Java内存模型-jsr133规范介绍(转)
最近在看《深入理解Java虚拟机:JVM高级特性与最佳实践》讲到了线程相关的细节知识,里面讲述了关于java内存模型,也就是jsr 133定义的规范。
系统的看了jsr 133规范的前面几个章节的内容,觉得受益匪浅。废话不说,简要的介绍一下java内存规范。
什么是内存规范
在jsr-133中是这么定义的
A memory model describes, given a program and an execution trace of that program, whether the execution trace is a legal execution of the program. For the Java programming language, the memory model works by examining each read in an execution trace and checking that the write observed by that read is valid according to certain rules.
也就是说一个内存模型描述了一个给定的程序和和它的执行路径是否一个合法的执行路径。对于java序言来说,内存模型通过考察在程序执行路径中每一个读操作,根据特定的规则,检查写操作对应的读操作是否能是有效的。
java内存模型只是定义了一个规范,具体的实现可以是根据实际情况自由实现的。但是实现要满足java内存模型定义的规范。
处理器和内存的交互
这个要感谢硅工业的发展,导致目前处理器的性能越来越强大。目前市场上基本上都是多核处理器。如何利用多核处理器执行程序的优势,使得程序性能得到极大的提升,是目前来说最重要的。
目前所有的运算都是处理器来执行的,我们在大学的时候就学习过一个基本概念 程序 = 数据 + 算法 ,那么处理器负责计算,数据从哪里获取了?
数据可以存放在处理器寄存器里面(目前x86处理都是基于寄存器架构的),处理器缓存里面,内存,磁盘,光驱等。处理器访问这些数据的速度从快到慢依次为:寄存器,处理器缓存,内存,磁盘,光驱。为了加快程序运行速度,数据离处理器越近越好。但是寄存器,处理器缓存都是处理器私有数据,只有内存,磁盘,光驱才是才是所有处理器都可以访问的全局数据(磁盘和光驱我们这里不讨论,只讨论内存)如果程序是多线程的,那么不同的线程可能分配到不同的处理器来执行,这些处理器需要把数据从主内存加载到处理器缓存和寄存器里面才可以执行(这个大学操作系统概念里面有介绍),数据执行完成之后,在把执行结果同步到主内存。如果这些数据是所有线程共享的,那么就会发生同步问题。处理器需要解决何时同步主内存数据,以及处理执行结果何时同步到主内存,因为同一个处理器可能会先把数据放在处理器缓存里面,以便程序后续继续对数据进行操作。所以对于内存数据,由于多处理器的情况,会变的很复杂。下面是一个例子:
初始值 a = b = 0
process1 process2
1:load a 5:load b
2:write a:2 6:add b:1
3:load b 7: load a
4:write b:1 8:write a:1
假设处理器1先加载内存变量a,写入a的值为2,然后加载b,写入b的值为1,同时 处理2先加载b,执行b+1,那么b在处理器2的结果可能是1 可能是3。因为在load b之前,不知道处理器1是否已经吧b写会到主内存。对于a来说,假设处理器1后于处理器2把a写会到主内存,那么a的值则为2。
而内存模型就是规定了一个规则,处理器如何同主内存同步数据的一个规则。
内存模型介绍
在介绍java内存模型之前,我们先看看两个内存模型
Sequential Consistency Memory Model:连续一致性模型。这个模型定义了程序执行的顺序和代码执行的顺序是一致的。也就是说 如果两个线程,一个线程T1对共享变量A进行写操作,另外一个线程T2对A进行读操作。如果线程T1在时间上先于T2执行,那么T2就可以看见T1修改之后的值。
这个内存模型比较简单,也比较直观,比较符合现实世界的逻辑。但是这个模型定义比较严格,在多处理器并发执行程序的时候,会严重的影响程序的性能。因为每次对共享变量的修改都要立刻同步会主内存,不能把变量保存到处理器寄存器里面或者处理器缓存里面。导致频繁的读写内存影响性能。
Happens-Before Memory Model : 先行发生模型。这个模型理解起来就比较困难。先介绍一个现行发生关系 (Happens-Before Relationship)
