第15章: Prometheus监控Kubernetes资源与应用
Prometheus监控Kubernetes资源与应用
目录
1 监控方案
老的监控系统无法感知这些动态创建的服务,已经不适合容器化的场景
|
cAdvisor+Heapster+InfluxDB+Grafana |
Y |
简单 |
容器监控 |
|
cAdvisor/exporter+Prometheus+Grafana |
Y |
扩展性好 |
容器,应用,主机全方面监控 |
对于非容器化业务来说,像Zabbix,open-falcon已经在企业深入使用。
而Prometheus新型的监控系统的兴起来源容器领域,所以重点是放在怎么监控容器。
随着容器化大势所趋,如果传统技术不随着改变,将会被淘汰,基础架构也会发生新的技术栈组合。
cAdvisor+InfluxDB+Grafana
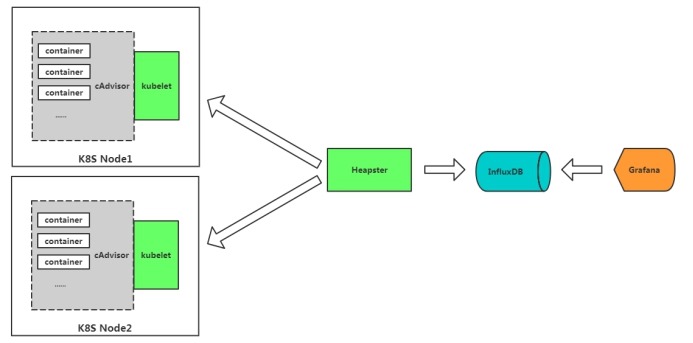
cAdvisor:是谷歌开源的一个容器监控工具,采集主机上容器相关的性能指标数据。比如CPU、内存、网络、文件系统等。
Heapster是谷歌开源的集群监控数据收集工具,会收集所有节点监控数据,Heapster作为一个pod在集群中运行,通过API获得集群中的所有节点,然后从节点kubelet暴露的10255汇总数据。目前社区用Metrics Server 取代 Heapster。
InfluxDB:时序数据库,存储监控数据。
Grafana:可视化展示。Grafana提供一个易于配置的仪表盘UI,可以轻松定制和扩展。
不足
l 功能单一,无法做到对K8S资源对象监控
l 告警单一,利用Grafana基本告警
l 依赖Influxdb,而Influxdb单点(高可用商业才支持),缺少开源精神
l heapster在1.8+弃用,metrics-server取代
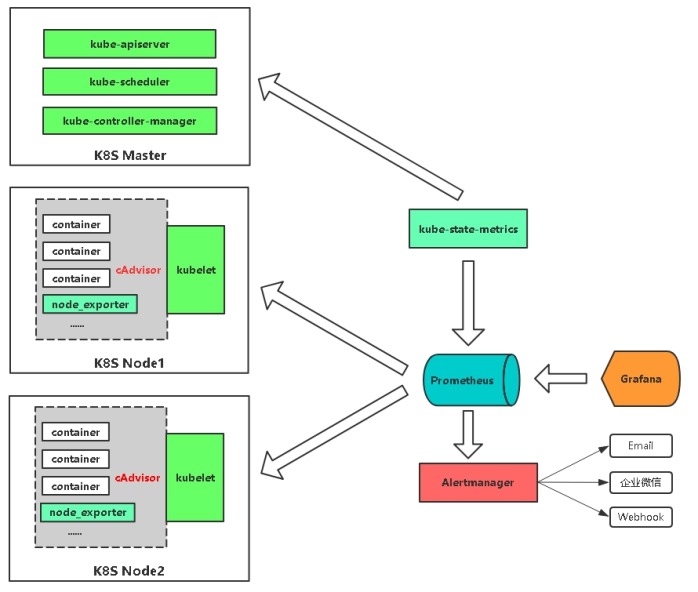
cAdvisor/exporter+Prometheus+Grafana
Prometheus+Grafana是监控告警解决方案里的后起之秀
通过各种exporter采集不同维度的监控指标,并通过Prometheus支持的数据格式暴露出来,Prometheus定期pull数据并用Grafana展示,异常情况使用AlertManager告警。
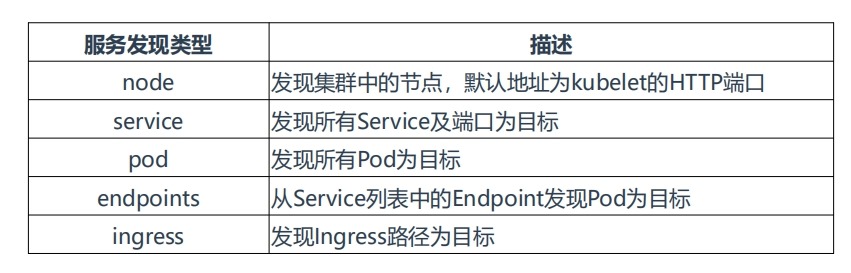
# Kubernetes的API
SERVER会暴露API服务,Promethues集成了对Kubernetes的自动发现,它有# 5种模式:Node、Service、Pod、Endpoints、ingress。
n 通过cadvisor采集容器、Pod相关的性能指标数据,并通过暴露的/metrics接口用prometheus抓取
n 通过prometheus-node-exporter采集主机的性能指标数据,并通过暴露的/metrics接口用prometheus抓取
n 应用侧自己采集容器中进程主动暴露的指标数据(暴露指标的功能由应用自己实现,并添加平台侧约定的annotation,平台侧负责根据annotation实现通过Prometheus的抓取)
n 通过kube-state-metrics采集k8s资源对象的状态指标数据,并通过暴露的/metrics接口用prometheus抓取
n 通过etcd、kubelet、kube-apiserver、kube-controller-manager、kube-scheduler自身暴露的/metrics获取节点上与k8s集群相关的一些特征指标数据。
2 监控指标
Kubernetes本身监控
• Node资源利用率
• Node数量
• Pods数量(Node)
• 资源对象状态
Pod监控
• Pod数量(项目)
• 容器资源利用率
• 应用程序
