Raft: 一点阅读笔记
前言
如果想要对Raft算法的了解更深入一点的话,仅仅做6.824的Lab和读《In Search of an Understandable Consensus Algorithm》这篇论文是不够的。我个人粗略阅读了一下Tikv中关于Raft的实现(https://github.com/tikv/raft-rs ,使用rust语言,基本移植了etcd中关于raft算法的实现),并配合着注释阅读了下原作者的博士论文《CONSENSUS: BRIDGING THEORY AND PRACTICE》,配合着PingCap的一些Blog,还是比较有收获的。开这篇Blog是希望记录一下6.824的Lab和《In Search of an Understandable Consensus Algorithm》中没有涉及到的一些东西。
Cluster Member Change
集群成员变更足足占了一整张Ongano的论文,重要性不言而喻吧..
Safty Guarantee
Conf Change的设计首先要保证安全问题;假设当前使用旧配置的机器构成集合Mold,使用新配置的机器构成集合Mnew;在Ongano的论文中,貌似将安全性问题等价为了双主问题,即Mold和Mnew是否会形成两个互不交叠Qurom(两个Qurom存在选出两个Leader的可能性);换句话说,原作者认为只要解决了双主问题,Conf Change的安全性就得以保证;
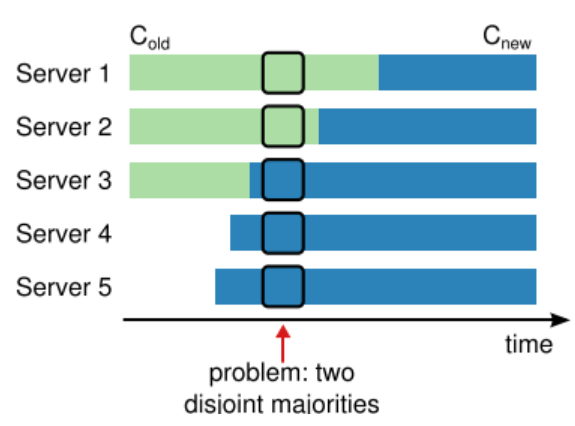
上图为一种双主问题的情景;在箭头所指的地方,{3, 4, 5} ∈ Mnew, {1, 2} ∈ Mold;nQurom(Mold) = (3 + 1) / 2 = 2,nQurom(Mnew) = (5 + 1) / 2 = 3;可以看到{1, 2}可以构成Qurom,{3, 4, 5}也可以构成Qurom,这样就可能出现双主错误;
在2014年的论文中,采用了一种Join Concensus算法解决双主问题;而在Phd的论文中提出了一种更加简单的方法:一次Conf Change只添加/删除一台Server;在这种情景下,两个Qurom至少有一个交集,因此双主错误可以避免,而更加复杂的Conf Change也可以由多次增/删机器来实现;

Conf Change
1)当Server收到Conf Change时,必须立刻使用,无需等待其对应的日志被提交;
2)只有上一条Conf Change成功提交后,才允许下一条Conf Change开始;
3)Conf Change可能最终未能提交而被截断;在这种情景下,Server必须恢复到Conf之前的状态
Unfortunately, this decision does imply that a log entry for a configuration change can be removed (if leadership changes); in this case, a server must be prepared to fall back to the previous configuration in its log.
作者在论文中解释了为什么Conf Change的日志为什么会立即生效,而不是在Commit时生效:
If servers adopted Cnew only when they learned that Cnew was committed, Raft leaders would have a difficult time knowing when a majority of the old cluster had adopted it. They would need to track which servers know of the entry’s commitment, and the servers would need to persist their commit index to disk;
增添机器
我们考虑新的机器的加入会对集群的Avalibility产生哪些影响:
1)新的机器初始日志是空的,它Catch-Up需要一段不短的时间;
2)新的机器可能会被算入Qurom,它的Catch Up所需时间可能会影响性能;例如3台机器构成的cluster其Qurom为2,而4台机器构成的Qurom为3,为此整个集群必须等待那个新加入者顺利Catch Up才能提交新的请求;
- 新的机器可能性能或环境很差,迫使Leader为它花费更多的开销;例如说必须给他送多次AppendEntries浪费网络带宽,或者想做一次日志压缩,但被迫要等待那台慢的机器;
Raft算法充分考虑了上述情景,并给出了解决方案:
为这些新加入的机器设定设定一个Learner的角色;Learner可以投票,可以接收日志,但其本身不被计入Qurom内,等它Catch Up到了一定阶段后,再把它计入到Qurom内;这解决了问题1和2,但又引入了一个新的问题,就是怎么评估新机器的Catch Up进度,以及这个进度到哪个程度时才把它计入Qurom;
为了解决3以及前面新带来的问题,作者提出了一种Catch-Up算法;设定一个max_round,每个round里都会将自己所有的日志(第一轮round)或者新机器缺的日志(后面的rounds)全量发送;如果发现新的机器可以赶得上,那么就把它计入Qurom,否则会回报一个错误,期望集群管理者将这台机器撤除掉;
If the last round lasts less than an election timeout, then the leader adds the new server to the cluster, under the assumption that there are not enough unreplicated entries to create a significant availability gap. Otherwise, the leader aborts the configuration change with an error.
