MongoDB基础教程系列--第七篇 MongoDB 聚合管道
在讲解聚合管道(Aggregation Pipeline)之前,我们先介绍一下 MongoDB 的聚合功能,聚合操作主要用于对数据的批量处理,往往将记录按条件分组以后,然后再进行一系列操作,例如,求最大值、最小值、平均值,求和等操作。聚合操作还能够对记录进行复杂的操作,主要用于数理统计和数据挖掘。在 MongoDB 中,聚合操作的输入是集合中的文档,输出可以是一个文档,也可以是多条文档。
MongoDB 提供了非常强大的聚合操作,有三种方式:
- 聚合管道(Aggregation Pipeline)
- 单目的聚合操作(Single Purpose Aggregation Operation)
- MapReduce 编程模型
在本篇中,重点讲解聚合管道和单目的聚合操作,MapReduce 编程模型会在后续的文章中讲解。
1、聚合管道
聚合管道是 MongoDB 2.2版本引入的新功能。它由阶段(Stage)组成,文档在一个阶段处理完毕后,聚合管道会把处理结果传到下一个阶段。
聚合管道功能:
- 对文档进行过滤,查询出符合条件的文档
- 对文档进行变换,改变文档的输出形式
每个阶段用阶段操作符(Stage Operators)定义,在每个阶段操作符中可以用表达式操作符(Expression Operators)计算总和、平均值、拼接分割字符串等相关操作,直到每个阶段进行完成,最终返回结果,返回的结果可以直接输出,也可以存储到集合中。
MongoDB 中使用 db.COLLECTION_NAME.aggregate([{<stage>},...]) 方法来构建和使用聚合管道。先看下官网给的实例,感受一下聚合管道的用法。
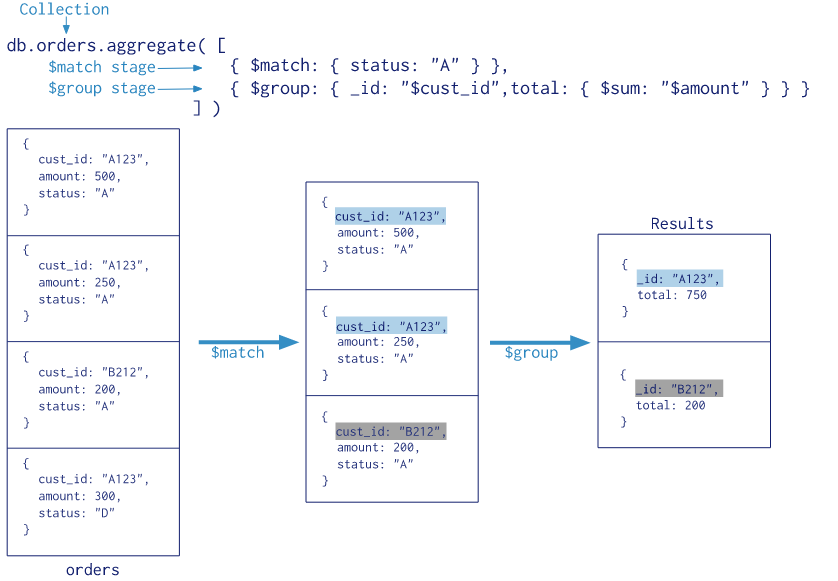
实例中,$match 用于获取 status = "A" 的记录,然后将符合条件的记录送到下一阶段 $group 中进行分组求和计算,最后返回 Results。其中,$match、$group 都是阶段操作符,而阶段 $group 中用到的 $sum 是表达式操作符。
在下面,我们通过范例分别对阶段操作符和表达式操作符进行详解。
1.1、阶段操作符
使用阶段操作符之前,我们先看一下 article 集合中的文档列表,也就是范例中用到的数据。
>db.article.find().pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}
1.1.1、$project
作用
修改文档的结构,可以用来重命名、增加或删除文档中的字段。
范例1
只返回文档中 title 和 author 字段
>db.article.aggregate([{$project:{_id:0, title:1, author:1 }}])
{ "title": "MongoDB Aggregate", "author": "liruihuan" },
{ "title": "MongoDB Index", "author": "liruihuan" },
{ "title": "MongoDB Query", "author": "eryueyang" }
因为字段 _id 是默认显示的,这里必须用 _id:0 把字段_id过滤掉。
范例2
把文档中 pages 字段的值都增加10。并重命名成 newPages 字段。
>db.article.aggregate(
[
{
$project:{
_id:0,
title:1,
author:1,
newPages: {$add:["$Pages",10]}
}
}
]
)
{ "title": "MongoDB Aggregate", "author": "liruihuan", "newPages": 15 },
{ "title": "MongoDB Index", "author": "liruihuan", "newPages": 13 },
{ "title": "MongoDB Query", "author": "eryueyang", "newPages": 18 }
其中,$add 是 加 的意思,是算术类型表达式操作符,具体表达式操作符,下面会讲到。
1.1.2、$match
作用
用于过滤文档。用法类似于 find() 方法中的参数。
范例
查询出文档中 pages 字段的值大于等于5的数据。
>db.article.aggregate(
[
{
$match: {"pages": {$gte: 5}}
}
]
).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}
注:
- 在 $match 中不能使用 $where 表达式操作符
- 如果 $match 位于管道的第一个阶段,可以利用索引来提高查询效率
- $match 中使用 $text 操作符的话,只能位于管道的第一阶段
- $match 尽量出现在管道的最前面,过滤出需要的数据,在后续的阶段中可以提高效率。
1.1.3、$group
作用
将集合中的文档进行分组,可用于统计结果。
范例
从 article 中得到每个 author 的文章数,并输入 author 和对应的文章数。
>db.article.aggregate(
[
{
$group: {_id: "$author", total: {$sum: 1}}
}
]
)
{"_id" : "eryueyang", "total" : 1}
{"_id" : "liruihuan", "total" : 2}
1.1.4、$sort
作用
将集合中的文档进行排序。
范例
让集合 article 以 pages 升序排列
>db.article.aggregate([{$sort: {"pages": 1}}]).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}
如果以降序排列,则设置成 "pages": -1
1.1.5、$limit
作用
限制返回的文档数量
范例
返回集合 article 中前两条文档
>db.article.aggregate([{$limit: 2}]).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
}
1.1.6、$skip
作用
跳过指定数量的文档,并返回余下的文档。
范例
跳过集合 article 中一条文档,输出剩下的文档