3 实现思路
|
监控指标 |
具体实现 |
举例 |
|
Pod性能(k8s集群资源监控) |
cAdvisor |
容器CPU,内存利用率 |
|
Node性能(k8s工作节点监控) |
node-exporter |
节点CPU,内存利用率 |
|
K8S资源对象(k8s资源对象状态监控) |
kube-state-metrics |
Pod/Deployment/Service |
4 在K8S中部署Prometheus
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
源码目录:kubernetes/cluster/addons/prometheus
5 在K8S中部署Grafana与可视化
grafana 是一个可视化面板,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持
Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus
自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
https://grafana.com/grafana/download
推荐模板:
• 集群资源监控:3119
• 资源状态监控 :6417
• Node监控 :9276
6 监控K8S集群Node与Pod
(1) Node
Prometheus社区提供的NodeExporter项目可以对主机的关键度量指标进行监控,通过Kubernetes的DeamonSet可以在各个主机节点上部署有且仅有一个NodeExporter实例,实现对主机性能指标数据的监控,但由于容器隔离原因,使用容器NodeExporter并不能正确获取到宿主机磁盘信息,故将NodeExporter部署到宿主机。
使用文档:https://prometheus.io/docs/guides/node-exporter/
GitHub: https://github.com/prometheus/node_exporter
exporter列表:https://prometheus.io/docs/instrumenting/exporters/
node-exporter所采集的指标主要有:
node_cpu_*
node_disk_*
node_entropy_*
node_filefd_*
node_filesystem_*
node_forks_*
node_intr_total_*
node_ipvs_*
node_load_*
node_memory_*
node_netstat_*
node_network_*
node_nf_conntrack_*
node_scrape_*
node_sockstat_*
node_time_seconds_*
node_timex _*
node_xfs_*
(2) pod
目前cAdvisor集成到了kubelet组件内,可以在kubernetes集群中每个启动了kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有容器相关的性能指标数据。
暴露API接口地址:https://NodeIP:10250/metrics/cadvisor
7 监控K8S资源对象
https://github.com/kubernetes/kube-state-metrics
kube-state-metrics是一个简单的服务,它监听Kubernetes
API服务器并生成有关对象状态的指标。它不关注单个Kubernetes组件的运行状况,而是关注内部各种对象的运行状况,例如部署,节点和容器。
kube-state-metrics采集了k8s中各种资源对象的状态信息:
kube_daemonset_*
