rsync技术报告(翻译)
本篇为rsync官方推荐技术报告rsync technical report的翻译,主要内容是Rsync的算法原理以及rsync实现这些原理的方法。翻译过程中,在某些不易理解的地方加上了译者本人的注释。
本文目录:
Rsync 算法
Andrew Tridgell Paul Mackerras
Department of Computer Science
Australian National University
Canberra, ACT 0200, Australia
1.1 摘要
本报告介绍了一种将一台机器上的文件更新到和另一台机器上的文件保持一致的算法。我们假定两台机器之间通过低带宽、高延迟的双向链路进行通信。该算法计算出源文件中和目标文件中一致的部分(译者注:数据块一致的部分),然后仅发送那些无法匹配(译者注:即两端文件中不一致的部分)的部分。实际上,该算法计算出了两个机器上两文件之间一系列的不同之处。如果两文件相似,该算法的工作效率非常高,但即使两文件差别非常大,也能保证正确且有一定效率的工作。
1.2 The problem
假设你有两个文件A和B,你希望更新B让它和A完全相同,最直接的方法是拷贝A变为B。
但想象一下,如果这两个文件所在机器之间以极慢的通信链路进行连接通信,例如使用拨号的IP链路。如果A文件很大,拷贝A到B速度是非常慢的。为了提高速度,你可以将A压缩后发送,但这种方法一般只能获得20%到40%的提升。
现在假定A和B文件非常相似,也许它们两者都是从同一个源文件中分离出来的。为了真正的提高速度,你需要利用这种相似性。一个通用的方法是通过链路仅发送A和B之间差异的部分,然后根据差异列表重组文件(译者注:所以还需要创建差异列表,发送差异列表,最后匹配差异列表并重组)。
这种通用方法的问题是,要创建两个文件之间的差异集合,它依赖于有打开并读取两文件的能力。因此,这种方法在读取两文件之前,要求事先从链路的另一端获取文件。如果无法从另一端获取文件,这种算法就会失效(但如果真的从另一端获取了文件,两文件将同在一台机器上,此时直接拷贝即可,没有必要比较这些文件的差异)。rsync就是处理这种问题的。
rsync算法能高效率地计算出源文件和目标已存在文件相同的部分(译者注:即能匹配出相同的数据块)。这些相同的部分不需要通过链路发送出去;所有需要做的是引用目标文件中这些相同的部分来做匹配参照物(译者注:即基准文件basis file)。只有源文件中不能匹配上的部分才会以纯数据的方式被逐字节发送出去。之后,接收端就可以通过这些已存在的相同部分和接收过来的逐字节数据组建成一个源文件的副本。
一般来说,发送到接收端的数据可以使用任意一种常见的压缩算法进行压缩后传输,以进一步提高速度。
1.3 The rsync algorithm
假设我们有两台计算机α和β,α上有可以访问的文件A,β上有可以访问的文件B,且A和B两文件是相似的。α和β之间以低速链路通信。
rsync算法由以下过程组成:
1.β将文件B分割为一系列不重叠且大小固定为S字节(译者注:作者们备注说500到1000字节比较适合)的数据块。当然,最后一个数据块可能小于S字节。
2.β对每个这样的数据块都计算出两个校验码:32位的弱校验码rolling-checksum和128位的强校验码MD4-checksum(译者注:现在的rsync使用的是128位的MD5-checksum)。
3.β将这些校验码发送给α。
4.α将搜索文件A,从中查找出所有长度为S字节且和B中两个校验码相同的数据块(从任意偏移量搜索)。这个搜索和比较的过程可以通过使用弱滚动校验(rolling checksum)的特殊功能非常快速地完成。
(译者注:以字符串123456为例,要搜索出包含3个字符的字符串,如果以任意偏移量的方式搜索所有3个字符长度的字符串,最基本方法是从1开始搜索得到123,从2开始搜索得到234,从3开始搜索得到345,直到搜索完成。这就是任意偏移量的意思,即从任意位置搜索长度为S的数据块)