>db.article.aggregate([{$skip: 1}]).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}
1.1.7、$unwind
作用
将文档中数组类型的字段拆分成多条,每条文档包含数组中的一个值。
范例
把集合 article 中 title="MongoDB Aggregate" 的 tags 字段拆分
>db.article.aggregate(
[
{
$match: {"title": "MongoDB Aggregate"}
},
{
$unwind: "$tags"
}
]
).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": "Mongodb",
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": "Database",
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": "Query",
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
}
注:
- $unwind 参数数组字段为空或不存在时,待处理的文档将会被忽略,该文档将不会有任何输出
- $unwind 参数不是一个数组类型时,将会抛出异常
- $unwind 所作的修改,只用于输出,不能改变原文档
1.2、表达式操作符
表达式操作符有很多操作类型,其中最常用的有布尔管道聚合操作、集合操作、比较聚合操作、算术聚合操作、字符串聚合操作、数组聚合操作、日期聚合操作、条件聚合操作、数据类型聚合操作等。每种类型都有很多用法,这里就不一一举例了。
1.2.1、布尔管道聚合操作(Boolean Aggregation Operators)
| 名称 | 说明 |
|---|---|
$and |
Returns true only when all its expressions evaluate to true. Accepts any number of argument expressions. |
$or |
Returns true when any of its expressions evaluates to true. Accepts any number of argument expressions. |
$not |
Returns the boolean value that is the opposite of its argument expression. Accepts a single argument expression. |
范例
假如有一个集合 mycol
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 }
{ "_id" : 2, "item" : "abc2", description: "product 2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", description: "product 3", qty: 250 }
{ "_id" : 4, "item" : "VWZ1", description: "product 4", qty: 300 }
{ "_id" : 5, "item" : "VWZ2", description: "product 5", qty: 180 }
确定 qty 是否大于250或者小于200
db.mycol.aggregate(
[
{
$project:
{
item: 1,
result: { $or: [ { $gt: [ "$qty", 250 ] }, { $lt: [ "$qty", 200 ] } ] }
}
}
]
)
{ "_id" : 1, "item" : "abc1", "result" : true }
{ "_id" : 2, "item" : "abc2", "result" : false }
{ "_id" : 3, "item" : "xyz1", "result" : false }
{ "_id" : 4, "item" : "VWZ1", "result" : true }
{ "_id" : 5, "item" : "VWZ2", "result" : true }
1.2.2、集合操作(Set Operators)
用于集合操作,求集合的并集、交集、差集运算。
| 名称 | 说明 |
|---|---|
$setEquals |
Returns true if the input sets have the same distinct elements. Accepts two or more argument expressions. |
$setIntersection |
Returns a set with elements that appear in all of the input sets. Accepts any number of argument expressions. |
$setUnion |
Returns a set with elements that appear in any of the input sets. Accepts any number of argument expressions. |
$setDifference |
Returns a set with elements that appear in the first set but not in the second set; i.e. performs a relative complement of the second set relative to the first. Accepts exactly two argument expressions. |
$setIsSubset |
Returns true if all elements of the first set appear in the second set, including when the first set equals the second set; i.e. not a strict subset. Accepts exactly two argument expressions. |
$anyElementTrue |
