Apache Hive
1.Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
本质是将SQL转换为MapReduce程序。
主要用途:操作接口采用类SQL语法,提供快速开发的能力,功能扩展方便,用来做离线分析,比直接用MapReduce开发效率更高。
2.Hive架构
2.1Hive架构图
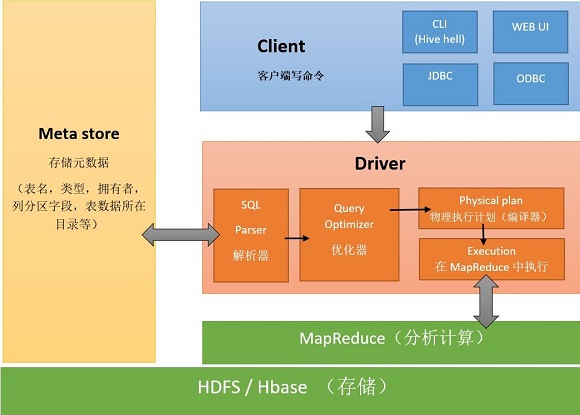
2.2Hive组件
用户接口:包括CLI、JDBC/ODBC、WebGUI。其中CLI(command line interface)为shell命令行;JDBC/ODBC是hive的JAVA试下,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
元数据存储:通常是存储在关系数据库中如mysql/derby中。Hive将元数据存储在数据库中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表),表的数据所在的目录等。
解释器、编译器、优化器、执行器:完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划生成。生成的查询计划存储在HDFS中,并在随后又MapReduce调用执行。
2.3Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
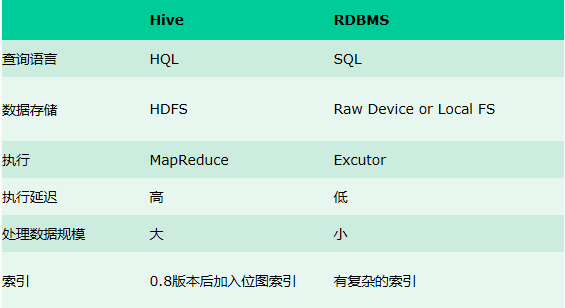
3.Hive与传统数据库对比
Hive用于海量数据数据的离线数据分析。
Hive具有sql数据库外表,但应用场景完全不同,hive只适合用来做批量数据统计分析。
4.Hive数据模型
Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式。
在创建表时指定数据中的分隔符,Hive就可以映射成功,解析数据。
Hive中包含以下数据模型
db:在HDFS中表现为hive。metastore.warehouse.dir目录下一个文件夹。
table:在HDFS中表现所属db目录下一个文件夹。
external table:数据存放位置可以在HDFS任意指定路径。
partition:在HDFS中表现为table目录下的子目录。
bucket:在HDFS中表现为同一个目录下根据hash散列之后的多个文件。
5.安装部署
Hive安装前需要安装好JDK和Hadoop。配置好环境变量。如果需要使用mysql来存储数据,需要提前安装好mysql。
5.1metadata、metastore
Metadata即元数据。元数据包含用Hive创建的database、table、表的字段等元信息。元数据存储在关系型数据库中。如hive内置的Derby、第三方如Mysql等。
Metastore即元数据服务,作用是:客户端连接metastore服务,metastore再去连接Mysql数据库来存取元数据。有了metastore服务,就可以有多个客户端同时进行连接,而且这些客户端不需要知道mysql数据库的用户名和密码,只需要连接metastore服务即可。
5.2metastore三种配置方式--hive安装方式
- 内嵌模式:解压缩即可,默认使用的数据库是derby,通常过家家的方法
本地模式
修改配置文件
修改配置文件hive-env.sh
- export HADOOP_HOME=/export/servers/hadoop-2.6.-cdh5.14.0/
修改配置文件hive-site.xml
- <configuration>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value></value>
- </property>
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://hadoop01:9083</value>
- </property>
- </configuration>
缺点:每连接一次hive,都会启动一个metastore进程,浪费资源
- 远程模式
配置hive-site.xml
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://node01:9083</value>
- </property>
启动metastore
- #前台启动--好处可以直接看到日志信息,坏处ctrl+C服务就停止,在当前连接中不能操作其他
- bin/hive --service metastore
- #后台启动 --坏处,看日志需要去找到日志文件,好处的话,不影响其他操作
- nohup bin/hive --service metastore &
5.3连接方式
- 第一种连接方式--过时
- #启动metastore服务器
- bin/hive
- 第二种连接方式
配置hive.site.xml
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>node01</value>
- </property>
启动hiveserver2服务
- #启动metastore服务器
- nohup bin/hive --service hiveserver2 &
连接
- !connect jdbc:hive2://node01:10000
- root
6.Hive基本操作
6.1DDL操作(数据定义语言)
- DDL数据库的定义语言 创建、修改和删除库、表、字段
- DCL数据库的控制语言 授权
- DQL数据库查询语言 select
- DML数据库测操作语言 增删改
DDL操作
- 内部表:当创建表的时候没有指定external关键字,就是一个内部表,外部的表象,这个表的文件默认会放在对应的数据库的文件夹,---删除的时候,元数据信息和HDFS上文件数据都被删除掉。
- 外部表:当创建表的时候需要指定external关键字,就是一个外部表,外部的表象这个表可以在HDFS的任意位置,--删除外部表的时候,元数据就会别删除,HDFS的文件数据不会删除的。
内部表操作
- create [external] table [if not exists] table_name
- [(col_name data_type [comment col_comment], ...)]
