CNN中的卷积核及TensorFlow中卷积的各种实现
声明:
1. 我和每一个应该看这篇博文的人一样,都是初学者,都是小菜鸟,我发布博文只是希望加深学习印象并与大家讨论。
2. 我不确定的地方用了“应该”二字
首先,通俗说一下,CNN的存在是为了解决两个主要问题:
1. 权值太多。这个随便一篇博文都能解释
2. 语义理解。全连接网络结构处理每一个像素时,其相邻像素与距离很远的像素无差别对待,并没有考虑图像内容的空间结构。换句话说,打乱图像像素的输入顺序,结果不变。
然后,CNN中的卷积核的一个重要特点是它是需要网络自己来学习的。这一点很简单也很重要:一般的卷积核如sobel算子、平滑算子等,都是人们根据数学知识得到的,比如求导,平均等等。所以一般的人工卷积核是不能放进卷积层的,这有悖于“学习”的概念。我们神经网络就是要自己学习卷积核的参数。来提取人们想不到甚至是无法理解的空间结构或特征。其他特征包括全局共享(一个卷积核滑动一整张图像),多核卷积(用一个卷积核只能提取一种空间结构或特征)。
最后,说一说TensorFlow中卷积的各种实现API(经常用到的):
import tensorflow as tf #自己去加,下面用tf代替tensorflow模块
1 tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, Name=None)
#输入:
# input: 一个张量。数据类型必须是float32或者float64。记住这个张量为四维[batch, in_height, in_width, in_channels],batch应该是指每次feed给网络的数据的个数,和mini-batch gradient descend有关;中间是长宽两项;最后是通道,灰度为1,RGB等为3
# filter: 输入的卷积核,也是四维[filter_height,filter_width,in_channels,channel_multiplier],前两维是尺寸比如3x3,2x2(注意是可以2x2的,这个涉及到非对称卷积核),第三维等于 in_channels,第四维是输出通道数,也就是你要输出的通道数,也就是你要使用的卷积核数
# strides: 一个长度是4的一维整数类型的数组,一般设为[1,1,1,1],注意第一个和第四个"1”固定不变(我试过改了结果不变,并且没有意义)中间的两个1,就是横向步长和纵向步长,意思是卷积核不一定是一步一步的滑动的。
# padding: 有两个值‘SAME’和'VALID',前者使得卷积后图像尺寸不变;后者尺寸变化
# use_cudnn_on_gpu: 在gpu上处理,tensorflow-gpu都默认设为了True
# data_format=None, Name=None 这两项请博友们自己查查,应该问题不大,Name应该与TensorFlow的图结构以及Session(会话)有关系;data_format的默认值应该为'NHWC',及张量维度的顺序应该是batch个数,高度,宽度和通道数。
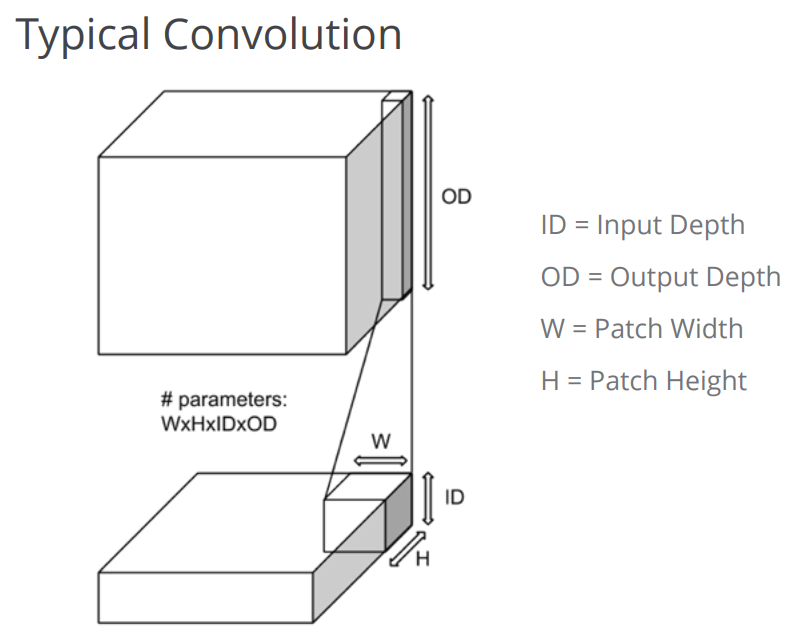
可以说, tf.nn.conv2d就是处理的典型的卷积,例子和图示如下:
input_data =tf.Variable(np.random.rand(10,9,9,3),dtype=np.float32)
filter_data = tf.Variable(np.random.rand(2,2,3,2),dtype=np.float32)
y = tf.nn.conv2d(input_data,filter_data,strides=[2,5,5,3],padding='SAME') #中间5,5大家自己设置一下,自己感受
y.shape
结果是 TensorShape([Dimension(10), Dimension(2), Dimension(2), Dimension(2)])
2 tf.nn.depthwise_conv2d(input, filter, strides, padding, rate=None, name=None, data_format=None)
与1的不同有有两点:
1. depthwise_conv2d将不同的卷积核独立地应用在in_channels的每个通道:我们一般对于三通道图像做卷积,都是先加权求和再做卷积(注意先加权求和再卷积与先卷积再加权求和结果一样),形象化描述就是我先把3通道压扁成1通道,在把它用x个卷积核提溜成x通道(或者我先把3通道用x个卷积核提溜成3x个通道,再分别压扁得到x通道); 而depthwise_conv2d就不加权求和了,直接卷积,所以最后输出通道的总数是in_channels*channel_multiplier
2. rate参数是一个1维向量,of size 2,由两个元素组成,这个参数与atrous convolution(孔卷积)和感受野有关,我下面会给出参考链接。注意, If it is greater than 1, then all values of strides must be 1.
