HBase在特征工程中的应用
前言
HBase是一款分布式的NoSQL DB,可以轻松扩展存储和读写能力。
主要特性有:
按某精确的key获取对应的value(Get)
通过前缀匹配一段相邻的数据(Scan)
多版本
动态列
服务端协处理器(可以支持用户自定义)
TTL:按时间自动过期
今天我们来聊一聊HBase以上特性在特征工程中的应用,先从最简单的获取一条数据说起:
应用场景介绍
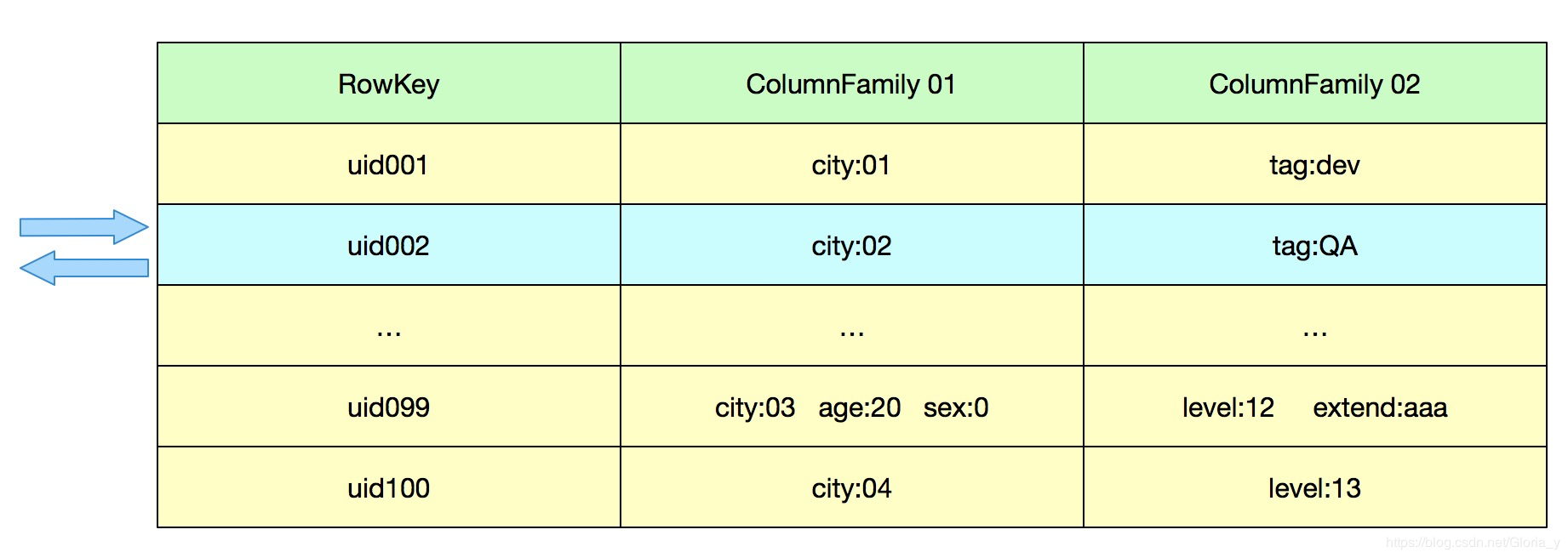
Get
这是HBase中最简单的一个查询操作,根据id读某一个id的属性
比如根据用户id获取这个用户的 城市,年龄,标签等信息
进阶-前缀匹配扫描-Scan
常见场景:
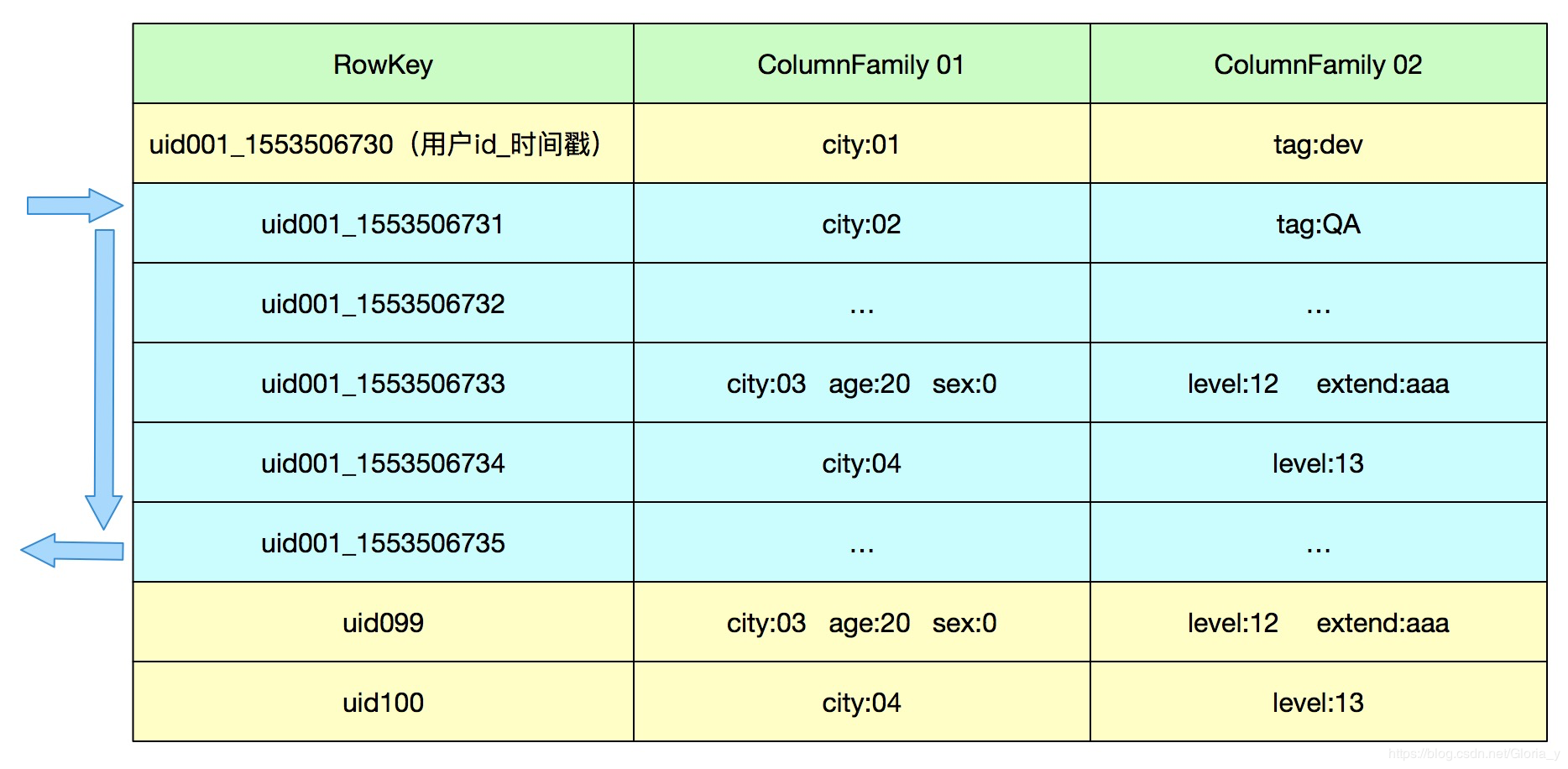
下图是经典的scan用法
hbase中rowkey是按字典序排列
因此非常经典的用法为:
rowkey: 散列(用户id)_时间戳
然后这样就可以通过制定startkey,endkey来扫描一段时间内的数据,并且这些数据是存储在一起的
HBase天生对Scan(扫描)操作有良好的支持,
这里要从HBase的存储特点说起:
NoSQL DB有两种常见的分散数据的方案,一种是按完整的key做hash,数据完全是分散的,另外一种是按Range划分,连续的key存储上是相邻的,这样可以通过在rowkey上做一些业务逻辑的拼接,使得在扫描一定量级逻辑连续的数据的时候,直接扫描的同一块文件下的数据,而不是到分散的各个机器上去查找
HBase选择的是第二种方式来存储数据
1.相邻数据通过scan前缀匹配查询
例如:查某一个用户一个时间段内的数据
2.为scan操作赋能——Filter
可以根据rowkey,列等维度设置过滤器,减少服务端到客户端的数据传输
Tips:过滤器是个好东西,需要的过滤操作在服务端都进行完了,减少了网络传输,只返回符合条件的数据。
但是因为符合条件的数据,可能是在设置的范围中最后一条,所以实际扫描的数据还是Scan的startkey到endkey之间的,还是要注意扫描的范围不要过大
3.使用Scan的正确姿势
经过一定的测试和实践,我们发现持续的进行Scan,稳定可控的并发下,发起Scan,每次Scan 1000条的时候最佳
因为此场景下HBase的RPC队列会得到快速的消费,从而有能力处理新的请求,而不是一直堆积等待一个大的请求的完成
很多同学看到可以做扫描操作,就希望通过扫描操作来查询几百万几千万甚至更多的数据来代替HIVE?