- [comment table_comment]
- [partitioned by (col_name data_type [comment col_comment], ...)]
- [clustered by (col_name, col_name, ...)
- [sorted by (col_name [asc|desc], ...)] into num_buckets buckets]
- [row format row_format]
- [stored as file_format]
- [location hdfs_path]
创建一张简单的表
- create table t_user(id int,name string,age int);
加载数据
将一个文件直接放到表目录下面,字段和列的内容进行对应,一定要使用默认的分隔符?不一定,可以通过row format delimited fields terminated by指定
代码层面"\001",非打印字符,vi编辑命令下可以通过ctrl+v和ctrl+a输入
为什么不用其他的分割符?---通常使用默认分隔符\001、制表符\t或逗号
手动指定分割符
- create table if not exists t_student(sid int comment 'key',name int,sex string) row format delimited fields terminated by '\t';
- --if not exists 判断表是否存在
- --comment 字段或表的注释信息
- --row format 行的格式化 delimited fields terminated by 指定分隔符
- 文件中的字段类型,hive会尝试的去转换,不保证一定转换成功
外部表
创建一个外部表
- create external table if not exists t_student_ext(sid int comment 'key',name int,sex string) row format delimited fields terminated by '\t' location "/hive";
- --external 创建外部表
- --location 指定外部表的文件所在路径
分区表
分区表:会在表的文件夹下创建多个子目录,数据会放到各个子目录中
创建分区表
- create table t_user_part(id int,name string,country string) partitioned by (guojia string) row format delimited fields terminated by ',' ;
- --注意顺序问题
- --分区的字段不能是表当中的字段
加载数据--必须登录到hive的窗口执行
- load data local inpath './root/4.txt' into table t_user_part partition (guojia='usa');
- load data local inpath '/root/5.txt' into table t_user_part partition (guojia='china');
- --将数据加载到哪个文件夹中
为什么要有分区表?是一个用于优化查询的表
减少全文检索的问题
通常分区的字段有哪些?省市区 时间
多级分区
- create table t_order(id int,pid int,price double) partitioned by (year string,month string,day string) row format delimited fields terminated by ',' ;
- load data local inpath '/root/5.txt' into table t_order partition (year='',month='',day='');
- load data local inpath '/root/4.txt' into table t_order partition (year='',month='',day='');
分通表
创建表
- create table stu_buck2(Sno string,Sname string,Sbrithday string, Sex string)
- clustered by(Sno)
- into 4 buckets
- row format delimited
- fields terminated by '\t';
- --clustered by 根据哪个字段去分桶,这个字段在表中一定存在
- --into N buckets 分多少个文件
- --如果该分桶字段是string,会根据字符串的hashcode % bucketsNum
- --如果该分桶字段是数值类型,数值 % bucketsNum
- --创建普通表
- create table student2(Sno string,Sname string,Sbrithday string, Sex string) row format delimited fields terminated by '\t';
- --开启分桶
- set hive.enforce.bucketing = true;
- set mapreduce.job.reduces=4;
- --insert+select
- insert overwrite table stu_buck2 select * from student2 cluster by(Sno);
- --默认不让直接使用分桶表
为什么创建分桶表?也是一个优化表
优化join的笛卡尔积
加载数据
内部表和外部表:将文件直接上传到hdfs对应的表的目录下面即可,分隔符
分区表:load data local into table
分通表:insert overwrite table 分通表 select * from 普通表
Apache Hive的更多相关文章
- Apache Hive 基本理论与安装指南
一.Hive的基本理论 Hive是在HDFS之上的架构,Hive中含有其自身的组件,解释器.编译器.执行器.优化器.解释器用于对脚本进行解释,编译器是对高级语言代码进行编译,执行器是对java代码的执 ...
