利用Python进行数据分析 第5章 pandas入门(1)
pandas库,含有使数据清洗和分析工作变得更快更简单的数据结构和操作工具。pandas是基于NumPy数组构建。
pandas常结合数值计算工具NumPy和SciPy、分析库statsmodels和scikitlearn,和可视化库matplotlib等工具一同使用。
5.1 pandas数据结构介绍
pandas的主要数据结构:Series和DataFrame
(1)Series
Series是一种类似于一维数组的对象,由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成:
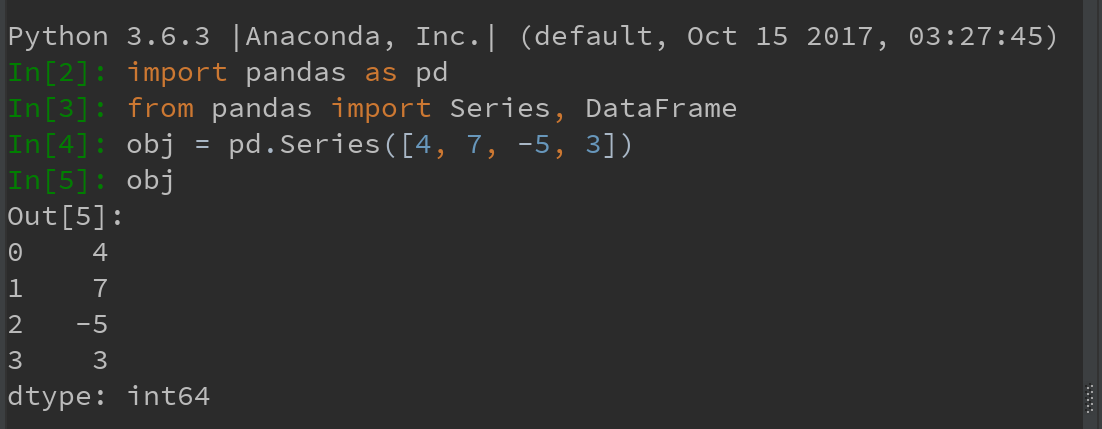
可通过Series的values和index属性获取其数组表示形式和索引对象:

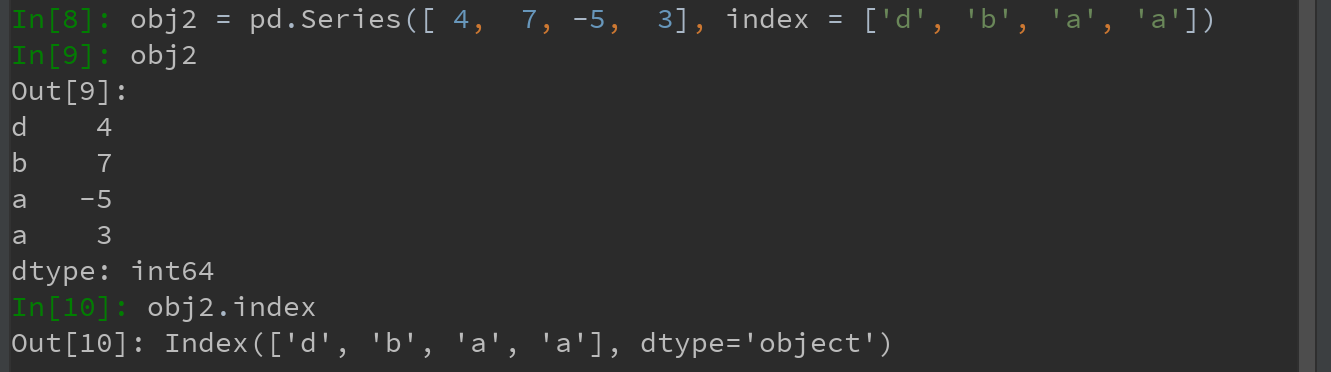
可创建自定义的索引(Series的索引可以通过赋值的方式就地修改):
1)与普通NumPy数组相比,可通过索引的方式选取Series中的单个或一组值:



3)还可将Series看成是一个定长的有序字典,因为它是索引值到数据值的一个映射(故它可用在许多原本需要字典参数的函数中):

