CVPR2021提出的一些新数据集汇总
前言
在《论文创新的常见思路总结》(点击标题阅读)一文中,提到过一些新的数据集或者新方向比较容易出论文。因此纠结于选择课题方向的读者可以考虑以下几个新方向。文末附相关论文获取方式。
本文来自公众号CV技术指南的技术总结系列
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
一些新发布的数据集可以提供一个窗口,通过这些数据集可以了解试图解决的问题的复杂程度。公共领域中新发布的数据集可以很好地代表理解计算机视觉的发展以及有待解决的问题的新途径。
本文简要总结了一些CVPR 2021 上发表的数据集论文,并通读了论文以提取一些重要的细节。
1. The Multi-Temporal Urban Development SpaceNet Dataset
数据集论文:https://paperswithcode.com/paper/the-multi-temporal-urban-development-spacenet
下载地址:https://registry.opendata.aws/spacenet/


新的 SpaceNet 数据集包含每个月拍摄的建筑区域的卫星图像。目标是在空间时间序列的帮助下在全球范围内跟踪这种建筑活动。
由于其解决非常困难的全局问题的方法,这是 CVPR 中最有趣的数据集论文。该数据集试图使用卫星图像分析解决量化一个地区城市化的问题,这对于没有基础设施和财政资源来建立有效的民事登记系统的国家来说是一个巨大的帮助。
该数据集主要是关于使用在 18 到 26 个月的时间跨度内捕获的卫星图像跟踪世界各地大约 101 个地点的建筑。随着时间的推移,有超过 1100 万条注释带有单个建筑物和施工现场的独特像素级标签。
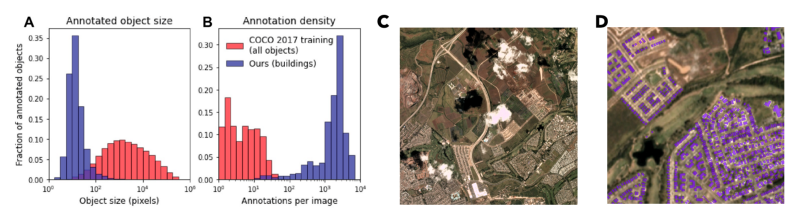
A.) 与 COCO 数据集对象相比,带注释的对象的大小非常小 B.) 在此数据集中,每张图像的标签数量太高。C.) 像云这样的遮挡(这里)会使跟踪探测变得困难。D.) Spacenet 数据集中单个图像中的带注释对象。
所有这些可能使它听起来像是一个更具挑战性的对象分割和跟踪问题。为了清楚起见,每帧大约有 30 多个对象。此外,与普通视频数据不同,由于天气、光照和地面季节性影响等原因,帧之间几乎没有一致性。这使得它比视频分类数据集(如 MOT17 和斯坦福无人机数据集)更加困难。
虽然这可能是一个难题,但解决它对于全球福利来说是值得的。
2. Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges
数据集论文:https://arxiv.org/abs/2009.03137
下载地址:https://github.com/QingyongHu/SensatUrban
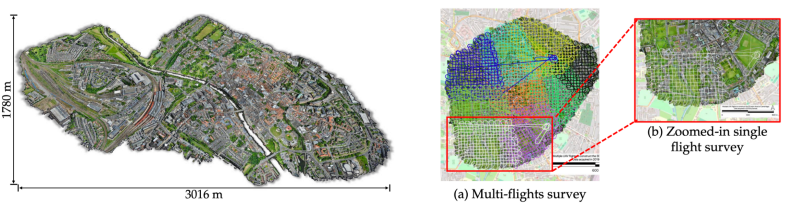
Sensat Urban 数据集的整体图,包括英国约克市的连续区域,扩展到 3 平方公里。
