Configure Red Hat Enterprise Linux shared disk cluster for SQL Server——RHEL上的“类”SQL Server Cluster功能
下面一步一步介绍一下如何在Red Hat Enterprise Linux系统上为SQL Server配置共享磁盘集群(Shared Disk Cluster)及其相关使用(仅供测试学习之用,基础篇)
一. 创建共享磁盘和 Cluster
微软官方配置文档:https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-shared-disk-cluster-red-hat-7-configure。
Linux Cluster结构图如下:
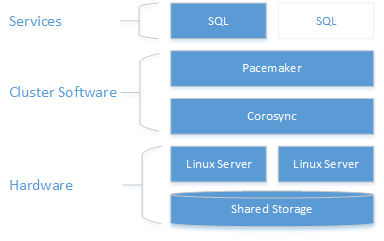
具体配置步骤如下:
1. 安装及配置SQL Server
a) 先安装两个SQL Server作为Cluster的两个节点,请参考博文“SQL Server on Red Hat Enterprise Linux——RHEL上的SQL Server(全截图)”(如果需要更多节点则安装更多);
b) 在Secondary端停掉并禁用SQL Server服务:
sudo systemctl stop mssql-server
sudo systemctl disable mssql-server
c) 备份同步Server Master Key(由于Linux中SQL Server是以本地用户mssql运行的,因此不同的节点无法识别别的节点的认证,所以需要备份同步加密key从Primary端到其它节点上以便于能够成功解密Server Master Key):
- Secondary端备份原来的machine-key:
sudo su
cd /var/opt/mssql/secrets
mv machine-key machine-key.original.bak
- Primary端把machine-key复制到Secondary端:
sudo su
cd /var/opt/mssql/secrets/
scp machine-key root@**<Secondary Node IP Address>**:/var/opt/mssql/secrets/
- Secondary端检查是否成功备份过来并且添加相关权限:
ls

chown mssql:mssql machine-key
d) 在Primary端为Pacemaker程序创建一个SQL登录用户,并给足足够的权限运行sp_server_diagnostics。
先开启SQL Server服务:
sudo systemctl start mssql-server
连接到SQL Server上:
sqlcmd -S localhost -U sa -P **<Your Password>**
执行以下SQL语句创建用户并赋予权限:
USE [master] CREATE LOGIN [<loginName>] with PASSWORD= N'<loginPassword>'
GRANT VIEW SERVER STATE TO <loginName>
GO
退出sqlcmd:
exit
e) 在Primary端停掉并禁用SQL Server服务:
sudo systemctl stop mssql-server
sudo systemctl disable mssql-server
f) 配置每一个节点的hosts文件,保证互相能够识别。
sudo vi /etc/hosts
下图是配置完成后的例子:

2. 配置共享磁盘以及转移数据库文件
有很多种提供共享磁盘的解决方案。下面简单介绍配置NFS的共享磁盘。推荐使用Kerberos去配置NFS以提高安全性:https://www.certdepot.net/rhel7-use-kerberos-control-access-nfs-network-shares/。这里仅介绍最简单的方式用于简单测试和学习。