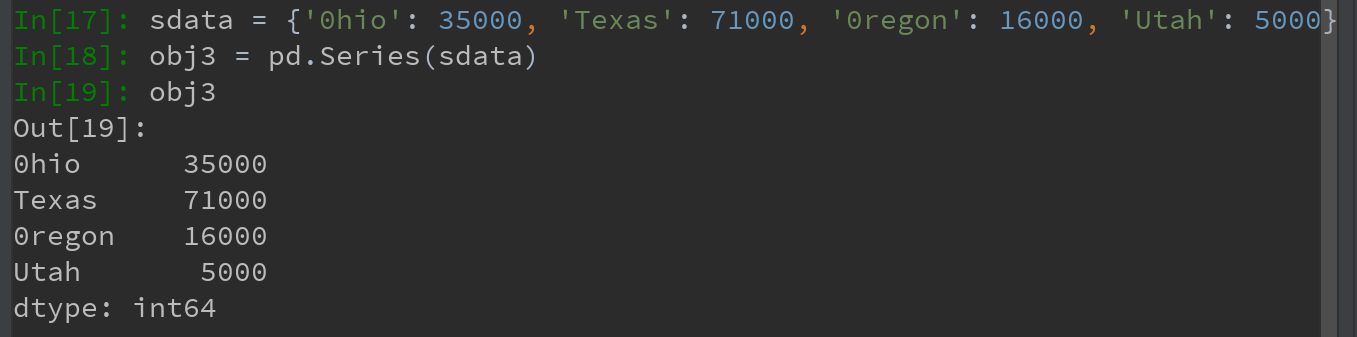
4)若数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series:
如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。
5)可传入排好序的字典的键以改变顺序:
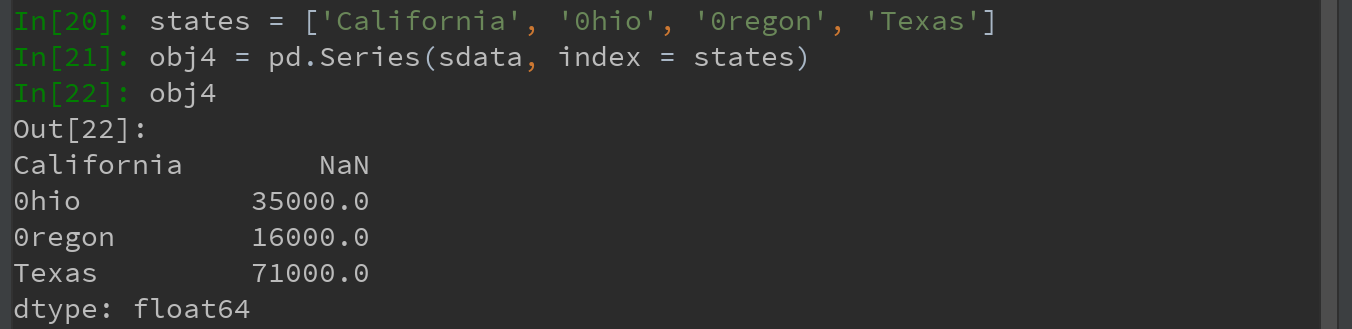
注意:California为新增的州,在sdata中找不到值,故结果为NaN(“非数字”, Not a Number);原sdata中的Utah不在states中,故被从结果中剔除。
6)pandas用isnull和notnull函数检测缺失数据(Series也有类似的实例方法 .isnull() ):

Series类似的实例方法 .isnull() :