今年的会议重点讨论了 3D 图像处理及其相应的方法。因此,这个名为 Sensat Urban 的数据集也不足为奇,只是这个摄影测量 3D 点云数据集比迄今为止可用的任何开源数据集都要大。它覆盖超过7.6公里。涵盖约克、剑桥和伯明翰的城市景观广场。每个点云都被标记为 13 个语义类之一。
该数据集有可能推动许多有前途的领域的研究,如自动化区域测量、智慧城市和大型基础设施规划和管理。
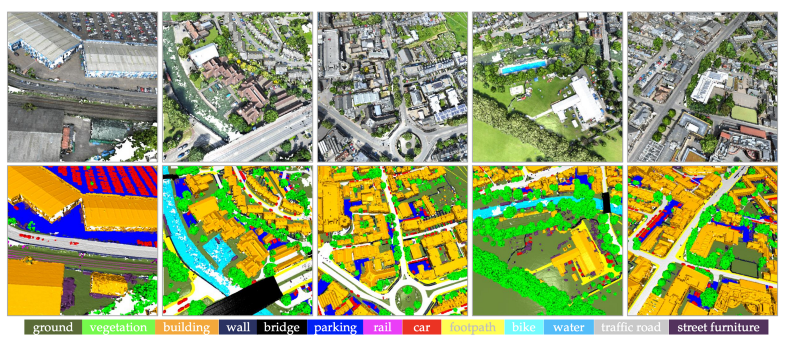
Sensat Urban 数据集中的不同分割类别。
在论文中,他们还对点云中的颜色信息进行了实验,并证明了在色彩丰富的点云上训练的神经网络能够在测试集上更好地泛化。这实际上为该领域未来应用的发展提供了重要方向。
3.Spoken Moments: Learning Joint Audio-Visual Representations from Video Descriptions
数据集论文:https://arxiv.org/abs/2105.04489
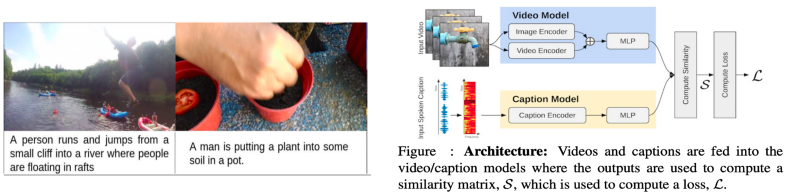
来自 MIT 音频字幕数据集的一些样本 [左] 在数据集中结合视听信息的提议架构 [右]
这是今年另一个最受欢迎的数据集,因为它对图像字幕和视频摘要问题采用了略有不同的方法。通常,对于此类任务,我们有像 COCO 这样的数据集,其中包含图像及其随附的文本标题。虽然这种方法已被证明是有前途的,但我们经常忘记,在口语方面对我们的视觉体验进行了很多丰富的总结。
该数据集构建了一个包含 50 万个描述各种不同事件的短视频音频描述的语料库。然而,他们并没有止步于展示一个很棒的数据集,他们还提供了一个优雅的解决方案来使用自适应平均边距(AMM)方法来解决视频/字幕检索问题。
4.Conceptual 12M : Pushing Web-Scale Image-Text Pre-training to recognise Long-Tail visual concepts
数据集论文:https://arxiv.org/abs/2102.08981

来自Conceptual 12M 数据集的一些图像标题对。虽然 alt-text 本身的信息量并不大,但它对于学习视觉概念的更广义的文本表示非常有帮助。
最近,由于预训练transformer和 CNN 架构的性能提升,模型预训练获得了极大的欢迎。通常,我们希望在一个类似的数据集上训练模型。然后使用迁移学习在下游任务上利用模型。
到目前为止,唯一可用的用于预训练的大规模数据集是用于视觉+语言任务的 CC-3M 数据集,有 300 万个字幕。现在,谷歌研究团队通过放宽数据抓取的限制,将该数据集扩展到 1200 万个图像字幕对--Conceptual 12M。
更有趣的是生成数据集的方法。在数据集管理期间使用 Google Cloud Natural Language API 和 Google Cloud Vision API 过滤任务对于任何未来的数据集管理任务来说都是一个很好的教训。
使用 12M 数据集,图像字幕模型能够学习长尾概念,即数据集中非常具体且罕见的概念。训练方法的结果令人印象深刻,并在下面进行了可视化。

