Hibernate3 第三天
Hibernate3 第三天
第一天:三个准备、七个步骤
第二天:一级缓存、快照、多对多和一对多的配置
学习内容:
- Hibernate的查询详解(各种检索(fetch)对象的方式)
1)条件查询分类(对象导航检索)。
2)HQL\SQL\QBC的各种查询(基础查询、条件查询、排序、分页、投影查询、统计分组、命名查询、离线查询等)。
- Hibernate的抓取策略(查询优化)
1)延迟抓取和立即抓取策略
类级别的抓取策略
关联集合级别的抓取策略
2)批量抓取策略
学习目标:
- 掌握各种查询
- 掌握常用的抓取策略:懒加载、迫切连接、批量抓取
多表映射回顾和准备查询数据
多表映射回顾
创建Hibernate项目:

构建Hibernate环境:导入jar包、hibernate.cfg.xml、log4j.properties、util工具类。
创建包:cn.itcast.a_onetomany,配置一对多的实体类和hbm映射文件的编写:
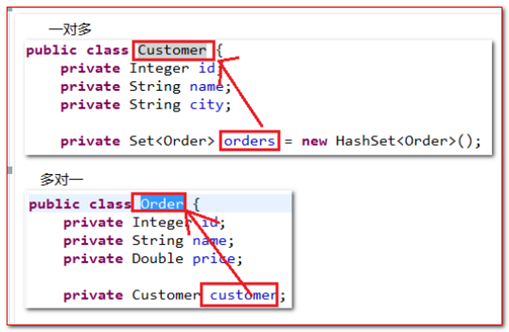
实体类(Customer):
|
package cn.itcast.a_onetomany; import java.util.HashSet; import java.util.Set; public class Customer { private Integer id; private String name; private String city; //集合 //set:无需不重复 //也可以用list:有序重复 //配置hbm.xml的时候,如果类中用的是list集合的话,那边hbm中也可以使用<bag>标签配置集合 //<bag>:有序不重复,但是效率低下 private Set<Order> orders = new HashSet<Order>(); public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getCity() { return city; } public void setCity(String city) { this.city = city; } public Set<Order> getOrders() { return orders; } public void setOrders(Set<Order> orders) { this.orders = orders; } @Override public String toString() { return "Customer [id=" + id + ", name=" + name + ", city=" + city + "]"; } } |
实体类(Order):
|
package cn.itcast.a_onetomany; public class Order { private Integer id; private String name; private Double price; private Customer customer ; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Double getPrice() { return price; } public void setPrice(Double price) { this.price = price; } public Customer getCustomer() { return customer; } public void setCustomer(Customer customer) { this.customer = customer; } @Override public String toString() { return "Order [id=" + id + ", name=" + name + ", price=" + price + "]"; } } |
hbm映射文件:
Customer.hbm.xml
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!-- 配置java类与表之间的对应关系 --> <!-- name:类名:类对应的完整的包路径 table:表名 --> <class name="cn.itcast.a_onetomany.Customer" table="t_customer"> <!-- 主键 --> <id name="id"> <generator class="native"></generator> </id> <property name="name"></property> <property name="city"></property> <set name="orders"> <key column="cid"></key> <one-to-many class="cn.itcast.a_onetomany.Order"/> </set> </class> </hibernate-mapping> |
Order.hbm.xml
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!-- 配置java类与表之间的对应关系 --> <!-- name:类名:类对应的完整的包路径 table:表名 --> <class name="cn.itcast.a_onetomany.Order" table="t_order"> <id name="id"> <generator class="native"></generator> </id> <property name="name"></property> <property name="price"></property> <many-to-one name="customer" class="cn.itcast.a_onetomany.Customer" column="cid"></many-to-one> </class> </hibernate-mapping> |
核心配置文件中引入HBM映射配置:
|
<!-- 在核心配置文件中 引用 mapping 映射文件 --> <mapping resource="cn/itcast/a_onetomany/Customer.hbm.xml"/> <mapping resource="cn/itcast/a_onetomany/Order.hbm.xml"/> |
建表测试是否配置成功:
|
@Test public void createTable(){ HibernateUtils.getSessionFactory(); } |
准备查询数据
批量插入3个客户和相应的订单(共30个)
|
@Test @Test public void prepareData() { Session session = HibernateUtils.openSession(); session.beginTransaction(); //一个客户对应多个订单,一个客户对应10个订单 Customer customer = new Customer(); customer.setName("jack"); customer.setCity("北京"); session.save(customer); for(int i=1;i<=10;i++) { Order o = new Order(); o.setName(customer.getName()+"的订单"+i); o.setPrice(i*10d); o.setCustomer(customer); session.save(o); } session.getTransaction().commit(); session.close(); } |
【扩展】
问题:如果你在大批量的插入数据的时候,可能会报内存溢出的错误!
原因:当save操作的时候,会将瞬时态转换为持久态,对象都放在了session的一级缓存中,如果超大量的数据,会撑爆一级缓存,导致内存溢出。
解决方案:
// 批插入的对象立即写入数据库并释放内存
|
if(i%10000==0){ //刷出到数据库 session.flush(); //清空一级缓存,释放内存 session.clear(); } |
【提示:】
如果真的有大批量(几十万,上百万,上千万)的操作,其实,不太建议用hibernate,直接用jdbc(stmt. executeBatch())
Hibernate的查询详解(各种检索对象的方式)
Hibernate查询数据方式
Hibernate是通过检索对象来查询数据的,下面我们了解一下,Hibernate提供的几种检索对象的方式:
- 对象导航检索方式:根据已经加载的对象导航到其他对象,主要针对关联集合对象的查询。(针对多表)
- OID检索方式:根据对象的OID来检索对象。(单表ById)
- HQL检索方式:使用面向对象的HQL(Hibernate Query Language)查询语言来检索对象,Hibernate底层会自动将HQL转换为SQL。Hibernate自己创建的一套以面向对象的方式操作数据库的查询语句,语法很类似SQL(推荐)
- Native SQL检索方式:本地(原生)SQL检索,使用本地数据库的SQL查询语句来检索对象。
- QBC检索方式:使用完全面向对象的QBC(Query By Criteria)的API来检索对象,该API底层封装了查询语句。
完全不需要懂HQL或者SQL,完全的面向对象的操作方式
其中,前两种属于快捷检索方式,比较简单且常用,当这两种检索方式不能满足需要的时候,就需要使用后面几种检索方式,来自定义检索,如复杂检索条件等等。
后面三种是可代替的,
对象导航检索方式
什么是对象导航检索?
当两个对象之间配置了一对一、一对多或者多对多的关系的时候,可以通过一个对象关联获取到另外一个对象的检索方式
如:Customer和Order对象的对象导航检索:
【示例】创建cn.itcast.b_query,创建类TestQuery,然后进行如下的测试
1).查询某客户信息,并且打印其下所有的订单;
2).查询某订单的信息,并打印其所属客户的信息。
|
@Test public void testNavigate(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //1).查询某客户信息,并且打印其下订单; // Customer customer = (Customer) session.get(Customer.class, 1); // System.out.println(customer); //遍历所有的订单 // for(Order o:customer.getOrders()) // { // System.out.println(o); // } //2).查询某订单的信息,并打印其所属客户的信息。 Order order = (Order) session.get(Order.class, 21); System.out.println(order); System.out.println(order.getCustomer()); session.getTransaction().commit(); session.close(); } |
【提示】
在Hibernate的多表开发中,几乎所有的关联都可以进行双向导航。
【提示2】
报错的原因:在customer的toString 方法中打印了orders集合,在order的toString方法中打印了customer,由于会进行导航,所以导致内存溢出

所以改进:

【注意】
导航检索必须是持久态对象,否则不能导航!
【导航检索的概念扩展】
导航检索就是在查询出某个的PO对象(持久态)后,再访问其关联的集合对象属性的时候,会自动发出SQL,来填充关联属性的所引用的对象。
如:查询客户后,再访问其订单属性的时候,Hibernate会自动发出查询订单的语句,并自动填充订单的值。
【注意】
默认情况下,关联属性是延迟加载的,只有在访问其关联属性的时候才发出SQL从数据库查询,导致查询两张表数据时,至少发出两部分SQL语句,一个是主对象查询语句,一个是关联属性的语句。
其他检索方式基本操作回顾
- OID检索方式:session.get(entity.class,id),session.load(entity.class,id)
- HQL检索方式:session.createQuery(hql).list(),uniqu…
- SQL检索方式(Native Query):session.createSQLQuery(sql).addEntity().list(),
- QBC检索方式:(Query by Criteria):session.createCriteria(Entity.class).list()
HQL支持各种各样的常见查询,和sql语言有点相似,它是Hibernate中使用最广泛的一种检索方式。
- 支持条件查询
- 支持投影查询, 即仅检索出对象的部分属性:用的不会太多(聚合函数sum/avg/count/max/min会使用)
- 支持分页查询
- 支持多表连接查询
- 支持order by
- 支持分组查询, 允许使用 HAVING 和 GROUP BY 关键字
- 内置聚合函数, 如count(), sum(), min() 和 max(),avg()
- 支持自定义函数查询:自定义的 SQL 函数或标准的 SQL 函数
- 支持子查询
- 支持动态注入参数:
- ...
QBC也支持HQL所支持的查询方式,但完全采用面向对象的思想来编程。完整使用详见:

【提示了解】
HQL\QBC和SQL的区别?
HQL\QBC面向类和属性,由hibernate自动生成sql语句,效率低
SQL面向表和字段,你写啥语句,就运行啥语句,不会去组建sql语句,效率高
下面的课程将着重分别研究HQL、SQL、QBC这三种检索方式。
【三种方式的选择】
其中HQL和QBC是Hibernate推荐的检索方式,但性能上会有折扣,而SQL的检索方式虽然效率很高,但不是面向对象的,开发上麻烦一些。
基础查询
【示例】
查询出所有客户信息。
|
@Test public void testQueryAll(){ //查询出所有客户信息 Session session = HibernateUtils.openSession(); session.beginTransaction(); //HQL方式一 // List<Customer> list = session.createQuery("from Customer").list(); //HQL方式二:给对象起别名的方式查询 // List<Customer> list = session.createQuery("select c from Customer c").list(); //请注意:HQL不支持*的查询方式的, // List<Customer> list = session.createQuery("select * from Customer").list(); //SQL //List<Customer> list = session.createSQLQuery("select * from t_customer").addEntity(Customer.class).list(); //QBC:完全的面向对象 Criteria criteria = session.createCriteria(Customer.class); List<Customer> list = criteria.list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
【总结】
1.sql查询的默认结果是List<Object[]>(用数组包装了很多小customer),需要进行实体的绑定,SQLQuery提供了addEntity方法。
2.SQL的语句生成方式:
Hql和sql的方式:语句是可控的,可以自定义的
Qbc:语句是完全由hibernate自己生成。
条件查询
HQL和SQL的查询时的条件值可以直接写死,但是写死的这种方式,几乎不用,现在主要使用匿名参数(占位符?)和命名参数这两种主要方式进行参数注入。
- 匿名参数(?):query.setParameter(索引,参数值)
- 命名参数(:paramname):query.setParameter(命名参数,参数值)
【示例】
查询姓名是rose的客户,只返回rose的一条记录。
|
//查询姓名是rose的客户,只返回rose的一条记录。 @Test public void testQueryByCondition(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql //方式一:写死的方式,几乎不用 // Customer customer = (Customer)session.createQuery("from Customer where name='rose'").uniqueResult(); //方式二:匿名方式:占位符? // Customer customer = (Customer)session.createQuery("from Customer where name = ?") // .setParameter(0, "rose") // .uniqueResult(); //方式三: // Customer customer = (Customer)session.createQuery("from Customer where name = ?") // .setString(0, "rose") // .uniqueResult(); //方式四:命名的方式:注入参数 // Customer customer = (Customer)session.createQuery("from Customer where name = :name") //// .setString("name", "rose") // .setParameter("name", "rose") // .uniqueResult(); //sql //方式一:写死 // Customer customer = (Customer)session.createSQLQuery("select * from t_customer where name ='rose'") // .addEntity(Customer.class)//使用sql,一定不能忘记封装实体 // .uniqueResult(); //方式二:匿名方式:占位符? // Customer customer = (Customer)session.createSQLQuery("select * from t_customer where name = ?") // .addEntity(Customer.class)//必须先封装实体,再注入参数 //// .setString(0, "rose") // .setParameter(0, "rose") // .uniqueResult(); //方式三:命名方式: // Customer customer = (Customer)session.createSQLQuery("select * from t_customer where name = :name") // .addEntity(Customer.class) // .setString("name", "rose") //// .setParameter("name", "rose") // .uniqueResult(); //qbc Criteria criteria = session.createCriteria(Customer.class); //玩命的加条件 criteria.add(Restrictions.eq("name", "rose")); // /继续加条件 criteria.add(Restrictions.like("city", "%上%")); //...继续加条件 //当条件都加完之后, // List<Customer> list = criteria.list();//当结果是0/1条的时候,也可以使用uniqueResult(),任何情况之下,都可以使用list Customer customer = (Customer) criteria.uniqueResult(); System.out.println(customer); session.getTransaction().commit(); session.close(); } |
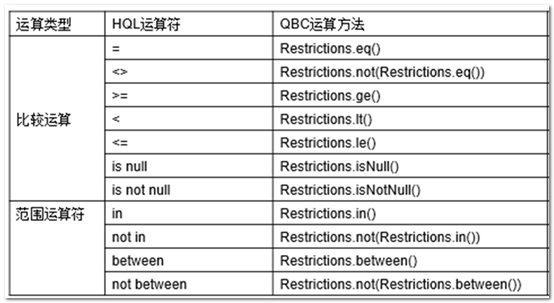
【HQL和QBC支持的各种运算和对应关系】:

排序查询
【示例】
按照id对客户信息进行排序。
|
//按照id对客户信息进行排序。 @Test public void testQueryByOrder(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql :都是面向对象 asc:升序 (默认值) desc:降序 // List<Customer> list = session.createQuery("from Customer order by id desc").list(); //sql // List<Customer> list = session.createSQLQuery("select * from t_customer order by id desc") // .addEntity(Customer.class) // .list(); //qbc List<Customer> list = session.createCriteria(Customer.class) .addOrder(org.hibernate.criterion.Order.desc("id"))//排序 org.hibernate.criterion.Order.desc("id") 降序 .list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
分页查询
【示例】
将订单进行分页查询,每页10条记录,现在需要显示第二页的数据。
|
//将订单进行分页查询,每页10条记录,现在需要显示第二页的数据。 @Test public void testQueryByPage(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //准备两个变量 int page = 2; int pageCount = 10 ; //起始数:hibernate也是从0开始计数,所以起始条数不需要+1 int fromIndex = (page-1)*10; //hql:分页查询方式,适用所有的数据库 // List<Customer> list = session.createQuery("from Order") // //设置起始索引 // .setFirstResult(fromIndex) // //设置每页查询的条数 // .setMaxResults(pageCount) // .list(); //sql:注意区分数据库:mysql的分页使用limit关键,oracle的分页相当复杂 // List list = session.createSQLQuery("select * from t_order limit ?,?") // .addEntity(Order.class) // .setInteger(0, fromIndex) // .setInteger(1, pageCount) // .list(); //qbc List<Order> list = session.createCriteria(Order.class) //起始索引 .setFirstResult(fromIndex) //每页的条数 .setMaxResults(pageCount) .list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
【扩展oracle的sql语句的写法】
|
//oracle:写的技巧:先在sql编辑器中写好,再复制进来改一改就行了。 List<Order> list2 = session.createSQLQuery("SELECT * FROM (SELECT t.*,ROWNUM r FROM t_order t WHERE ROWNUM<="+(firstResult+maxResults)+") t2 WHERE t2.r>="+(firstResult+1)).addEntity(Order.class).list(); System.out.println(list2); |
注意:如果用Hibernate技术,分页推荐使用hql或qbc,因为可以自动适应数据库。
投影查询(用的并不多,了解)
什么是投影查询?
投影查询就是查询结果仅包含实体的部分属性,即只查询表中的部分指定字段的值,不查询全部。如:
select t.a,t.b,t.c from t;或者select count(*) from table; (是一种特殊的投影查询)
投影的实现:
- HQL和SQL中可以通过SELECT关键字实现。
- QBC中,需要通过criteria.setProjection(投影列表)方法实现,投影列表通过add方法添加:Projections.projectionList().add(Property.forName("id"))。
criteria.setProjection(需要查询的属性)
【示例】
查询客户的id和姓名。
|
//查询客户的id和姓名。 @Test public void testQueryByProjection(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql:投影查询返回是一个数组,不在一个是封装好的对象, //在hibernate中,如果返回的是Object[]的话,那么这个对象是不会存在于一级缓存的, // 是一个非受管对象(不受session管理) //List集合的长度是3: // 0 [1,'rose'] // 1 [2,'lucy'] // 2 [3,'jack'] // List<Object[]> list = session.createQuery("select c.id,c.name from Customer c").list(); //适用hql投影查询的结果可以封装成一个对象,但是还是一个非受管对象 //步奏 //1 去po中添加构造方法:空参构造+带参构造 //2 重新编写hql语句 // List<Customer> list = session.createQuery("select new Customer(c.id,c.name) from Customer c").list(); //sql // List<Object[]> list = session.createSQLQuery("select id,name from t_customer").list(); //qbc List<Object[]> list = session.createCriteria(Customer.class) //设置投影,参数就是需要投影的属性 .setProjection( //投影可能需要投影多个列,所以将多个列加入list集合,list集合是有序的 Projections.projectionList() //向projectionList中添加需要查询的列 .add(Property.forName("id")) .add(Property.forName("name")) //疯狂的追加投影的列 ).list(); for(Object[] obj:list) { System.out.println(obj[0]+":"+obj[1]); } // System.out.println(list); session.getTransaction().commit(); session.close(); } |
【注意】
经过投影查询的结果,默认都不会封装到实体类型中,而是根据实际查询的结果自动封装(object[]),如查询id和name,返回的object[]的list集合。
最大的坏处:一级缓存不存放该对象。无法使用hibernate的一些特性,比如快照等等。
【注意】查询之后封装到Object[]数组中的这些数据,称之为散装数据,不会存放于一级缓存,所以未来需要用的时候,还要查询,尽量少用
【应用提示】
实际hibernate开发中,一般较少使用投影查询(除了统计).一般我们都查询出所有字段,让其自动封装到实体类中就行了.
【扩展阅读】(了解)
投影查询也可以封装到实体类中。(感兴趣的同学可查看课后文档)

实体类:

qbc:

.setResultTransformer(Transformers.aliasToBean(Customer.class))
最终代码:
|
//查询用户的id和姓名。 @Test //投影查询:只查询部分属性的值 public void queryByProjection(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql //结果集是根据返回的数据,自动封装为Object[],没有封装为实体对象 // List<Object[]> list = session.createQuery("select id,name from Customer").list(); //如果要封装为实体对象,需要提供一个投影属性的构造方法,不会再调用默认的构造器 //尽管被封装为实体对象,但该对象,是个非受管对象。不是被session管理 // List list = session.createQuery("select new Customer(id,name) from Customer").list(); // System.out.println(list); // for (Object[] obj : list) { // System.out.println(obj[1]); // } //sql //结果集也是根据返回的数据的结果自动封装为Object[] List list2 = session.createSQLQuery("select id,name from t_customer") //设置结果集封装策略 //类似于dbutil中的beanhandler,自动通过反射机制,自动将结果集封装到指定的类型中 // .setResultTransformer(new AliasToBeanResultTransformer(Customer.class)) //官方提供了一个工具类,简化代码编写 .setResultTransformer(Transformers.aliasToBean(Customer.class)) .list(); // ResultTransformer System.out.println(list2); //qbc List list3 = session.createCriteria(Customer.class) //设置投影列表 .setProjection(Projections.projectionList() //给属性起别名 .add(Property.forName("id").as("id")) .add(Property.forName("name").as("name"))) //添加结果集的封装策略 //发现了,该结果集封装策略,是根据字段的别名来自动封装 //解决方案:增加别名 .setResultTransformer(Transformers.aliasToBean(Customer.class)) .list(); // Projection // Property System.out.println(list3); session.getTransaction().commit(); session.close(); } |
小结:hibernate开发的情况下,一般,不使用投影。,因为查询出来的对象不被hibernate管理,它是是一个非受管对象。
无法使用到hibernate的一些特性,比如快照更新等。
还有一种情况,必须使用投影!统计的时候!(即使是统计的时候,投影也不是唯一的查询方式)
举例:查询customer#2的订单数量:customer.getOrders().size();
统计分组(特殊的投影查询,用得比较多)
统计是一种特殊的投影查询,所以结果也无法封装到实体,而是直接返回了统计后的结果值。
实现方式:
HQL和SQL使用统计函数/聚合函数,如下几种:
- count()
- min()
- max()
- sum()
- avg()
QBC统计时是在投影方法参数中,使用Projections.rowCount()或者Projections.count(字段名)
sql语句中:
Count(*)
count(birthday):如果birthday=null,就不会作为总的结果
【示例】
查询客户的总数
|
//查询客户的总数 @Test public void testQueryByCount(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql:hql返回的结果集类型是Long // Object result = session.createQuery("select count(c) from Customer c").uniqueResult(); // long result = (Long) session.createQuery("select count(c) from Customer c").uniqueResult(); //sql:返回是BigInteger // Object result = session.createSQLQuery("select count(*) from t_customer").uniqueResult(); // BigInteger result = (BigInteger) session.createSQLQuery("select count(*) from t_customer").uniqueResult(); //qbc:返回Long类型 Object result = session.createCriteria(Customer.class) //rowCount:读取所有的行数 // .setProjection(Projections.rowCount()) //读取指定列的行数 ,这种读取方式,当city为null的时候,就不算一条记录 .setProjection(Projections.count("city")) .uniqueResult(); System.out.println(result); session.getTransaction().commit(); session.close(); } |
【提示】
如果数据库是oracle的话,sql方式返回的是BigDecimal
7 阶段综合小练习
【示例】
查询一下客户编号为1的客户的订单数量,要求只统计订单的金额要大于等于30。(提示:综合了条件查询和统计查询(投影))
|
@Test public void testPractise(){ //查询一下客户编号为1的客户的订单数量,要求只统计订单的金额要大于等于30 Session session = HibernateUtils.openSession(); session.beginTransaction(); // HQL:面向对象的查询方式 // Object result = session.createQuery("select count(o) from Order o where o.price>=? and o.customer.id = ? ") // .setParameter(0, 30d) // .setParameter(1, 1) // .uniqueResult(); //不用投影,不用统计查询 // int result = session.createQuery("from Order o where o.price>=? and o.customer.id = ? ") // .setParameter(0, 30d) // .setParameter(1, 1) // .list().size(); // SQL // Object result = session.createSQLQuery("select count(*) from t_order where price >=? and cid = ?") // .setParameter(0, 30d) // .setParameter(1, 1) // .uniqueResult(); // QBC:完全的面向对象的方式操作数据库 Customer customer = new Customer(); customer.setId(1); //不采用投影的方式 // int result = session.createCriteria(Order.class) // .add(Restrictions.ge("price", 30d)) // .add(Restrictions.eq("customer", customer)) // .list().size(); //采用投影的方式 Object result = session.createCriteria(Order.class) .add(Restrictions.ge("price", 30d))//设置条件 .add(Restrictions.eq("customer", customer))//设置条件 .setProjection(Projections.rowCount())//投影:只要统计结果的行数 .uniqueResult(); System.out.println(result); session.getTransaction().commit(); session.close(); } |
命名查询(了解)
什么是命名查询?
命名查询(NamedQuery),是指将sql或hql语句写入配置文件中,为该语句起个名字,在程序中通过名字来访问sql或hql语句。
优点:便于维护。
命名查询的实现步骤:
第一步:在hbm中配置命名查询的名字和语句(支持HQL或SQL)。
第二步:在程序中通过session.getNamedQuery(命名查询的名字)来直接获取Query或SQLQuery对象,进而进行查询操作。
【示例】
查询客户的所有信息
Xml中的配置:
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!-- 配置java类与表之间的对应关系 --> <!-- name:类名:类对应的完整的包路径 table:表名 --> <class name="cn.itcast.a_onetomany.Customer" table="t_customer"> <!-- 配置主键 name:java类中的属性 column:表中的字段,列名,当name和column一致的时候,column可以省略 --> <id name="id" column="id"> <!-- 主键生成策略 mysql的自增长:identity --> <generator class="native"></generator> </id> <!-- 其他属性 name:java中的属性 column:表中字段名 当name和column一致的时候,column可以省略 --> <property name="name" column="name"></property> <!-- age :--> <property name="city"></property> <!-- 配置集合 --> <set name="orders"> <!-- column:外键 --> <key column="cid"></key> <!-- 配置关系 class:集合中装载对象的原型 --> <one-to-many class="cn.itcast.a_onetomany.Order"/> </set> <!-- hql :注意语句结束不能加";",否则报错--> <query name="query1"> from Customer </query> <!-- sql --> <sql-query name="query2"> select * from t_customer </sql-query> </class> <!-- name尽量具有实际意义 --> <!-- hql :注意语句结束不能加";",否则报错--> <query name="Customer.hql.queryall"> from Customer </query> <!-- sql --> <sql-query name="Customer.sql.queryall"> select * from t_customer </sql-query> </hibernate-mapping> |
testNameQuery方法的编写:
|
@Test public void testNamedQuery(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql //写在class里面,得通过包路径调用 // List<Customer> list = session.getNamedQuery("cn.itcast.a_onetomany.Customer.query1").list(); //写在class外面,就直接通过name调用 // List<Customer> list = session.getNamedQuery("query3").list(); //sql //class里面 // SQLQuery sqlQuery = (SQLQuery) session.getNamedQuery("cn.itcast.a_onetomany.Customer.query2"); // List<Customer> list = sqlQuery.addEntity(Customer.class).list(); //写在class外面 List<Customer> list = ((SQLQuery)session.getNamedQuery("query4")).addEntity(Customer.class).list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
【提示】
命名查询写在<class>元素的内外是有区别的:
- 如果写在class内部,则需要通过"完整的类名.查询的命名"执行。
- 如果写在class外面,则尽量将命名规范一些,通常在命名前面加上PO的类名。
离线查询DetachedCriteria(重点掌握)
业务开发场景(阅读):
在项目中:CRUD操作,查询使用量最多,在实际中,都是根据条件查询
条件不一样,那么我们后台是不是要写很多查询方法
根据城市查询:queryByCity
根据用户名查询:queryByName
根据年龄查询:queryByAge
-----dao中方法很重复
离线查询:他允许在业务层(service)去拼装条件,然后直接将条件传入dao层的方法,运行,
这时候,dao层只需要一个方法,就可以完成查询
|
在常规的Web编程中,有大量的动态条件查询,即用户在网页上面自由选择某些条件,程序根据用户的选择条件,动态生成SQL语句,进行查询。 针对这种需求,对于分层应用程序来说,Web层需要传递一个查询的条件列表给业务层对象,业务层对象获得这个条件列表之后,然后依次取出条件,构造查询语句。这里的一个难点是条件列表用什么来构造?传统上使用Map,但是这种方式缺陷很大,Map可以传递的信息非常有限,只能传递name和value,无法传递究竟要做怎样的条件运算,究竟是大于,小于,like,还是其它的什么,业务层对象必须确切掌握每条entry的隐含条件。因此一旦隐含条件改变,业务层对象的查询构造算法必须相应修改,但是这种查询条件的改变是隐式约定的,而不是程序代码约束的,因此非常容易出错。
DetachedCriteria可以解决这个问题,即在web层,程序员使用DetachedCriteria来构造查询条件,然后将这个DetachedCriteria作为方法调用参数传递给业务层对象。而业务层对象获得DetachedCriteria之后,可以在session范围内直接构造Criteria,进行查询。就此, WEB层只需要添加条件,不需要考虑查询语句如何编写,而业务层则只负责完成持久化和查询的封装即可,与查询条件构造完全解耦,非常完美! 最大的意义在于,业务层或dao层代码是固定不变的,所有查询条件的构造都在web层完成,业务层只负责在session内执行之。这样代码就可放之四海而皆准,都无须修改了。 |