如果是希望一次性读大量数据的时候(比如加载一个月的几百万用户明细数据,或者通过一个月所有用户明细做聚合),不如直接跑离线任务读文件或者使用预聚合的NoSQL 引擎比较好。
短小快的请求则可以通过HBase的cache,文件的index,bloomfilter等特性来施展更多。
Tips:Get就是一个只读一行的小Scan
灵活的动态列
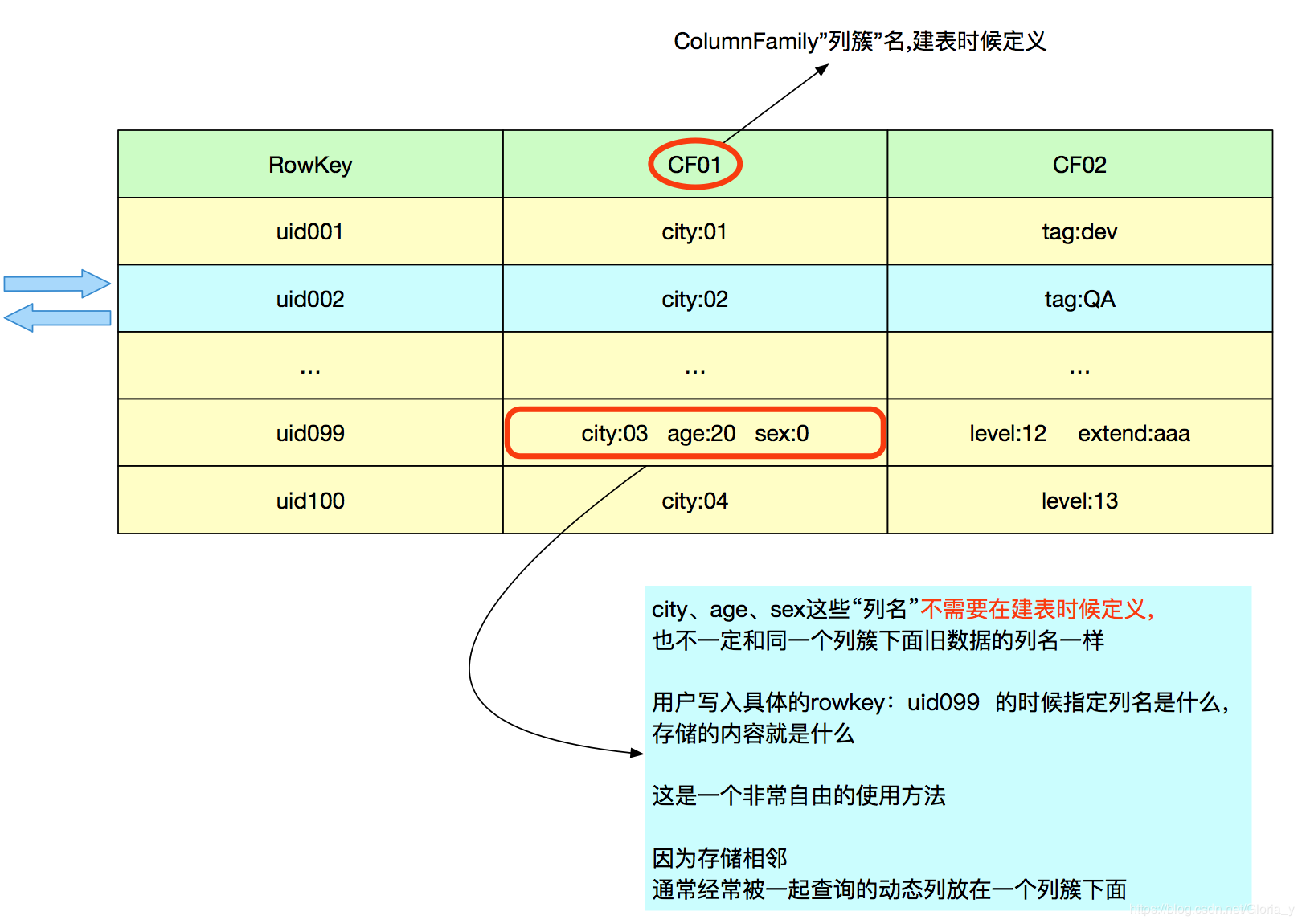
传统数据库以及大部分数据存储需要在建表的时候定义好“字段”,
但是实际应用的时候,比如特征训练中,有很多场景是“字段”或者tag不确定的情况
HBase的动态列则很好的解决了这个问题
1.建表不需要指定列名
2.一次取出一个rowkey所有动态列或者多个动态列
3.也可以table.get( list ),一次获取多个id对应的数据
在实际应用中的使用:
实际应用中,HBase的每一个Column对应一个特征,RowKey的设计为 md5(业务ID)+时间戳,md5用来对ID散列,使数据均匀分布在不同Region上,时间戳用来在SCAN操作时对时间遍历
摘抄自用户的way社区文章:http://way.xiaojukeji.com/article/13662
