MapReduce处理简单数据
首先要说明的是,关于老师给的实验要求,我在网上看到了原文,原文地址:https://blog.csdn.net/qq_41035588/article/details/90514824,有兴趣的同学可以去看一下。本篇博客是在此基础上进行的重写。
刚刚按照老师给的实验要求完成了一次关于MapReduce的实验,说是完成,其实也就是按照老师给的程序教程去配置关于MapReduce的一些环境,学习一些关于MapReduce的基本操作,并且学会搭建和运行MapReduce程序。现在将实验内容和代码按照要求展示一下,并按照我的实现步骤进行更改。
实验目的
1.准确理解Mapreduce的设计原理
2.熟练掌握WordCount程序代码编写
3.学会自己编写WordCount程序进行词频统计
实验原理
MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。
1.MapReduce的工作原理
在分布式计算中,MapReduce框架负责处理了并行编程里分布式存储、工作调度,负载均衡、容错处理以及网络通信等复杂问题,现在我们把处理过程高度抽象为Map与Reduce两个部分来进行阐述,其中Map部分负责把任务分解成多个子任务,Reduce部分负责把分解后多个子任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中输入的value值存储的是文本文件中的一行(以回车符为行结束标记),而输入的key值存储的是该行的首字母相对于文本文件的首地址的偏移量。然后用StringTokenizer类将每一行拆分成为一个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map方法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输入到reduce方法中,reduce方法只要遍历values并求和,即可得到某个单词的总次数。
在main()主函数中新建一个Job对象,由Job对象负责管理和运行MapReduce的一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。本实验是设置使用将继承Mapper的doMapper类完成Map过程中的处理和使用doReducer类完成Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由字符串指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务,其余的工作都交由MapReduce框架处理。
2.MapReduce框架的作业运行流程
(1)ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
(2)NodeManager:简称NM,NodeManager是ResourceManager在每台机器上的代理,负责容器管理,并监控他们的资源使用情况(cpu、内存、磁盘及网络等),以及向ResourceManager提供这些资源使用报告。
(3)ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动Container,并告诉Container做什么事情。
(4)Container:资源容器。YARN中所有的应用都是在Container之上运行的。AM也是在Container上运行的,不过AM的Container是RM申请的。Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster。Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
①运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源。
②运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并为了ApplicationMaster与NodeManager通信以启动的。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
实验内容
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“ ”分割,样本数据及格式如下:
买家id 商品id 收藏日期
10181 1000481 2010-04-04 16:54:31
20001 1001597 2010-04-07 15:07:52
20001 1001560 2010-04-07 15:08:27
20042 1001368 2010-04-08 08:20:30
20067 1002061 2010-04-08 16:45:33
20056 1003289 2010-04-12 10:50:55
20056 1003290 2010-04-12 11:57:35
20056 1003292 2010-04-12 12:05:29
20054 1002420 2010-04-14 15:24:12
20055 1001679 2010-04-14 19:46:04
20054 1010675 2010-04-14 15:23:53
20054 1002429 2010-04-14 17:52:45
20076 1002427 2010-04-14 19:35:39
20054 1003326 2010-04-20 12:54:44
20056 1002420 2010-04-15 11:24:49
20064 1002422 2010-04-15 11:35:54
20056 1003066 2010-04-15 11:43:01
20056 1003055 2010-04-15 11:43:06
20056 1010183 2010-04-15 11:45:24
20056 1002422 2010-04-15 11:45:49
20056 1003100 2010-04-15 11:45:54
20056 1003094 2010-04-15 11:45:57
20056 1003064 2010-04-15 11:46:04
20056 1010178 2010-04-15 16:15:20
20076 1003101 2010-04-15 16:37:27
20076 1003103 2010-04-15 16:37:05
20076 1003100 2010-04-15 16:37:18
20076 1003066 2010-04-15 16:37:31
20054 1003103 2010-04-15 16:40:14
20054 1003100 2010-04-15 16:40:1
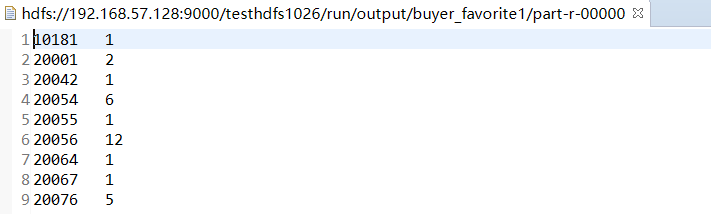
要求编写MapReduce程序,统计每个买家收藏商品数量。
实验步骤
MapReduce环境配置:
1、下载hadoop-eclipse-plugin-2.6.0 的jar包,复制到eclipse中的plugins目录下(对于较高版本的eclipse拥有dropins目录,需要将jar包放在这里,一定不要放在plugins目录下)。
2、启动eclipse,点击Window -> Show View -> Other,选择Map/Reduce Locations ,然后在下面控制台的位置出现Map/Reduce Locations.
3、右击空白处,点击New Hadoop location,按照下图进行配置:

其中,Location Name可以随便起一个名字;Map/Reduce Master为你hdfs.site-xml中的端口号,Host为你的端口号或者是你的host名字;DFS Master为你core.site-xml中的端口号(一般的配置应该都是和我一样的)。
4、配置环境变量。在系统变量中添加HADOOP_USER_NAME,内容为在配置过程中的location name,如下如所示:

实现流程与代码:
1、启动在linux上hadoop
$HADOOP_HOME/sbin/start-all.sh
2.在Windows上,创建一个文本文件buyer_favorite1,并将上面给出的数据粘贴到buyer_favorite1文件中(要注意文本格式,因为MapReduce是按行读取的,所以最后一行一定不要有空格)。
3、在DFS Location中创建目录

右击,将文件上传至testhdfs1026/run/input中,此时在50070界面上是可以查看到的。

4、新建MapReduce项目,名字为mapreduce1,创建包Mapreduce,类WordCount
5、将以下代码复制进去
package mapreduce; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://192.168.57.128:9000/testhdfs1026/run/input/buyer_favorite1.txt");
Path out = new Path("hdfs://192.168.57.128:9000/testhdfs1026/run/output/buyer_favorite1");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
boolean flag=job.waitForCompletion(true);
System.out.println(flag);
System.exit( flag? 0 : 1);
} public static class doMapper extends Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text(); @Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(), " ");
word.set(tokenizer.nextToken());
context.write(word, one);
}
} public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
6、在WordCount类文件中,单击右键=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中,等待运行。
实验截图:

代码基本构思:
大致思路是将hdfs上的文本作为输入,MapReduce通过InputFormat会将文本进行切片处理,并将每行的首字母相对于文本文件的首地址的偏移量作为输入键值对的key,文本内容作为输入键值对的value,经过在map函数处理,输出中间结果<word,1>的形式,并在reduce函数中完成对每个单词的词频统计。整个程序代码主要包括两部分:Mapper部分和Reducer部分。
Mapper代码
public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{
//第一个Object表示输入key的类型;第二个Text表示输入value的类型;第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException
//抛出异常
{
StringTokenizer tokenizer = new StringTokenizer(value.toString(),"\t");
//StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分
word.set(tokenizer.nextToken());
//返回当前位置到下一个分隔符之间的字符串
context.write(word, one);
//将word存到容器中,记一个数
}
在map函数里有三个参数,前面两个Object key,Text value就是输入的key和value,第三个参数Context context是可以记录输入的key和value。例如context.write(word,one);此外context还会记录map运算的状态。map阶段采用Hadoop的默认的作业输入方式,把输入的value用StringTokenizer()方法截取出的买家id字段设置为key,设置value为1,然后直接输出<key,value>。
Reducer代码
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
//参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
//for循环遍历,将得到的values值累加
result.set(sum);
context.write(key, result);
}
}
map输出的<key,value>先要经过shuffle过程把相同key值的所有value聚集起来形成<key,values>后交给reduce端。reduce端接收到<key,values>之后,将输入的key直接复制给输出的key,用for循环遍历values并求和,求和结果就是key值代表的单词出现的总次,将其设置为value,直接输出<key,value>。
本次测试到此为止,下次带来海量数据的存储统计。
MapReduce处理简单数据的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 在Activity之间传递数据—简单数据/Bundle
1.首先要知道怎么通过一个Activity 打开另一个Activity.主页面为MainActivity,另一个页面为OtherActivity.MainActivity中的按钮Id为btnStart ...
- 【Android Developers Training】 31. 序言:共享简单数据
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对HBase表中数据进行单词统计(TableInputFormat) ...
- 用逗号隔开简单数据保存为csv
用记事本编辑简单数据,用英文逗号隔开,编辑为多列,保存为.csv文件.可以用Excel打开编辑.
- 项目中简单使用ztree,简单数据。
由于公司架构较旧,使用的jdk版本为1.4,页面上也没有el表达式. 加入 js 文件 <% String context = request.getContextPath(); %> & ...
- OLEDB 简单数据查找定位和错误处理
在数据库查询中,我们主要使用的SQL语句,但是之前也说过,SQL语句需要经历解释执行的步骤,这样就会拖慢程序的运行速度,针对一些具体的简单查询,比如根据用户ID从用户表中查询用户具体信息,像这样的简单 ...
- 使用MapReduce将HDFS数据导入Mysql
使用MapReduce将Mysql数据导入HDFS代码链接 将HDFS数据导入Mysql,代码示例 package com.zhen.mysqlToHDFS; import java.io.DataI ...
- 使用MapReduce将mysql数据导入HDFS
package com.zhen.mysqlToHDFS; import java.io.DataInput; import java.io.DataOutput; import java.io.IO ...
随机推荐
- SQL Server 动态创建表结构
需求是,在word里面设计好表结构(主要在word中看起来一目了然,方便维护),然后复制sql 里面,希望动态创建出来 存储表结构的表 CREATE TABLE [dbo].[Sys_CreateTa ...
- 摄像头Camera 标定Calibration原理Theory
摄像头Camera 标定Calibration原理Theory cv2.cameraCalibration Pinhole camera calibration calls camera vision ...
- HarmonyOS系统概述
HarmonyOS系统概述 系统定位 HarmonyOS是一款"面向未来".面向全场景(移动办公.运动健康.社交通信.媒体娱乐等)的分布式操作系统.在传统的单设备系统能力的基础上, ...
- 基于TensorRT车辆实时推理优化
基于TensorRT车辆实时推理优化 Optimizing NVIDIA TensorRT Conversion for Real-time Inference on Autonomous Vehic ...
- NVIDIA DRIVE AGX开发工具包
NVIDIA DRIVE AGX开发工具包 英伟达drive AGX开发工具包提供了开发生产级自主车辆(AV)所需的硬件.软件和示例应用程序.NVIDIA DRIVE AGX系统建立在汽车产品级芯片上 ...
- Python_Selenium之浏览器封装_去掉浏览器受到自动化控制横条显示及去掉是否记住密码弹窗
封装如下: from selenium import webdriverfrom common.config_utils import configfrom selenium.webdriver.ch ...
- 『言善信』Fiddler工具 — 9、Fiddler自动响应器(AutoResponder)详解
目录 1.AutoResponder介绍 2.AutoResponder界面说明 (1)选项: (2)按钮: (3)Rule Editor(规则编辑): (4)test(测试): (5)规则框: 1. ...
- python中json.dump()与json.dumps()的区别
1.将python数据结构转换为json字符串(json.dumps()) >>> import json >>> data={'name':'pipi','age ...
- 从一条sql报错解决过程学习程序员查bug的思路
从oracle迁移数据到达梦后,发现数据库默认值都丢失了.于是我想从oracle数据库将默认值查出来,在达梦数据库加回去. 于是上网查了一下,看怎么获取oracle数据库字段默认值信息,找到了这个sq ...
- vagrant+java+springcloud+redis+zookeeper镜像下载(&制作详解)
文章很长,建议收藏起来,慢慢读! 备注:持续更新中..... 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 + 涨薪必备 疯 ...