注意在新的配置中,虽然新的机器不被计入Qurom,但Qurom仍然被定义为Majority,因此不存在双主问题,仅仅是Qurom不包括那台龟速机而已,集群仍然是可用的;同时要注意到这个错误也不会违背invariants;让我们再回顾一下为什么这套错误机制为什么会被引入:
The leader should also abort the change if the new server is unavailable or is so slow that it will never catch up. This check is important: Lamport’s ancient Paxon government broke down because they did not include it. They accidentally changed the membership to consist of only drowned sailors and could make no more progress [48]. Attempting to add a server that is unavailable or slow is often a mistake.(这个mistake应该指的是人工错误)
撤出机器
增添机器要担心的事情已经很多了,但撤出机器要烦心的事情远比增添机器要多得多;撤除机器要担忧的不再是对Avalibility的影响,而是具体的实现细节;
1)被撤出的机器什么时候可以关停?(注意我使用“撤出”来描述Conf Change,而不是“停机”or"关闭"之类的,意图在指出机器撤出并不意味着它不再和集群有通信)
2)当前的Leader不属于Cnew,该怎么办?
3)对于那些撤出的机器,该怎样处理RPC,包括要不要给它们发RPC,以及怎样处理来自它们的RPC?
Incomming RPC的处理
第3个问题是最严重的,因为它事关具体的实现;我们先解决一个子集,即如何处理那些自己收到的RPC,即Incomming RPC。
先看一下作者的原话:
• A server accepts AppendEntries requests from a leader that is not part of the server’s latest configuration. Otherwise, a new server could never be added to the cluster (it would never accept any log entries preceding the configuration entry that adds the server).
• A server also grants its vote to a candidate that is not part of the server’s latest configuration (if the candidate has a sufficiently up-to-date log and a current term). This vote may occasionally be needed to keep the cluster available.
第一条其实又回到了增添机器这一操作的具体实施措施上;注意最初新机器的日志是空的,这意味着它不知道Cnew是什么东西,所以它必须接收任何来自Leader的AppendEntries,不然Catch Up机制就是一纸空谈;
第二条告诉我们,允许投票给那些不属于Cnew的机器;这是为了保证Avalibility;
用作者的原文总结:
Thus, servers process /incoming RPC requests/ without consulting their current configurations.
即对于Incomming RPC全体照接不误;
Leader Step Down
A leader that is removed from the configuration steps down once the Cnew entry is committed.
Leader Step Down规则规定了当Leader ∉ Cnew时怎么应对Cnew Entry;对于那些非Leader的Server,收到Cnew时直接就要采用其中的配置,不需要其他的行动;对于Leader来说,它同样也要立刻采用其中的配置,但很显然它不应该继续做Leader了,因为新的Conf中不包含它,即我们期望它应当被移除掉;Raft算法要求这种Leader在顺利Commit了Cnew之后就Step Down;
一定要注意 Step Down != Shut Down,只是让Leader下台而已;注意到此时Leader只会向那些属于Cnew的Server发送AppendEntries(而不会给自己发送),因此新的Leader必定属于Cnew;
作者也吐槽了自己的算法引入的奇怪情景:
First, there will be a period of time (while it is committing Cnew) when a leader can manage a cluster that does not include itself; it replicates log entries but does not count itself in majorities.
Second, a server that is not part of its own latest configuration should still start new elections, as it might still be needed until the Cnew entry is committed (as in Figure 4.6). It does not count its own vote in elections unless it is part of its latest configuration.