Returns true if any elements of a set evaluate to true; otherwise, returns false. Accepts a single argument expression. |
$allElementsTrue |
Returns true if no element of a set evaluates to false, otherwise, returns false. Accepts a single argument expression. |
范例
假如有一个集合 mycol
{ "_id" : 1, "A" : [ "red", "blue" ], "B" : [ "red", "blue" ] }
{ "_id" : 2, "A" : [ "red", "blue" ], "B" : [ "blue", "red", "blue" ] }
{ "_id" : 3, "A" : [ "red", "blue" ], "B" : [ "red", "blue", "green" ] }
{ "_id" : 4, "A" : [ "red", "blue" ], "B" : [ "green", "red" ] }
{ "_id" : 5, "A" : [ "red", "blue" ], "B" : [ ] }
{ "_id" : 6, "A" : [ "red", "blue" ], "B" : [ [ "red" ], [ "blue" ] ] }
{ "_id" : 7, "A" : [ "red", "blue" ], "B" : [ [ "red", "blue" ] ] }
{ "_id" : 8, "A" : [ ], "B" : [ ] }
{ "_id" : 9, "A" : [ ], "B" : [ "red" ] }
求出集合 mycol 中 A 和 B 的交集
db.mycol.aggregate(
[
{ $project: { A:1, B: 1, allValues: { $setUnion: [ "$A", "$B" ] }, _id: 0 } }
]
)
{ "A": [ "red", "blue" ], "B": [ "red", "blue" ], "allValues": [ "blue", "red" ] }
{ "A": [ "red", "blue" ], "B": [ "blue", "red", "blue" ], "allValues": [ "blue", "red" ] }
{ "A": [ "red", "blue" ], "B": [ "red", "blue", "green" ], "allValues": [ "blue", "red", "green" ] }
{ "A": [ "red", "blue" ], "B": [ "green", "red" ], "allValues": [ "blue", "red", "green" ] }
{ "A": [ "red", "blue" ], "B": [ ], "allValues": [ "blue", "red" ] }
{ "A": [ "red", "blue" ], "B": [ [ "red" ], [ "blue" ] ], "allValues": [ "blue", "red", [ "red" ], [ "blue" ] ] }
{ "A": [ "red", "blue" ], "B": [ [ "red", "blue" ] ], "allValues": [ "blue", "red", [ "red", "blue" ] ] }
{ "A": [ ], "B": [ ], "allValues": [ ] }
{ "A": [ ], "B": [ "red" ], "allValues": [ "red" ] }
1.2.3、比较聚合操作(Comparison Aggregation Operators)
| 名称 | 说明 |
|---|---|
$cmp |
Returns: 0 if the two values are equivalent, 1 if the first value is greater than the second, and -1 if the first value is less than the second. |
$eq |
Returns true if the values are equivalent. |
$gt |
Returns true if the first value is greater than the second. |
$gte |
Returns true if the first value is greater than or equal to the second. |
$lt |
Returns true if the first value is less than the second. |
$lte |
Returns true if the first value is less than or equal to the second. |
$ne |
Returns true if the values are not equivalent. |
这里就不举例了,之前的例子有用到过。
1.2.4、算术聚合操作(Arithmetic Aggregation Operators)
| 名称 | 说明 |
|---|---|
$abs |
Returns the absolute value of a number. |
$add |
Adds numbers to return the sum, or adds numbers and a date to return a new date. If adding numbers and a date, treats the numbers as milliseconds. Accepts any number of argument expressions, but at most, one expression can resolve to a date. |
$ceil |
Returns the smallest integer greater than or equal to the specified number. |
$divide |
Returns the result of dividing the first number by the second. Accepts two argument expressions. |