如果有两个操作A和B存在A Happens-Before B,那么操作A对变量的修改对操作B来说是可见的。这个现行并不是代码执行时间上的先后关系,而是保证执行结果是顺序的。看下面例子来说明现行发生
A,B为共享变量,r1,r2为局部变量初始 A=B=0Thread1 | Thread21: r2=A | 3: r1=B2: B=2 | 4: A=2 |
凭借直观感觉,线程1先执行 r2=A,则r2=0 ,然后赋值B=1,线程2执行r1=B,由于线程1修改了B的值为1,所以r1=1。但是在现行发生内存模型里面,有可能最终结果为r1 = r2 = 2。为什么会这样,因为编译器或者多处理器可能对指令进行乱序执行,线程1 从代码流上面看是先执行r2 = A,B = 1,但是处理器执行的时候会先执行 B = 2 ,在执行 r2 = A,线程2 可能先执行 A = 2 ,在执行r1 = B,这样可能 会导致 r1 = r2 = 2。
那我们先看看先行发生关系的规则
- 1 在同一个线程里面,按照代码执行的顺序(也就是代码语义的顺序),前一个操作先于后面一个操作发生
- 2 对一个monitor对象的解锁操作先于后续对同一个monitor对象的锁操作
- 3 对volatile字段的写操作先于后面的对此字段的读操作
- 4 对线程的start操作(调用线程对象的start()方法)先于这个线程的其他任何操作
- 5 一个线程中所有的操作先于其他任何线程在此线程上调用 join()方法
- 6 如果A操作优先于B,B操作优先于C,那么A操作优先于C
解释一下以上几个先行发生规则的含义
规则1应该比较好理解,因为比较适合人正常的思维。比如在同一个线程t里面,代码的顺序如下:
thread 1共享变量A、B局部变量r1、r2代码顺序1: A =12: r1 = A3: B = 24: r2 = B执行结果 就是 A=1 ,B=2 ,r1=1 ,r2=2 |
因为以上是在同一个线程里面,按照规则1 也就是按照代码顺序,A = 1 先行发生 r1 =A ,那么r1 = 1
再看规则2,下面是jsr133的例子

按照规则2,由于unlock操作先于发生于lock操作,所以X=1对线程2里面就是可见的,所以r2 = 1

在分析以下,看这个例子,由于unlock操作先于lock操作,所以线程x=1对于线程2不一定是可见(不一定是现行发生的),所以r2的值不一定是1,有可能是x赋值为1之前的那个状态值(假设x初始值为0,那么此时r2的值可能为0)
对于规则3,我们可以稍微修改一下我们说明的第一个例子
A,B为共享变量,并且B是valotile类型的r1,r2为局部变量初始 A=B=0Thread1 | Thread21: r2=A | 3: r1=B2: B=2 | 4: A=2那么r1 = 2, r2可能为0或者2 |
因为对于volatile类型的变量B,线程1对B的更新马上线程2就是可见的,所以r1的值就是确定的。由于A是非valotile类型的,所以值不确定。
规则4,5,6这里就不解释了,知道规则就可以了。
可以从以上的看出,先行发生的规则有很大的灵活性,编译器可以对指令进行重新排序,以便满足处理器性能的需要。只要重新排序之后的结果,在单一线程里面执行结果是可见的(也就是在同一个线程里面满足先行发生原则1就可以了)。
java内存模型是建立在先行发生的内存模型之上的,并且再此基础上,增强了一些。因为现行发生是一个弱约束的内存模型,在多线程竞争访问共享数据的时候,会导致不可预期的结果。有一些是java内存模型可以接受的,有一些是java内存模型不可以接受的。具体细节这里面就不详细说明了。这里只说明关于java新的内存模型重要点。
final字段的语义
在java里面,如果一个类定义了一个final属性,那么这个属性在初始化之后就不可以在改变。一般认为final字段是不变的。在java内存模型里面,对final有一个特殊的处理。如果一个类C定义了一个非static的final属性A,以及非static final属性B,在C的构造器里面对A,B进行初始化,如果一个线程T1创建了类C的一个对象co,同一时刻线程T2访问co对象的A和B属性,如果t2获取到已经构造完成的co对象,那么属性A的值是可以确定的,属性B的值可能还未初始化,
下面一段代码演示了这个情况
public class FinalVarClass { public final int a ; public int b = 0; static FinalVarClass co; public FinalVarClass(){ a = 1; b = 1; } //线程1创建FinalVarClass对象 co public static void create(){ if(co == null){ co = new FinalVarClass(); } } //线程2访问co对象的a,b属性 public static void vistor(){ if(co != null){ System.out.println(co.a);//这里返回的一定是1,a一定初始化完成 System.out.println(co.b);//这里返回的可能是0,因为b还未初始化完成 } }} |