第一,这意味存在这样一种情景,即一个不属于当前配置的Leader在管理整个集群,且这个Leader不会把自己算入Qurom中;
第二,如果创建Conf Change的机器最终不会在这次Conf Change中不会被移除,那没啥问题;问题在于如果Leader ∉ Cnew 但 Leader创建了Cnew的情景;假如在Cnew被提交前由于某些原因被罢黜了,它还不能躺平,还必须参与竞选!注意前文中我们知道Server对于一切的Incomming RPC是照单全收的,这造成了一个诡异的现象:一台Removed Server身上有Cnew,它知道自己不在Cnew中,但它仍然要参与竞选,它还可能胜选并把Cnew给提交;
Avoid Disruptions
Once the cluster leader has created the Cnew entry, a server that is not in Cnew will no longer receive heartbeats, so it will time out and start new elections. Furthermore, it will not receive the Cnew entry or learn of that entry’s commitment, so it will not know that it has been removed from the cluster.
这里其实也暗喻了Conf Change中对Outgoing RPC的处理方法,即Leader不再向哪些不属于Cnew的机器发送心跳包和AppendEntries,这会导致这群机器TimeOut,然后触发选举机制扰乱整个集群;
注意上述这个情景不一定是坏的,反而在某些时刻是必要且合理的,例如Leader Step Down中所描述的第二个场景,我们更期望那个拥有Cnew的机器当选;
preVote可以很大程度上避免这种情景,但并不完全够用;preVote机制可以保证当Cnew成功备份到Majority时,那些不属于Cnew的机器无法通过preVote阶段,但在Cnew成功备份到Majority之前,preVote机制无法避免这次Distruption:
Raft的作者提供的建议是使用HeartBeat + RequestVote来最大程度的减小上述场景;在原算法中,任何Server只要发现拉票者的term至少比自己新,且拥有最新的日志,就会向它投票并考虑更新自己的term(如果term更高可能会直接或间接的罢黜Leader,即我们讨论的Distruptive);这里做出了一点限制:
在一个election timeout内如果收到了心跳包,则拒绝投票,拒绝重置定时器,或者会把这个请求延后;
理论上讲,如果election timeout内如果收到了心跳包,那么Leader大概率是存在的,因此问题不算很大;
这里与Leader Transfer的思想存在冲突,Leader Transfer是期望立刻触发选举的,因此对于那些Leader Transfer的请求还需要捎带一个flag,表示“我自己有disrupt the leader”的权力;
Conf Change 小结
Cluster Member Change是一个必要且重要的操作,基本可以抽象为两类行为:添加新的机器,或者撤出某些机器;这里讨论了Cluster Member Change的三个问题:安全保证、可用性、具体实现;
首先是安全保证;Cluster Member Change唯一需要考虑的安全性问题是双主问题,即必须避免Cnew和Cold中的机器分别构成Qurom产生双主;最简单直接的方法就是一次仅增/删一台机器,这种情景下Cold和Cnew中的Qurom必定有交集,即最多只能形成一个Qurom,这样保证了安全性问题;
第二是可用性(Avalibility)问题;这主要体现在增加机器的场景下;新增的机器可能需要一段不短的时间来Catch Up,也可能新增的机器性能很差或环境很差;对于第一种情况,Raft算法设定了一种Learner角色,新加入的机器能够接收AppendEntries,但不被算入Qurom内,其投票请求也会被忽视,直到Leader认为它的确“赶上了”为止;对于第二种情况,作者提供了一种Catch Up算法,当新的Server无法赶上时,Leader会放弃这台机器并向管理员告知一个错误,期望将新的机器给撤出掉;注意到我们的Conf Change日志并不会到这台机器上,因此Conf Change只要在原来的集群上顺利提交,就可以将这个拖累的机器给撤出;