kube_deployment_*
kube_job_*
kube_namespace_*
kube_node_*
kube_persistentvolumeclaim_*
kube_pod_container_*
kube_pod_*
kube_replicaset_*
kube_service_*
kube_statefulset_*
8 在K8S中部署Alertmanager
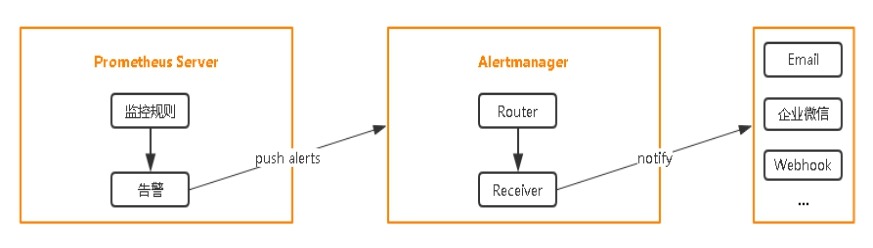
设置告警和通知的主要步骤如下:
1. 部署Alertmanager
2. 配置Prometheus与Alertmanager通信
3. 配置告警
1. prometheus指定rules目录
2. configmap存储告警规则
3. configmap挂载到容器rules目录
4. 增加alertmanager告警配置
9 Prometheus告警
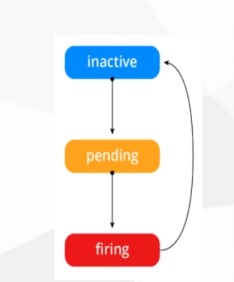
(1)
Prometheus告警状态
Inactive: 这里什么都没有发生。
Pending: 已触发阈值,但未满足告警持续时间
Firing: 已触发阈值且满足告警持续时间。警报发送给接受者。
(2)
告警收敛
分组(group): 将类似性质的警报分类为单个通知
抑制(Inhibition): 当警报发出后,停止重复发送由此警报引发的其他警报
静默(Silences): 是一种简单的特定时间静音提醒的机制
(3)
Prometheus发告警流程

默认大约4分钟能收到报警(prometheus收集间隔1m,prometheus评估1m,报警等待1m,报警分组1m),重复发送大约2分钟(报警分组1m,重复报警间隔1m)。
10 实验
|
主机名 |
ip |
用途 |
备注 |
|
k8s_nfs |
172.16.1.60 |
nfs存储 |
存储目录/ifs/kubernetes/ |
|
k8s-admin |
172.16.1.70 |
k8s主节点 |
|
|
k8s-node1 |
172.16.1.71 |
k8s从节点1 |
|
|
k8s-node2 |
172.16.1.72 |
k8s从节点2 |
# 创建名称为ops的命名空间
[root@k8s-admin prometheus]# kubectl create namespace
ops
namespace/ops created
(1)
安装managed-nfs-storage
这里省略安装步骤,可以参考之前的文章完成安装。
[root@k8s-admin nfs-client]# kubectl get
deploy,svc,pod,sc -o wide

(2) 部署prometheus
1) yaml文件说明
[root@k8s-admin prometheus]# ls -l
prometheus-*
-rw-r--r-- 1 root root 4965 Jul 24 2020
prometheus-configmap.yaml
# prometheus的主配置文件,采用ConfigMap方式挂载卷,通过kubernetes_sd_configs配置连接
# api-server自动发现被监控项。配置了连接alertmanager的参数。
[root@k8s-admin prometheus]# cat
prometheus-configmap.yaml | grep job_name
- job_name:
prometheus
- job_name:
kubernetes-apiservers
- job_name:
kubernetes-nodes-kubelet
- job_name:
kubernetes-nodes-cadvisor
- job_name:
kubernetes-service-endpoints