为什么会发生这种情况,原因可能是处理器对创建对象的指令进行重新排序。正常情况下,对象创建语句co = new FinalVarClass()并不是原子的,简单来说,可以分为几个步骤,1 分配内存空间 2 创建空的对象 3 初始化空的对象 4 把初始化完成的对象引用指向 co ,由于这几个步骤处理器可能并发执行,比如3,4 并发执行,所以在create操作完成之后,co不一定马上初始化完成,所以在vistor方法的时候,b的值可能还未初始化。但是如果是final字段,必须保证在对应返回引用之前初始化完成。
volatile语义
对于volatile字段,在现行发生规则里面已经介绍过,对volatile变量的写操作先于对变量的读操作。也就是说任何对volatile变量的修改,都可以在其他线程里面反应出来。
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这写交互
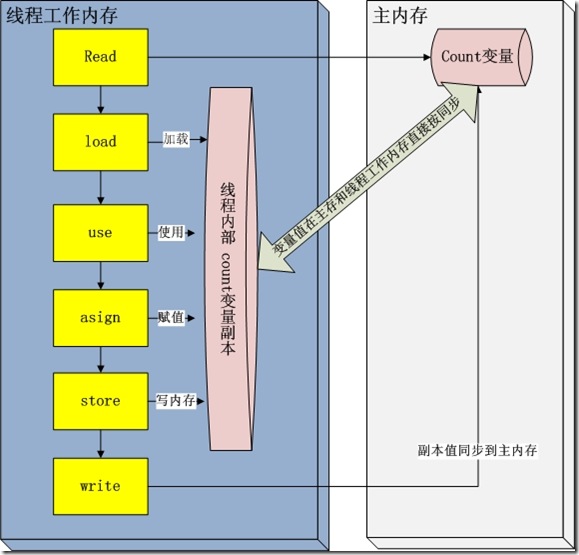
read and load 从主存复制变量到当前工作内存 use and assign 执行代码,改变共享变量值 store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
volatile在java新的内存规范里面还加强了新的语义。在老的内存规范里面,volatile变量与非volatile变量的顺序是可以重新排序的。举个例子
public class VolatileClass { int x = 0; volatile boolean v = false; //线程1write public void writer() { x = 42; v = true; } //线程2 read public void reader() { if (v == true) { System.out.println(x);//结果可能为0,可能为2 } }} |
线程1先调用writer方法,对x和v进行写操作,线程reader判断,如果v=true,则打印x。在老的内存规范里面,可能对v和x赋值顺序发生改变,导致v的写操作先行于x的写操作执行,同时另外一个线程判断v的结果,由于v的写操作先行于v的读操作,所以if(v==true)返回真,于是程序执行打印x,此时x不一定先行与System.out.println指令之前。所以显示的结果可能为0,不一定为2
但是java新的内存模型jsr133修正了这个问题,对于volatile语义的变量,自动进行lock 和 unlock操作包围对变量volatile的读写操作。那么以上语句的顺序可以表示为
thread1 thread21 :write x=1 5:lock(m)2 :lock(m) 6:read v3 :write v=true 7:unlock(m)4 :unlock 8 :if(v==true) 9: System.out.print(x) |
由于unlock操作先于lock操作,所以x写操作5先于发生x的读操作9
以上只是jsr规范中一些小结行的内容,由于jsr133规范定义了很多术语以及很多推论,上述只是简单的介绍了一些比较重要的内容,具体细节可以参考jsr规范的public view :http://today.java.net/pub/a/today/2004/04/13/JSR133.html
http://www.cnblogs.com/aigongsi/archive/2012/04/26/2470296.html
Java内存模型-jsr133规范介绍(转)的更多相关文章
- Java内存模型-jsr133规范介绍
原文地址:http://www.cnblogs.com/aigongsi/archive/2012/04/26/2470296.html; 近期在看<深入理解Java虚拟机:JVM高级特性与最佳 ...
- Java内存模型概念简单介绍,想深入自行百度
- 并发编程-Java内存模型
将之前看过的关于并发编程的东西总结记录一下,本文简单记录Java内存模型的相关知识. 1. 并发编程两个关键问题 并发编程中,需要处理两个关键问题:线程之间如何通信及线程之间如何同步. (1)在命令式 ...
