L1正则化及其推导
\(L1\)正则化及其推导
在机器学习的Loss函数中,通常会添加一些正则化(正则化与一些贝叶斯先验本质上是一致的,比如\(L2\)正则化与高斯先验是一致的、\(L1\)正则化与拉普拉斯先验是一致的等等,在这里就不展开讨论)来降低模型的结构风险,这样可以使降低模型复杂度、防止参数过大等。大部分的课本和博客都是直接给出了\(L1\)正则化的解释解或者几何说明来得到\(L1\)正则化会使参数稀疏化,本来会给出详细的推导。
\(L1\)正则化
大部分的正则化方法是在经验风险或者经验损失\(L_{emp}\)(emprirical loss)上加上一个结构化风险,我们的结构化风险用参数范数惩罚\(\Omega(\theta)\),用来限制模型的学习能力、通过防止过拟合来提高泛化能力。所以总的损失函数(也叫目标函数)为:
\[
J(\theta; X, y) = L_{emp}(\theta; X, y) + \alpha\Omega(\theta) \tag{1.1}
\]
其中\(X\)是输入数据,\(y\)是标签,\(\theta\)是参数,\(\alpha \in [0,+\infty]\)是用来调整参数范数惩罚与经验损失的相对贡献的超参数,当\(\alpha = 0\)时表示没有正则化,\(\alpha\)越大对应该的正则化惩罚就越大。对于\(L1\)正则化,我们有:
\[
\Omega(\theta) = \|w\|_1 \tag{1.2}
\]
其中\(w\)是模型的参数。
几何解释
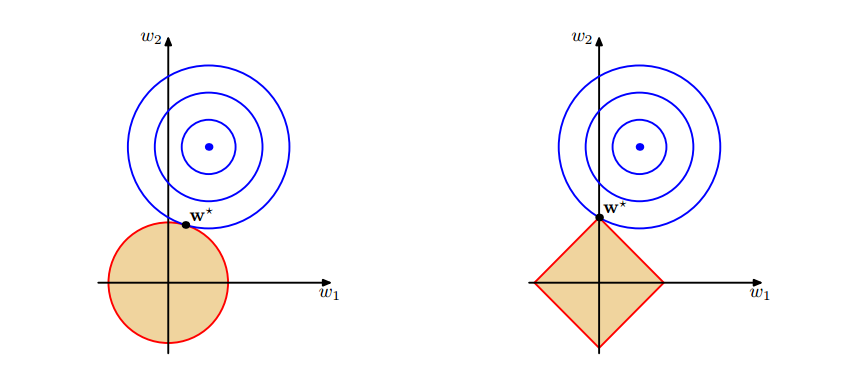
图1 上面中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为$L2$、$L1$正则化给出的限制。
可以看到在正则化的限制之下,\(L2\)正则化给出的最优解\(w^*\)是使解更加靠近原点,也就是说\(L2\)正则化能降低参数范数的总和。\(L1\)正则化给出的最优解\(w^*\)是使解更加靠近某些轴,而其它的轴则为0,所以\(L1\)正则化能使得到的参数稀疏化。
解析解的推导
有没有偏置的条件下,\(\theta\)就是\(w\),结合式\((1.1)\)与\((1.2)\),我们可以得到\(L1\)正则化的目标函数:
\[
J(w; X, y) = L_{emp}(w; X, y) + \alpha\|w\|_1 \tag{3.1}
\]
我们的目的是求得使目标函数取最小值的\(w^*\),上式对\(w\)求导可得:
\[
\nabla_w J(w; X, y) = \nabla_w L_{emp}(w; X, y) + \alpha \cdot sign(w) \tag{3.2}
\]
其中若\(w>0\),则\(sign(w)=1\);若\(w<0\),则\(sign(w) = -1\);若\(w=0\),则\(sign(w)=0\)。当\(\alpha = 0\),假设我们得到最优的目标解是\(w^*\),用秦勤公式在\(w^*\)处展开可以得到(要注意的\(\nabla J(w^*)=0\)):
\[
J(w; X, y) = J(w^*; X, y) + \frac{1}{2}(w - w^*)H(w-w^*) \tag{3.3}
\]
其中\(H\)是关于\(w\)的Hessian矩阵,为了得到更直观的解,我们简化\(H\),假设\(H\)这对角矩阵,则有:
\[
H = diag([H_{1,1},H_{2,2}...H_{n,n}]) \tag{3.4}
\]
将上式代入到式\((3.1)\)中可以得到,我们简化后的目标函数可以写成这样:
\[
J(w;X,y)=J(w^*;X,y)+\sum_i\left[\frac{1}{2}H_{i,i}(w_i-w_i^*)^2 + \alpha_i|w_i| \right] \tag{3.5}
\]
从上式可以看出,\(w\)各个方向的导数是不相关的,所以可以分别独立求导并使之为0,可得:
\[
H_{i,i}(w_i-w_i^*)+\alpha \cdot sign(w_i)=0 \tag{3.6}
\]
我们先直接给出上式的解,再来看推导过程:
\[
w_i = sign(w^*) \max\left\{ |w_i^*| - \frac{\alpha}{H_{i,i}},0 \right\} \tag{3.7}
\]
从式\((3.5)\)与式\((3.6)\)可以得到两点:
- 1.可以看到式\((3.5)\)中的二次函数是关于\(w^*\)对称的,所以若要使式\((3.5)\)最小,那么必有:\(|w_i|<|w^*|\),因为在二次函数值不变的程序下,这样可以使得\(\alpha|w_i|\)更小。
- 2.\(sign(w_i)=sign(w_i^*)\)或\(w_1=0\),因为在\(\alpha|w_i|\)不变的情况下,\(sign(w_i)=sign(w_i^*)\)或\(w_i=0\)可以使式\((3.5)\)更小。
由式\((3.6)\)与上述的第2点:\(sign(w_i)=sign(w_i^*)\)可以得到:
\[
\begin{split}
0 &= H_{i,i}(w_i-w_i^*)+\alpha \cdot sign(w_i^*) \cr
w_i &= w_i^* - \frac{\alpha}{H_{i,i}}sign(w_i^*) \cr
w_i &= sign(w_i^*)|w_i^*| - \frac{\alpha}{H_{i,i}}sign(w_i^*)\cr
&=sign(w_i^*)(|w_i^*| - \frac{\alpha}{H_{i,i}}) \cr
\end{split} \tag{3.8}
\]