(译者再注:之所以要以任意偏移量搜索,考虑一种情况,现有两个完全相同的文件A和B,现在向A文件的中间插入一段数据,那么A中从这段数据开始,紧跟其后的所有数据块的偏移量都向后挪动了一段长度,如果不以任意偏移量搜索固定长度数据块,那么从新插入的这段数据开始,所有的数据块都和B不一样,在rsync中意味着这些数据块都要传输,但实际上A和B不同的数据块只有插入在中间的那一段而已)
5.α将一系列的指令发送给β以使其构造出A文件的副本。每个指令要么是对B中数据块的引用,要么是纯数据。这些纯数据是A中无法匹配到B中数据块的数据块部分(译者注:就是A中不同于B的数据块)。
最终的结果是β获取到了A的副本,但却仅发送了A中存在B中不存在的数据部分(还包括一些校验码以及数据块索引数据)。该算法也仅只要求一次链路往返(译者注:第一次链路通信是β发送校验码给α,第二次通信是α发送指令、校验码、索引和A中存在B中不存在的纯数据给β),这可以最小化链路延迟导致的影响。
该算法最重要的细节是滚动校验(rolling checksum)以及与之相关的多备选(multi-alternate)搜索机制,它们保证了所有偏移校验(all-offsets checksum,即上文步骤4中从任意偏移位置搜索数据块)的搜索过程可以处理的非常迅速。下文将更详细地讨论它们。
(译者注:如果不想看算法理论,下面的算法具体内容可以跳过不看(可以看下最后的结论),只要搞懂上面rsync算法过程中做了什么事就够了。)
1.4 Rolling checksum
rsync算法使用的弱滚动校验(rolling checksum)需要能够快速、低消耗地根据给定的缓冲区X1 ...Xn 的校验值以及X1、Xn+1的字节值计算出缓冲区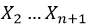 的校验值。
的校验值。
我们在rsync中使用的弱校验算法设计灵感来自Mark Adler的adler-32校验。我们的校验定义公式为:
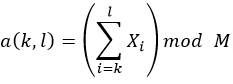

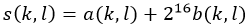
其中s(k,l)是字节 的滚动校验码。为了简单快速地计算出滚动校验码,我们使用
的滚动校验码。为了简单快速地计算出滚动校验码,我们使用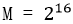 。
。
此校验算法最重要的特性是能使用递归关系非常高效地计算出连续的值。
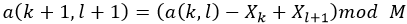

因此可以为文件中任意偏移位置的S长度的数据块计算出校验码,且计算次数非常少。
尽管该算法足够简单,但它已经足够作为两个文件数据块匹配时的第一层检查。我们在实践中发现,当数据块内容不同时,校验码(rolling checksum)能匹配上的概率是很低的。这一点非常重要,因为每个弱校验能匹配上的数据块都必须去计算强校验码,而计算强校验码是非常昂贵的。(译者注:也就是说,数据块内容不同,弱校验码还是可能会相同(尽管概率很低),也就是rolling checksum出现了碰撞,所以还要对弱校验码相同的数据块计算强校验码以做进一步匹配)
1.5 Checksum searching
当α收到了B文件数据块的校验码列表,它必须要去搜索A文件的数据块(以任意偏移量搜索),目的是找出能匹配B数据块校验码的数据块部分。基本的策略是从A文件的每个字节开始依次计算长度为S字节的数据块的32位弱滚动校验码(rolling checksum),然后对每一个计算出来的弱校验码,都拿去和B文件校验码列表中的校验码进行匹配。在我们实现的算法上,使用了简单的3层搜索检查(译者注:3步搜索过程)。
第一层检查,对每个32位弱滚动校验码都计算出一个16位长度的hash值,并将每216个这样的hash条目组成一张hash表。根据这个16位hash值对校验码列表(例如接收到的B文件数据块的校验码集合)进行排序。hash表中的每一项都指向校验码列表中对应hash值的第一个元素(译者注:即数据块ID),或者当校验码列表中没有对应的hash值时,此hash表项将是一个空值(译者注:之所以有空校验码以及对应空hash值出现的可能,是因为β会将那些α上有而β上没有的文件的校验码设置为空并一同发送给α,这样α在搜索文件时就会知道β上没有该文件,然后直接将此文件整个发送给β)。