- job_name:
kubernetes-services
- job_name:
kubernetes-pods
-rw-r--r-- 1 root root 1064 Jul 24 2020
prometheus-rbac.yaml
# prometheus的权限,ServiceAccount方式,名称prometheus
-rw-r--r-- 1 root root 4840 Jul 24 2020
prometheus-rules.yaml
# prometheus的告警规则,采用ConfigMap方式挂载卷
-rw-r--r-- 1 root root 384 Jul 24 2020
prometheus-service.yaml
# prometheus的SVC,NodePort方式暴露30090端口
-rw-r--r-- 1 root root 3253 Jul 24 2020
prometheus-statefulset.yaml
# 部署prometheus的配置文件,采用statefulset方式部署prometheus。
# 配置serviceAccountName:
prometheus为rbac配置用于连接api-server。
# 将/data目录挂载到nfs动态pvc卷prometheus-data
2) 应用yaml文件
[root@k8s-admin prometheus]# ls prometheus-* | xargs
-i kubectl apply -f {}
configmap/prometheus-config
created
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus
created
clusterrolebinding.rbac.authorization.k8s.io/prometheus
created
configmap/prometheus-rules created
service/prometheus created
statefulset.apps/prometheus
created
3) 查看部署信息
[root@k8s-admin prometheus]# kubectl get
statefulset,pod,svc,configmap,ServiceAccount,pvc,pv -n ops -o
wide
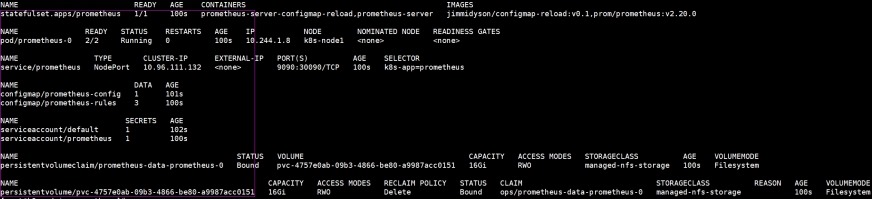
补充:如何获取serviceaccount
# 获取serviceaccount在secrets中的名称
[root@k8s-admin prometheus]# kubectl get
serviceaccount prometheus -n ops -o yaml
……
secrets:
- name: prometheus-token-zljjr
# 根据secrets的名称获取token
[root@k8s-admin prometheus]# kubectl describe secret
prometheus-token-zljjr -n ops > /root/token.k8s
# 只保留token.k8s文件最下面的token字符串,其余的全部删除掉。
4) 访问prometheus
http://172.16.1.71:30090/targets
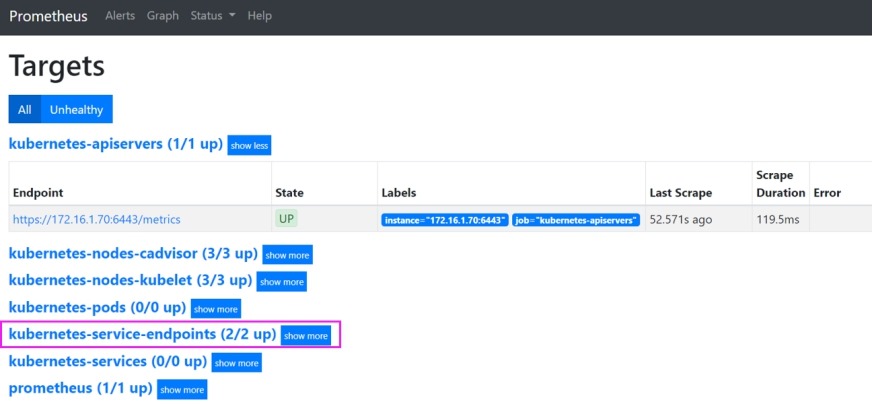
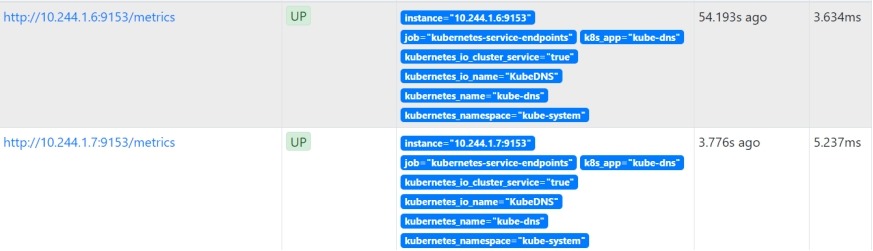
[root@k8s-admin prometheus]# kubectl get svc -n
kube-system

[root@k8s-admin prometheus]# kubectl get ep/kube-dns