*** 7)Series最重要的一个功能:根据运算的索引标签自动对齐数据!(类似数据库的join操作)
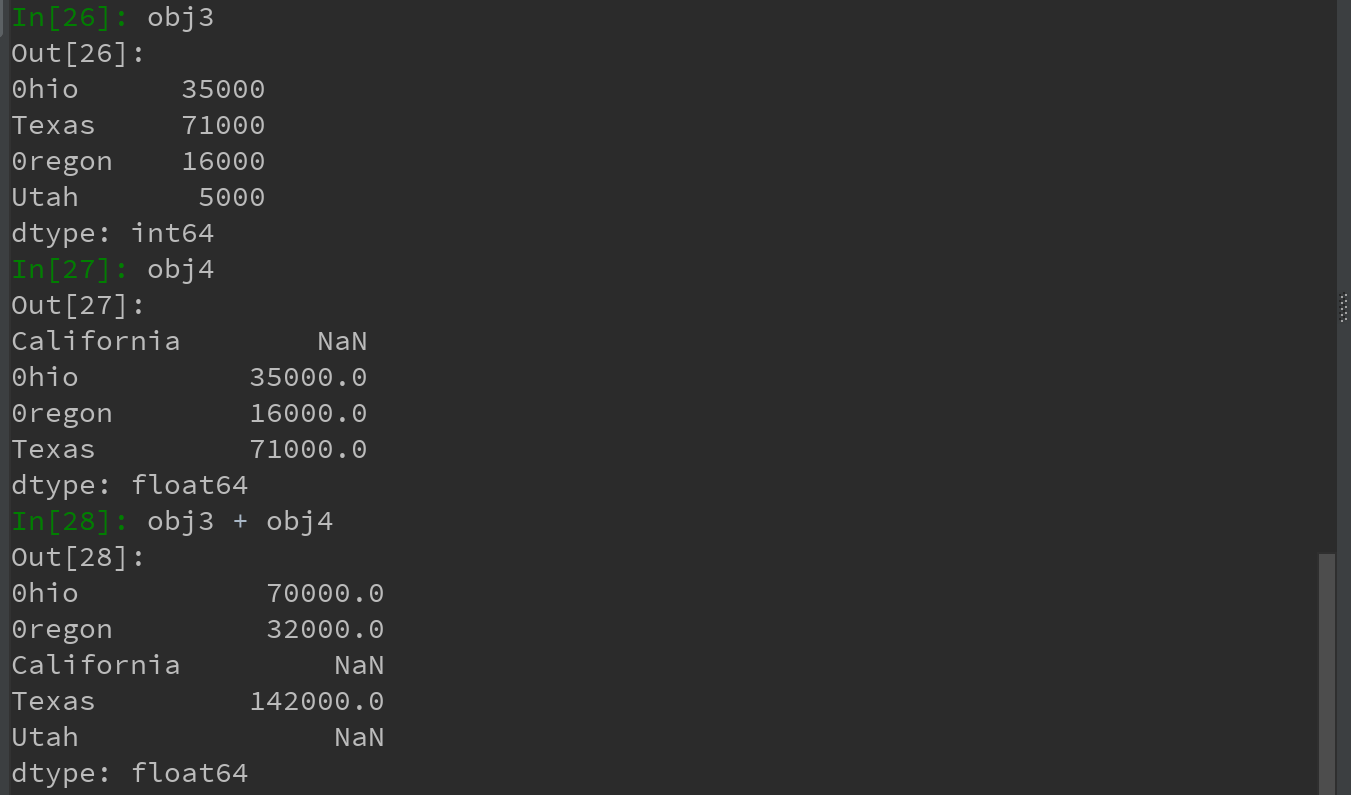
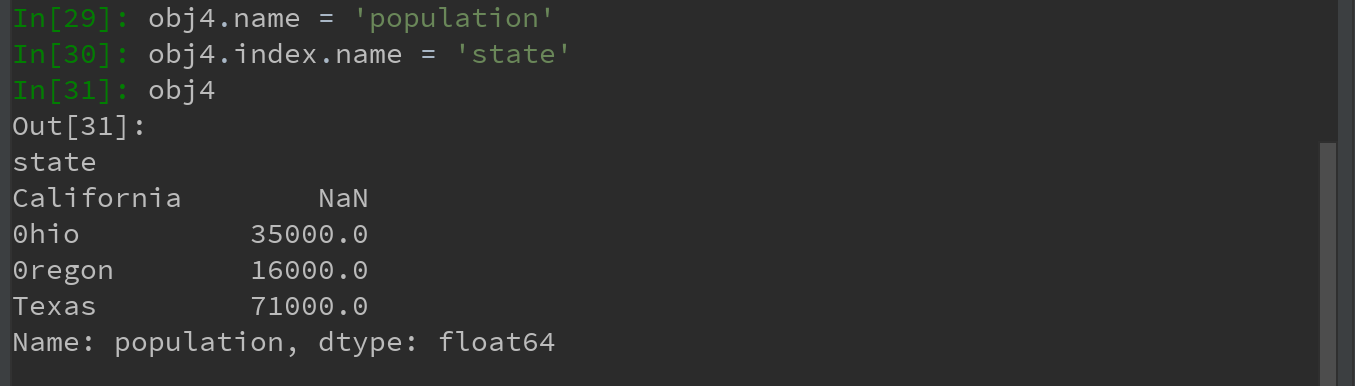
8)Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
(2)DataFrame
DataFrame是一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既又行索引也有列索引,可以被看做由Series组成的字典(共用同一个索引)。