$exp |
Raises e to the specified exponent. |
$floor |
Returns the largest integer less than or equal to the specified number. |
$ln |
Calculates the natural log of a number. |
$log |
Calculates the log of a number in the specified base. |
$log10 |
Calculates the log base 10 of a number. |
$mod |
Returns the remainder of the first number divided by the second. Accepts two argument expressions. |
$multiply |
Multiplies numbers to return the product. Accepts any number of argument expressions. |
$pow |
Raises a number to the specified exponent. |
$sqrt |
Calculates the square root. |
$subtract |
Returns the result of subtracting the second value from the first. If the two values are numbers, return the difference. If the two values are dates, return the difference in milliseconds. If the two values are a date and a number in milliseconds, return the resulting date. Accepts two argument expressions. If the two values are a date and a number, specify the date argument first as it is not meaningful to subtract a date from a number. |
$trunc |
Truncates a number to its integer. |
范例
假如有一个集合 mycol
{ _id: 1, start: 5, end: 8 }
{ _id: 2, start: 4, end: 4 }
{ _id: 3, start: 9, end: 7 }
{ _id: 4, start: 6, end: 7 }
求集合 mycol 中 start 减去 end 的绝对值
db.mycol.aggregate([
{
$project: { delta: { $abs: { $subtract: [ "$start", "$end" ] } } }
}
])
{ "_id" : 1, "delta" : 3 }
{ "_id" : 2, "delta" : 0 }
{ "_id" : 3, "delta" : 2 }
{ "_id" : 4, "delta" : 1 }
1.2.5、字符串聚合操作(String Aggregation Operators)
| 名称 | 说明 |
|---|---|
$concat |
Concatenates any number of strings. |
$indexOfBytes |
Searches a string for an occurence of a substring and returns the UTF-8 byte index of the first occurence. If the substring is not found, returns -1. |
$indexOfCP |
Searches a string for an occurence of a substring and returns the UTF-8 code point index of the first occurence. If the substring is not found, returns -1. |
$split |
Splits a string into substrings based on a delimiter. Returns an array of substrings. If the delimiter is not found within the string, returns an array containing the original string. |
$strLenBytes |
Returns the number of UTF-8 encoded bytes in a string. |
$strLenCP |
Returns the number of UTF-8 code points in a string. |
$strcasecmp |
Performs case-insensitive string comparison and returns: 0 if two strings are equivalent, 1 if the first string is greater than the second, and -1 if the first string is less than the second. |
$substr |
Deprecated. Use $substrBytes or $substrCP. |
$substrBytes |
Returns the substring of a string. Starts with the character at the specified UTF-8 byte index (zero-based) in the string and continues for the specified number of bytes. |
$substrCP |