第三就是具体的实现细节了;对于Incomming RPC,必须全部接受并进行处理;对于Outgoing RPC,只需要发送给自己当前应用的配置下的Server就可以了;对于那些在新配置中被撤出的机器,要避免他们超时后拉票造成的Disruptive,这里使用了心跳机制 + RequestVote限制来拒绝拉票;
解耦
TiKV里关于Raft基本移植了etcd中关于Raft的实现。一个很让我感到很惊奇的地方在它实现了Raft算法对存储、通信的解耦合。
当然也对使用提出了非常严格的限制。第一,由于内部逻辑中是没有时钟的,因此定时的逻辑必须由使用者来驱动(例如每100ms都要主动调用tick);第二,使用者必须保证正确处理全部的消息,例如说保证持久化、保证和其他peer之间的通信,如果处理出错甚至可能导致拜占庭错误。
选举
由于Leader Transfer机制的引入和Conf Change的影响,选举规则还需要作出一些其他的调整;
首先讨论Conf Change。Conf Change中已经脱离了集群的机器由于无法收到AppendEntries,因此会成为Candidate并试图向其他Server拉票。由于Server必须处理一切的incomming RPC(不管这些RPC的源是否属于当前配置),因此集群可能被扰动。preVote机制是无法避免集群扰动的,因为已经脱离了当前config的Candidate仍然可能持有最新的日志并当选为Leader(这不可避免,因为Conf Change的实现也部分依赖于此,可以参考前文中关于Conf Change的讨论)。
Ongano的论文提出了一种方案:如果一台机器收到了拉票请求,即使对方的term比自己高,它也可以拒绝投票,如果:
- 它自己是Leader且最近
check_qurom返回成功,或者 - 它自己是Follower且在election_timeout里收到了心跳;
- 满足1.2且请求消息并不是Leader Transfer请求;
上述1、2情景都可以推断存在一个合法的存活的Leader,因此拒绝投票以避免新Leader的产生;3是一个特例,因为Leader Transfer机制本身就是期望能在一个election timeout内选举出一个新的Leader。
Leader Transfer
Leader Transfer是做负载均衡的策略之一,例如说将Leader的角色交给一台性能更好地服务器;同时也是必要的,例如说我们希望关停某台机器进行维护,而它偏偏是个Leader,关停它可能会丢掉部分请求且导致一段时间内集群不可用;
Leader Transfer的规则大致如下:
当前Leader拒接一切client的请求,因为Leader会改变,所以这些请求大概率会被截断,不如不接;
Leader检查transferee的match Index,如果transferee缺少日志的话,则全量将自己的日志发送给它;
使用一条
MsgTimeoutNow告知Transferee计时器立刻超时并触发选举流程;如果一个election timeou中Leader仍未发现自己被罢黜,那么应当立刻撤销Leader Trasnferee的过程,恢复接受client的请求;
回顾一下我之前担心的几个问题:
- 当前的Leader不是最新的Leader;
- 过期的LeaderTransferee;
- 与lease这种基于election timeout的策略产生冲突;
在etcd的实现中,Leader在tick时都会立刻进行一次check_qurom,如果check_qurom失败了就会立刻主动下台(在原论文中没有提及Leader主动下台的情景),这样虽然存在假阳性的情况,但无疑大大避免了问题1的情景;
问题3主要在考虑原Leader的lease期会和transferee的Leader期存在交集导致了一种类似”双主“的情景,但原Leader此时已经停止接收一切客户请求了,因此应该不会出现问题;
比较麻烦的是2;Leader Transfer消息被作为本地消息并没有被标注消息发出时的term,这意味着Follower会相应并执行一切的这些消息,这可能扰乱集群;选举规则应该能避免这种情景;
Group Commit
Group Commit并不是一种优化,而是一种对Commit情景的更加严格的限制;初始阶段假定所有的peers都属于同一个group,也可以为每个peer指定不同的group_id;提交时,要求entries至少备份到不同的group上,否则不允许提交;
Tests group commit.
Logs should be replicated to at least different groups before committed;
all peers are configured to the same group, simple quorum should be used.