对文件中的每个偏移量,都会计算它的32位滚动校验码和它的16位hash值。如果该hash值的hash表项是一个非空值,将调用第二层检查。
(译者注:也就是说,第一层检查是比较匹配16位的hash值,能匹配上则认为该数据块有潜在相同的可能,然后从此数据块的位置处进入第二层检查)
第二层检查会对已排序的校验码列表进行扫描,它将从hash表项指向的条目处(译者注:此条目对应第一层检查结束后能匹配的数据块)开始扫描,目的是查找出能匹配当前值的32位滚动校验码。当扫描到相同32位弱滚动校验值时或者直到出现不同16位hash值都没有匹配的32位弱校验码时,扫描终止(译者注:由于hash值和弱校验码重复的概率很低,所以基本上向下再扫描1项最多2项就能发现无法匹配的弱滚动校验码)。如果搜索到了能匹配的结果,则调用第三层检查。
(译者注:也就是说,第二层检查是比较匹配32位的弱滚动校验码,能匹配上则表示还是有潜在相同的可能性,然后从此位置处开始进入第三层检查,若没有匹配的弱滚动校验码,则说明不同数据块内容的hash值出现了重复,但好在弱滚动校验的匹配将其排除掉了)
第三层检查会对文件中当前偏移量的数据块计算强校验码,并将其与校验码列表中的强校验码进行比较。如果两个强校验码能匹配上,我们认为A中的数据块和B中的数据块完全相同。理论上,这些数据块还是有可能会不同,但是概率是极其微小的,因此在实践过程中,我们认为这是一个合理的假设。
当发现了能匹配上的数据块,α会将A文件中此数据块的偏移量和前一个匹配数据块的结束偏移地址发送给β,还会发送这段匹配数据块在B中数据块的索引(译者注:即数据块的ID,chunk号码)。当发现能匹配的数据时,这些数据(译者注:包括匹配上的数据块相关的重组指令以及处于两个匹配块中间未被匹配的数据块的纯数据)会立即被发送,这使得我们可以将通信与进一步的计算并行执行。
如果发现文件中当前偏移量的数据块没有匹配上时,弱校验码将向下滚动到下一个偏移地址并且继续开始搜索(译者注:也就是说向下滚动了一个字节)。如果发现能匹配的值时,弱校验码搜索将从匹配到的数据块的终止偏移地址重新开始(译者注:也就是说向下滚动了一个数据块)。对于两个几乎一致的文件(这是最常见的情况),这种策略节省了大量的计算量。另外,对于最常见的情况,A的一部分数据能依次匹配上B的一系列数据块,这时对数据块索引号进行编码将是一件很简单的事。
1.6 Pipelining
上面几个小章节描述了在远程系统上组建一个文件副本的过程。如果我们要拷贝一系列文件,我们可以将过程流水线化(pipelining the process)以期获得很可观的延迟上的优势。
这要求β上启动的两个独立的进程。其中一个进程负责生成和发送校验码给α,另一个进程则负责从α接收不同的信息数据以便重组文件副本。(译者注:即generator-->sender-->receiver)
如果链路上的通信是被缓冲的,两个进程可以相互独立地不断向前工作,并且大多数时间内,可以保持链路在双方向上被充分利用。
1.7 Results
为了测试该算法,创建了两个不同Linux内核版本的源码文件的tar包。这两个内核版本分别是1.99.10和2.0.0。这个tar包大约有24M且5个不同版本的补丁分隔。
在1.99.10版本中的2441个文件中,2.0.0版本中对其中的291个文件做了更改,并删除了19个文件,以及添加了25个新文件。
使用标准GNU diff程序对这两个tar包进行"diff"操作,结果产生了超过32000行总共2.1 MB的输出。
下表显示了两个文件间使用不同数据块大小的rsync的结果。
|
block size |
matches |
tag hits |
false alarms |
data |
written |
read |
|
300 |
64247 |
3817434 |
948 |
5312200 |
5629158 |
1632284 |
|
500 |
46989 |
620013 |
64 |
1091900 |
1283906 |
979384 |
|
700 |
33255 |
571970 |
22 |
1307800 |