多版本
HBase中可以查看版本的N个历史版本,通过数据的时间戳实现的
常见场景:
查看某特征随时间变化情况
或者
当发现计算不符合预期的时候,回溯查询某一个id某特征的历史版本
原理简述:
HBase的每条数据都是带时间戳信息的,
会按rowkey,列簇,列,时间戳有序排列,默认会查询到指定的rowkey,列簇,列的最新时间戳的value
而指定查询历史N个版本,就会从最新的数据往前找N个时间戳对应的版本
快照
HBase可以导出快照文件,来进行离线分析
常见场景:
需要获取表中所有数据或者大部分数据的时候,可以通过快照方式,将截止到某一时间的数据文件导出到离线集群,来进行数据分析
原理简述:
数据实时写入HBase,触发快照操作的时候,实时写入的数据会落盘,落盘的文件不会再被修改,HBase内部会记录当前有哪些文件(生成引用),后续可以将快照引用对应的实际数据文件导出到Hadoop进行MR或Spark分析
Tips:导出文件对磁盘IO有一定压力,因此导出操作也是会进行限流的
总结
本文介绍了HBase在特征训练数据存储方面常用的几个特性:Get,Scan,动态列,多版本,以及具体应用场景。
版权声明:本文为博主原创文章,转载请附上博文链接!
