Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注。索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字“Python”,我们会得到下面的页面

我们可以看到这里罗列了"职位名"、"公司名"、"工作地点"、"薪资"、"发布时间",那么我们就把这些信息爬取下来吧!确定了需求,下一步我们就审查元素找到我们所需信息所在的标签,再写一个正则表达式把元素筛选出来就可以了!

顺理成章得到这样一个正则表达式:
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)
完成这关键的一步,下面写入本地就灰常简单了!还是来段代码吧!
# -*- coding:utf-8 -*-
import urllib.request
import re #获取原码
def get_content(page):
url ='http://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+ str(page)+'.html'
a = urllib.request.urlopen(url)#打开网址
html = a.read().decode('gbk')#读取源代码并转为unicode
return html def get(html):
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)#匹配换行符
items=re.findall(reg,html)
return items #多页处理,下载到文件
for j in range(1,10):
print("正在爬取第"+str(j)+"页数据...")
html=get_content(j)#调用获取网页原码
for i in get(html):
#print(i[0],i[1],i[2],i[3],i[4])
with open ('51job.txt','a',encoding='utf-8') as f:
f.write(i[0]+'\t'+i[1]+'\t'+i[2]+'\t'+i[3]+'\t'+i[4]+'\n')
f.close()
再来一张效果图
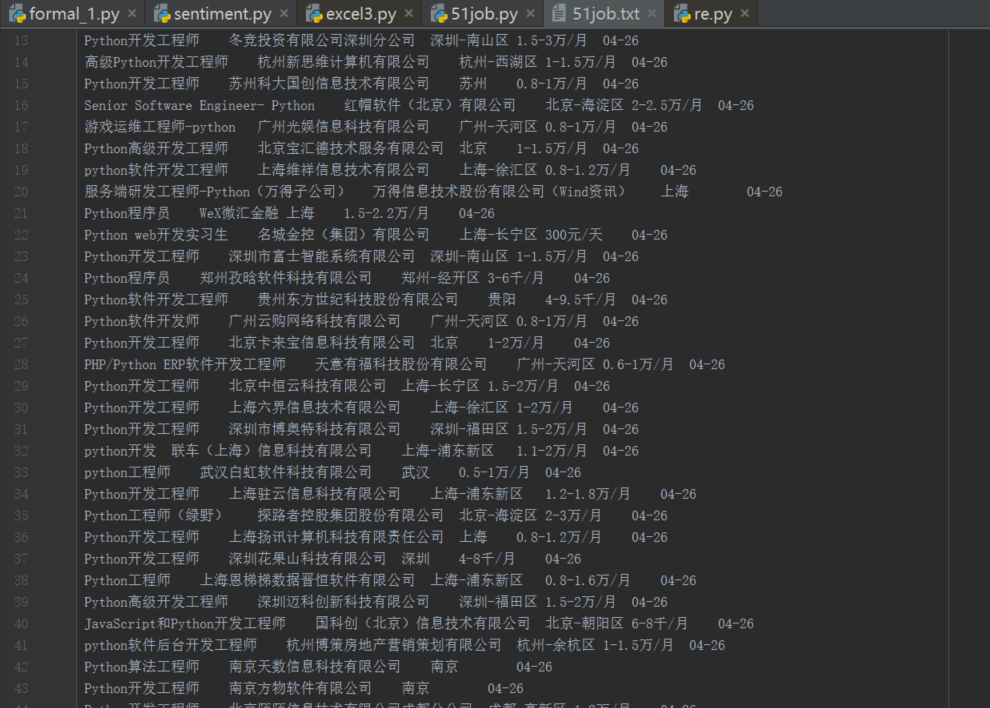
看起来效果还不错,要是能够以表格的形式展示出来就更好了,在网上看到有的大佬直接把招聘信息写入excel表格,今天我也来试一下吧!其实也并麻烦,只需要将上面的代码稍加修改就可以了。下面贴一下代码,重要的地方会有注释。
# -*- coding:utf-8 -*-
import urllib.request
import re
import xlwt#用来创建excel文档并写入数据 #获取原码
def get_content(page):
url ='http://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+ str(page)+'.html'
a = urllib.request.urlopen(url)#打开网址
html = a.read().decode('gbk')#读取源代码并转为unicode
return html def get(html):
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)#匹配换行符
items = re.findall(reg,html)
return items
def excel_write(items,index): #爬取到的内容写入excel表格
for item in items:#职位信息
for i in range(0,5):
#print item[i]
ws.write(index,i,item[i])#行,列,数据
print(index)
index+=1 newTable="test.xls"#表格名称
wb = xlwt.Workbook(encoding='utf-8')#创建excel文件,声明编码
ws = wb.add_sheet('sheet1')#创建表格
headData = ['招聘职位','公司','地址','薪资','日期']#表头部信息
for colnum in range(0, 5):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font: bold on')) # 行,列 for each in range(1,10):
index=(each-1)*50+1
excel_write(get(get_content(each)),index)
wb.save(newTable)
最后实现的效果如下图:

至此,我们的工作就已经完成了!有的朋友可能想要爬取其他工作的招聘信息,观察了一下URl可以知道修改一下关键字名称就可以了!可以定义成一个函数只需输入关键字,然后就可以自动爬取该工作的招聘信息!条条大路通罗马,想要实现上面的效果肯定不止这一种方法,以上内容仅供参考,希望可以给有需要的朋友提供一点思路!至于代码就比较粗糙了,而本人也希望有一天能够写得一手风骚代码!还是要重申一遍,本人能力有限,文章中可能会有纰漏或者错误,也欢迎表哥表姐们前来指正!谢谢大家!
Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel的更多相关文章
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习之爬取全国各省市县级城市邮政编码
实例需求:运用python语言在http://www.ip138.com/post/网站爬取全国各个省市县级城市的邮政编码,并且保存在excel文件中 实例环境:python3.7 requests库 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- Python爬虫一:爬取上交所上市公司信息
前几天领导让写一个从新闻语料中识别上市公司的方案.上市公司属于组织机构的范畴,组织机构识别属于命名实体识别的范畴.命名实体识别包括人名.地名.组织机构等信息的识别. 要想从新闻语料中识别上市公司就需要 ...
- python scrapy爬取前程无忧招聘信息
使用scrapy框架之前,使用以下命令下载库: pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple 1.创建项目文件夹 scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
随机推荐
- 非负矩阵分解(4):NMF算法和聚类算法的联系与区别
作者:桂. 时间:2017-04-14 06:22:26 链接:http://www.cnblogs.com/xingshansi/p/6685811.html 声明:欢迎被转载,不过记得注明出处 ...
- 细谈UITabBarController
1.简述 UITabBarController和UINavigationController类似,UITabBarController也可以轻松地管理多个控制器,轻松完成控制器之间的切换,UITabB ...
- GPIO的配置过程
今天看到一篇很好的博文,,看这里:http://www.cnblogs.com/crazyxu/archive/2011/10/14/2212337.html 下面总结一下,加深一下理解. 要使用GP ...
- gif-drawable的使用及详解
下载gif-drawable包和Demo的链接:http://pan.baidu.com/s/1eQxVKRo 本帖原创,转载的朋友请注明转载地址>:http://www.cnblogs.com ...
- LinkCode 下一个排列、上一个排列
http://www.lintcode.com/zh-cn/problem/next-permutation-ii/# 原题 给定一个若干整数的排列,给出按正数大小进行字典序从小到大排序后的下一个排列 ...
- C语言学习的第一章
首先,学习编写程序要先知道什么是程序,我们为什么要写程序? 程序就是为了让计算机执行某些操作或解决某个问题而编写的一系列有序指令的集合.程序里有很多算法,算法是解决问题的具体方法和步骤,就像我们想要得 ...
- 【Spark2.0源码学习】-4.Master启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 基于JS的问卷调查
主要工作 因为代码不好展示,也不好截长图,可以去看我的GitHub地址:https://github.com/14glwu/MyBlog/blob/master/questionnaire.html ...
- 全易通人事考勤工资验厂管理系统软件创建连接SQL2000数据库的操作方法和说明
全易通人事考勤工资验厂管理系统软件创建连接SQL2000数据库的操作方法和说明.全易通人事考勤工资验厂管理系统软件,有2种数据库,一个是ACCESS,另一个是SQL.不过由于ACCESS数据库比较小, ...
- Chrome DevTools 的 Queueing、Stalled解析
https://developers.google.com/web/tools/chrome-devtools/network-performance/understanding-resource-t ...