【区别】:
Criteria:在线查询方式:依赖session,有了session之后,才能去创建Criteria对象,然后才可以添加条件
DetachedCriteria:离线查询方式:不依赖session创建,自身内部含有创建方式,可以在没有session的情况下,自由的组装各种条件,
然后在发送给session执行
API的查看:


通过API分析,得到编程关键点:
DetachedCriteria是Criteria的子实现,通过静态方法DetachedCriteria.forClass(PO.class)来实例化,它可以像Criteria的对象一样增加各种查询条件,通过detachedCriteria.getExecutableCriteria(session)方法与session关联,变成在线Criteria对象,最后通过criteria.list()方法得到数据。
【示例】
查询id值大等于2且城市是杭州的客户信息。
|
@Test public void testDetachedCriteria(){ //查询id值大等于2且城市是杭州的客户信息。 //模拟service层 DetachedCriteria detachedCriteria = DetachedCriteria.forClass(Customer.class); //拼命的加条件 // detachedCriteria.add(Restrictions.ge("id", 2)); // detachedCriteria.add(Restrictions.eq("city", "杭州")); //查询名字带有c的人员的信息 detachedCriteria.add(Restrictions.like("name", "%c%")); //模拟dao层:dao层就固定写法 Session session = HibernateUtils.openSession(); session.beginTransaction(); //执行离线查询,传入session Criteria criteria = detachedCriteria.getExecutableCriteria(session); List<Customer> list = criteria.list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
【Criteria和DetachedCriteria的区别】
Criteria和DetachedCriteria 的主要区别在于创建的形式不一样, Criteria 是在线的,所以它是由 Hibernate Session 进行创建的;而 DetachedCriteria 是离线的,创建时无需Session,DetachedCriteria 提供了 2 个静态方法 forClass(Class) 或 forEntityName(Name)进行DetachedCriteria 实例的创建。使用getExecutableCriteria(session)方法转换成在线可执行的Criteria
多表关联(连接)查询
数据库中多表关联查询的回顾
多表关联的分类:
- 内连接查询:等值、不等值
- 外连接查询:左外、右外、全外(不是所有的数据库都支持,mysql不支持、oracle支持)
- 自连接查询:相当于将一张表当成N张表来用
三种连接方式的sql语句和结果:

|
[内连接]: select * from customer t1, order t2 where t1.id=t2.customer_id;--并不是标准-隐式的内连接 select * from customer t1 inner join order t2 on t1.id=t2.customer_id;--sql99标准语法-显示内连接 查询结果: 1 Rose 1001 电视机 1 [左外连接]:以左表为基表,右表来关联左表,如果右表没有与左表匹配的数据,则右表显示null select * from customer t1 left outer join order t2 on t1.id =t2.customer_id;//左外连接 查询结果: 1 Rose 1001 电视机 1 2 Jack null null null [右连接] select * from customer t1 right join order t2 on t1.id=t2.customer_id;//右连接 查询结果: 1 Rose 1001 电视机 1 null null 1002 空调 null |

|
#内连接:项目中使用最多的连接方式 #方式一:表连接的工作就是先进性笛卡尔乘积,然后在筛选 SELECT c.*,o.* FROM t_customer c,t_order o WHERE c.id=o.cid; #方式二 SELECT c.* ,o.* FROM t_customer c INNER JOIN t_order o ON c.id = o.cid; # 左外连接(左连接):以左表为基表,右表来匹配左表,左表数据全部显示,当右表没有与之匹配的数据的时候,直接用null代替 SELECT c.*,o.* FROM t_customer c LEFT JOIN t_order o ON c.id = o.cid; #左连接实际应用场景:查询从来没有买过东西的客户信息 SELECT c.*,o.* FROM t_customer c LEFT JOIN t_order o ON c.id = o.cid WHERE o.id IS NULL; # 右外连接(右连接):以右表为基表,左表来匹配右表,右表数据全部显示,当左表没有与之匹配的数据的时候,直接用null代替 SELECT o.*,c.* FROM t_order o RIGHT JOIN t_customer c ON c.id = o.cid; |
Hibernate的多表连接的查询方式(了解++)