我们再来看一下第2点:\(sign(w_i)=sign(w_i^*)\)或\(w_1=0\),若\(|w_i^*| < \frac{\alpha}{H_{i,i}}\),那么有\(sign(w_i) \neq sign(w_i^*)\),所以这时有\(w_1=0\),由于可以直接得到解式\((3.7)\)。
从这个解可以得到两个可能的结果:
- 1.若\(|w_i^*| \leq \frac{\alpha}{H_{i,i}}\),正则化后目标中的\(w_i\)的最优解是\(w_i=0\)。因为这个方向上\(L_{emp}(w; X, y)\)的影响被正则化的抵消了。
- 2.若\(|w_i^*| > \frac{\alpha}{H_{i,i}}\),正则化不会推最优解推向0,而是在这个方面上向原点移动了\(\frac{\alpha}{H_{i,i}}\)的距离。
L1正则化及其推导的更多相关文章
- Laplace(拉普拉斯)先验与L1正则化
Laplace(拉普拉斯)先验与L1正则化 在之前的一篇博客中L1正则化及其推导推导证明了L1正则化是如何使参数稀疏化人,并且提到过L1正则化如果从贝叶斯的观点看来是Laplace先验,事实上如果从贝 ...
- L2与L1正则化理解
https://www.zhihu.com/question/37096933/answer/70507353 https://blog.csdn.net/red_stone1/article/det ...
- L1正则化与L2正则化的理解
1. 为什么要使用正则化 我们先回顾一下房价预测的例子.以下是使用多项式回归来拟合房价预测的数据: 可以看出,左图拟合较为合适,而右图过拟合.如果想要解决右图中的过拟合问题,需要能够使得 $ ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- L1正则化
正则化项本质上是一种先验信息,整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式, ...
- L1正则化和L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合(overfitting):一定程度上,L1也可以防止过拟合 一.L1正则化 1.L1正则化 需注意, ...
- 正则化--L1正则化(稀疏性正则化)
稀疏矢量通常包含许多维度.创建特征组合会导致包含更多维度.由于使用此类高维度特征矢量,因此模型可能会非常庞大,并且需要大量的 RAM. 在高维度稀疏矢量中,最好尽可能使权重正好降至 0.正好为 0 的 ...
- LASSO回归与L1正则化 西瓜书
LASSO回归与L1正则化 西瓜书 2018年04月23日 19:29:57 BIT_666 阅读数 2968更多 分类专栏: 机器学习 机器学习数学原理 西瓜书 版权声明:本文为博主原创文章,遵 ...
随机推荐
- 【Zookeeper】应用场景
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台server运行,但是他们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这应用系统的serve ...
- dotnet使用Selenium执行自动化任务
如果要做百度文库,百度贴吧,百度知道签到,你,会怎么做?前不久我还会觉得这好像太麻烦了,now,soeasy. 自动化测试工具:Selenium Selenium是一个用于Web应用程序测试的工具.S ...
- 进入子shell的各种情况分析
子shell的概念贯穿整个shell,写shell脚本时更是不可不知.所谓子shell,即从当前shell环境新开一个shell环境,这个新开的shell环境就称为子shell(subshell),而 ...
- 阿里云ECS部署ES
背景 最近越来越多的公司把业务搬迁到云上,公司也有这个计划,自己抽时间在阿里云和Azure上做了一些小的尝试,现在把阿里云上部署ES和kibana记录下来.为以后做一个参考,也希望对其他人有帮助. 这 ...
- 线性代数-矩阵-【1】矩阵汇总 C和C++的实现
矩阵的知识点之多足以写成一本线性代数. 在C++中,我们把矩阵封装成类.. 程序清单: Matrix.h//未完待续 #ifndef _MATRIX_H #define _MATRIX_H #incl ...
- 关于回文串的DP问题
问题1:插入/删除字符使得原字符串变成一个回文串且代价最小 poj 3280 Cheapest Palindrome 题意:给出一个由m中字母组成的长度为n的串,给出m种字母添加和删除花费的代价,求让 ...
- hdu3713 Double Maze
Problem Description Unlike single maze, double maze requires a common sequence of commands to solve ...
- TCP协议三次握手与四次挥手通俗解析
TCP/IP协议三次握手与四次握手流程解析 一.TCP报文格式 TCP/IP协议的详细信息参看<TCP/IP协议详解>三卷本.下面是TCP报文格式图: 图1 TCP报文格式 上图中有几个字 ...
- Java的HashMap实现原理整理总结
通过Debug 探寻Java-HashMap 实现原理: 一个简单的例子,代码如下, 测试方法 main: public static void main(String[] args) { KeyOb ...
- 【NOIP2014】子矩阵
这题如果按暴力做只有一半分,最大时间复杂度为O(C(16,8)*C(16,8)); 很容易算出超时: 我们可以发现如果直接dp会很难想,但是知道选哪几行去dp就很好写状态转移方程: dp[i][j]= ...