-n kube-system

[root@k8s-admin prometheus]# kubectl get svc -n
kube-system -o yaml | head -10
(3)
node节点利用率监控
在node节点上部署exporter导出器
1) 配置文件说明
[root@k8s-admin prometheus]# ls -l
node-exporter-*
-rw-r--r-- 1 root root 1633 Jul 25 2020
node-exporter-ds.yml
# node导出器部署文件,采用DaemonSet方式部署,临时文件存储采用hostPath方式
-rw-r--r-- 1 root root 417 Jul 24 2020
node-exporter-service.yaml
# node导出器svc配置文件,clusterIP为None,暴露内部端口为9100
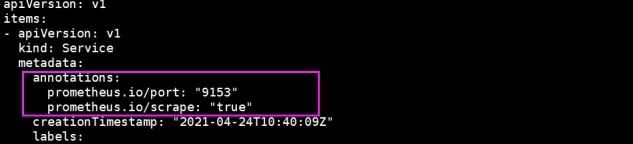
# 注解annotations下的prometheus.io/scrape:
"true"参数表示service node-exporter可以被prometheus抓取到
2) 应用yaml文件
[root@k8s-admin prometheus]# ls node-exporter-* |
xargs -i kubectl apply -f {}
daemonset.apps/node-exporter
created
service/node-exporter created
3) 查看部署信息
[root@k8s-admin prometheus]# kubectl get
daemonset,pod,svc,ep -o wide -n ops

4) 访问prometheus
http://172.16.1.71:30090/targets
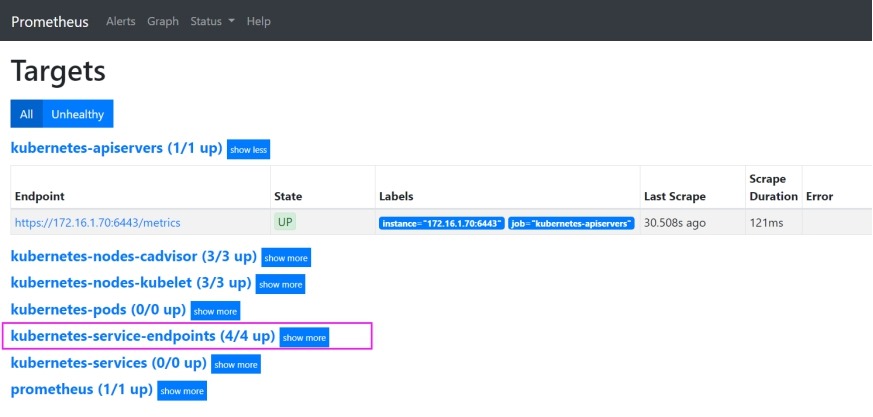
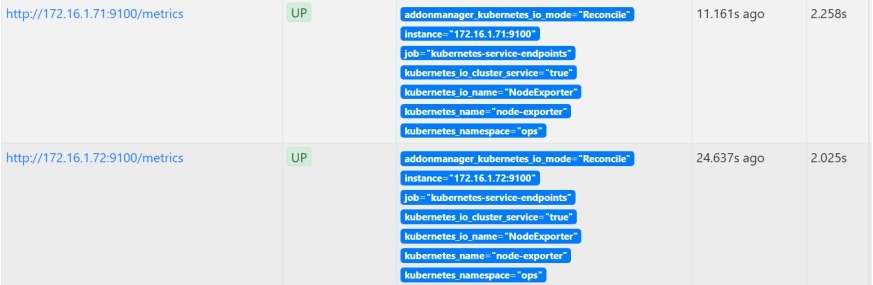
# kubernetes-service-endpoints中增加了如下内容
(4)
k8s资源信息监控
1) 配置文件说明
[root@k8s-admin prometheus]# ls -l
kube-state-metrics-*
-rw-r--r-- 1 root root 2362 Jul 24 2020
kube-state-metrics-deployment.yaml
# kube-state-metrics
部署文件,Deployment方式,
# 连接api-serverservice的授权配置为AccountName: kube-state-metrics
-rw-r--r-- 1 root root 2536 Jul 24 2020
kube-state-metrics-rbac.yaml
# 授权文件,ServiceAccount方式,名称kube-state-metrics
-rw-r--r-- 1 root root 498 Jul 24 2020
kube-state-metrics-service.yaml
# kube-state-metrics
svc配置文件,内部暴露端口为8080、8081
# 注解annotations下的prometheus.io/scrape: "true"参数表示service node-exporter可以被prometheus抓取到
2) 应用yaml文件
[root@k8s-admin prometheus]# ls kube-state-metrics-*
| xargs -i kubectl apply -f {}
deployment.apps/kube-state-metrics
created