1.1 )最常用的DataFrame创建方式
直接传入一个由等长列表或NumPy数组组成的字典:
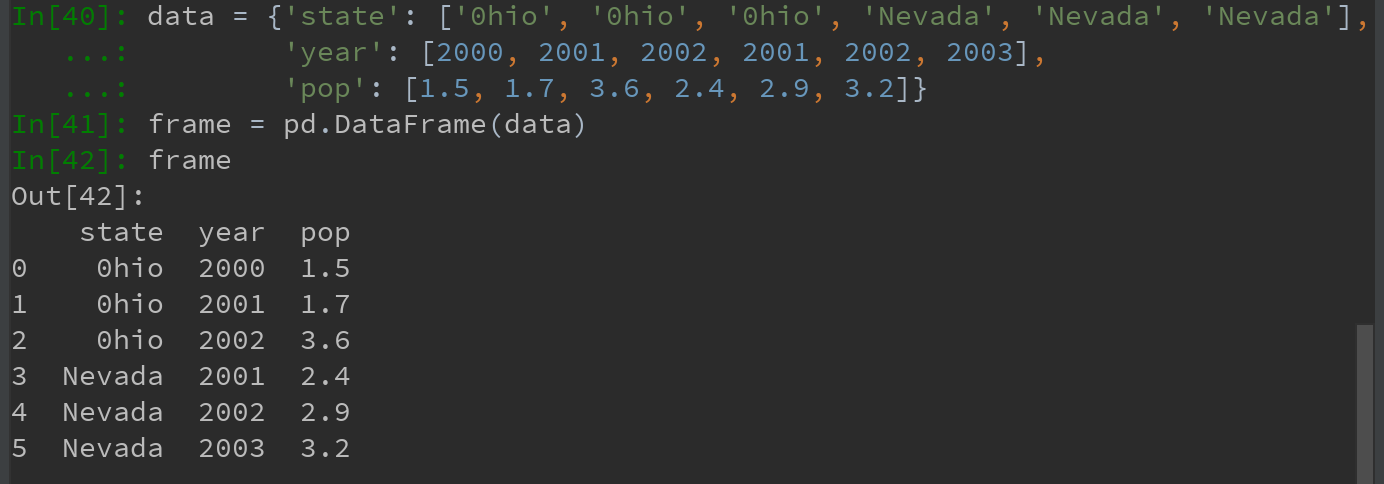
注:结果DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列
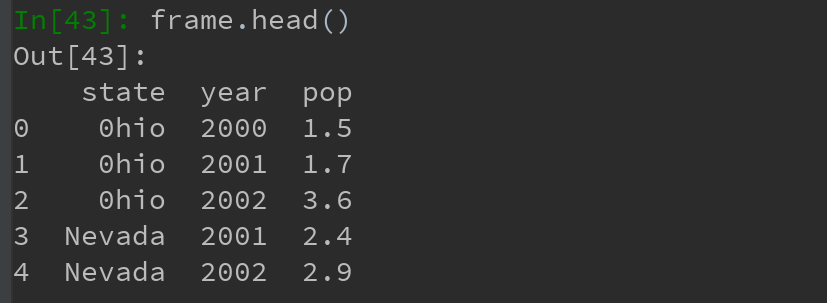
.head() 方法可用于选取前五行:
DataFrame可通过指定列序列,对所有列按照指定顺序进行排列:
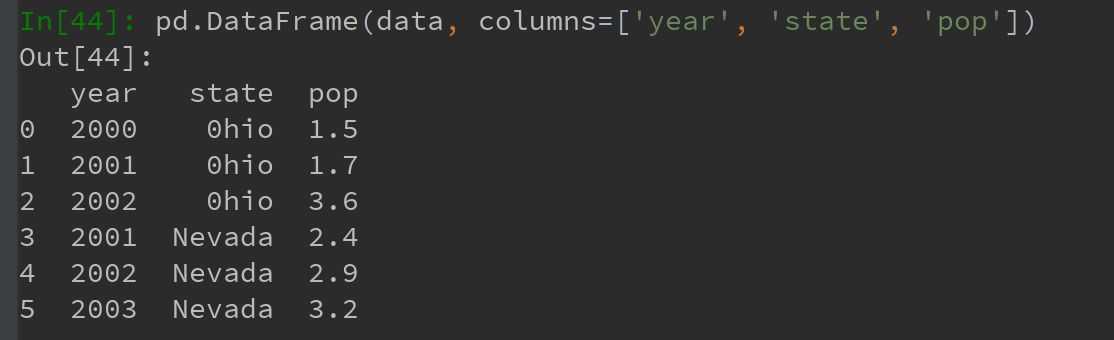
如果传入的列在数据中找不到,就会在结果中产生缺失值:

1.2 )另一种常见的DataFrame数据创建形式是嵌套字典
用嵌套字典传给DataFrame,pandas会被解释为:外层字典的键作为列,内层键作为行索引


内层字典的键会被合并、排序以形成最终的索引。如果明确指定了索引,则会按指定顺序进行排列:

1.3 )由Series组成的字典差不多一样的用法
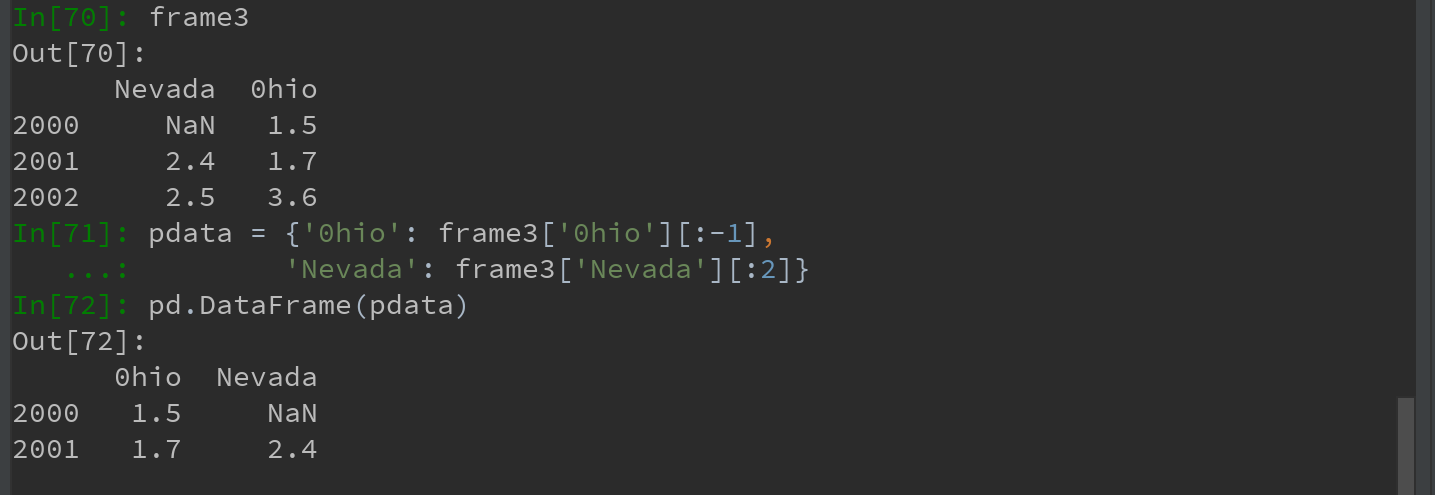
2)将DataFrame的列获取为一个Series
通过类似字典标记的方式:

属性访问的方式:

注:返回的Series拥有原DataFrame相同的索引
3)通过位置或名称的方式获取行的Series

Ps:loc属性详解:???
4)通过赋值的方式,可以对列进行修改
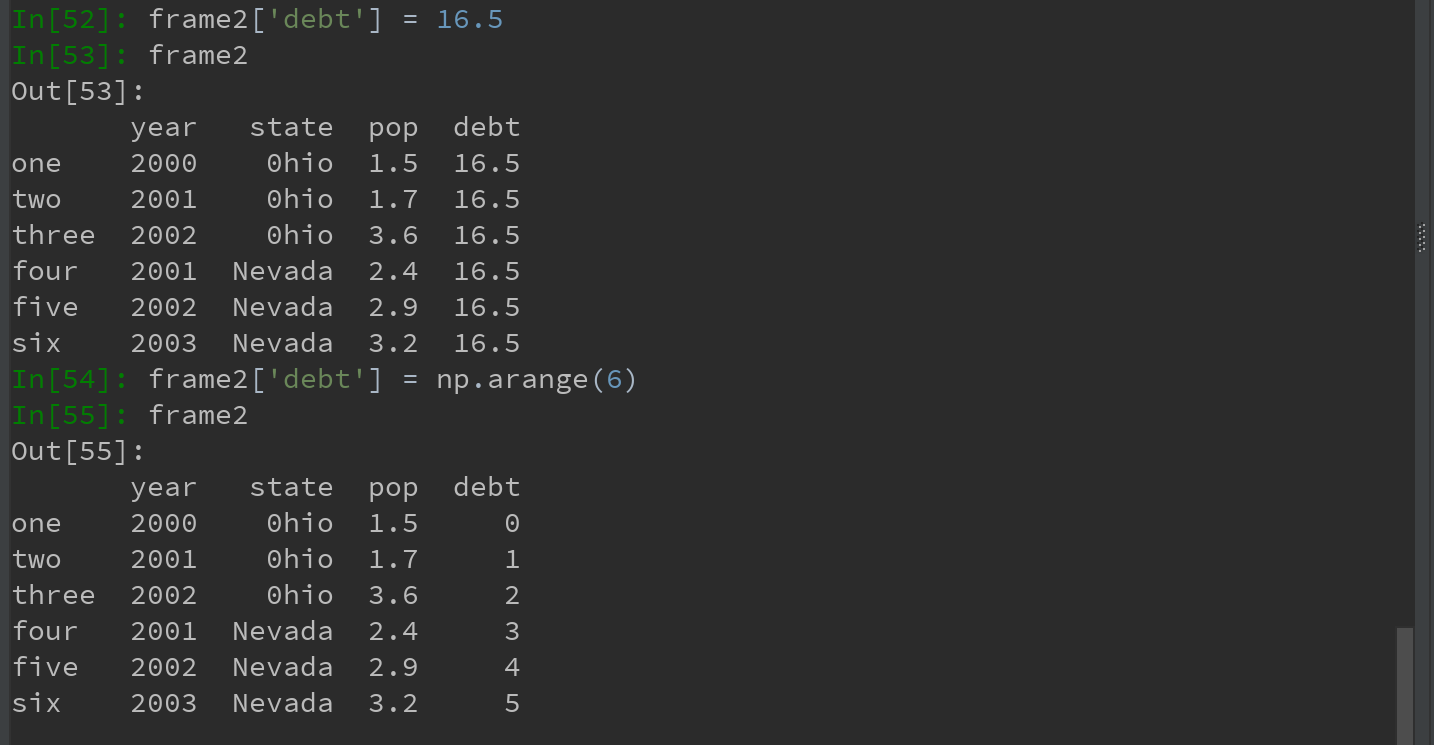
Ps:将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。
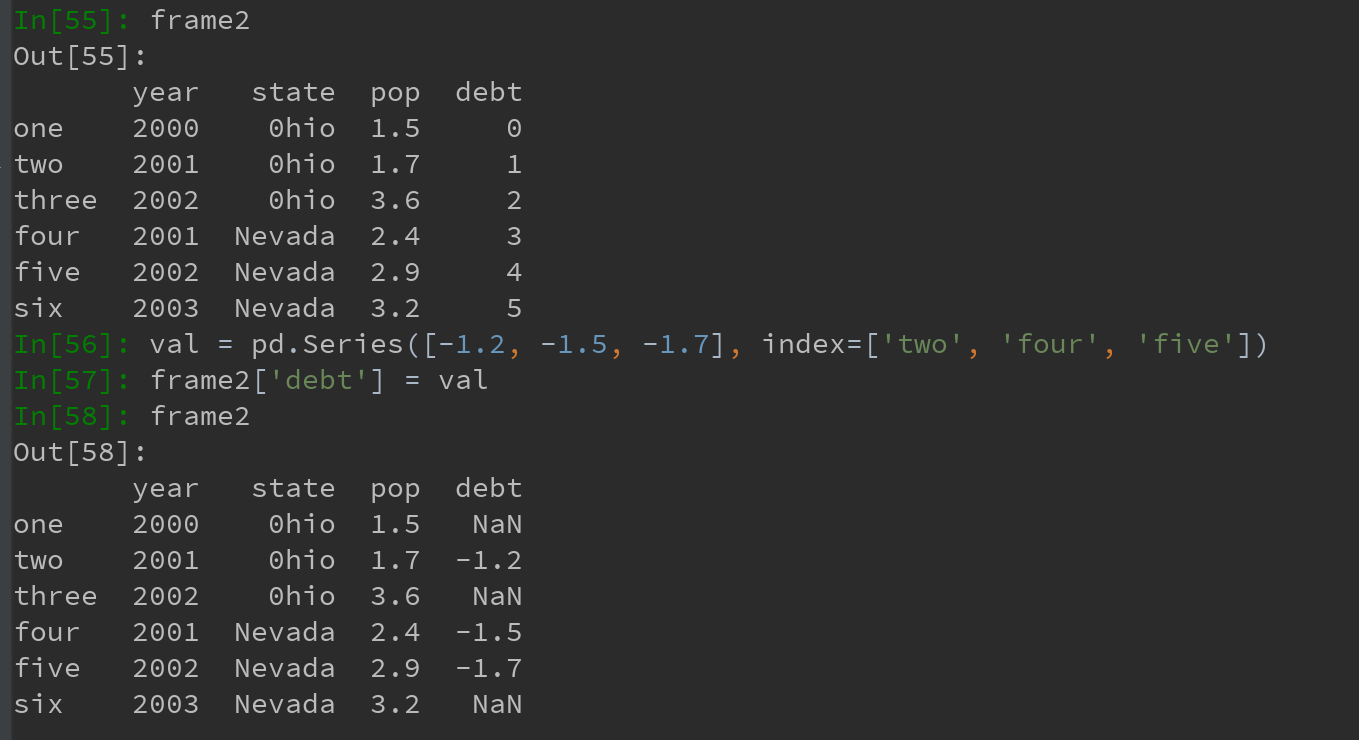
a)如果赋值的时一个Series,则会精确匹配DataFrame的索引,所有空位都将被填上缺失值:
b)为不存在的列赋值,会创建一个新列。关键字del用于删除列
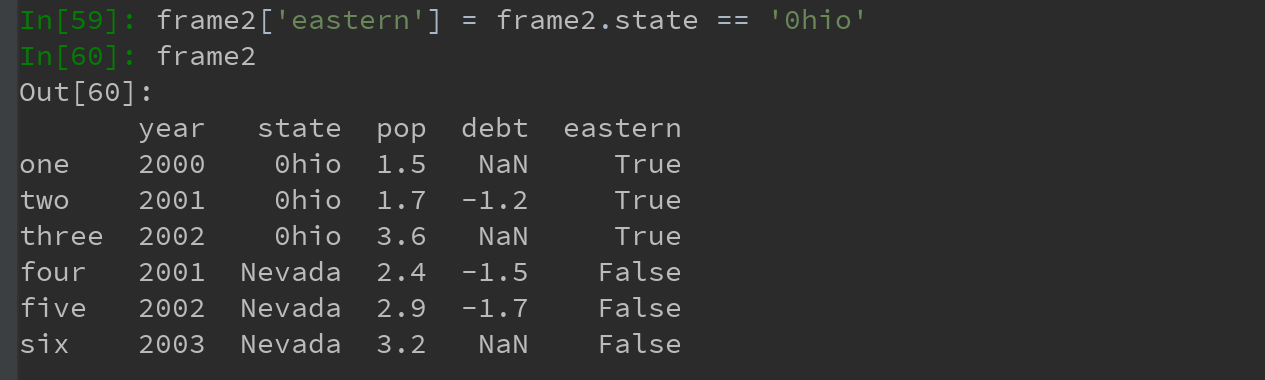
关键字del用于删除列

