Hadoop3 在eclipse中访问hadoop并运行WordCount实例
前言:
毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了。对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环境跑起来,然后在能用的基础上在多想想为什么。
通过这三个礼拜(基本上就是周六周日,其他时间都在加班啊T T)的探索,我目前主要完成的是:
1.在Linux环境中伪分布式部署hadoop(SSH免登陆),运行WordCount实例成功。 http://www.cnblogs.com/PurpleDream/p/4009070.html
2.自己打包hadoop在eclipse中的插件。 http://www.cnblogs.com/PurpleDream/p/4014751.html
3.在eclipse中访问hadoop运行WordCount成功。 http://www.cnblogs.com/PurpleDream/p/4021191.html
所以我下边会分三次记录下我的过程,为自己以后查阅方便,要是能帮助到其他人,自然是更好了!
===============================================================长长的分割线====================================================================
正文:
在之前的两篇文章中,我主要是介绍了自己初次学习hadoop的过程中是如何将hadoop伪分布式模式部署到linux环境中的,以及如何自己编译一个hadoop的eclipse插件。如果大家有需要的话,可以点击我在前言中列出的前两篇文章的链接。
今天,我将在eclipse中,讲解如何使用MapReduce。对于下面的问题,我们首先讲解的是,如何在eclipse中配置DFS Location,然后讲解的是,在配置好的Location上运行WordCount实例。
第一步,配置DFS Location:
1.打开eclipse之后,切换到Map/Reduce模式,点击右下角的“new hadoop Location”图标,弹出一个弹出框,如下图所示,页面中中有两个页签需要配置,分别是General和Advanced Parameters。

2.首先,我们先配置General中内容。General中主要需要我们进行Map/Reduce和HDFS的host的配置。
(1).之前我们在Linux安装hadoop时,曾经修改了两个配置文件,分别是mapred-site.xml和core-site.xml。当时我们再配置的时候,配置的主机就是localhost和端口号。这里由于我们是在eclipse远程访问你Linux服务器中的hadoop,所以我们需要将原来配
置文件中的localhost修改成你服务器的ip地址,端口号不变(当然你可以参考网上的文章,配置host文件)。
(2).然后将eclipse中我们刚才打开的General页签中的Map/Reduce的host配置成你的mapred-site.xml配置的ip地址和端口号;再将HDFS的host配置成你的core-site.xml配置的ip地址和端口号。注意,如果你勾选了HDFS中的那个“Use M/R Master Host”选项,那么HDFS的host将默认与Map/Reduce中配置的ip地址一致,端口号可另行配置。
3.然后,我们要配置的是Advanced Parameters这个选项卡中的内容,这里面的内容比较多,但是不要紧张哦,因为我们在第一次配置时,可以使用他的默认配置。
(1)打开这个选项卡,我们可以浏览一下这里面的内容,着重看下其中选项值包含“/tmp/.....”这种目录结构的选项,如果我们后边自己配置的话,其实要修改的也就是这些项。默认的“dfs.data.dir”是在linux服务器中的“/tmp”目录下,有时会带上你的root账号,这个可以根据自己的需要。