用NFS配置共享磁盘
找另一个RHEL系统机器作为NFS Server,执行如下命令(由于仅是测试研究,这里选用Cluster的一个节点作为NFS Server也可):
a) 安装NFS软件包:
sudo yum -y install nfs-utils
b) 启用并开启rpcbind服务:
sudo systemctl enable rpcbind && systemctl start rpcbind
c) 启用并开启nfs-server服务:
sudo systemctl enable nfs-server && systemctl start nfs-server
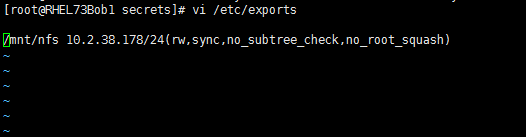
d) 编辑/etc/exports文件去设置想要共享的存储路径,注意每一个共享是一行:
vi /etc/exports
设置完的例子如下:
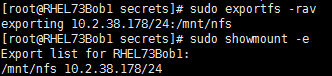
e) 导出共享并确定是否成功:
sudo exportfs -rav
sudo showmount -e
f) 在SELinux中添加异常设置:
sudo setsebool -P nfs_export_all_rw
g) 防火墙中允许相关服务通信:
sudo firewall-cmd --permanent --add-service=nfs
sudo firewall-cmd --permanent --add-service=mountd
sudo firewall-cmd --permanent --add-service=rpc-bind
sudo firewall-cmd --reload
为Cluster所有节点设置NFS
在所有的Cluster节点机器上执行如下命令,确保能访问NFS共享磁盘:
a) 安装NFS软件包:
sudo yum -y install nfs-utils
b) 防火墙中允许相关服务通信:
sudo firewall-cmd --permanent --add-service=nfs
sudo firewall-cmd --permanent --add-service=mountd
sudo firewall-cmd --permanent --add-service=rpc-bind
sudo firewall-cmd --reload
c) 确认是否可以看到NFS共享:
sudo showmount -e **<IP OF NFS SERVER>**
更多关于NFS的文档资源参考以下站点:
- NFS servers and firewalld | Stack Exchange
- Mounting an NFS Volume | Linux Network Administrators Guide
- NFS server configuration
设置数据库文件路径为共享磁盘
转移数据库文件到共享磁盘上:
a) 在Primary节点上先把数据库文件保存到临时路径/var/opt/mssql/tmp下,
su mssql
mkdir /var/opt/mssql/tmp
cp /var/opt/mssql/data/* /var/opt/mssql/tmp
rm /var/opt/mssql/data/*
exit
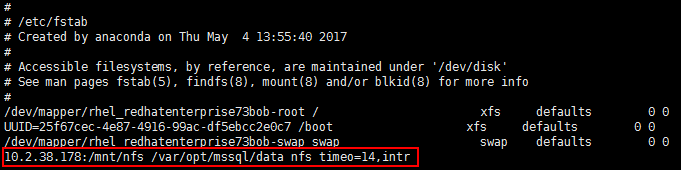
b) 在所有节点上编辑/etc/fstab文件,保证重启系统后自动挂载NFS共享磁盘:
<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=,intr
例子如下:
Note(摘自微软):