configmap/kube-state-metrics-config
created
serviceaccount/kube-state-metrics
created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics
created
role.rbac.authorization.k8s.io/kube-state-metrics-resizer
created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics
created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics
created
service/kube-state-metrics created
3) 查看部署信息
[root@k8s-admin prometheus]# kubectl get
deployment,pod,svc,ep -o wide -n ops

4) 访问prometheus
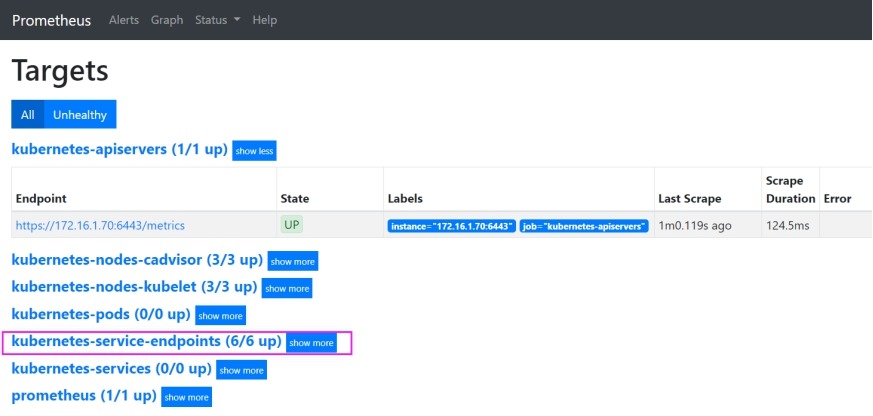
http://172.16.1.71:30090/targets
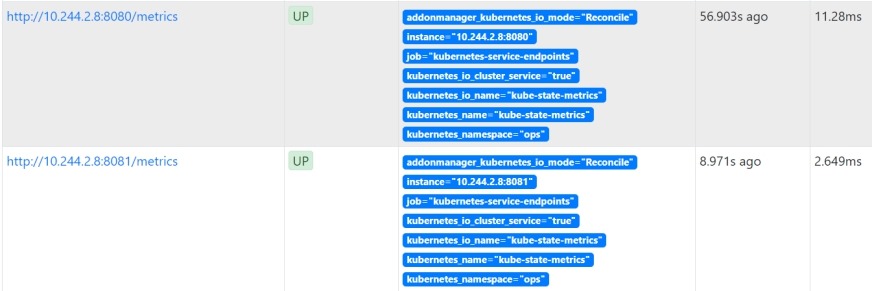
(5)
安装grafana
1) 配置文件说明
[root@k8s-admin prometheus]# ls -l grafana.yaml
-rw-r--r-- 1 root root 1266 Jul 24 2020
grafana.yaml
# 该配置文件包含Deployment和service配置。
# grafana版本为grafana:7.1.0,/var/lib/grafana挂载到nfs动态pvc卷grafana上
# service类型为NodePort,暴露外部端口为30030
2) 应用yaml文件
[root@k8s-admin prometheus]# kubectl apply -f
grafana.yaml
deployment.apps/grafana created
persistentvolumeclaim/grafana
created
service/grafana created
3) 查看部署信息
[root@k8s-admin prometheus]# kubectl get
deployment,pod,svc,pvc,pv,ep -n ops -o wide
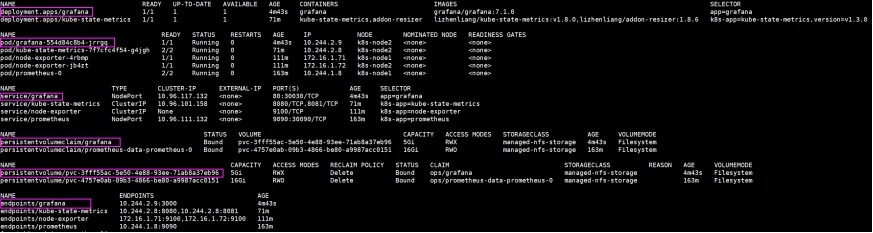
# 查看存储

4) 登录grafana
http://172.16.1.71:30030/
(6)
在grafana中导入dashboard
1) 配置grafana连接prometheus
# 获取svc值
[root@k8s-admin ~]# kubectl get svc -n
ops
prometheus NodePort 10.96.111.132 <none> 9090:30090/TCP 47h
Address 1: 10.96.111.132
prometheus.ops.svc.cluster.local
# 连接prometheus
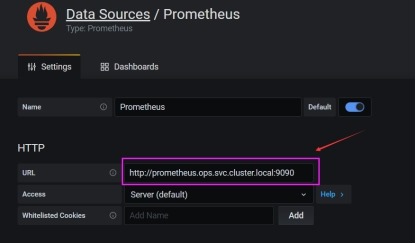
2) 导入"K8S工作节点监控"(node性能)

3) 导入K8S集群资源监控(pod性能)
4)
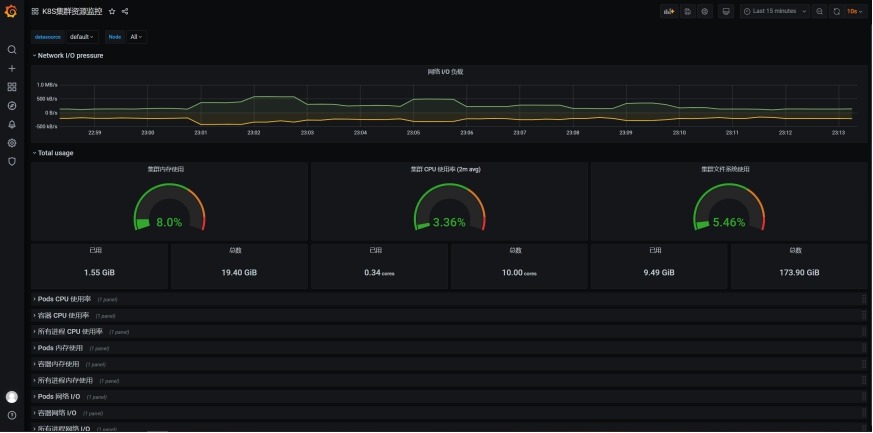
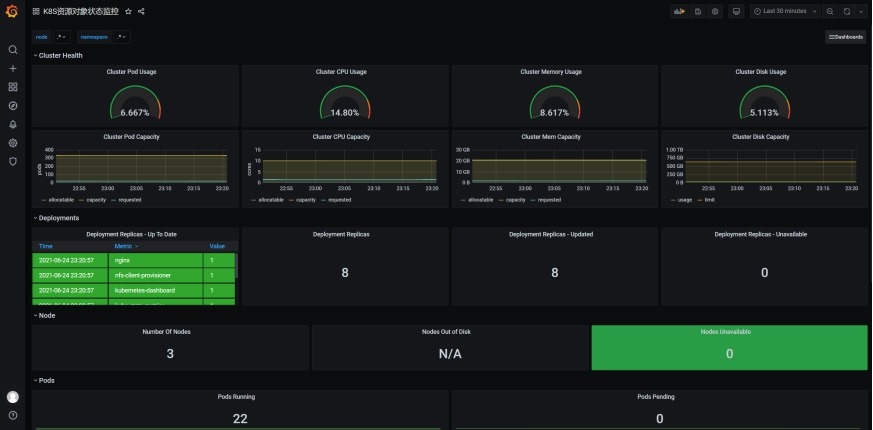
导入"K8S资源对象状态监控"(kube-state-metrics)
(7)
告警
1) 配置文件说明
