2分22秒 | 50秒 |
| ORC | 1分52秒 | 56秒 |
注:CPU时间:表示运行程序所占用服务器CPU资源的时间。
用户等待耗时:记录的是用户从提交作业到返回结果期间用户等待的所有时间。
查询TextFile类型的数据表耗时33分钟, 查询ORC类型的表耗时1分52秒,时间得以极大缩短,可见不同的数据存储格式也能给HiveSQL性能带来极大的影响。
3. 小文件过多优化
小文件如果过多,对 hive 来说,在进行查询时,每个小文件都会当成一个块,启动一个Map任务来完成,而一个Map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的Map数量是受限的。
所以我们有必要对小文件过多进行优化,关于小文件过多的解决的办法,我之前专门写了一篇文章讲解,具体可查看:
4. 并行执行优化
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。
当然得是在系统资源比较空闲的时候才有优势,否则没资源,并行也起不来。
5. JVM优化
JVM重用是Hadoop调优参数的内容,其对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或task特别多的场景,这类场景大多数执行时间都很短。
Hadoop的默认配置通常是使用派生JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次。N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间,具体多少需要根据具体业务场景测试得出。
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value>
<description>How many tasks to run per jvm. If set to -1, there is
no limit.
</description>
</property>
我们也可以在hive中设置
set mapred.job.reuse.jvm.num.tasks=10; //这个设置来设置我们的jvm重用
这个功能的缺点是,开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job中有某几个reduce task执行的时间要比其他Reduce task消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
6. 推测执行优化
在分布式集群环境下,因为程序Bug(包括Hadoop本身的bug),负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
设置开启推测执行参数:Hadoop的mapred-site.xml文件中进行配置:
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks
may be executed in parallel.</description>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks
may be executed in parallel.</description>
</property>
hive本身也提供了配置项来控制reduce-side的推测执行:
set hive.mapred.reduce.tasks.speculative.execution=true
关于调优这些推测执行变量,还很难给一个具体的建议。如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的map或者Reduce task的话,那么启动推测执行造成的浪费是非常巨大大。
公众号【五分钟学大数据】,大数据领域原创技术号
最后
代码优化原则:
- 理透需求原则,这是优化的根本;
- 把握数据全链路原则,这是优化的脉络;
- 坚持代码的简洁原则,这让优化更加简单;
- 没有瓶颈时谈论优化,这是自寻烦恼。
Hive企业级性能优化的更多相关文章
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
一.本课程是怎么样的一门课程(全面介绍) 1.1.课程的背景 作为企业Hadoop应用的核心产品,Hive承载着FaceBook.淘宝等大佬 95%以上的离线统计,很多企业里的离线统 ...
- Hive常用性能优化方法实践全面总结
Apache Hive作为处理大数据量的大数据领域数据建设核心工具,数据量往往不是影响Hive执行效率的核心因素,数据倾斜.job数分配的不合理.磁盘或网络I/O过高.MapReduce配置的不合理等 ...
- 深入浅出数据仓库中SQL性能优化之Hive篇
转自:http://www.csdn.net/article/2015-01-13/2823530 一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,R ...
- Hive性能优化
1.概述 继续<那些年使用Hive踩过的坑>一文中的剩余部分,本篇博客赘述了在工作中总结Hive的常用优化手段和在工作中使用Hive出现的问题.下面开始本篇文章的优化介绍. 2.介绍 首先 ...
- Hive性能优化上的一些总结
https://blog.csdn.net/mrlevo520/article/details/76339075 1.介绍 首先,我们来看看Hadoop的计算框架特性,在此特性下会衍生哪些问题? 数据 ...
- 转:Hive性能优化之ORC索引–Row Group Index vs Bloom Filter Index
之前的文章<更高的压缩比,更好的性能–使用ORC文件格式优化Hive>中介绍了Hive的ORC文件格式,它不但有着很高的压缩比,节省存储和计算资源之外,还通过一个内置的轻量级索引,提升查询 ...
- 【SQL系列】深入浅出数据仓库中SQL性能优化之Hive篇
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[SQL系列]深入浅出数据仓库中SQL性能优化之 ...
- Hive性能优化(全面)
1.介绍 首先,我们来看看Hadoop的计算框架特性,在此特性下会衍生哪些问题? 数据量大不是问题,数据倾斜是个问题. jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 ...
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
随机推荐
- EntityFrameworkCore之工作单元的封装
1. 简介 2. DbContext 生命周期和使用规范 2.1. 生命周期 2.2. 使用规范 2.3. 避免 DbContext 线程处理问题 3. 封装-工作单元 3.1. 分析 3.2. 设计 ...
- Spring Cloud:面向应用层的云架构解决方案
Spring Cloud:面向应用层的云架构解决方案 上期文章我们介绍了混合云,以及在实际操作中我们常见的几种混合云模式.今天我们来聊一聊Spring Cloud如何解决应用层的云架构问题. 对于Sp ...
- 【10.5NOIP普及模拟】sum
[10.5NOIP普及模拟]sum 文章目录 [10.5NOIP普及模拟]sum 题目描述 输入 输出 输入输出样例 样例输入 样例输出 解析 code 题目描述 小x有很多糖果,分成了 N 堆,排成 ...
- vue篇之路由详解
一.vue路由传参的几种方式 1.声明式 router-link 父组件:<router-link :to="`/path/${id}`"><router-lin ...
- 腾讯高级工程师带你玩转打包利器webpack
随着前端领域飞速发展,webpack将前端不断出现的新模块.新资源.新需求,进行自动化整合.梳理.输出,极大提高了我们的工作效率,成为前端构建领域里最炙手可热的构建工具. 不少人webpack 的使用 ...
- SpringBoot项目war包部署
服务部署 记录原因 将本地SpringBoot项目通过war包部署到虚拟机中,验证服务器部署. 使用war包是为了方便替换配置文件等. 工具 对象 版本 Spring Boot 2.4.0 VMwar ...
- 使用VS Code从零开始开发调试.NET 5
使用VS Code 从零开始开发调试.NET 5.无需安装VS 2019即可开发调试.NET 5应用. VS Code 全称是 Visual Studio Code,Visual Studio Cod ...
- Java第三章基础学习课后题练习
小结:final 类型 变量名 = 数值 定义常量使用 变量的原则*** 一定要"先声明,后使用",变量使用前必须先声明.这点就没php好玩:两种键盘输入方式InputStream ...
- [kuangbin]专题六 最小生成树 题解+总结
kuangbin专题链接:https://vjudge.net/article/752 kuangbin专题十二 基础DP1 题解+总结:https://www.cnblogs.com/RioTian ...
- Day11_51_Collections工具类之sort方法和list集合的遍历方式
Collections工具类之sort方法 * 使用Collections工具类对List集合进行排序 Collections.sort(List集合) * Collections.sort()方法只 ...