关于如何配置Fencing,请参考How To Configure VMware fencing using fence_vmware_soap in RHEL High Availability Add On(RHEL Pacemaker中配置STONITH)。
c) 挂载刚刚配置的NFS存储:
sudo mount -a
可以执行mount命令检测是否已经成功挂载:

d) 在Primary节点上把临时路径下的数据库文件复制到新挂载的路径下,并保证mssql这个本地用户有读写权限:
chown mssql /var/opt/mssql/data
chgrp mssql /var/opt/mssql/data
su mssql
cp /var/opt/mssql/tmp/* /var/opt/mssql/data/
rm /var/opt/mssql/tmp/*
exit
e) 在Primary节点上开启SQL Server服务验证是否成功,这时SQL Server已经使用NFS服务器上的共享磁盘了:
sudo systemctl start mssql-server
sudo systemctl status mssql-server
sudo systemctl stop mssql-server
f) 在其它非Primary节点上依次开启SQL Server服务验证是否成功。
Note:目前所有节点的SQL Server都使用这个NFS服务器共享磁盘了,根据微软推荐,为了防止冲突,需要使用一个File System Cluster资源来防止一个共享路径被挂载多次。
3. 安装及配置Pacemaker
在所有Cluster节点下依次执行以下操作:
a) 创建一个文件保存之前为Pacemaker创建的SQL Server登录用户账户密码信息:
sudo touch /var/opt/mssql/secrets/passwd
sudo echo '<loginName>' >> /var/opt/mssql/secrets/passwd
sudo echo '<loginPassword>' >> /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod /var/opt/mssql/secrets/passwd
b) 设置防火墙允许Pacemaker服务通信:
sudo firewall-cmd --permanent --add-service=high-availability
sudo firewall-cmd --reload
Note:如果使用的是其它防火墙工具,需要开启如下端口。
TCP: Ports 2224, 3121, 21064
UDP: Port 5405
c) 安装Pacemaker软件包:
sudo yum install pacemaker pcs fence-agents-all resource-agents
d) 设置安装Pacemaker和Corosync时创建的默认用户hacluster的密码:
sudo passwd hacluster
e) 启用并开启pcsd服务,以及启用Pacemaker:
sudo systemctl enable pcsd && sudo systemctl start pcsd
sudo systemctl enable pacemaker
f) 安装FCI资源代理:
sudo yum install mssql-server-ha
4. 创建Cluster
下面正式创建Cluster:
a) 在Primary节点上创建Cluster:
sudo pcs cluster auth **<nodeName1 nodeName2 …>** -u hacluster
sudo pcs cluster setup --name **<clusterName>** **<nodeName1 nodeName2 …>**