[root@k8s-admin prometheus]# ls -l
alertmanager-*
-rw-r--r-- 1 root root 652 Jul 24 2020
alertmanager-configmap.yaml
# alertmanager报警邮箱配置文件,根据需要修改,采用ConfigMap方式挂载
-rw-r--r-- 1 root root 2175 Jul 24 2020
alertmanager-deployment.yaml
# altermanager部署配置,deployment方式部署,nfs动态卷pvc alertmanager挂载到/data
-rw-r--r-- 1 root root 323 Jul 24 2020
alertmanager-pvc.yaml
# nfs动态卷pvc
alertmanager配置文件
-rw-r--r-- 1 root root 384 Jul 24 2020
alertmanager-service.yaml
# alertmanager
svc配置文件,NodePort方式暴露30093端口
2) 应用yaml文件
[root@k8s-admin prometheus]# ls alertmanager-* |
xargs -i kubectl apply -f {}
configmap/alertmanager-config
created
deployment.apps/alertmanager
created
persistentvolumeclaim/alertmanager
created
service/alertmanager created
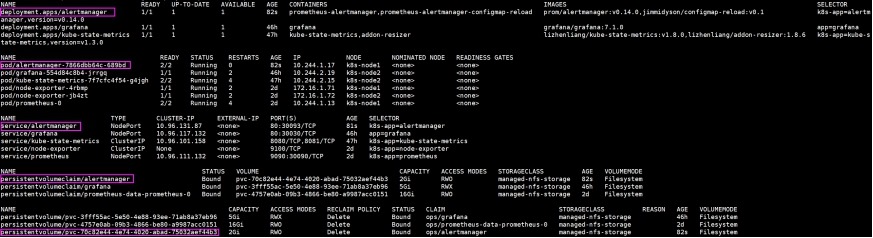
3) 查看部署信息
[root@k8s-admin prometheus]# kubectl get
deployment,pod,svc,pvc,pv -o wide
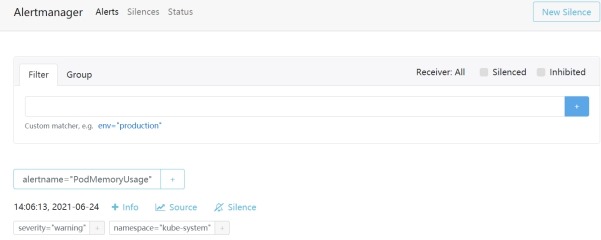
4) 访问alertmanager
http://172.16.1.71:30093/#/alerts
5) 查看报警规则
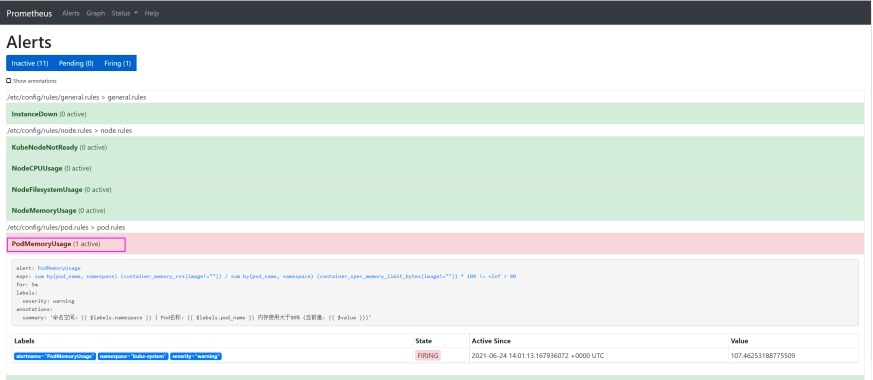
6) 查看报警邮件
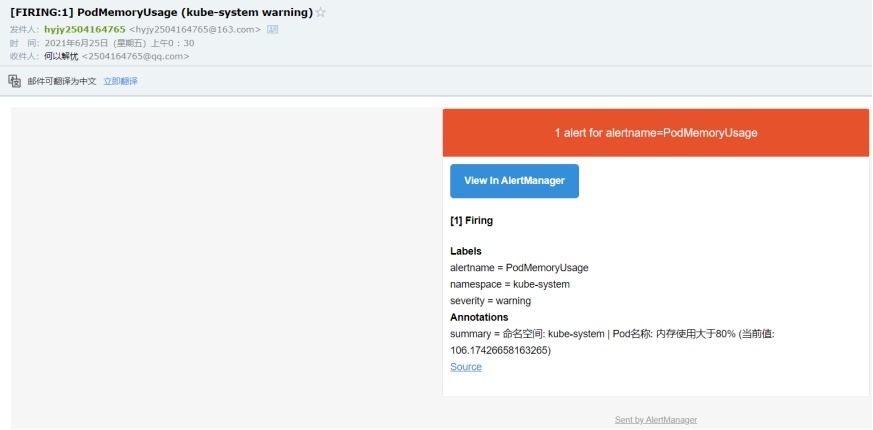
(8)
修改Prometheus和Alertmanager配置文件后重启方法
以上的配置中Prometheus和Alertmanager分别在各自的pod中又启动了一个镜像为
jimmidyson/configmap-reload:v0.1的容器,用于监控配置文件的更改,然后重启pod
中的Prometheus和Alertmanager容器,但有时不太起作用,这时需要采用手动的方
法重启pod中的Prometheus和Alertmanager。
[root@k8s-admin prometheus]# kubectl get pod -n ops
-o wide | egrep "prometheus|alertmanager"
Prometheus: curl -XPOST
http://10.244.1.13:9090/-/reload
Alertmanager: curl -XPOST
http://10.244.1.17:9093/-/reload
第15章: Prometheus监控Kubernetes资源与应用的更多相关文章
- Kubernetes集群部署史上最详细(二)Prometheus监控Kubernetes集群
使用Prometheus监控Kubernetes集群 监控方面Grafana采用YUM安装通过服务形式运行,部署在Master上,而Prometheus则通过POD运行,Grafana通过使用Prom ...