在概念 12M 数据集上预训练的神经图像标题模型的预测示例很少。
5. Euro-PVI:密集城市中心的行人车辆交互
数据集论文:
https://openaccess.thecvf.com/content/CVPR2021/supplemental/Bhattacharyya_Euro-PVI_Pedestrian_Vehicle_CVPR_2021_supplemental.pdf

实时车辆-行人行为示例。预测行人将采取什么样的轨迹来响应接近的车辆对于构建全自动自动驾驶汽车至关重要。
虽然有很多关于完全自主的自动驾驶系统的讨论,但事实仍然是,它是一个非常困难的问题,需要同时实时解决多个问题。关键部分之一是使这些自主系统了解行人对其存在的反应,在密集环境中预测行人轨迹是一项具有挑战性的任务。
因此,Euro-PVI 数据集旨在通过在行人和骑自行车者轨迹的标记数据集上训练模型来解决这个问题。早些时候,斯坦福无人机、nuScenes 和 Lyft L5 等数据集专注于附近车辆的轨迹,但这只是自主系统完整画面的一部分。
Euro-PVI通过交互时的视觉场景、交互过程中的速度和加速度以及整个交互过程中的整体坐标轨迹等信息,提供了一个全面的交互图。
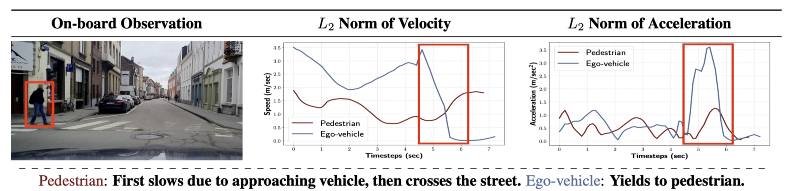
Euro-PVI 数据集包含有关行人车辆交互的丰富信息,例如场景中所有参与者的视觉场景、速度和加速度。
所有这些信息都必须由经过训练的模型映射到相关的潜在空间。为了解决潜在空间中轨迹和视觉信息的联合表示问题,同一篇论文还提出了 Joint-B-VAE 的生成架构,这是一种经过训练的变分自动编码器,用于对参与者的轨迹进行编码并将其解码为未来的合成轨迹。
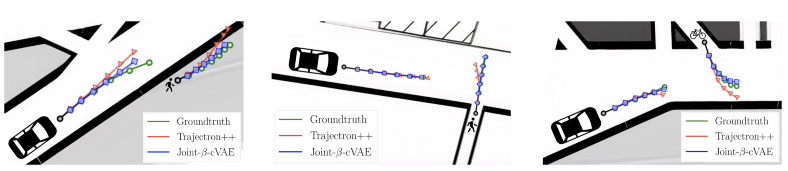
ground truth,Trajectron++ 预测的轨迹和联合 B-VAE 的预测轨迹(在同一数据集论文中提出)
在公众号CV技术指南中回复关键字 “ 0010 ” 可获取以上论文。
作者:Shwetank Panwar
编译:CV技术指南
原文链接:
https://medium.com/@shwetank.ml/datasets-cvpr-2021-problems-that-shouldnt-be-missed-6128d07c59c3
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结”可获取公众号原创技术总结文章的汇总pdf。

其它文章
视频理解综述:动作识别、时序动作定位、视频Embedding
资源分享 | SAHI:超大图片中对小目标检测的切片辅助超推理库
使用 Ray 将 PyTorch 模型加载速度提高 340 倍
CVPR2021提出的一些新数据集汇总的更多相关文章
- 【转】Spark-Sql版本升级对应的新特性汇总
Spark-Sql版本升级对应的新特性汇总 SparkSQL的前身是Shark.由于Shark自身的不完善,2014年6月1日Reynold Xin宣布:停止对Shark的开发.SparkSQL抛弃原 ...