sudo pcs cluster start --all
例子如下:

b) 目前CTP 2.1中没有HyperV和cloud环境用的fencing,因此暂时需要禁用fencing功能(不推荐在生产环境中禁用)
sudo pcs property set stonith-enabled=false
sudo pcs property set start-failure-is-fatal=false
c) 配置Cluster的相关资源信息,可能需要设置的信息如下:
SQL Server Resource Name——SQL Server资源名字,
Timeout Value ——Cluster等待一个资源起来的超时时间,如果是SQL Server,则是master database启动的时间,
Floating IP Resource Name——虚拟IP资源的名字,
IP Address——用来连接SQL Cluster实例的IP地址,
File System Resource Name——文件系统资源的名字,
device——NFS共享路径,
directory——本地挂载路径,
fstype——文件共享类型,比如nfs。
脚本如下:
sudo pcs cluster cib cfg
sudo pcs -f cfg resource create **<sqlServerResourceName>** ocf:mssql:fci op defaults timeout=**<timeout_in_seconds>**
sudo pcs -f cfg resource create **<floatingIPResourceName>** ocf:heartbeat:IPaddr2 ip=**<ip Address>**
sudo pcs -f cfg resource create **<fileShareResourceName>** Filesystem device=**<networkPath>** directory=**<localPath>** fstype=**<fileShareType>**
sudo pcs -f cfg constraint colocation add **<virtualIPResourceName>** **<sqlResourceName>**
sudo pcs -f cfg constraint colocation add **<fileShareResourceName>** **<sqlResourceName> **
sudo pcs cluster cib-push cfg
例子如下:
sudo pcs cluster cib cfg
sudo pcs -f cfg resource create mssqlha ocf:mssql:fci op defaults timeout=60s
sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.2.38.180
sudo pcs -f cfg resource create fs Filesystem device="10.2.38.178:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs"
sudo pcs -f cfg constraint colocation add virtualip mssqlha
sudo pcs -f cfg constraint colocation add fs mssqlha
sudo pcs cluster cib-push cfg
配置完成后SQL Server会运行在Cluster其中一个节点上。
d) 使用如下命令确认Cluster中相关SQL Server服务是否正常:
sudo pcs status
下图是正常启动的情况:
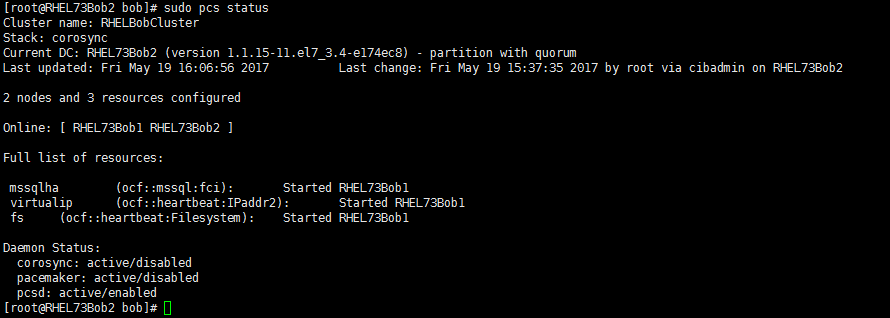