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- Apache Hive 存储方式、压缩格式
简介: Apache hive 存储方式跟压缩格式! 1.Text File hive> create external table tab_textfile ( host string com ...
- 解决kylin sync table报错:MetaException(message:java.lang.ClassNotFoundException Class org.apache.hive.hcatalog.data.JsonSerDe not found
在kylin-gui中sync表default.customer_visit时报错: -- ::, ERROR [http-bio--exec-] controller.BasicController ...
- Spring boot with Apache Hive
5.29.1. Maven <dependency> <groupId>org.springframework.boot</groupId> <artif ...
- Apache Hive 安装文档
简介: Apache hive 是基于 Hadoop 的一个开源的数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,将 SQL 语句转换为 MapReduce 任务 ...
- Apache Hive (四)Hive的连接3种连接方式
转自:https://www.cnblogs.com/qingyunzong/p/8715925.html 一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~] ...
- Apache Hive 建表操作的简单描述
客户端连接hive [root@bigdata-02 bin]# ./beeline Beeline version by Apache Hive beeline: Connecting : Ente ...
- Apache Hive 简介及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. 主要用途:用来 ...
- 系统解析Apache Hive
Apache Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供一种HQL语言进行查询,具有扩展性好.延展性好.高容错等特点,多应用于离线数仓建设. 1. ...
随机推荐
- Asp.Net报https请求报传输流收到意外的 EOF 或 0 个字节
网上搜索,都说是.net framework版本太低,改为.net 4.5以上版本即可.于是使用vs2017环境测试了下,使用.net framework4.5版本确实可以正常返回结果,低于这个版本就 ...
- 解决栏登 F~~~秋~~~之后只有火狐能上网的问题
我发现F~~~完秋~~~只有火狐可以上网,惊了,后来发现是没有关代理服雾气 1.打开Chrome->设置 2.翻到最后点击显示高级设置 3.找到网络标签,点击更改代理服务器按钮 4.点击连接标签 ...
- Python全栈--目录导航
这里更新以Python语言作为基础,想要成为全栈工程师需要掌握的技能... Python基础语法 day01 初识Python day02 while循环 运算符和编码 day03 字符串 day04 ...
- mac 下使用nasm
#安装nasm brew install nasm #创建文件 vi hello.asm 写入如下内容 msg: db "hello world!", 0x0a len: equ ...
- [HeadFrist-HTMLCSS学习笔记]第二章深入了解超文本:认识HTML中的“HT”
[HeadFrist-HTMLCSS学习笔记]第二章深入了解超文本:认识HTML中的"HT" 敲黑板!!! 创建HTML超链接 <a>链接文本(此处会有下划线,可以单击 ...
- [Gamma阶段]测试报告
[Gamma阶段]测试报告 博客目录 测试方法及过程 在正式发布前,为检验后端各接口功能的正确性,后端服务器对压力的耐受程度,以及前端各页面.功能的运行情况,我们对我们的服务器及小程序进行了多种测试. ...
- 解决github打不开
今天重庆电信的“临时工”把github废了. 主要是github.githubassets.com和customer-stories-feed.github.com访问不到 通过修改host的方式上g ...
- Python 2 代码转 Python 3的一些转化
Python 2 代码转 Python 3的一些转化 1.“print X” 更改为“print(X)” 2.xrange改为range 3.m.itervalues() 改为 m.values() ...
- laravel如何引用外部文件
(1).首先在app\Http\routes.php中定义路由: 1 2 3 Route::get('view','ViewController@view'); Route::get('article ...
- javascript 忍者秘籍读书笔记
书名 "学徒"=>"忍者" 性能分析 console.time('sss') console.timeEnd('sss') 函数 函数是第一类对象 通过字 ...