- 面试官:为什么需要Java内存模型?
面试官:今天想跟你聊聊Java内存模型,这块你了解过吗? 候选者:嗯,我简单说下我的理解吧.那我就从为什么要有Java内存模型开始讲起吧 面试官:开始你的表演吧. 候选者:那我先说下背景吧 候选者:1 ...
- 深入浅出Java内存模型
面试官:我记得上一次已经问过了为什么要有Java内存模型 面试官:我记得你的最终答案是:Java为了屏蔽硬件和操作系统访问内存的各种差异,提出了「Java内存模型」的规范,保证了Java程序在各种平台 ...
- 深入理解 Java 内存模型(一)- 内存模型介绍
深入理解 Java 内存模型(一)- 内存模型介绍 深入理解 Java 内存模型(二)- happens-before 规则 深入理解 Java 内存模型(三)- volatile 语义 深入理解 J ...
- JSR133提案-修复Java内存模型
目录 1. 什么是内存模型? 2. JSR 133是关于什么的? 3. 再谈指令重排序 4.同步都做了什么? 5. final字段在旧的内存模型中为什么可以改变? 6."初始化安全" ...
- 从原子类和Unsafe来理解Java内存模型,AtomicInteger的incrementAndGet方法源码介绍,valueOffset偏移量的理解
众所周知,i++分为三步: 1. 读取i的值 2. 计算i+1 3. 将计算出i+1赋给i 可以使用锁来保持操作的原子性和变量可见性,用volatile保持值的可见性和操作顺序性: 从一个小例子引发的 ...
- 【Todo】【转载】深入理解Java内存模型
提纲挈领地说一下Java内存模型: 什么是Java内存模型 Java内存模型定义了一种多线程访问Java内存的规范.Java内存模型要完整讲不是这里几句话能说清楚的,我简单总结一下Java内存模型的几 ...
随机推荐
- poj 3259(bellman最短路径)
Wormholes Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 30169 Accepted: 10914 Descr ...
- iOS 在TabViewController中的一个ViewController跳转到另一种ViewController
第一步: #import "AppDelegate.h" 步骤二: 在须要跳转的地方: AppDelegate *appDelegate = (AppDelegate *)[[UI ...
- iOS Crash获取闪回日志和上传server
首先我们整理常常会闪退的异常哪些:数组越界.空引用.引用没有定义方法.内存空间不足等等. 怎样获取crash闪退日志 -- 工具查看 先看第一个问题怎样查看,我搜索的方法有下面几个: 第一个方法:XC ...
- 11gR2更换OCR和VOTE
11gR2开始,OCR和VOTE它们被存储在ASM磁盘组,因此,更换OCR有两种方法,第一是使用ASM磁盘组drop disk数据重组后,另一种方法是OCR迁移到另一个磁盘组 第一种:add disk ...
- CKEditor上传插件
CKEditor上传插件 前言 CKEditor上传插件是不是免费的,与您分享在此开发.这个插件是基于ASP.NET MVC下开发的,假设是webform的用户或者其他语言的用户.能够參考把serve ...
- Java 的布局管理器GridBagLayout的使用方法(转)
GridBagLayout是java里面最重要的布局管理器之一,可以做出很复杂的布局,可以说GridBagLayout是必须要学好的的, GridBagLayout 类是一个灵活的布局管理器,它不要求 ...
- C++结构体之统计最高最低分
[Submit][Status][Web Board] Description 输入学生的姓名和成绩,统计出最高分的学生和最低分的学生. Input 输入5个学生的姓名和分数,用结构体完成 Outpu ...
- main thread starting…
例的结果,下面的: main thread starting- Thrad 2 staring- Thrad 2 end- Thrad 4 staring- Thrad 4 end- Thrad 1 ...
- 【.NET进程通信】初探.NET中进程间通信的简单的实现
转载请注明出处:http://blog.csdn.net/xiaoy_h/article/details/26090277 废话不多说,IPC就是进程间通信. 进程间通信能够採用的方法非常多,比方创建 ...
- C++该函数隐藏
只有基类成员函数的定义已声明virtualkeyword,当在派生类中的时间,以支付功能实现,virtualkeyword可以从时间被添加以增加.它不影响多状态. easy混淆视听,掩盖: ,规则例如 ...