【提示】
HQL支持普通连接(内连接、左外连接),但也支持迫切连接(迫切内连接、迫切左外连接)。
QBC和SQL都只支持普通连接(内连接、左外连接)。
【学习目标提醒】
主要目标是学习连接和迫切连接的异同。
回顾导航查询的缺点:
会先查询主po对象,发出一条语句,再访问关联属性的时候,再发出一条语句,需要两次查询。
如果,我想一次性拿到客户和关联的订单,我就可以使用多表关联查询。仅使用一条sql语句,就可以得到两个表(对象)的数据,效率比两次查询高!
HQL
【示例】
查询所有客户信息和对应的所有订单信息,要求一条语句就将两张表的结果查询出来(提示:内连接或迫切内连接)。
|
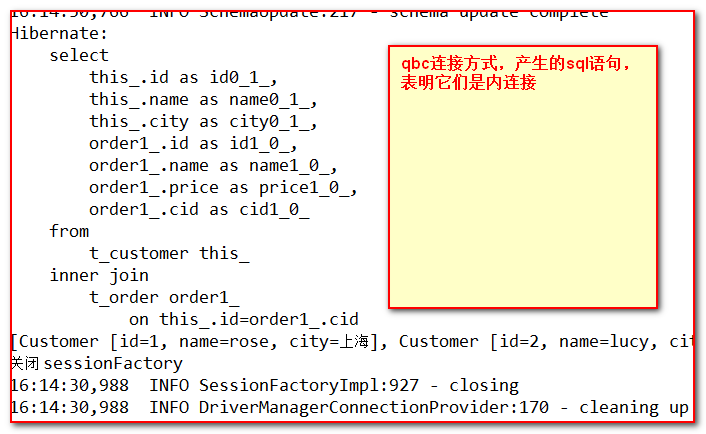
//查询所有客户信息和对应的所有订单信息,要求一条语句就将两张表的结果查询出来 @Test public void testQueryForManyTable(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); // HQL:采用HQL进行连接,不需要加条件,因为条件已经在hbm.xml中定义好了 //内连接返回的是数组对象 (数组是一种散装对象,不会存入session缓存,不具备快照特性) // List list = session.createQuery("from Customer c inner join c.orders").list(); //迫切连接将返回的结果封装为实体对象 // List<Customer> list = session.createQuery("from Customer c inner join fetch c.orders").list(); //通过观察,我们发现,结果重复,接下来去除重复:滤重 //distinct:去处重复的关键字(hibernate,mysql和oracle都用这个关键字去重) List<Customer> list = session.createQuery("select distinct(c) from Customer c inner join fetch c.orders").list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
【结果】
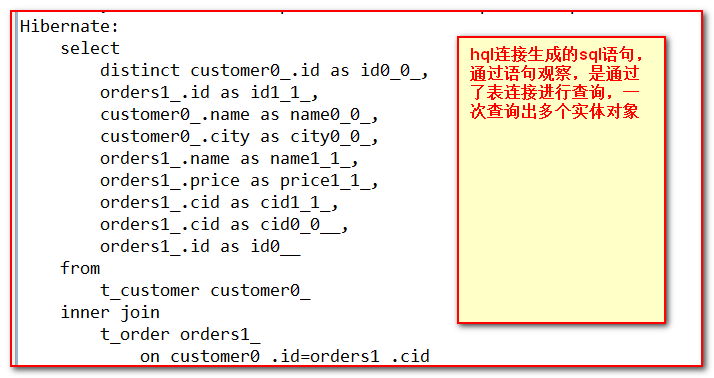
【分析内连接和迫切内连接的异同】
- 相同点:都是只需要发出一条SQL就可以将两个表的数据一次性查询出来。
- 不同点:返回的结果的默认封装方式不同:
- 内连接将结果封装为List<Object[]>,Object[]中再封装了实体对象。非受管对象。
- 迫切内连接将结果封装为List<主表的实体>,这里是List<Customer>,其从表数据被封装到主表实体中的关联属性中了。而且是受管对象
【扩展了解】
和SQL语句一样,内连接或迫切内连接的语句中的inner关键字可以省略。
【问题】
迫切内连接返回的结果是重复的,可使用distinct关键字滤重。
【示例】
一次性查询出所有客户信息以及其所下的订单的信息,要求结果被封装到客户的实体对象中,并且返回的对象不要重复。
|
List<Customer> list13 = session.createQuery("select distinct (c) from Customer c join fetch c.orders").list(); |
【提示】
如果要用迫切连接查询的话,结果需要去除重复的。
左外连接(左连接)和迫切左外连接:
|
//左外连接:返回的结果是一个Object[]的数组对象 // List list15 = session.createQuery("from Customer c left join c.orders").list(); //迫切左外连接:返回的结果是一个封装好的Customer对象 List list15 = session.createQuery("select distinct c from Customer c left join fetch c.orders").list(); System.out.println(list15); |
SQL
【示例】封装之后的数据,只能是Object[]类型的数组,是一个非受管对象
一次性查询出客户信息和其下的订单信息。(提示:无法实现实体的完全封装)
|
//内连接--没有迫切一说 //sql //普通的内连接 List list = session.createSQLQuery("select * from t_customer t1 inner join t_order t2 on t1.id =t2.cid") // .addEntity(Customer.class)//封装到实体 .addEntity(Order.class)//封装到实体,发现封装后会丢失数据 .list(); |
【提示:】
SQL只有内连接查询,没有迫切内连接查询。因此,无法实现一次性将主对象和关联对象一次性查询出来的需求。
QBC
Criteria接口提供createCriteria和createAlias两组方法用于完成多表关联查询
- createCriteria(String associationPath) 采用内连接关联 (返回新的Criteria对象)
- createCriteria(String associationPath, int joinType) 可以通过joinType指定关联类型 (返回新的Criteria对象 )
- createAlias(String associationPath, String alias) 采用内连接关联
- createAlias(String associationPath, String alias, int joinType) 可以通过joinType 指定连接类型
提示:qbc没有迫切查询
QBC采用createCriteria()非常容易的在互相关联的实体间建立连接关系。

从名字上看,貌似是创建一个子的creaiteria,但是生成的语句可以是内连接或左连接的.
【示例】
一次性查询出所有用户及其所下的订单信息。
一次性查询出某用户(id=1)所下订单的信息,并且要求订单价格大于50元。
|
//一次性查询出所有用户及其所下的订单信息。 @Test public void testQueryForManyTableByCriteria1(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //主查询 Criteria criteria = session.createCriteria(Customer.class); //连接对象:默认是内连接 criteria.createCriteria("orders"); // 由于查询结果是重复的,所以在list方法执行之前一定要滤重, //设置重复结果过滤 criteria.setResultTransformer(Criteria.DISTINCT_ROOT_ENTITY); //进行查询 //返回的结果到底封装成什么类型,主要看主查询的参数 List<Customer> list = criteria.list(); System.out.println(list); session.getTransaction().commit(); session.close(); } //一次性查询出某用户(id=1)所下订单的信息,并且要求订单价格大于50元。 @Test public void testQueryForManyTableByCriteria2(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //主查询:订单 Criteria criteria = session.createCriteria(Order.class); // /添加条件 criteria.add(Restrictions.gt("price", 50d)); //子查询:默认是内连接 Criteria childCriteria = criteria.createCriteria("customer"); //添加条件 childCriteria.add(Restrictions.eq("id", 1)); //执行查询 List<Order> list = criteria.list(); System.out.println(list); session.getTransaction().commit(); session.close(); } |
【控制台结果】
【QBC的优势】
条件越多,编码起来相对越简单一些,只需要在criteria上加条件即可,而不需要关心语句该怎么写。
[扩展:更改qbc的结果集的重复封装的问题]