(2).如果你不想使用上边的默认配置,则我们根据自己的需要,在我们安装的hadoop中的hdfs-site.xml文件中,增加对“dfs.data.dir”这个选项的配置,对应的目录自己可以提前建立,我的配置如图:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/dfs_data_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(3).以我的配置为例,如果我在hadoop的服务器端做了这样的配置,那么我在Advanced Parameters选项卡中,需要修改下面的的几个选项的value值,注意,其实有个小技巧,你在配置的时候,先找到“hadoop.tmp.dir”这个选项,将这个选项配置成你自定义的目录位置,然后将Location这个弹出框关掉,再选中刚才的那个Location重新点击右下角的“Edit hadoop Location”选项(在“new hadoop Location”旁边),然后再切换到Advanced Parameters选项卡,会发现与之相关的几个选项的目录前缀都会发生改变,这时候你在浏览一下其他选项,确保目录前缀都进行了修改,就ok了。
dfs.data.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/data dfs.name.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/name dfs.name.edits.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/name fs.checkpoint.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/namesecondary fs.checkpoint.edits.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/namesecondary fs.s3.buffer.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/s3 hadoop.tmp.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir mapred.local.dor => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/local mapred.system.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/system mapred.temp.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/temp mapreduce.jobtracker.staging.root.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/staging
4.经过上边的几步,我们自己的Location已经配置完了,这时候如果没有什么问题的话,会在我们的eclipse的左上角“DFS Location”的下面,显示出我们刚刚配置好的Location,右键点击这个Location的选择“Refresh”或者“ReConnect”,如果之前的配置没有问题的话,会显示我们再第一篇文章中上传的a.txt文件,以及我们之前在linux服务器端运行hadoop成功的output文件夹,如下图。如果没有上传文件,那么只会显示“dfs.data.dir”这个目录。

第二步,运行Word Count实例:
1.Location配置好之后,我们可以在eclipse中建立一个MapReduce项目的工程。
(1).利用反编译软件,从hadoop-1.0.1的安装包中反编译hadoop-examples-1.0.1.jar这个jar包,将其中的Word Count类取出来,放到你刚才建立的工程中。注意,如果你之前参考的在编译eclipse的hadoop插件时,参考的是我的第二篇文章的方法,这里需要加一步,右键点击项目选择buidld Path,对于以“hadoop-”开头的jar包,除了“hadoop-core-1.0.1.jar”和“hadoop-tools-1.0.1.jar”这两个jar包,其余的以“hadoop-”开头的jar包都要删除掉。主要是因为如果不删除,会导致WordCount这个类方法中的有些累引入的不正确。
