jaccard similarity coefficient 相似度计算
Jaccard index
The Jaccard index, also known as the Jaccard similarity coefficient (originally coined coefficient de communauté by Paul Jaccard), is a statisticused for comparing the similarity and diversity of sample sets. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets:
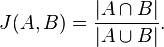
(If A and B are both empty, we define J(A,B) = 1.)
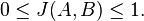
The MinHash min-wise independent permutations locality sensitive hashing scheme may be used to efficiently compute an accurate estimate of the Jaccard similarity coefficient of pairs of sets, where each set is represented by a constant-sized signature derived from the minimum values of ahash function.
The Jaccard distance, which measures dissimilarity between sample sets, is complementary to the Jaccard coefficient and is obtained by subtracting the Jaccard coefficient from 1, or, equivalently, by dividing the difference of the sizes of the union and the intersection of two sets by the size of the union:
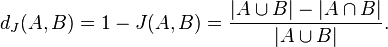
An alternate interpretation of the Jaccard distance is as the ratio of the size of the symmetric difference  to the union.
to the union.
This distance is a metric on the collection of all finite sets.[1][2]
There is also a version of the Jaccard distance for measures, including probability measures. If  is a measure on a measurable space
is a measure on a measurable space  , then we define the Jaccard coefficient by
, then we define the Jaccard coefficient by 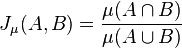 , and the Jaccard distance by
, and the Jaccard distance by  . Care must be taken if
. Care must be taken if 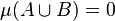 or
or  , since these formulas are not well defined in that case.
, since these formulas are not well defined in that case.
jaccard similarity coefficient 相似度计算的更多相关文章
- Jaccard similarity(杰卡德相似度)和Abundance correlation(丰度相关性)
杰卡德距离(Jaccard Distance) 是用来衡量两个集合差异性的一种指标,它是杰卡德相似系数的补集,被定义为1减去Jaccard相似系数.而杰卡德相似系数(Jaccard similarit ...
- 海量数据相似度计算之simhash和海明距离
通过 采集系统 我们采集了大量文本数据,但是文本中有很多重复数据影响我们对于结果的分析.分析前我们需要对这些数据去除重复,如何选择和设计文本的去重算法?常见的有余弦夹角算法.欧式距离.Jaccard相 ...
- NLP 语义相似度计算 整理总结
更新中 最近更新时间: 2019-12-02 16:11:11 写在前面: 本人是喜欢这个方向的学生一枚,写文的目的意在记录自己所学,梳理自己的思路,同时share给在这个方向上一起努力的同学.写得不 ...
- java算法(1)---余弦相似度计算字符串相似率
余弦相似度计算字符串相似率 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据 ...
- 转:Python 文本挖掘:使用gensim进行文本相似度计算
Python使用gensim进行文本相似度计算 转于:http://rzcoding.blog.163.com/blog/static/2222810172013101895642665/ 在文本处理 ...
- Finding Similar Items 文本相似度计算的算法——机器学习、词向量空间cosine、NLTK、diff、Levenshtein距离
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf 汇总于此 还有这本书 http://www-nlp.stanford.edu/IR-book/ 里面有 ...
- Jaccard Similarity and Shingling
https://www.cs.utah.edu/~jeffp/teaching/cs5955/L4-Jaccard+Shingle.pdf https://www.cs.utah.edu/~jeffp ...
- 使用同一个目的port的p2p协议传输的tcp流特征相似度计算
结论: (1)使用同一个目的port的p2p协议传输的tcp流特征相似度高达99%.如果他们是cc通信,那么应该都算在一起,反之就都不是cc通信流. (2)使用不同目的端口的p2p协议传输的tcp流相 ...
- 孪生网络(Siamese Network)在句子语义相似度计算中的应用
1,概述 在NLP中孪生网络基本是用来计算句子间的语义相似度的.其结构如下 在计算句子语义相似度的时候,都是以句子对的形式输入到网络中,孪生网络就是定义两个网络结构分别来表征句子对中的句子,然后通过曼 ...
随机推荐
- sql server 2005导出数据到oracle
一. 在sql server下处理需要导出的数据库 1. 执行以下sql,查出所有'float'类型的字段名,手动将float类型改为decimal(18,4). select 表名=d.name,字 ...
- 烂泥:mysql数据库使用的基本命令
本文由秀依林枫提供友情赞助,首发于烂泥行天下. 1.连接数据库的格式 mysql -h IP -u用户名 -p密码; 1.1连接远程数据库 mysql -h 192.168.1.214 -uroot ...
- python enumerate函数用法
enumerate函数用于遍历序列中的元素以及它们的下标 i = 0 seq = ['one', 'two', 'three'] for element in seq: print i, seq[i] ...
- 警惕多iframe下的同名id引起的诡异问题
遇到个诡异bug,虽然bug中套bug,忽略次要bug,其中最诡异最典型的现象是多行window.top.$("#id")取值操作,其中有一行却取不到值.这个着实让我费解.因为用到 ...
- 学习OpenStack之 (2):Cinder LVM 配置
0.背景 OpenStack 中的实例是不能持久化的,cinder服务重启,实例消失.如果需要挂载 volume,需要在 volume 中实现持久化.Cinder提供持久的块存储,目前仅供给虚拟机挂载 ...
- [转]学习Nop中Routes的使用
本文转自:http://www.cnblogs.com/miku/archive/2012/09/27/2706276.html 1. 映射路由 大型MVC项目为了扩展性,可维护性不能像一般项目在Gl ...
- NOIP2009 提高组T3 机器翻译 解题报告-S.B.S
题目背景 小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章. 题目描述 这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换.对于每个英文单词,软件会先 ...
- stl学习(二)集合 set 的使用
set集合容器底层由红黑树实现,是平衡二叉搜索树. 相对stl中的list.deque效率更高. 注意:由于集合 的 性质,单纯的 set 不允许重复的元素 初始化 / 清空 函数 : clear() ...
- java list
List:元素是有序的(怎么存的就怎么取出来,顺序不会乱),元素可以重复(角标1上有个3,角标2上也可以有个3)因为该集合体系有索引 ArrayList:底层的数据结构使用的是数组结构(数组长度是可变 ...
- 01Spring_基本jia包的导入andSpring的整体架构and怎么加入日志功能
1.什么是Spring : v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:u ...