HBase在特征工程中的应用的更多相关文章
- 特征工程中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选自变 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- Auto-ML之自动化特征工程
1. 引言 个人以为,机器学习是朝着更高的易用性.更低的技术门槛.更敏捷的开发成本的方向去发展,且Auto-ML或者Auto-DL的发展无疑是最好的证明.因此花费一些时间学习了解了Auto-ML领域的 ...
- <转>特征工程(二)
出处: http://blog.csdn.net/longxinchen_ml/article/details/50493845, http://blog.csdn.net/han_xiaoyang/ ...
- <转>特征工程(一)
转自http://blog.csdn.net/han_xiaoyang/article/details/50481967 1. 引言 再过一个月就是春节,相信有很多码农就要准备欢天喜地地回家过(xia ...
- Sklearn与特征工程
Scikit-learn与特征工程 “数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这句话很好的阐述了数据在机器学习中的重要性.大部分直接拿过来的数据都是特征不明显的.没有经过处理的或者说 ...
- 《转发》特征工程——categorical特征 和 continuous特征
from http://breezedeus.github.io/2014/11/15/breezedeus-feature-processing.html 请您移步原文观看,本文只供自己学习使用 连 ...
- 手把手教你用Python实现自动特征工程
任何参与过机器学习比赛的人,都能深深体会特征工程在构建机器学习模型中的重要性,它决定了你在比赛排行榜中的位置. 特征工程具有强大的潜力,但是手动操作是个缓慢且艰巨的过程.Prateek Joshi,是 ...
- 机器学习-特征工程-Feature generation 和 Feature selection
概述:上节咱们说了特征工程是机器学习的一个核心内容.然后咱们已经学习了特征工程中的基础内容,分别是missing value handling和categorical data encoding的一些 ...
随机推荐
- 《你们都是魔鬼吗》第八次团队作业 第二天Alpha
<你们都是魔鬼吗>第八次团队作业:Alpha冲刺 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 你们都是魔鬼吗 作业学习目标 完成最 ...
- python实现抽样分布描述
本次使用木东居士提供数据案例,验证数据分布等内容, 参考链接:https://www.jianshu.com/p/6522cd0f4278 #数据读取 df = pd.read_excel('C:// ...
- Vue 项目环境搭建
Vue项目环境搭建 ''' 1) 安装node 官网下载安装包,傻瓜式安装:https://nodejs.org/zh-cn/ 2) 换源安装cnpm >: npm install -g cnp ...
- Monitor 实现阻塞队列 + 生产消费者实例
转载至 https://www.codeproject.com/Articles/28785/Thread-synchronization-Wait-and-Pulse-demystified /* ...
- Python3.X下安装Scrapy
Python3.X下安装Scrapy (转载) 2017年08月09日 15:19:30 jingzhilie7908 阅读数:519 标签: python 相信很多同学对于爬虫需要安装Scrap ...
- CF827D Best Edge Weight 题解
题意: 给定一个点数为 n,边数为 m,权值不超过 \(10^9\) 的带权连通图,没有自环与重边. 现在要求对于每一条边求出,这条边的边权最大为多少时,它还能出现在所有可能的最小生成树上,如果对于任 ...
- Hello 2019【A,B,C】
#include<bits/stdc++.h> using namespace std; #define int long long signed main(){ string str; ...
- 012——软件安装之_matlab2019安装
(一)参考文献:https://www.isharepc.com/14196.html (二)下载地址: 链接:https://pan.baidu.com/s/1gq06TuBWGr1Qc4owpRX ...
- 结构化异常SEH处理机制详细介绍(一)
结构化异常处理(SEH)是Windows操作系统提供的强大异常处理功能.而Visual C++中的__try{}/__finally{}和__try{}/__except{}结构本质上是对Window ...
- package.json 版本号解释
经常看到package.json中的各种版本号记录 比如 ~ ^ 等.其实是有个规范的.其遵循 semver. 具体的网站为: http://semver.org/lang/zh-CN/