Returns the substring of a string. Starts with the character at the specified UTF-8 code point (CP) index (zero-based) in the string and continues for the number of code points specified. |
$toLower |
Converts a string to lowercase. Accepts a single argument expression. |
$toUpper |
Converts a string to uppercase. Accepts a single argument expression. |
范例
假如有一个集合 mycol
{ "_id" : 1, "city" : "Berkeley, CA", "qty" : 648 }
{ "_id" : 2, "city" : "Bend, OR", "qty" : 491 }
{ "_id" : 3, "city" : "Kensington, CA", "qty" : 233 }
{ "_id" : 4, "city" : "Eugene, OR", "qty" : 842 }
{ "_id" : 5, "city" : "Reno, NV", "qty" : 655 }
{ "_id" : 6, "city" : "Portland, OR", "qty" : 408 }
{ "_id" : 7, "city" : "Sacramento, CA", "qty" : 574 }
以 ',' 分割集合 mycol 中字符串city的值,用 $unwind 拆分成多个文档,匹配出城市名称只有两个字母的城市,并求和各个城市中 qty 的值,最后以降序排序。
db.mycol.aggregate([
{ $project : { city_state : { $split: ["$city", ", "] }, qty : 1 } },
{ $unwind : "$city_state" },
{ $match : { city_state : /[A-Z]{2}/ } },
{ $group : { _id: { "state" : "$city_state" }, total_qty : { "$sum" : "$qty" } } },
{ $sort : { total_qty : -1 } }
])
{ "_id" : { "state" : "OR" }, "total_qty" : 1741 }
{ "_id" : { "state" : "CA" }, "total_qty" : 1455 }
{ "_id" : { "state" : "NV" }, "total_qty" : 655 }
1.2.6、数组聚合操作(Array Aggregation Operators)
| 名称 | 说明 |
|---|---|
$arrayElemAt |
Returns the element at the specified array index. |
$concatArrays |
Concatenates arrays to return the concatenated array. |
$filter |
Selects a subset of the array to return an array with only the elements that match the filter condition. |
$indexOfArray |
Searches an array for an occurence of a specified value and returns the array index of the first occurence. If the substring is not found, returns -1. |
$isArray |
Determines if the operand is an array. Returns a boolean. |
$range |
Outputs an array containing a sequence of integers according to user-defined inputs. |
$reverseArray |
Returns an array with the elements in reverse order. |
$reduce |
Applies an expression to each element in an array and combines them into a single value. |
$size |
Returns the number of elements in the array. Accepts a single expression as argument. |
$slice |
Returns a subset of an array. |
$zip |
Merge two lists together. |
$in |
Returns a boolean indicating whether a specified value is in an array. |
范例
假如有一个集合 mycol
{ "_id" : 1, "name" : "dave123", favorites: [ "chocolate", "cake", "butter", "apples" ] }
{ "_id" : 2, "name" : "li", favorites: [ "apples", "pudding", "pie" ] }
{ "_id" : 3, "name" : "ahn", favorites: [ "pears", "pecans", "chocolate", "cherries" ] }
{ "_id" : 4, "name" : "ty", favorites: [ "ice cream" ] }
求出集合 mycol 中 favorites 的第一项和最后一项
db.mycol.aggregate([
{
$project:
{
name: 1,
first: { $arrayElemAt: [ "$favorites", 0 ] },
last: { $arrayElemAt: [ "$favorites", -1 ] }
}
}
])
{ "_id" : 1, "name" : "dave123", "first" : "chocolate", "last" : "apples" }