1444346 |
699564 |
|
900 |
25686 |
525058 |
24 |
1469500 |
1575438 |
544124 |
|
1100 |
20848 |
496844 |
21 |
1654500 |
1740838 |
445204 |
在每种情况下,所占用的CPU时间都比在两个文件间直接运行"diff"所需时间少。
表中各列的意思是:
block size:计算校验和的数据块大小,单位字节。
matches:从A中匹配出B中的某个数据块所匹配的次数。(译者注:相比于下面的false matches,这个是true matches)
tag hits:A文件中的16位hash值能匹配到B的hash表项所需的匹配次数。
false alarms:32位弱滚动校验码能匹配但强校验码不能匹配的匹配次数。(译者注:即不同数据块的rolling checksum出现小概率假重复的次数)
data:逐字节传输的文件纯数据,单位字节。
written:α所写入的总字节数,包括协议开销。这几乎全是文件中的数据。
read:α所读取的总字节数,包括协议开销,这几乎全是校验码信息数据。
结果表明,当块大小大于300字节时,仅传输了文件的一小部分(大约5%)数据。而且,相比使用diff/patch方法更新远端文件,rsync所传输的数据也要少很多。
每个校验码对占用20个字节:弱滚动校验码占用4字节,128位的MD4校验码占用16字节。因此,那些校验码本身也占用了不少空间,尽管相比于传输的纯数据大小而言,它们要小的多。
false alarms少于true matches次数的1/1000,这说明32位滚动校验码可以很好地检测出不同数据块。
tag hits的数值表明第二层校验码搜索检查算法大致每50个字符被调用一次(译者注:以block size=1100那行数据为例,50W*50/1024/1024=23M)。这已经非常高了,因为在这个文件中所有数据块的数量是非常大的,因此hash表也是非常大的。文件越小,我们期望tag hit的比例越接近于匹配次数。对于极端情况的超大文件,我们应该合理地增大hash表的大小。
下一张表显示了更小文件的结果。这种情况下,众多文件并没有被归档到一个tar包中,而是通过指定选项使得rsync向下递归整个目录树。这些文件是以另一个称为Samba的软件包为源抽取出来的两个版本,源码大小为1.7M,对这两个版本的文件运行diff程序,结果输出4155行共120kB大小。
|
block size |
matches |
tag hits |
false alarms |
data |
written |
read |
|
300 |
3727 |
3899 |
0 |
129775 |
153999 |
83948 |
|
500 |
2158 |
2325 |
0 |
171574 |
189330 |
50908 |
|
700 |
1517 |
1649 |
0 |
195024 |
210144 |
36828 |
|
900 |
1156 |
1281 |
0 |
222847 |
236471 |
29048 |
|
1100 |
921 |
1049 |
0 |
250073 |
262725 |
23988 |
回到系列文章大纲:http://www.cnblogs.com/f-ck-need-u/p/7048359.html
转载请注明出处:http://www.cnblogs.com/f-ck-need-u/p/7220753.html
rsync技术报告(翻译)的更多相关文章
- rsync工作机制(翻译)
本篇为rsync官方推荐文章How Rsync Works的翻译,主要内容是Rsync术语说明和简单版的rsync工作原理.本篇没有通篇都进行翻译,前言直接跳过了,但为了文章的完整性,前言部分的原文还 ...
- 商汤开源的mmdetection技术报告
目录 1. 简介 2. 支持的算法 3. 框架与架构 6. 相关链接 前言:让我惊艳的几个库: ultralytics的yolov3,在一众yolov3的pytorch版本实现算法中脱颖而出,收到开发 ...