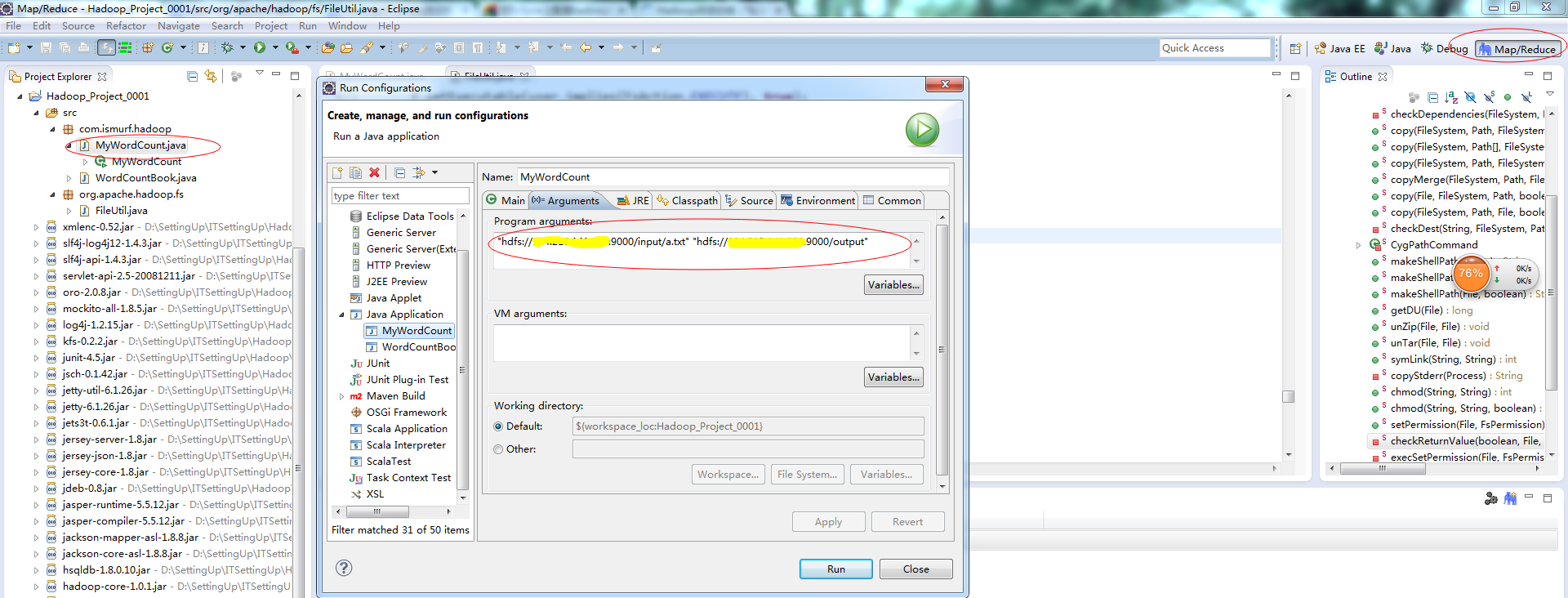
2.项目建立好之后,我们在WordCount类中,右键选择“Run Configurations”弹出一个弹出框,如下图,然后选中“Arguments”选项卡,在其中的“Program arguments”中配置你的hdfs的input文件的目录和output目录,然后点击“run”,运行即可,如果在console中没有抛出异常,证明运行成功,可选择左上角的Location,选择“Refresh”,会显示你的output文件夹以及运行的结果文件。
第三步,错误排除:
1.如果之前的output文件夹存在,你直接在eclipse中运行WordCount方法的话,可能console会报“output文件夹已经存在”这个错误,那么你只需要现将Location中的output文件夹删除,这个错误就不会报了。
2.如果你运行的过程中报了“org.apache.hadoop.security.AccessControlException: Permission denied:。。。。”这个错误,是由于本地用户想要远程操作hadoop没有权限引起的,这时,我们需要在hdfs-site.xml中配置dfs.permissions属性修改为false(默认为true),可以参考本文上边关于“hdfs-site.xml”的配置。
3.如果你运行的过程中报了“Failed to set permissions of path:。。。。”这个错误,解决方法是修改/hadoop-1.0.1/src/core/org/apache/hadoop/fs/FileUtil.java里面的checkReturnValue,注释掉即可(有些粗暴,在Window下,可以不用检查)。注意,此处修改时,网上的一般方法是,重新编译hadoop-core的源码,然后重新打包。其实如果想省事儿一点的话,我们可以在项目中建立一个org.apache.hadoop.fs这个包,将FileUtil.java这个类复制到这个包里面,按照下边图片中的修改方法,修改FileUtil.java就行了。之所以这种方法也行,是因为java运行时,会优先默认在本项目的源码中扫描相同路径的包,然后才是引入的jar文件中的。

经过上边的步骤,我想多数情况下,你已经成功的在eclipse中远程访问了你的hadoop了,也许在你实践的过程中还会碰到其他问题,只要你耐心的在网上搜索资料,相信一定可以解决的,切记不要太着急。
Hadoop3 在eclipse中访问hadoop并运行WordCount实例的更多相关文章
- eclipse中访问不了tomcat首页server Locations变灰无法编辑
eclipse中访问不了tomcat首页server Locations变灰无法编辑 2014年07月25日 14:37:21 wuha0 阅读数:19139更多 个人分类: servlet 解决 ...
- [学习笔记] 在Eclipse中导出可以直接运行的jar,依赖的jar中的类解压后放在运行jar中
前文: [学习笔记] 在Eclipse中导出可以直接运行的jar,依赖的jar打在jar包中 使用7z打开压缩包,查看所有依赖的jar都被解压以包名及class的方式存储在了运行jar中,此时jar的 ...
- [学习笔记] 在Eclipse中导出可以直接运行的jar,依赖的jar打在jar包中
本文需要参考前文: [学习笔记] 在Eclipse中导出可以直接运行的jar,依赖的jar在子目录中 上文是导出的运行的依赖jar被放在了子目录中,本文是将依赖jar放在可运行jar的本身,这样发布的 ...
- hadoop运行wordcount实例,hdfs简单操作
1.查看hadoop版本 [hadoop@ltt1 sbin]$ hadoop version Hadoop -cdh5.12.0 Subversion http://github.com/cloud ...