查询小结
查询方式的选择
Hibernate推荐使用HQL和QBC,两者区别:

但企业开发中,如果为了sql语句的性能,会直接采用SQL进行开发。如果为了封装方便(比如离线查询条件封装),也会采用QBC。具体根据项目架构来决定。
Query功能的扩展--了解
但是这不是Query主要职责,他的只要职责还是查询,而且他做增加的时候,还有缺陷:
它不能执行 insert into table(,,,) values(,,)
只支持INSERT INTO ... SELECT ...形式
Query接口也可以接受insert、update、delete语句的执行。
|
//Query也可以执行insert,update,delete //场景,不根据id来更新,不根据id删除,想创建一张表 @Test //query对象的使用扩展 public void queryObjExtend(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //hql //根据名称更新客户->query不止是可以查询,也可以执行任何的语句 //该方法更新,不走一级缓存,直接操作数据库了,相当于以前connection了 // Query query = session.createQuery("update Customer set city='海南岛' where name='xiaohong'"); // //执行query // int count = query.executeUpdate(); // System.out.println(count); //sql session.createSQLQuery("create table t_test (name varchar(30))").executeUpdate(); session.getTransaction().commit(); session.close(); } |
但insert只支持:hql 只支持INSERT INTO ... SELECT ...形式, 不支持INSERT INTO ... VALUES ...形式.
原理是:query还是以查询为基础的
Hibernate的抓取策略(查询优化)
抓取策略的概念和分类
抓取策略的官方定义:

简单的说:Hibernate抓取策略(fetching strategy)是指:在检索一个对象,或者在对持久态对象通过对象导航方式来获取关联对象属性的数据时,Hibernate的相关检索策略。抓取策略可以在hbm映射文件中配置声明,也可以在HQL语句中进行覆盖(即前面写的迫切左外语句,缺点代码耦合太强,可配置性差)。
根据数据的抓取方式分为:
- 延迟抓取和立即抓取策略
- 类级别的抓取策略:针对查询对象本身的抓取策略
- 关联属性级别的抓取策略:针对通过对象导航访问关联属性的抓取策略
- 批量抓取策略
类级别抓取策略
类级别的抓取策略就两种:立即检索和延迟检索
立即检索和延迟检索
立即检索:get(第二次查询会从一级缓存中查询),createQuery(hql).list(每次都查询,每次都发查询语句)
延迟检索:load(第二次查询会从一级缓存中查询)
创建包cn.itcast.c_fetchingstrategy,创建类TestStrategy,然后测试
|
//加载customer信息 //get:默认立即加载 Customer c1 = (Customer)session.get(Customer.class, 1); System.out.println(c1); //load:默认延迟加载 Customer c2 = (Customer)session.load(Customer.class, 2); System.out.println(c2); |
load默认返回目标类的代理对象的子类对象,没有发送sql(即没有初始化),只有当访问的时候才初始化。
类级别抓取策略的配置
load延迟加载是否可以改变呢?
通过hbm文件的<class>元素的lazy属性进行设置(默认值是true)

再次测试上面的例子。
发现load也变成立即加载了。

结论:lazy=false的时候,类采用立即加载策略,load和get效果一样了。
关于代理对象的初始化的时机—了解
情况一:当访问代理对象id之外的属性的时候
|
//load:默认延迟加载,何时被初始化呢? Customer c2 = (Customer)session.load(Customer.class, 2); System.out.println(c2.getId());//访问id的时候不会初始化 System.out.println(c2);//当访问其他属性的时候,自动初始化 |
情况二:使用Hibernate工具类的initialize方法强制初始化代理对象--了解
|
Customer c2 = (Customer)session.load(Customer.class, 2); Hibernate.initialize(c2);//强制初始化 |
小结:如果真要用强制初始化。,那还不如直接用get进行查询
当访问对象的延迟加载时,底层也是调用Hibernate工具类的initialize方法
使用HQL覆盖配置的检索策略
如果使用HQL进行查询,即使配置了延迟加载,也无效
【示例】
采用createQuery查询一个对象,无懒加载特点。(即使配置了懒加载也无效)
|
Customer c3=(Customer)session.createQuery("from Customer where id =2").uniqueResult(); System.out.println(c3); |
【提示】
这里可以看出,Query对象的查询都是立即加载,并立即发出用户定义好的SQL,而且一定会发出(不从一级缓存中获取)。
HQL的两个特点:立刻加载 ; 不走一级缓存
关联级别的抓取策略--set集合的抓取策略
检索策略
【解释说明】在一对多的关系中,在一方,配置了集合,我们研究集合的初始化的时机,在默认情况下,集合在你需要使用的时候,才会初始化,不使用,就不会初始化。当然,对于这个默认的结果,是可以改变的,如何改变呢?
主要使用:
<set> 元素提供fetch属性和lazy属性 用于设置 集合 抓取策略
关于fetch和lazy的作用:

语言精简一下,记住:
fetch是控制sql语句的生成方式,(1 表连接、2 子查询、3需要的时候查询)
lazy是控制数据初始化的时间。
一对多或多对多方向关联的检索策略表: (配置在set标签上的)

【提示】
经过分析发现Fetch:属性的值有3个,Lazy属性的值也有3个,这两个属性是要同时配置的,有9种组合。
为方便学习,我们将根据fetch的值的情况,将其分为三类组合:
- Select+true/false/extra延迟加载(默认值:)select +extra加强延迟---3
- join+false/true立即左联,效率高.(相对于子查询)--1
- Subselect 一般不用,原因,使用了子查询,效率很低.
检索策略(strategy)配置
第一类组合:
|
fetch |
语句形式 |
lazy |
数据初始化的时间 |
|
select |
多条简单SQL语句 |
true |
延迟加载(默认值) |
|
false |
立即加载 |
||
|
extra |
增强的延迟加载(极其懒惰) |
lazy=extra的说明:当程序调用orders 属性的 size(), contains() 和 isEmpty() 方法时, Hibernate 不会初始化orders集合类中所有子对象的实例,
仅通过特定的 select 语句查询必要的信息, 不会检索所有的 Order 对象。
设置方法:
在采用<one-to-many>元素的父元素(如set)中设置fetch和lazy属性的值。
在customer.hbm.xml中设置一下默认属性的值:

【测试示例代码】
|
@Test public void testFetchAndLazy(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer customer = (Customer)session.get(Customer.class, 1); System.out.println(customer.getOrders().size()); session.getTransaction().commit(); session.close(); } |
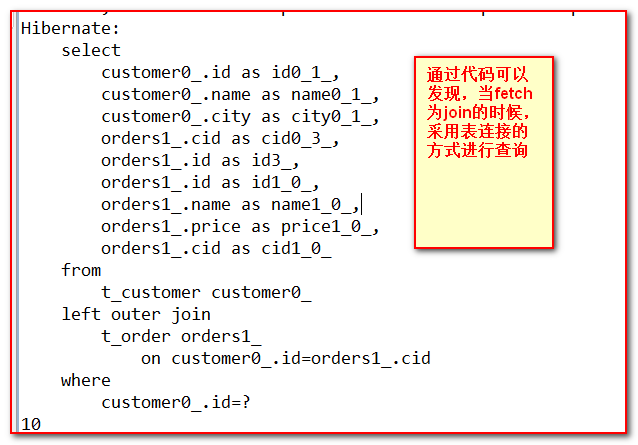
第二类组合:
|
fetch |
语句形式 |
lazy |
数据初始化的时间 |
|
join |
迫切左外连接SQL语句 |
true |
全部忽略失效。 |
|
false |
|||
|
extra |
【进一步】
通过策略列表发现,只要是fetch是join就是迫切左外连接,而迫切左外连接就会立即加载其属性, lazy属性被忽略. (如Customer left join fetch orders立即查询客户和订单数据)
【示例】
|
@Test public void testFetchAndLazy(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer customer = (Customer)session.get(Customer.class, 1); System.out.println(customer.getOrders().size()); session.getTransaction().commit(); session.close(); } 控制打印的语句:
|