- 技术报告:APT组织Wekby利用DNS请求作为C&C设施,攻击美国秘密机构
技术报告:APT组织Wekby利用DNS请求作为C&C设施,攻击美国秘密机构 最近几周Paloalto Networks的研究人员注意到,APT组织Wekby对美国的部分秘密机构展开了一次攻击 ...
- rsync(四)技术报告
1.1 摘要 本报告介绍了一种将一台机器上的文件更新到和另一台机器上的文件保持一致的算法.我们假定两台机器之间通过低带宽.高延迟的双向链路进行通信.该算法计算出源文件中和目标文件中一致的部分(译者注: ...
- OpenGL中的光照技术(翻译)
Lighting:https://www.evl.uic.edu/julian/cs488/2005-11-03/index.html 光照 OpenGL中的光照(Linghting)是很重要的,为什 ...
- man rsync翻译(rsync命令中文手册)
本文为命令rsync的man文档翻译,几乎所有的选项都翻译了,另外关于筛选规则部分只翻译了一部分.由于原文很多地方都比较啰嗦,所以译文中有些内容可能容易让国人疑惑,所以我个人在某些地方加上了注释.若有 ...
- 第2章 rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释. 以下是本文的姊妹篇: 1.rsync(一):基本命令和用法 2.rsync(二):ino ...
- 第2章 rsync(一):基本命令和用法
本文目录: 2.1 说在前面的话 2.2 rsync同步基本说明 2.3 rsync三种工作方式 2.4 选项说明和示例 2.4.1 基础示例 2.4.2 "--exclude"排 ...
- 第2章 rsync(二):inotify+rsync详细说明和sersync
本文目录: inotify+rsync 1.1 安装inotify-tools 1.2 inotifywait命令以及事件分析 1.3 inotify应该装在哪里 1.4 inotify+rsync示 ...
随机推荐
- laravel 服务容器实现原理
前言 通过实现laravel 框架功能,以便深入理解laravel框架的先进思想. 什么是服务容器 服务容器是用来管理类依赖与运行依赖注入的工具.Laravel框架中就是使用服务容器来实现 ** 控制 ...
- Android应用安全学习笔记前言
Android是基于Linux kernel的一个自由及开放源代码的操作系统,主要用于移动设备.在2011年第一季度超越了塞班系统跃居了全球第一.本系列作为分享的东西吧.比较基础. 文章也不知道会分为 ...
- Spring+SpringMVC+MyBatis深入学习及搭建(十二)——SpringMVC入门程序(一)
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6999743.html 前面讲到:Spring+SpringMVC+MyBatis深入学习及搭建(十一)——S ...
- JSON 转换异常 multipartRequestHandler servletWrapper
下面出现红色的字还有警告,解决方法:本人项目是struts1 from类继承了“extends ActionForm” .把它去掉就行了.如果你是其它的框架一定是继承引起的作个参考吧. ....... ...
- sleep()方法和wait()方法之间有什么差异?
sleep()方法用被用于让程序暂停指定的时间,而wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者nofifyAl()方法 主要的区别是,wait()释放 ...
- jQuery.validate 的form校验
jQuery验证框架 : 基本html代码: <script src="js/jquery-1.9.1.js"></script> <script s ...
- django-xadmin ModelAdmin中定义object_list_template无效的问题
环境:https://github.com/y2kconnect/xadmin-for-python3.git python3.5.2 django1.9.12 object_list_templat ...
- 【Android Developers Training】 94. 创建一个空内容提供器(Content Provider)
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- 【Android Developers Training】 17. 停止和重启一个Activity
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- 页面刷新vuex数据消失问题解决方案
VBox持续进行中,哀家苦啊,有没有谁给个star. vuex是vue用于数据存储的,和redux充当同样的角色. 最近在VBox开发的时候遇到的问题,页面刷新或者关闭浏览器再次打开的时候数据归零.这 ...