优化类型
从这部分开始可以讨论一下Raft的优化了。优化是一个很大的课题,可以优化的层次非常多:
Multi - Raft,对 Key - Value 进行range - based或者hash - based的分片(Sharding);
prepare优化,即增添Follower -> Leader 的日志流,打破Leader必须拥有全部已提交日志的限制条件;
Batch、Pipeline;
读优化,例如ReadIndex、Follower Read、Lease Read;
落盘、通信的优化等;
优化的层次非常多,这里只讨论内联到算法内部的优化;即3和4;2我只听说PolarDB实现了,但没见过。
ReadIndex、Follower Read、Lease Read
首先,不要把读操作狭义的理解为Key - Value中的读一个或几个Key的操作。读操作应该抽象成某个时刻的状态机的部分或全部状态的只读操作;因此Raft中不会提供读操作的具体实现,而是仅仅告知应用层读操作可以进行。
ReadIndex可以满足强一致读,即必定返回的是某个时刻的最新数据。请求到来时会生成一条ReadIndex记录,其中记录了这个时刻的commitIndex和读请求本身的ctx;
如果是Follower收到了读请求,Follower会将这个请求转发给Leader;Leader收到了读请求时,会记录下这个请求以及请求到来时的commitIndex;在发送心跳包/AppendEntries时,会记录下有哪些Follower成功响应。如果超过Qurom的Follower们回复了响应,那么当appliedIndex执行到那个读请求的commitIndex时,那个读请求以及之前的所有读请求都可以正确的执行了,此时Raft会向应用层返回一个ReadState,里面记录了所有可以实现一致读的请求,应用层根据ReadState检索并执行读请求;如果这个读请求来自于Follower,那么一条MsgReadIndexResp也将转发给Follower,里面记录了相应的commitIndex以及读请求的ctx,Follower也可以根据这条消息生成自己的ReadState返还给应用层;
那么ReadIndex为什么满足强一直读呢?注意经过一轮Qurom响应后,Leader即可确认在读请求到来时刻,自己的commitIndex是那个时刻最新的commitIndex,那么那个时刻的最新状态,就应该是commitIndex之前所有的日志均被执行后的状态,即appliedIndex == commitIndex时的状态。这样也可以理解为什么经过了Qurom check之后,仍然要等待appliedIndex == commitIndex才能响应读请求了。
以上ReadIndex流程其实就是Follower Read的实现原理。注意MsgReadIndexResp返回的不仅仅是读请求本身,还有读请求到来时刻Leader的commitIndex,即那个时刻的最新的commitIndex。对于Follower来说,它也可以等待自己的appliedIndex == MsgReadIndexResp.commitIndex后执行队请求了。
你可能会疑惑,明明说的是Follower Read,为什么一条只读请求仍然经过了Leader且要check qurom?这样Leader岂不是仍然担负了读操作本身的开销?并不是这样的,这里Leader担负的仅仅是同步和通信的开销。读操作本身可能很大,例如说数据库扫描一整张表,这个操作本身并没有被Leader所执行,不过是这个请求在Leader这里走了一圈而已。当这个请求已经被Leader成功的做了Qurom Check之后,读表这个操作就可以在Follower这里做了。这也是为什么我前文中强调的,不要把读操作的理解狭义化,读操作本身不是在Raft算法里实现的,而是应用层实现的,Raft算法只是告知应用层可以做读请求了而已。
Lease Read需要依赖时间来保证强一致性(如果time drift过大就悲剧了)。Lease期的设定必须小于election_timeout,否则可能导致旧Leader的Lease期与新Leader的任期出现交叠,导致一种“双主”情景的出现。Lease在每次成功check_qurom会成功续约;在时间上,如果一个Leader在Lease期内,那么被其check_qurom的机器以及它本身会拒绝Lease期内发起preVote和RequeseVote的请求(具体原因请看前文中对拒绝投票原因的讨论),即Lease期内不会出现更新的Leader,因此读操作可以直接进行而无需为了这个读操作再进行一次check_qurom。
如果开启了Lease Read模式,那么ReadOnly请求就不会进行Qurom Check了,仅仅检查了一下自己是否是当前的Leader,就生成了ReadState并告知了应用层。根据 https://pingcap.com/blog-cn/tikv-source-code-reading-19/ 的描述,Lease Read的Lease期检查应该是被放在了应用层,因此Raft库中没有相关的代码。
Batch & Pipeline
对于通信过程,可以通过Batch和Pipeline。注意TiKV的Raft库和通信的实现是解耦的,一切需要发送给其他peers的消息都会被放在RawNode.messages之中,由应用层取出并发送给对应的peer,因此Batch操作需要在应用层实现。具体来说就是将消息进行打包,减少元数据占据的总数据的比例以降低通信开销。但也必须要设定一个具体的范围,例如说等待多长时间后必须发送消息,或者对消息大小进行限制。
Leader要为每一个peer维护一个nextIndex,表明下一次给它们发送日志时要从nextIndex开始;Pipeline指的是无需等待上一轮的Msg得到相应的MsgResp,就可以发送新的Msg,即加快发送消息的效率。
Parallelly Append & Asynchronous Apply
除了对通信的优化外,还有两个可以优化的地方:日志的持久化,以及日志的apply。
对于Leader来说,日志的持久化可以和AppendEntries并行进行。当然,在收到Qurom的确认前如果Leader尚未完成日志的持久化,那么它不能调整自己的commitIndex,因为调整commitIndex意味着日志本身已不可撤销。
日志的apply既包括执行也很可能涉及到新的落盘操作,开销不可忽视。实际上apply过程完全可以和Raft算法的执行并行进行,因为日志的apply改动的是状态机的状态(例如数据库就是一个状态机),而不是Raft算法所维护的状态。我们完全可以在日志成功commit之后,开启另一个线程去异步的Apply日志,通过回调来改动applyIndex;
参考文献
[1] CONSENSUS: BRIDGING THEORY AND PRACTICE
[2] In Search of an Understandable Consensus Algorithm.