- hadoop2.6.5运行wordcount实例
运行wordcount实例 在/tmp目录下生成两个文本文件,上面随便写两个单词. cd /tmp/ mkdir file cd file/ echo "Hello world" ...
- Hadoop第6周练习—在Eclipse中安装Hadoop插件及测试(Linux操作系统)
1 运行环境说明 1.1 硬软件环境 1.2 机器网络环境 2 :安装Eclipse并测试 2.1 内容 2.2 实现过程 2.2.1 2.2.2 ...
- 在Eclipse中打开Hadoop工程
1. 安装虚拟机,我用的是VMware Workstation 12 Player 2. 在VM中安装Ubuntu,我用的镜像文件是ubuntu-15.10-desktop-amd64.iso 3. ...
- 在eclipse中导入hadoop jar包,和必要时导入源码包。
1. 解药hadoop包 1, C:\hadoop-2.7.2\share\hadoop 提取出所有的 jar 包, 到 _lib 文件夹下 2,将有含有source 名称的jar包 剪切出来 3, ...
- eclipse中对Hadoop项目进行mvn clean install时报错的处理
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-clean-plugin:2.5:clean (default-clean) ...
随机推荐
- ABP文档 - 本地化
文档目录 本节内容: 简介 应用语言 本地化源 XML文件 注册XML本地化源 JSOn文件 注册JSON本地化源 资源文件 自定义源 获取一个本地文本 在服务端 在MVc控制器里 在MVC视图里 在 ...
- 阿里签名中URLEncode于C#URLEncod不同之处
问题 如上图所示,阿里云的PercentEncode 转换! 为 %21 PercentEncode 源码为: package com.aliyuncs.auth; import java.io.Un ...
- 如何安全的将VMware vCenter Server使用的SQL Server Express数据库平滑升级到完整版
背景: 由于建设初期使用的vSphere vCenter for Windows版,其中安装自动化过程中会使用SQL Server Express的免费版数据库进行基础环境构建.而此时随着业务量的增加 ...
- 当web.config文件放置在共享目录下(UNC),启动IIS会提示有错误信息500.19,伴随有错误代码0x80070003和错误代码0x80070005的解决办法
最近遇到一个很有意思的使用环境,操作人员将所有的网站应用内容投放到共享存储里面,并且使用微软的SMB协议将其以CIFS的方式共享出来,使用Windows Server 2008 R2的IIS将其连接起 ...
- 谈谈JS的观察者模式(自定义事件)
呼呼...前不久参加了一个笔试,里面有一到JS编程题,当时看着题目就蒙圈...后来研究了一下,原来就是所谓的观察者模式.就记下来...^_^ 题目 [附加题] 请实现下面的自定义事件 Event 对象 ...
- jQuery幻灯片插件autoPic
原文地址:Jquery自定义幻灯片插件 插件效果图: 演示地址:autoPic项目地址:autoPic 欢迎批评指正!
- Python 基础之一变量和赋值
变量:程序在运行的时候会用到很多临时存储数据,这个时候就用到了变量,临时数据的名字. Python中变量不需要声明,直接可以使用,变量的数据类型由赋值确定. >>> name=&qu ...
- Javascript高性能编程-提高Dom访问速度
在浏览器中对于Dom的操作和普通的脚本的操作处于两个不同的dll中,两个dll的交互是比较耗时的,优化对Dom的操作可以提高脚本的执行速度.下面是对如何优化的一些总结: 将需要多次操作的节点存储在一个 ...
- 易用BPM时代,软件开发者缘何选择H3?
近年来,企业级软件开发市场暗流汹涌,呈现出多种态势.软件开发团队规模趋于小型化,工作方式趋于快捷化,超过半数的软件开发者在工作中会选择使用易用的软件开发工具.随着流程管理越来越受到企业的重视,流程开发 ...
- maven 快照
大型应用软件一般由多个模块组成,一般它是多个团队开发同一个应用程序的不同模块,这是比较常见的场景.例如,一个团队正在对应用程序的应用程序,用户界面项目(app-ui.jar:1.0) 的前端进行开发, ...