{ "_id" : 2, "name" : "li", "first" : "apples", "last" : "pie" }
{ "_id" : 3, "name" : "ahn", "first" : "pears", "last" : "cherries" }
{ "_id" : 4, "name" : "ty", "first" : "ice cream", "last" : "ice cream" }
1.2.7、日期聚合操作(Date Aggregation Operators)
| 名称 | 说明 |
|---|---|
$dayOfYear |
Returns the day of the year for a date as a number between 1 and 366 (leap year). |
$dayOfMonth |
Returns the day of the month for a date as a number between 1 and 31. |
$dayOfWeek |
Returns the day of the week for a date as a number between 1 (Sunday) and 7 (Saturday). |
$year |
Returns the year for a date as a number (e.g. 2014). |
$month |
Returns the month for a date as a number between 1 (January) and 12 (December). |
$week |
Returns the week number for a date as a number between 0 (the partial week that precedes the first Sunday of the year) and 53 (leap year). |
$hour |
Returns the hour for a date as a number between 0 and 23. |
$minute |
Returns the minute for a date as a number between 0 and 59. |
$second |
Returns the seconds for a date as a number between 0 and 60 (leap seconds). |
$millisecond |
Returns the milliseconds of a date as a number between 0 and 999. |
$dateToString |
Returns the date as a formatted string. |
$isoDayOfWeek |
Returns the weekday number in ISO 8601 format, ranging from 1 (for Monday) to 7 (for Sunday). |
$isoWeek |
Returns the week number in ISO 8601 format, ranging from 1 to 53. Week numbers start at 1 with the week (Monday through Sunday) that contains the year’s first Thursday. |
$isoWeekYear |
Returns the year number in ISO 8601 format. The year starts with the Monday of week 1 (ISO 8601) and ends with the Sunday of the last week (ISO 8601). |
范例
假如有一个集合 mycol
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2017-01-01T08:15:39.736Z") }
得到集合 mycol 中 date 字段的相关日期值
db.mycol.aggregate(
[
{
$project:
{
year: { $year: "$date" },
month: { $month: "$date" },
day: { $dayOfMonth: "$date" },
hour: { $hour: "$date" },
minutes: { $minute: "$date" },
seconds: { $second: "$date" },
milliseconds: { $millisecond: "$date" },
dayOfYear: { $dayOfYear: "$date" },
dayOfWeek: { $dayOfWeek: "$date" },
week: { $week: "$date" }
}
}
]
)
{
"_id" : 1,
"year" : 2017,
"month" : 1,
"day" : 1,
"hour" : 8,
"minutes" : 15,
"seconds" : 39,
"milliseconds" : 736,
"dayOfYear" : 1,
"dayOfWeek" : 1,
"week" : 0
}
1.2.8、条件聚合操作(Conditional Aggregation Operators)
| 名称 | 说明 |
|---|---|
$cond |
A ternary operator that evaluates one expression, and depending on the result, returns the value of one of the other two expressions. Accepts either three expressions in an ordered list or three named parameters. |
$ifNull |
Returns either the non-null result of the first expression or the result of the second expression if the first expression results in a null result. Null result encompasses instances of undefined values or missing fields. Accepts two expressions as arguments. The result of the second expression can be null. |