- iOS8 针对开发者所拥有的新特性汇总如下
iOS8 针对开发者所拥有的新特性汇总如下 1.支持第三方键盘 2.自带网页翻译功能(即在线翻译) 3.指纹识别功能开放:第三方软件可以调用 4.Safari浏览器可直接添加新的插件. 5.可以把一个 ...
- 21、前端知识点--html5和css3新特性汇总
跳转到该链接 新特性汇总版: https://www.cnblogs.com/donve/p/10697745.html HTML5和CSS3的新特性(浓缩好记版) https://blog.csdn ...
- CVPR 2022数据集汇总|包含目标检测、多模态等方向
前言 本文收集汇总了目前CVPR 2022已放出的一些数据集资源. 转载自极市平台 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘信息. M5Produc ...
- ES 2015/6 新特性汇总
ES 2015/6 新特性汇总 箭头函数 箭头函数,通过 => 语法实现的函数简写形式,C#/JAVA8/CoffeeScript 中都有类似语法.与函数不同,箭头函数与其执行下文环境共享同一个 ...
- Android恶意样本数据集汇总
硕士论文的研究方向为Android恶意应用分类,因此花了一点时间去搜集Android恶意样本.其中一部分来自过去论文的公开数据集,一部分来自社区或平台的样本.现做一个汇总,标明了样本或数据集的采集时间 ...
- 【ES】338- ECMAScirpt 2019 新特性汇总
点击上方"前端自习课"关注,学习起来~ 最近在做的一个活动,大家都可以参与: 送 1600 元超大现金红包啦,走过路过不要错过哦 ~ 最近 ECMAScript2019,最新提案完 ...
- iOS7向开发者开放的新功能汇总
转自:http://www.25pp.com/news/news_28002.html iOS7才放出第二个测试版本,我们已经看到了不少的新功能和新改变.最近,科技博客9to5Mac将iOS7中向开发 ...
- Swift3新特性汇总
之前 Apple 在 WWDC 上已将 Swift 3 整合进了 Xcode 8 beta 中,而本月苹果发布了 Swift 3 的正式版.这也是自 2015 年底Apple开源Swift之后,首个发 ...
随机推荐
- Layui form表单提交注意事项
// 表单提交form.on('submit(first1)', function (data) { var articleFrom = data.field; $.ajax({ type:" ...
- 解决移动端click事件300ms延迟的问题
方法1.部分浏览器的<meta>标签加上width=device-width就能解决. 方法2.引入fastclick.js库 <!DOCTYPE html> <html ...
- 三大操作系统对比使用之·MacOSX
时间:2018-11-13 整理:byzqy 本篇是一篇个人对Mac系统使用习惯和应用推荐的分享,在此记录,以便后续使用查询! 打开终端: command+空格,调出"聚焦搜索(Spotli ...
- TDSQL-A与CK的对比
CK介绍 CK是目前社区里面比较热门的,应用场景也比较广泛. 首先,在架构上,集群内划分为多个分片,通过分片的线性扩展能力,支持海量数据的分布式存储计算,每个分片内包含一定数量的节点Node,即进程, ...
- adb shell 查看当前与用户交互的 activity
adb shell dumpsys activity activities | grep mActivityComponent
- RabbitMQ-进阶
目录 过期时间TTL 设置队列TTL 消息确认机制的配置 死信队列 内存磁盘的监控 RabbitMQ的内存控制 命令的方式 配置文件方式 rabbitmq.conf RabbitMQ的内存换页 Rab ...
- SAR总结
1.星载InSAR技术简介 星载合成孔径雷达干涉测量(InSAR)是一种用于大地测量和遥感的雷达技术.InSAR使用两个或多个SAR图像,利用返回卫星的波的相位差来计算目标地区的地形.地貌以及表面的微 ...
- Sentry Web 性能监控 - Metrics
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- 通过JDK动态代理实现 Spring AOP
1.新建一个目标类 接口:public interface IUserService //切面编程 public void addUser(); public void updateUser( ); ...
- Intel® QAT加速卡之编程demo框架
QAT demo流程框架 示例一: 代码路径:qat1.5.l.1.13.0-19\quickassist\lookaside\access_layer\src\sample_code\functio ...