- Prometheus 监控K8S 资源状态对象
Prometheus 监控K8S 资源状态对象 官方文档:https://github.com/kubernetes/kube-state-metrics kube-state-metrics是一个简 ...
- Prometheus 监控 Kubernetes Job 资源误报的坑
转载自:https://www.qikqiak.com/post/prometheus-monitor-k8s-job-trap/ 昨天在 Prometheus 课程辅导群里面有同学提到一个问题,是关 ...
- 部署prometheus监控kubernetes集群并存储到ceph
简介 Prometheus 最初是 SoundCloud 构建的开源系统监控和报警工具,是一个独立的开源项目,于2016年加入了 CNCF 基金会,作为继 Kubernetes 之后的第二个托管项目. ...
- Prometheus监控学习笔记之解读prometheus监控kubernetes的配置文件
0x00 概述 Prometheus 是一个开源和社区驱动的监控&报警&时序数据库的项目.来源于谷歌BorgMon项目.现在最常见的Kubernetes容器管理系统中,通常会搭配Pro ...
- Kubernetes容器集群管理环境 - Prometheus监控篇
一.Prometheus介绍之前已经详细介绍了Kubernetes集群部署篇,今天这里重点说下Kubernetes监控方案-Prometheus+Grafana.Prometheus(普罗米修斯)是一 ...
- Prometheus 监控外部 Kubernetes 集群
转载自:https://www.qikqiak.com/post/monitor-external-k8s-on-prometheus/ 在实际环境中很多企业是将 Prometheus 单独部署在集群 ...
- 使用Prometheus Operator 监控Kubernetes(15)
一.Prometheus概述: Prometheus是一个开源系统监测和警报工具箱. Prometheus Operator 是 CoreOS 开发的基于 Prometheus 的 Kubernete ...
- Prometheus的监控解决方案(含监控kubernetes)
prometheus的简介和安装 Prometheus(普罗米修斯)是一个开源系统监控和警报工具,最初是在SoundCloud建立的.自2012年成立以来,许多公司和组织都采用了普罗米修斯,该项目拥有 ...
随机推荐
- Flutter 2.2 更新详解
Flutter 2.2 版已正式发布!要获取新版本,您只需切换到 stable 渠道并更新目前安装的 Flutter,或前往 flutter.cn/docs/get-started 从头开始安装. 虽 ...
- .Net core Worker Service 扩展库
.Net core Worker Service 扩展库,目的为更易控制每一个worker 的运行. 提供根据配置文件对每一个Worker的停止.启动和自动解析注册Worker. 获取配置的方式不限于 ...
- [DB] MySQL 索引分类
按数据结构 B树索引 数据位于叶子节点,到任何一个叶子节点的距离相同,一般不超过3-4层 B+树索引:每个叶子节点除了数据还存放前后叶子节点的指针,方便快速检索,是InnoDB采用的索引结构 Hash ...
- 7.12-7.19 id、w、who、last、lastb、lastlog
7.12-7.19 id.w.who.last.lastb.lastlog 目录 7.12 id:显示用户与用户组的信息 7.13 w:显示已登录用户信息 7.14 who:显示已登录用户信息 显示最 ...
- Android屏幕适配全攻略(最权威的官方适配指导)屏幕尺寸 屏幕分辨率 屏幕像素密度 dpdipdpisppx mdpihdpixdpixxdpi
Android屏幕适配全攻略(最权威的官方适配指导)原创赵凯强 发布于2015-05-19 11:34:17 阅读数 153734 收藏展开 转载请注明出处:http://blog.csdn.net/ ...
- PHP相关session的知识
由于http协议是一种无状态协议,所以没有办法在多个页面间保持一些信息.例如,用户的登录状态,不可能让用户每浏览一个页面登录一次.session就是为了解决一些需要在多页面间持久保持一种状态的机制.P ...
- 达梦数据库产品支持技术学习分享_Week2
本周主要从以下几个方面进行本人对达梦数据库学习的分享,学习进度和学习情况因人而异,仅供参考. 一.文本命令行工具使用的方法(Disql和dmfldr) 二.数据库备份 三.定时作业功能 四.系统表和动 ...
- Go语言web开发---Beego的session
一.简介 Session是一段保存在服务器上的信息,当客户端第一次访问服务器时创建Session,同时也会创建一个名为beegosessionID,值为创建的Session的id的Cookie. 这个 ...
- NVIDIA GPU上的Tensor线性代数
NVIDIA GPU上的Tensor线性代数 cuTENSOR库是同类中第一个GPU加速的张量线性代数库,提供张量收缩,归约和逐元素运算.cuTENSOR用于加速在深度学习训练和推理,计算机视觉,量子 ...
- CMOS图像传感器理解
CMOS图像传感器理解 水流方向从左边流向右边,上面有一个开关,拧下去的时候水流停止,拧上去的时候水流打开.左边是水流的源头我们给它起个名字,叫做源端(就是源头的意思嘛),右边是水流出去的地方,也就是 ...