3 tf.nn.separable_conv2d(input, depthwise_filter, pointwise_filter, strides, padding, rate=None, name=None, data_format=None)
#特殊参数:
# depthwise_filter。一个张量,数据维度是四维[filter_height,filter_width,in_channels,channel_multiplier],如1中所述,但是卷积深度是1,如2中所述。
# pointwise_filter。一个张量,数据维度是四维[1,1,in_channels*channel_multiplier,out_channel]
tf.nn.separable_conv2d是利用几个分离的卷积核去做卷积。首先用depthwise_filter做卷积,效果与depthwise_conv2d相同,然后用1x1的卷积核pointwise_filter去做卷积。实例图如下:
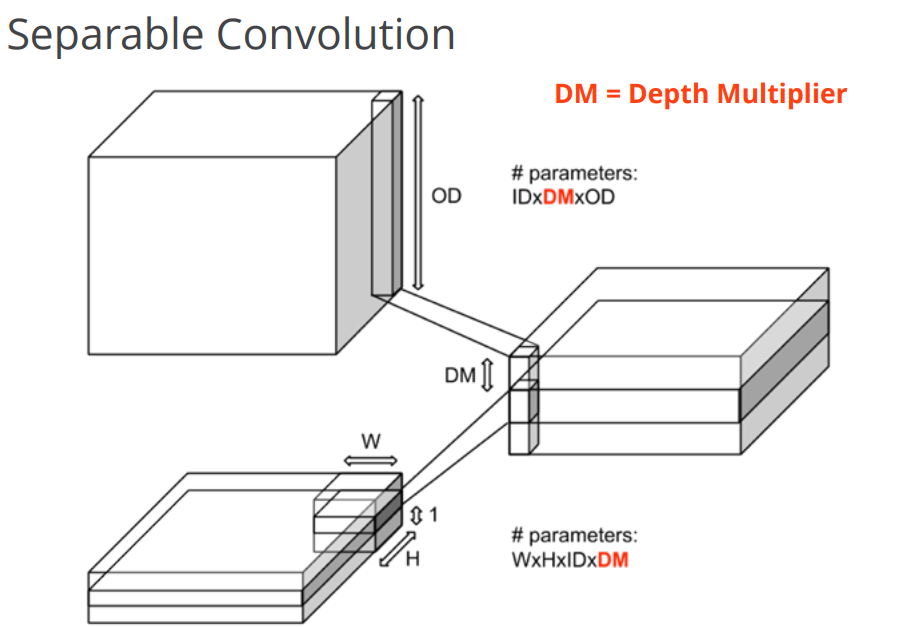
这个理解困难就是最后一步,pointwise_filter是什么?需要说明的是,我只知道原理,我还不知道这样做的目的是什么。最后pointwise原理很简单,就和2中我说过的一样,我先把DM*in_channels(即in_channels*channel_multiplier)个通道压扁成1个通道,再用pointwise_filter这个1*1的卷积核提溜成out_channel个通道,所以pointwise_filter相当于out_channel个scalar。
例子如下:
1 input_data = tf.Variable(np.random.rand(10,9,9,3),dtype=np.float32)
2 depthwise_filter = tf.Variable(np.random.rand(2,2,3,5),dtype=np.float32)
3 pointerwise_filter = tf.Variable(np.random.rand(1,1,15,20),dtype=np.float32)
4 #out_channels >= channel_multiplier * in_channels
5 y =tf.nn.separable_conv2d(input_data, depthwise_filter, pointerwise_filter, strides = [1,1,1,1], padding='SAME')
y.shape
结果是 TensorShape([Dimension(10), Dimension(9), Dimension(9), Dimension(20)])
参考资料:
《深度学习原理与Tensorflow实践》
《TensorFlow技术解析与实战》
Tensorflow(API MASTERT),也就是API Documentation
CNN中的卷积核及TensorFlow中卷积的各种实现的更多相关文章
- TensorFlow中卷积
CNN中的卷积核及TensorFlow中卷积的各种实现 声明: 1. 我和每一个应该看这篇博文的人一样,都是初学者,都是小菜鸟,我发布博文只是希望加深学习印象并与大家讨论. 2. 我不确定的地方用了“ ...