e) 正常启动后就可以用Cluster虚拟IP访问SQL Server了:
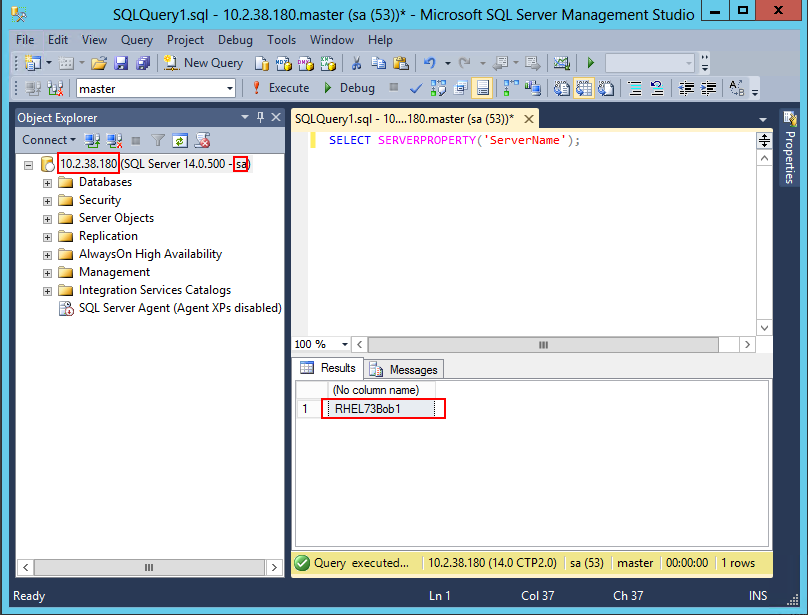
Note:
- 如果某些资源启动的时候有问题,可以使用下面这个命令诊断启动:
sudo pcs resource debug-start **<resource id>**
如果没问题或者有问题修复后,则重启Cluster服务稍微等一段时间就好使了:
sudo pcs cluster stop --all
sudo pcs cluster start --all
2. 管理和使用Cluster(基础篇)
- 微软官方介绍:https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-shared-disk-cluster-red-hat-7-operate。
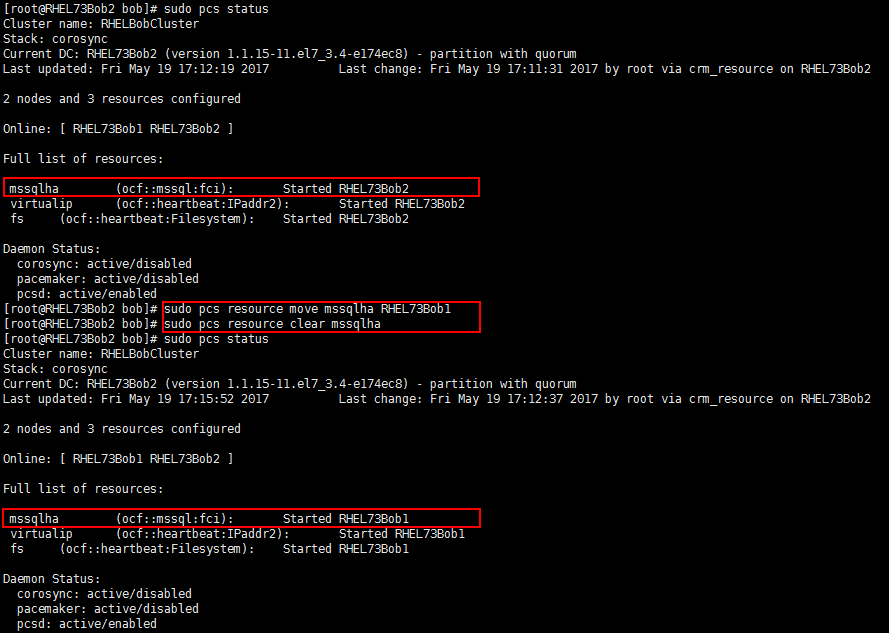
这里暂时只介绍一个常用的功能Failover,可以转移某个资源到目的端节点上:
sudo pcs resource move **<sqlResourceName>** **<targetNodeName>**
sudo pcs resource clear **<sqlResourceName>**
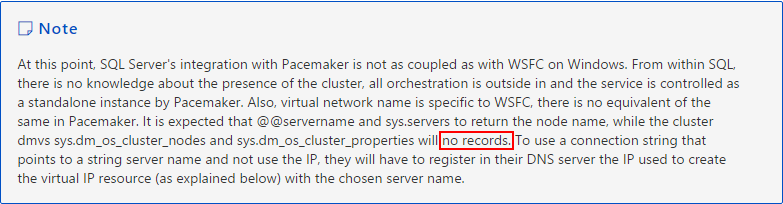
- Linux上为SQL Server搭建的共享磁盘集群系统和Windows SQL Cluster是不一样的(所以标题为“类”),它不能用SQL Query来判断是否是Cluster了,以下命令目前检测不出来是Cluster也获取不到任何信息:
select serverproperty(‘IsClustered’);
select * from ::fn_virtualservernodes();
select * from sys.dm_os_cluster_nodes,sys.dm_io_cluster_shared_drives;
从这个站点可以找到依据,但是不确定未来是否有变化:https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-shared-disk-cluster-red-hat-7-configure。
- Pacemaker是一个在Linux上很成熟的开源高可用性集群。下面这个站点介绍了Pacemaker GUI的使用:https://keithtenzer.com/2015/06/22/pacemaker-the-open-source-high-availability-cluster/?utm_source=tuicool&utm_medium=referral:
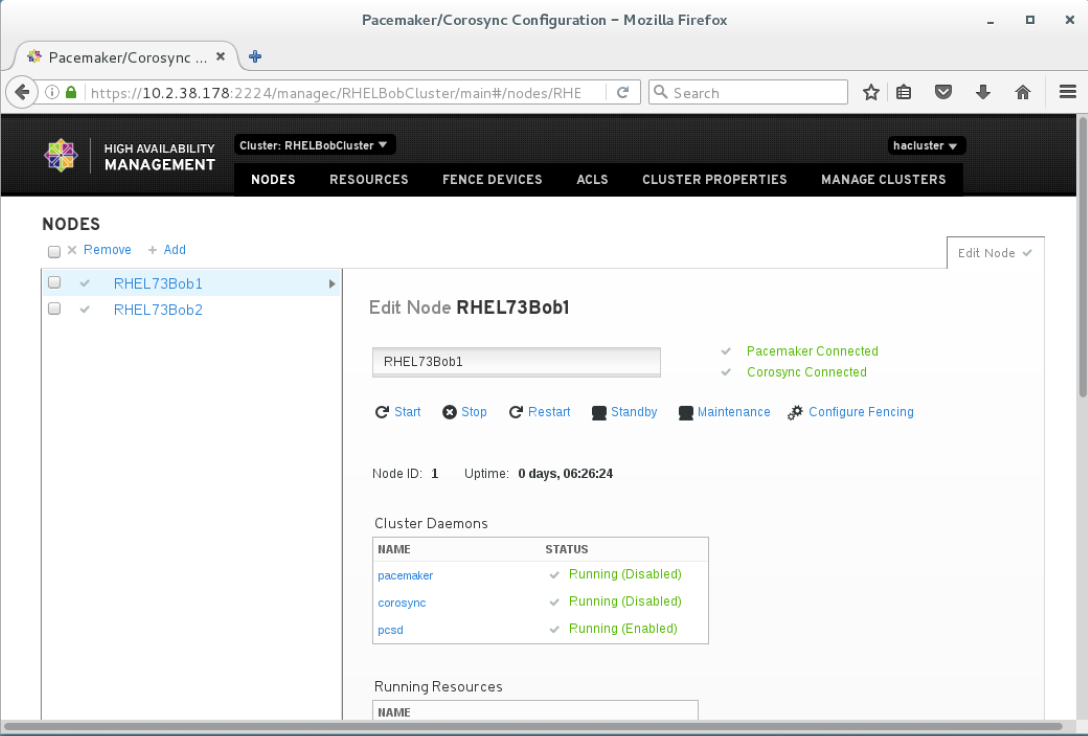
- 其它相关有用的站点:
Note: 文档比较基础,未来可能会继续更新。
[原创文章,转载请注明出处,仅供学习研究之用,如有错误请留言,谢谢支持]
[原站点:http://www.cnblogs.com/lavender000/p/6880355.html,来自永远薰薰]
Configure Red Hat Enterprise Linux shared disk cluster for SQL Server——RHEL上的“类”SQL Server Cluster功能的更多相关文章
- Configure Red Hat Enterprise Linux shared disk cluster for SQL Server
下面一步一步介绍一下如何在Red Hat Enterprise Linux系统上为SQL Server配置共享磁盘集群(Shared Disk Cluster)及其相关使用(仅供测试学习之用,基础篇) ...