第三种组合:(了解)
|
fetch |
语句形式 |
lazy |
数据初始化的时间 |
|
subselect |
子查询的sql语句(效率偏低,一般不采用) |
true |
全部忽略失效。 |
|
subselect |
【示例】
|
List<Customer> list = session.createQuery("from Customer").list(); for (Customer customer : list) { System.out.println(customer.getOrders().size()); } |
使用HQL覆盖配置的检索策略
使用createQuery自定义HQL查询语句时,fetch就会被直接忽略(失效),而lazy会根据语句的编写情况可以有效,也可以无效。
也就是说,语句的格式已经定死了,fetch无法改变了,就会失效。而语句如果是采用多表连接查询,那么lazy也会无效;但如果语句只是查询一个对象,那么其关联属性的lazy依然有效(因为是一般的导航查询)
采用HQL的时候,fetch直接失效
Lazy看情况:当hql语句只是查询单个简单的对象,lazy依然有效
当hql是进行多表查询的时候,lazy也会失效
【示例】
|
//fetch肯定是失效,lazy有效 session.createQuery("from Customer"); //fetch和lazy都失效 session.createQuery("from Customer c inner join c.orders"); |
【总结】

关联级别的抓取策略--单个对象的抓取策略
多对一抓取策略:通过多的一方(Order)来导航查询一的一方(Customer)的策略。
抓取一方的时机
检索策略
关系元素(<many-to-one>)中提供fetch属性和lazy属性 用于设置 抓取策略,如:
在Order.hbm.xml <many-to-one>中配置。
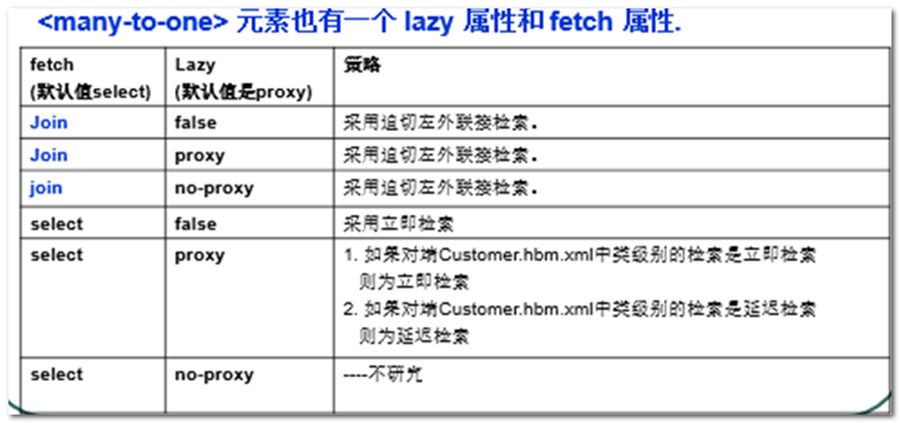
我们将根据fetch的值的情况,将其分为两类组合:
- select + proxy/false 简单sql,延迟或立即加载
- join+proxy/no-proxy/false 迫切左外连接
检索策略配置
【测试示例】
查询某订单,并且要显示其所属的客户信息。
分析:查询主体是订单
|
号订单,并且要显示其所属的客户信息。 Order o =(Order)session.get(Order.class, 1); System.out.println(o); System.out.println(o.getCustomer()); |
第一类组合:
|
fetch |
语句形式 |
lazy |
数据初始化的时间 |
|
select |
多条简单SQL语句 |
Proxy (分情况讨论) |
根据关联对象的类级别抓取策略来决定是否延迟加载(默认值) <class name="..Customer" lazy=true >:延迟加载 <class name="..Customer" lazy=false>:立即加载 |
|
false |
立即加载 |
第二类组合:
|
fetch |
语句形式 |
lazy |
数据初始化的时间 |
|
join |
迫切左外连接SQL语句 |
proxy |
全部忽略失效。 |
|
false |
【示例】
|
@Test public void testFetchAndLazy_manyToOne(){ //查询某订单,并且要显示其所属的客户信息。 Session session = HibernateUtils.openSession(); session.beginTransaction(); Order order = (Order) session.get(Order.class, 1); System.out.println(order); System.out.println(order.getCustomer()); session.getTransaction().commit(); session.close(); } |

使用HQL覆盖配置的检索策略
使用createQuery自定义HQL查询语句时,fetch就会被直接忽略(失效),而lazy会根据语句的编写情况可以有效,也可以无效。
也就是说,语句的格式已经定死了,fetch无法改变了,就会失效。而语句如果是采用多表连接查询,那么lazy也会无效;但如果语句只是查询一个对象,那么其关联属性的lazy依然有效(因为是一般的导航查询)
【示例】
如果采用Query查询,不会自动生成左外连接(query是自己写的语句),fetch=join 被忽略,lazy可以生效
|
//fetch无效,lazy有效 session.createQuery("from Order where id = 1"); //fetch和lazy都无效 session.createQuery("from Order o inner join o.customer"); |
【总结】当使用HQL的时候,很多的配置会直接失效

抓取策略的小结
区分类级别延迟和关联级别的延迟
- 类级别:设置load的加载策略,lazy属性:true和false ,只有load受影响
- 关联级别:在已经获取的持久对象的基础上,通过对象导航访问其关联属性的对象的加载策略,如customer.getOrders().size()
抓取策略的设置方法和相关内容回顾
1.设置类级别抓取策略 ,可以通过修改 hbm文件 <class>元素 lazy属性来实现,值可以是:true延迟,false 立即:
- get方法采用立即抓取
- load方法,根据类级别抓取策略配置,使用立即或者延迟抓取(默认 延迟抓取)
- session.createQuery(hql).list() ,采用立即抓取策略 ,如:

2.设置关联级别抓取策略:
- 一对多 和 多对多 (set集合上设置),hbm使用 <set>元素, 提供 lazy(true,false)属性和fetch(select join)属性 ,用来配置抓取策略
- 多对一 和 一对一(在关系上面设置), hbm采用 <many-to-one> 元素,提供lazy(false,proxy)属性和fetch(select ,join)属性,用来配置抓取策略
延迟抓取策略的作用
延迟加载的好处是:没有立即加载数据,当需要的时候再加载,提高了内存的使用率,优化了程序的效率!
因此,在一般情况下,能延迟加载的尽量延迟,默认情况下都是延迟的。这也是框架默认的。
默认的处理方式已经是非常优秀了,很少需要改。
但,还要根据具体业务开发中的需要,如果这些数据就是需要立即展示,那么就优先使用fetch=join迫切左外连接查询加载数据。
抓取策略理解练习
Fetch+lazy的组合
Select+lazy:效果较多
Join+lazy:lazy失效,直接表连接
下面几道题目用来理解抓取策略:

问题:发出了几条sql语句
//上述案例的验证核心代码:
|
Order order =(Order)session.get(Order.class, 1); Customer customer=order.getCustomer(); customer.getName (); |
分析:
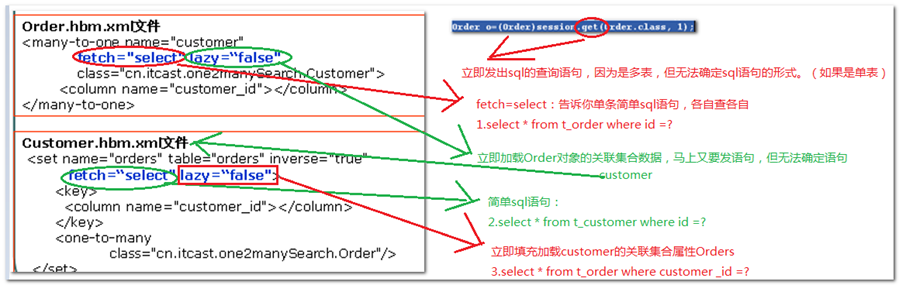