[3] https://pingcap.com/blog-cn/lease-read/
[4] https://youjiali1995.github.io/raft/etcd-raft-log-replication/
[5] https://pingcap.com/blog-cn/optimizing-raft-in-tikv/
[6] https://pingcap.com/blog-cn/tikv-source-code-reading-19/
Raft: 一点阅读笔记的更多相关文章
- 阅读笔记 1 火球 UML大战需求分析
伴随着七天国庆的结束,紧张的学习生活也开始了,首先声明,阅读笔记随着我不断地阅读进度会慢慢更新,而不是一次性的写完,所以会重复的编辑.对于我选的这本 <火球 UML大战需求分析>,首先 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- Hadoop阅读笔记(一)——强大的MapReduce
前言:来园子已经有8个月了,当初入园凭着满腔热血和一脑门子冲动,给自己起了个响亮的旗号“大数据 小世界”,顿时有了种世界都是我的,世界都在我手中的赶脚.可是......时光飞逝,岁月如梭~~~随手一翻 ...
- CI框架源码阅读笔记3 全局函数Common.php
从本篇开始,将深入CI框架的内部,一步步去探索这个框架的实现.结构和设计. Common.php文件定义了一系列的全局函数(一般来说,全局函数具有最高的加载优先权,因此大多数的框架中BootStrap ...
随机推荐
- 1089 Insert or Merge
According to Wikipedia: Insertion sort iterates, consuming one input element each repetition, and gr ...
- 1.6.1- HTML中ul元素无序列表的使用
无序列表的各个列表项之间没有顺序级别之分,是并列的,语法如下: <ul> <li>列表项1</li> <li>列表项2</li> <l ...
- Linux 服务管理的两种方式service和systemctl
service命令 service命令其实是去/etc/init.d目录下,去执行相关程序 ``` # service命令启动redis脚本 service redis start # 直接启动red ...
- 基于dalvik模式下的Xposed Hook开发的某加固脱壳工具
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/77966109 这段时间好好的学习了一下Android加固相关的知识和流程也大致把A ...
- PAT 乙级 -- 1013 -- 数素数
题目简介 令Pi表示第i个素数.现任给两个正整数M <= N <= 104,请输出PM到PN的所有素数. 输入格式: 输入在一行中给出M和N,其间以空格分隔. 输出格式: 输出从PM到PN ...
- 基于frida框架Hook native中的函数(1)
作者:H01mes撰写的这篇关于frida框架hook native函数的文章很不错,值得推荐和学习,也感谢原作者. 0x01 前言 关于android的hook以前一直用的xposed来hook j ...
- Sqli 注入点解析
目录 Less-1: 字符型注入 Less-2: 数字型注入 Less-3: 单引号字符型+括号 Less-4: 双引号字符型+括号 Less-5: 单引号字符型+固定输出信息 (floor报错注入& ...
- hdu5246超级赛亚ACMer
题意(中文题意直接粘吧) 超级赛亚ACMer Problem Description 百小度是一个ACMer,也是一个超级赛亚人,每个ACM ...
- Windows核心编程 第七章 线程的调度、优先级和亲缘性(下)
7.6 运用结构环境 现在应该懂得环境结构在线程调度中所起的重要作用了.环境结构使得系统能够记住线程的状态,这样,当下次线程拥有可以运行的C P U时,它就能够找到它上次中断运行的地方. 知道这样低层 ...
- 分布式事务与Seate框架(1)——分布式事务理论
前言 虽然在实际工作中,由于公司与项目规模限制,实际上所谓的微服务分布式事务都不会涉及,更别提单独部署构建Seata集群.但是作为需要不断向前看的我,还是有必要记录下相关的分布式事务理论与Seate框 ...