- Configure Always On Availability Group for SQL Server on RHEL——Red Hat Enterprise Linux上配置SQL Server Always On Availability Group
下面简单介绍一下如何在Red Hat Enterprise Linux上一步一步创建一个SQL Server AG(Always On Availability Group),以及配置过程中遇到的坑的 ...
- ORACLE Install (10g r2) FOR Red Hat Enterprise Linux Server release 5.5 (64 bit) (转)
OS Info----------# cat /etc/redhat-releaseRed Hat Enterprise Linux Server release 5.5 (Tikanga)# cat ...
- setting up a IPSEC/L2TP vpn on CentOS 6 or Red Hat Enterprise Linux 6 or Scientific Linux
This is a guide on setting up a IPSEC/L2TP vpn on CentOS 6 or Red Hat Enterprise Linux 6 or Scientif ...
- [转] KVM storage performance and cache settings on Red Hat Enterprise Linux 6.2
Almost one year ago, I checked how different cache settings affected KVM storage subsystem performan ...
- Interpreting /proc/meminfo and free output for Red Hat Enterprise Linux 5, 6 and 7
Interpreting /proc/meminfo and free output for Red Hat Enterprise Linux 5, 6 and 7 Solution Verified ...
- Common administrative commands in Red Hat Enterprise Linux 5, 6, and 7
https://access.redhat.com/articles/1189123 Common administrative commands in Red Hat Enterprise Linu ...
- Red Hat Enterprise Linux 6.6安装体验
Red Hat Enterprise Linux 6.6的安装首界面有五个选项,这跟以前的Red Hat Enterprise Linux 5.x的安装界面是有一些区别的. 安装或者升级现有系统( ...
- 如何安装win10+Red Hat Enterprise Linux双系统?
1,如何安装win10+Red Hat Enterprise Linux双系统???? 有很多人(没做过调查,可能就我自己想装吧)想要安装Red Hat Enterprise Linux系统,但是又不 ...
随机推荐
- 搭建ntp 时钟服务器_Linux
一.搭建时间同步服务器1.编译安装ntp serverwget [url]http://www.eecis.udel.edu/~ntp/ntp_spool/ntp4/ntp-4.2.4p4.tar.g ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- [C#] 使用 StackExchange.Redis 封装属于自己的 Helper
使用 StackExchange.Redis 封装属于自己的 Helper 目录 核心类 ConnectionMultiplexer 字符串(String) 哈希(Hash) 列表(List) 有序集 ...
- Android开发 旋转屏幕导致Activity重建解决方法(转)
文章来源:http://www.jb51.net/article/31833.htm Android开发文档上专门有一小节解释这个问题.简单来说,Activity是负责与用户交互的最主要机制,任何“ ...
- 【Android】error opening trace file: No such file or directory (2)
1.问题描述: 运行报错: 12-25 13:35:32.286: E/Trace(1202): error opening trace file: No such file or directory ...
- Entity Framework快速入门--IQueryable与IEnumberable的区别
IEnumerable接口 公开枚举器,该枚举器支持在指定类型的集合上进行简单迭代.也就是说:实现了此接口的object,就可以直接使用foreach遍历此object: IQueryable 接口 ...
- C#调用WebService接口实现天气预报在web前端显示
本文使用web (C#)调用互联网上公开的WebServices接口: (http://www.webxml.com.cn/WebServices/WeatherWebService.asmx)来实现 ...
- Spark名词解释及关系
随着对spark的业务更深入,对spark的了解也越多,然而目前还处于知道的越多,不知道的更多阶段,当然这也是成长最快的阶段.这篇文章用作总结最近收集及理解的spark相关概念及其关系. 名词 dri ...
- RabbitMQ配置与安装
最近这几天身体不舒服,脖子痛的厉害,可能是上月太累了好久没写博客了,之前也说了公司的.Net项目部做了,改用Scale来做,原本想着会用java来搞,所以上个月在拼命的学java,这几天一直脖子不舒服 ...
- 聊聊 Tomcat 的单机多实例
Tomcat 从何而来? 先说 Tomcat 这一单词解释,如果你不是一个开发者,当然它在美国口语中并非是褒义词:如果你是开发者,那你一定听过 Web 应用服务器.Sun 公司和 Tomcat .如你 ...