- python/numpy/tensorflow中,对矩阵行列操作,下标是怎么回事儿?
Python中的list/tuple,numpy中的ndarrray与tensorflow中的tensor. 用python中list/tuple理解,仅仅是从内存角度理解一个序列数据,而非数学中标量 ...
- tensorflow中的卷积和池化层(一)
在官方tutorial的帮助下,我们已经使用了最简单的CNN用于Mnist的问题,而其实在这个过程中,主要的问题在于如何设置CNN网络,这和Caffe等框架的原理是一样的,但是tf的设置似乎更加简洁. ...
- Tensorflow中使用CNN实现Mnist手写体识别
本文参考Yann LeCun的LeNet5经典架构,稍加ps得到下面适用于本手写识别的cnn结构,构造一个两层卷积神经网络,神经网络的结构如下图所示: 输入-卷积-pooling-卷积-pooling ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- 第十四节,TensorFlow中的反卷积,反池化操作以及gradients的使用
反卷积是指,通过测量输出和已知输入重构未知输入的过程.在神经网络中,反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积神经网络,没有学习训练的过程.反卷积有着许多特别的应用,一般可以用 ...
- TensorFlow中的卷积函数
前言 最近尝试看TensorFlow中Slim模块的代码,看的比较郁闷,所以试着写点小的代码,动手验证相关的操作,以增加直观性. 卷积函数 slim模块的conv2d函数,是二维卷积接口,顺着源代码可 ...
- 【深度学习】CNN 中 1x1 卷积核的作用
[深度学习]CNN 中 1x1 卷积核的作用 最近研究 GoogLeNet 和 VGG 神经网络结构的时候,都看见了它们在某些层有采取 1x1 作为卷积核,起初的时候,对这个做法很是迷惑,这是因为之前 ...
- TensorFlow 中的卷积网络
TensorFlow 中的卷积网络 是时候看一下 TensorFlow 中的卷积神经网络的例子了. 网络的结构跟经典的 CNNs 结构一样,是卷积层,最大池化层和全链接层的混合. 这里你看到的代码与你 ...
随机推荐
- Spring 日期时间处理
1 Spring自身的支持 1.1 factory-bean <bean id="dateFormat" class="java.text.SimpleDateFo ...
- 浅谈prototype和__proto__
讲prototype前先看一下对象的静态方法和实例方法. function Person () { }; Person.sayHello = function () { //定义一个静态方法 cons ...
- 数据结构与算法系列研究七——图、prim算法、dijkstra算法
图.prim算法.dijkstra算法 1. 图的定义 图(Graph)可以简单表示为G=<V, E>,其中V称为顶点(vertex)集合,E称为边(edge)集合.图论中的图(graph ...
- (one) 条件判断的总结
第一:if语句的一般形式: if(expression) statement1; statement2; 对于条件判断,我觉得要点在于“条件”(expression),它是一个结果为false或t ...
- 《Android进阶》之第一篇 在Java中调用C库函数
在Java代码中通过JNI调用C函数的步骤如下: 第一步:编写Java代码 class HelloJNI{ native void printHello(); native void printStr ...
- 《安卓网络编程》之第五篇 WebView的使用
Android提供了WebView组件,,在Android的所有组件中,WebView的功能是最强大的,是当之无愧的老大.WebView组件本身就是一个浏览器实现,她的内核是基于开源WebKit引擎. ...
- Session Cookie的HttpOnly和secure属性
Session Cookie的HttpOnly和secure属性 一.属性说明: 1 secure属性 当设置为true时,表示创建的 Cookie 会被以安全的形式向服务器传输,也就是只能在 HTT ...
- javaWeb学习总结(5)- HttpServletRequest应用
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过这个对象的相关方法,即可以获得客户的这些信息 ...
- docker安装-centos7
操作系统要求 要安装Docker,您需要64位版本的CentOS 7.步骤: 卸载旧版本 Docker的旧版本被称为docker或docker-engine . 如果这些已安装,请卸载它们以及关联 ...
- 容器扩展属性 IExtenderProvider 实现WinForm通用数据验证组件
大家对如下的Tip组件使用应该不陌生,要想让窗体上的控件使用ToolTip功能,只需要拖动一个ToolTip组件到窗口,所有的控件就可以使用该功能,做信息提示. 本博文要记录的,就是通过容器扩展属性 ...