5)对DataFrame进行转置(交换行和列)
可使用类似NumPy数组的方法 .T:

6)DataFrame构造函数所能接受的各种数据

7)设置DataFrame的index和columns的name属性

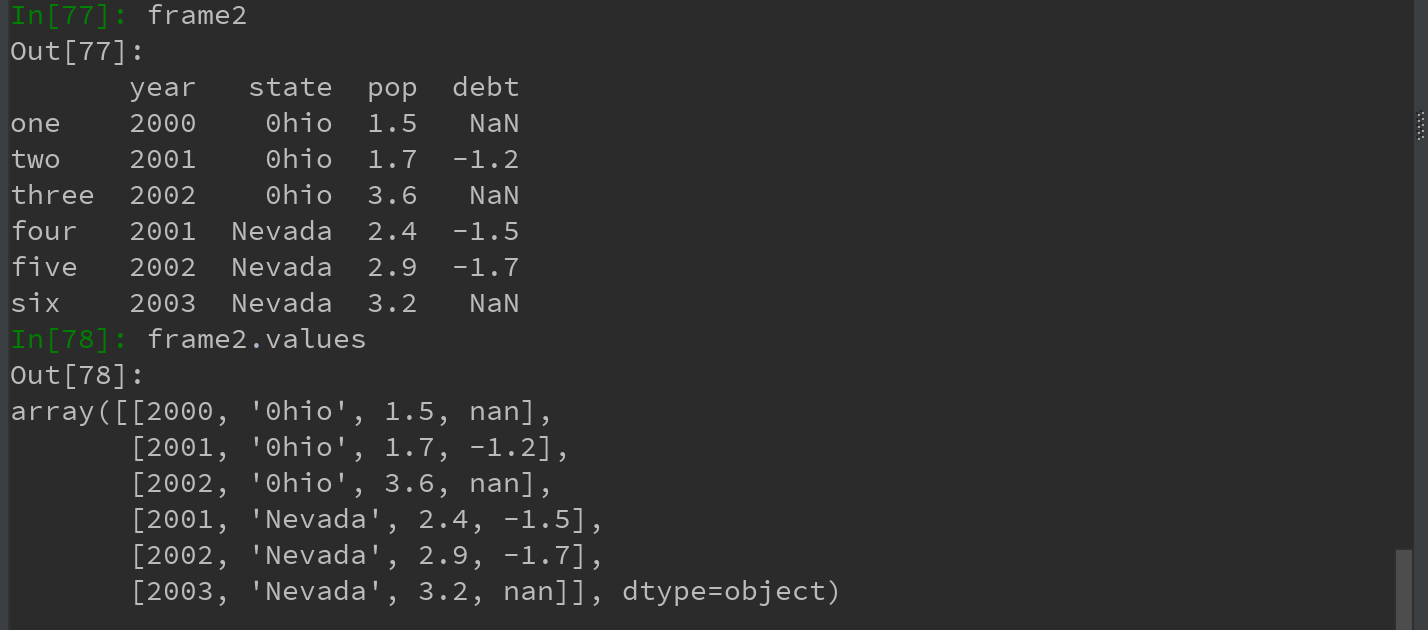
8)DataFrame的values属性
跟Series一样values属性也会以二维nadarray的形式返回DataFrame中的数据:

注:如果DataFrame各列的数据类型不同,则值数组的dtype就会选用能兼容所有列的数据类型:
(3)索引对象
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。
构建Series和DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index:

Index对象是不可变的,无法对其进行修改。不可变,可使Index对象在多个数据结构之间安全共享: 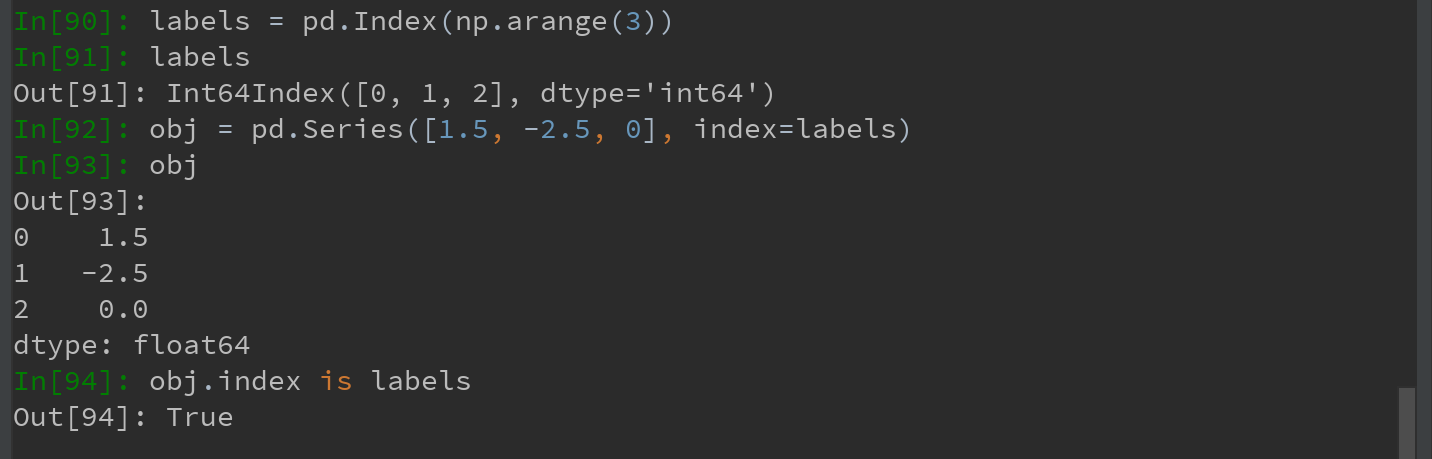
与Python的集合不同,pandas的Index可以包含重复的标签。
Index的方法和属性:

利用Python进行数据分析 第5章 pandas入门(1)的更多相关文章
- 利用Python进行数据分析 第5章 pandas入门(2)
5.2 基本功能 (1)重新索引 - 方法reindex 方法reindex是pandas对象地一个重要方法,其作用是:创建一个新对象,它地数据符合新地索引. 如,对下面的Series数据按新索引进行 ...
- 利用Python进行数据分析 第4章 IPython的安装与使用简述
本篇开始,结合前面所学的Python基础,开始进行实战学习.学习书目为<利用Python进行数据分析>韦斯-麦金尼 著. 之前跳过本书的前述基础部分(因为跟之前所学的<Python基 ...
- 利用Python进行数据分析 第7章 数据清洗和准备(2)
7.3 字符串操作 pandas加强了Python的字符串和文本处理功能,使得能够对整组数据应用字符串表达式和正则表达式,且能够处理烦人的缺失数据. 7.3.1 字符串对象方法 对于许多字符串处理和脚 ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数 通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数. 1)一元(unary)ufunc,如,sqrt和exp函数 2)二元(unary) ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 利用Python进行数据分析 第7章 数据清洗和准备(1)
学习时间:2019/10/25 周五晚上22点半开始. 学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完. 实际反馈:集中学习1.5小时,学习6页:集中学习 ...
- < 利用Python进行数据分析 - 第2版 > 第五章 pandas入门 读书笔记
<利用Python进行数据分析·第2版>第五章 pandas入门--基础对象.操作.规则 python引用.浅拷贝.深拷贝 / 视图.副本 视图=引用 副本=浅拷贝/深拷贝 浅拷贝/深拷贝 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
随机推荐
- 2019-2020-1 20175313 《信息安全系统设计基础》实现mypwd
目录 MyPWD 一.题目要求 二.题目理解 三.需求分析 四.设计思路 五.伪代码分析 六.码云链接 七.运行结果截图 MyPWD 一.题目要求 学习pwd命令 研究pwd实现需要的系统调用(man ...
- ubuntu之路——day11.1 如何进行误差分析
举个例子 还是分类猫图片的例子 假设在dev上测试的时候,有100张图片被误分类了.现在要做的就是手动检查所有被误分类的图片,然后看一下这些图片都是因为什么原因被误分类了. 比如有些可能因为被误分类为 ...
- postgresql大数据查询加索引和不加索引耗时总结
1.创建测试表 CREATE TABLE big_data( id character varying(50) NOT NULL, name character varying(50), dat ...
- expdp导出卡住问题诊断
本文链接:https://blog.csdn.net/guogang83/article/details/78800487 [oracle@database ~]$nohup expdp gg/gg ...
- 【vue】常用操作
一.Vue中import from的来源:省略后缀与加载文件夹 https://blog.csdn.net/fyyyr/article/details/83657828 二.Vue安装依赖 #安装依赖 ...
- flutter 日志工具类
class LogUtils { //dart.vm.product 环境标识位 Release为true debug 为false static const bool isRelease = con ...
- Python高级笔记(八)with、上下文管理器
1. 上下文管理器 __enter__()方法返回资源对象,__exit__()方法处理一些清除资源 如:系统资源:文件.数据库链接.Socket等这些资源执行完业务逻辑之后,必须要关闭资源 #!/u ...
- 【Java】Spring快速入门(一)
Spring介绍 Spring可以轻松创建Java企业应用程序.它提供了在企业环境中使用Java语言所需的一切,支持Groovy和Kotlin作为JVM上的替代语言,并可根据应用程序的需要灵活地创建多 ...
- Django Model 定义语法
简单用法 from django.db import models class Person(models.Model): first_name = models.CharField(max_leng ...
- 删除pod后又重新创建pod发现还是访问原先的服务状态---解决
因为做了数据持久化存储,需要删除数据目录下的数据才可以 参照: https://www.cnblogs.com/effortsing/p/10496391.html