$switch |
Evaluates a series of case expressions. When it finds an expression which evaluates to true, $switch executes a specified expression and breaks out of the control flow. |
范例
假如有一个集合 mycol
{ "_id" : 1, "item" : "abc1", qty: 300 }
{ "_id" : 2, "item" : "abc2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", qty: 250 }
如果集合 mycol 中 qty 字段值大于等于250,则返回30,否则返回20
db.mycol.aggregate(
[
{
$project:
{
item: 1,
discount:
{
$cond: { if: { $gte: [ "$qty", 250 ] }, then: 30, else: 20 }
}
}
}
]
)
{ "_id" : 1, "item" : "abc1", "discount" : 30 }
{ "_id" : 2, "item" : "abc2", "discount" : 20 }
{ "_id" : 3, "item" : "xyz1", "discount" : 30 }
1.2.9、数据类型聚合操作(Data Type Aggregation Operators)
| 名称 | 说明 |
|---|---|
$type |
Return the BSON data type of the field. |
范例
假如有一个集合 mycol
{ _id: 0, a : 8 }
{ _id: 1, a : [ 41.63, 88.19 ] }
{ _id: 2, a : { a : "apple", b : "banana", c: "carrot" } }
{ _id: 3, a : "caribou" }
{ _id: 4, a : NumberLong(71) }
{ _id: 5 }
获取文档中 a 字段的数据类型
db.mycol.aggregate([{
$project: {
a : { $type: "$a" }
}
}])
{ _id: 0, "a" : "double" }
{ _id: 1, "a" : "array" }
{ _id: 2, "a" : "object" }
{ _id: 3, "a" : "string" }
{ _id: 4, "a" : "long" }
{ _id: 5, "a" : "missing" }
1.3、聚合管道优化
默认情况下,整个集合作为聚合管道的输入,为了提高处理数据的效率,可以使用一下策略:
- 将 $match 和 $sort 放到管道的前面,可以给集合建立索引,来提高处理数据的效率。
- 可以用 $match、$limit、$skip 对文档进行提前过滤,以减少后续处理文档的数量。
当聚合管道执行命令时,MongoDB 也会对各个阶段自动进行优化,主要包括以下几个情况:
- $sort + $match 顺序优化
如果 $match 出现在 $sort 之后,优化器会自动把 $match 放到 $sort 前面
2. $skip + $limit 顺序优化
如果 $skip 在 $limit 之后,优化器会把 $limit 移动到 $skip 的前面,移动后 $limit的值等于原来的值加上 $skip 的值。
例如:移动前:{$skip: 10, $limit: 5},移动后:{$limit: 15, $skip: 10}
1.4、聚合管道使用限制
对聚合管道的限制主要是对 返回结果大小 和 内存 的限制。
返回结果大小
聚合结果返回的是一个文档,不能超过 16M,从 MongoDB 2.6版本以后,返回的结果可以是一个游标或者存储到集合中,返回的结果不受 16M 的限制。
内存
聚合管道的每个阶段最多只能用 100M 的内存,如果超过100M,会报错,如果需要处理大数据,可以使用 allowDiskUse 选项,存储到磁盘上。
2、单目的聚合操作
单目的聚合命令,常用的:count()、distinct(),与聚合管道相比,单目的聚合操作更简单,使用非常频繁。先通过 distinct() 看一下工作流程
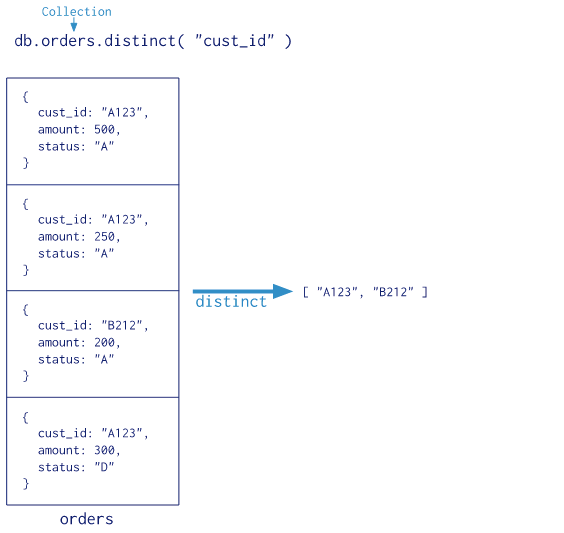
distinct() 的作用是去重。而 count() 是求文档的个数。
下面用 count() 方法举例说明一下
范例
求出集合 article 中 time 值大于 2017-04-09 的文档个数
>db.article.count( { time: { $gt: new Date('04/09/2017') } } )
3
这个语句等价于
db.article.find( { time: { $gt: new Date('04/09/2017') } } ).count()
业精于勤,荒于嬉;行成于思,毁于随。
如果你觉得这篇文章不错或者对你有所帮助,可以通过右侧【打赏】功能,给予博主一点点鼓励和支持
MongoDB基础教程系列--第七篇 MongoDB 聚合管道的更多相关文章
- MongoDB基础教程系列--第三篇 MongoDB基本操作(二)
1.集合操作 1.1.创建集合 MongoDB 用 db.createCollection(name, options) 方法创建集合. 格式 db.createCollection(name, op ...
- MongoDB基础教程系列--第四篇 MongoDB 查询文档
查询文档 查询文档可以用 find() 方法查询全部文档,可以用 findOne() 查询第一个文档,当然还可以根据 条件操作符 和 $type操作符 查询满足条件的文档. find() 和 find ...
- MongoDB基础教程系列--第五篇 MongoDB 映射与限制记录
上一篇提到的 find() 的方法,细心的伙伴会发现查询的结果都是显示了集合中全部的字段,实际应用中,显然是不够用的.那么有没有办法指定特定的字段显示出文档呢?答案是肯定的,MongoDB 中用映射实 ...