分析:

【由此看出】
sql语句是由类级别抓取策略和关联集合的抓取策略共同决定的
批量抓取(掌握,比较实用)
什么是批量抓取
批量抓取(Batch fetching):对查询抓取的优化方案,通过指定一个主键或外键列表,Hibernate使用单条的select语句获取一批对象实例或集合的策略.
批量抓取的目的:为了解决
.(或称之为1+N)的问题。(主要是针对导航查询)
什么是N+1?请看下面的示例。(下面我们也将分为一对多和多对一两个方向进行讲解。)
批量抓取策略----一对多方向
【需求】
查询所有客户和其所下的订单的数量情况
|
//查询所有客户和其订单的数量情况 List<Customer> list = session.createQuery("from Customer").list(); for(Customer c:list) { System.out.println(c.getName()+":"+c.getOrders().size()); } |
思考:会产生多少条语句呢?
3个客户,4条语句。
先查客户一条+3次订单查询。
这就是N+1
而且从打印的语句看后面4条都差不多。
问题:如果是1w个用户呢?会发送10001条语句。(每个用户查询订单 SQL语句格式是相同的)
优化方案:

设置:


问题:那这个值如何设定呢?
值的设定根据你的需求(你前台的页面来了)来的,比如你的条件就每次查询10条,那就配置为10。
批量抓取策略----多对一方向
【需求】
查询所有订单信息,并打印对应的客户姓名
|
List<Order> list = session.createQuery("from Order").list(); for(Order o:list) { System.out.println(o.getName()+":"+o.getCustomer().getName()); } |
思考:会产生多少条语句呢?
4条语句------>查询订单一条+查询对应的客户3条(一级缓存导致不是30条)
优化方案:
注意,还是在customer.hbm.xml中配置:
还是在一的一方的class标签上配置的。

优化后变成2条
小结:batch-size到底设置多少?根据你的页面显示的数量来调整。比如你页面每次就10条,那么你可以将该值设置为10。
该值,也不能太大,太大可能会导致内存溢出,要根据实际情况来设置。
小结和重点

Fetch=join:直接采用表连接

- 导航查询
- 排序和分页(排序+分页)
- 统计投影查询(返回的类型)
- 命名查询
- 离线查询
- 迫切连接:多表关联---练习一下-了解
- 抓取策略:fetch和lazy的使用
- 批量抓取(batch-size)
作业
【作业一】
完成全天课程练习。
【作业二】
第二天的课前练习(未完成的部分)
Hibernate3 第三天的更多相关文章
- 【Java EE 学习 52】【Spring学习第四天】【Spring与JDBC】【JdbcTemplate创建的三种方式】【Spring事务管理】【事务中使用dbutils则回滚失败!!!??】
一.JDBC编程特点 静态代码+动态变量=JDBC编程. 静态代码:比如所有的数据库连接池 都实现了DataSource接口,都实现了Connection接口. 动态变量:用户名.密码.连接的数据库. ...
- SSH整合(struts2.3.24+hibernate3.6.10+spring4.3.2+mysql5.5+myeclipse8.5+tomcat6+jdk1.6)
终于开始了ssh的整合,虽然现在比较推崇的是,ssm(springmvc+spring+mybatis)这种框架搭配确实比ssh有吸引力,因为一方面springmvc本身就是遵循spring标准,所以 ...
- SSH:Struts2.2+Hibernate3.6+Spring3.1分页示例[转]
参考资料 1 ssh分页(多个例子) http://useryouyou.iteye.com/blog/593954 2 ssh2分页例子 http://459104018-qq-com.iteye. ...
- java的三大框架(三)---Hibernate
一.什么是映射 这里所说的映射就是对象关系映射:将对象数据保存到数据库中,同时可以将数据库数据读入对象中,开发人员只对对象进行操作就可以完成对数据库数据的操作. 二.什么是基本映射 知道了什么是映射, ...
- [Java面试三]JavaWeb基础知识总结.
1.web服务器与HTTP协议 Web服务器 l WEB,在英语中web即表示网页的意思,它用于表示Internet主机上供外界访问的资源. l Internet上供外界访问的Web资源分为: • 静 ...
- Hibernate3注解[转]
Hibernate3注解 收藏 1.@Entity(name="EntityName") 必须,name为可选,对应数据库中一的个表 2.@Table(name="&qu ...
- Hibernate3.3.2 手动配置annotation环境
简单记录Hibernate3.3.2如何快速配置环境 一.下载hibernate-distribution-3.3.2.GA-dist.zip文件,建立User libraries. 打开window ...
- Spring3 整合Hibernate3.5 动态切换SessionFactory (切换数据库方言)
一.缘由 上一篇文章Spring3.3 整合 Hibernate3.MyBatis3.2 配置多数据源/动态切换数据源 方法介绍到了怎么样在Sping.MyBatis.Hibernate整合的应用中动 ...
- Spring3.3 整合 Hibernate3、MyBatis3.2 配置多数据源/动态切换数据源 方法
一.开篇 这里整合分别采用了Hibernate和MyBatis两大持久层框架,Hibernate主要完成增删改功能和一些单一的对象查询功能,MyBatis主要负责查询功能.所以在出来数据库方言的时候基 ...
随机推荐
- Xamarin原生跨平台概述(精简概述,命中要害。PS:无图)
Xamarin原生跨平台:原生界面.原生性能.原生API(与H5比较): 1.C#可以访问Andrid.IOS原生API,也可以调用C#系统类型,如Syetem,System.IO;2.原理:基于Mo ...
- 嵌入式SQL
一.包含嵌入式SQL 程序的处理过程 由预处理程序对源程序进行扫描,识别出ESQL语句 把它们转换成主语言的函数调用语句,使主语言编译程序能够识别 最后由主语言的编译程序将整个源程序编译成目标码 ...
- 《Python高效开发实战》实战演练——内置Web服务器4
<Python高效开发实战>实战演练——开发Django站点1 <Python高效开发实战>实战演练——建立应用2 <Python高效开发实战>实战演练——基本视图 ...
- 使用Spring AOP来进行权限验证
使用Spring AOP前需要先引入相应的包 <dependency> <groupId>org.aspectj</groupId> <artifactId& ...
- [HMLY]13.请谨慎使用 @weakify 和 @strongify
前言 相信大部分见过 @weakify 和 @strongify 的开发者都会喜欢上这两个宏.但是很多人只知道它的强大威力,却没有意识到在特定环境下的危险性. 本文将通过代码测试的方式告诉读者,如何正 ...
- H3 BPM报销流程开发示例
以报销流程为示例,介绍H3 BPM的流程开发过程. 报销流程的表单效果如下: 审核流程为填写报销申请.主管审核.总监审核(1000以上).出纳付款,显示如下: 步骤一:准备工作 使用管理员账号的登录H ...
- 获取Storyboard中的视图控制器
storyboard对于框架的构建是一个非常方便的工具,我们经常需要在storyboard中获取我们指定的视图控制器,那么要怎么获取呢? 方法如下: 第一步:选中视图,为视图自定义一个Storyboa ...
- Android学习笔记(三)Android开发环境的搭建
一.配置JAVA环境 二.配置Android开发环境 可以安装adt-bundle-windows,该压缩包一般自带Eclipse.或者安装Android Studio,要注意SDK的版本是否符合要求 ...
- Android进程回收的一些知识
关于OOM_ADJ说明: Android 进程易被杀死的情形: 参考:Android进程保活招式大全
- childNodes属性 和 nodeType属性
childNodes属性可以用来获取任何一个元素的所有子元素,它是一个包含这个元素的全部子元素的数组:element.childNodes 如果需要把某个文档的body元素的全体子元素检索出来.首先使 ...