- MongoDB基础教程系列--第六篇 MongoDB 索引
使用索引可以大大提高文档的查询效率.如果没有索引,会遍历集合中所有文档,才能找到匹配查询语句的文档.这样遍历集合中整个文档的方式是非常耗时的,特别是处理大数据时,耗时几十秒甚至几分钟都是有可能的. 创 ...
- MongoDB基础教程系列--第八篇 MongoDB 副本集实现复制功能
为什么用复制 为什么要使用复制呢?如果我们的数据库只存在于一台服务器,若这台服务器宕机了,那对于我们数据将会是灾难,当然这只是其中一个原因,若数据量非常大,读写操作势必会影响数据库的性能,这时候复制就 ...
- MongoDB基础教程系列--未完待续
最近对 MongoDB 产生兴趣,在网上找的大部分都是 2.X 版本,由于 2.X 与 3.X 差别还是很大的,所以自己参考官网,写了本系列.MongoDB 的知识还是很多的,本系列会持续更新,本文作 ...
- MongoDB基础教程系列--目录结构
最近对 MongoDB 产生兴趣,在网上找的大部分都是 2.X 版本,由于 2.X 与 3.X 差别还是很大的,所以自己参考官网,写了本系列.MongoDB 的知识还是很多的,本系列会持续更新,本文作 ...
- MongoDB基础教程系列--第一篇 进入MongoDB世界
1.什么是MongoDB MongoDB是跨平台的.一个基于分布式文件存储的数据库.由C++语言编写.用它创建的数据库具备性能高.可用性强.易于扩展等特点.MongoDB将数据存储为一个文档,数据结构 ...
- MongoDB基础教程系列--第二篇 MongoDB基本操作(一)
1.安装环境 在官网上下载MongoDB的最新版本,根据自身Windows版本下载正确的MongoDB版本.下载后,双击32位或者64位.msi文件,按操作提示安装就可以了. 说明: 32 位版本的 ...
随机推荐
- MINA、Netty、Twisted一起学(十一):SSL/TLS
什么是SSL/TLS 不使用SSL/TLS的网络通信,一般都是明文传输,网络传输内容在传输过程中很容易被窃听甚至篡改,非常不安全.SSL/TLS协议就是为了解决这些安全问题而设计的.SSL/TLS协议 ...
- 在Vue中通过自定义指令获取元素
vue.js 是数据绑定的框架,大部分情况下我们都不需要直接操作 DOM Element,但在某些时候,我们还是有获取DOM Element的需求的: 在 vue.js 中,获取某个DOM Eleme ...
- cocoapods 删除已导入项目的第三方库和移除项目中的cocoapods
第一部分将介绍如何删除项目中已经由cocoapods配置好的第三方 1.打开项目中的Podfile文件 2.删除选中的pod Snapkit的命令行3.打开终端cd到当前项目的根目录下重新执行pod ...
- json基础入门
json是什么? JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于阅读和编写,同时也易于机器解析和生成.它基于ECMAScript的一个子集. JSO ...
- DOM操作和样式操作库的封装
一.DOM常用方法和属性复习 以下粗略的罗列一下DOM的常用方法和属性,由于不是介绍DOM的基础内容,所以就不一一详细说明各个方法和属性了(学习DOM的封装的,一般都对基础DOM比较熟悉了). 1.1 ...
- WeMall微商城源码报名插件Apply的主要源码
WeMall微信商城源码报名插件Apply,用于商城的签到系统,分享了部分比较重要的代码,供技术员学习参考 AdminController.class.php <?php namespace A ...
- 某电商网站线上drbd+heartbeat+nfs配置
1.环境 nfs1.test.com 10.1.1.1 nfs2.test.com 10.1.1.2 2.drbd配置 安装drbd yum -y install gcc gcc-c++ make g ...
- JDBC-Eclipse & Mysql & Servlet实现
import java.io.IOException;import java.io.PrintWriter;import java.sql.Connection;import java.sql.Dri ...
- 文件File
前面的话 不能直接访问用户计算机中的文件,一直都是Web应用开发中的一大障碍.2000年以前,处理文件的唯一方式就是在表单中加入<input type="file">字 ...
- MyEclipse10的正确破解方法
无法转载,故给出原文链接,以供需要者. MyEclipse10的正确破解方法