XGBoost 重要参数(调参使用)
XGBoost 重要参数(调参使用)
数据比赛Kaggle,天池中最常见的就是XGBoost和LightGBM。
模型是在数据比赛中尤为重要的,但是实际上,在比赛的过程中,大部分朋友在模型上花的时间却是相对较少的,大家都倾向于将宝贵的时间留在特征提取与模型融合这些方面。在实战中,我们会先做一个baseline的demo,尽可能快尽可能多的挖掘出模型的潜力,以便后期将精力花在特征和模型融合上。这里就需要一些调参功底。
本文从这两种模型的一共百余参数中选取重要的十余个进行探讨研究。并给大家展示快速轻量级的调参方式。当然,有更高一步要求的朋友,还是得戳LightGBM和XGBoost这两个官方文档链接。
XGBoost 的重要参数
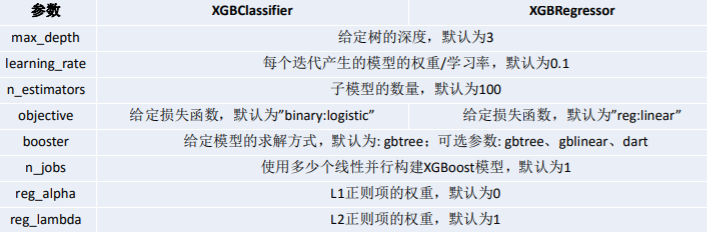
XGBoost的参数一共分为三类:
通用参数:宏观函数控制。
Booster参数:控制每一步的booster(tree/regression)。booster参数一般可以调控模型的效果和计算代价。我们所说的调参,很这是大程度上都是在调整booster参数。
学习目标参数:控制训练目标的表现。我们对于问题的划分主要体现在学习目标参数上。比如我们要做分类还是回归,做二分类还是多分类,这都是目标参数所提供的。
通用参数
booster:我们有两种参数选择,
gbtree和gblinear。gbtree是采用树的结构来运行数据,而gblinear是基于线性模型。silent:静默模式,为
1时模型运行不输出。nthread: 使用线程数,一般我们设置成
-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程。
Booster参数
n_estimator: 也作
num_boosting_rounds这是生成的最大树的数目,也是最大的迭代次数。
learning_rate: 有时也叫作
eta,系统默认值为0.3,。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。我们一般使用比默认值小一点,
0.1左右就很好。gamma:系统默认为
0,我们也常用0。在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。
gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点。所以树生成的时候更不容易分裂节点。范围:[0,∞]subsample:系统默认为
1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:
0.5-1,0.5代表平均采样,防止过拟合. 范围:(0,1],注意不可取0colsample_bytree:系统默认值为1。我们一般设置成0.8左右。
用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:
0.5-1范围:(0,1]colsample_bylevel:默认为1,我们也设置为1.
这个就相比于前一个更加细致了,它指的是每棵树每次节点分裂的时候列采样的比例
max_depth: 系统默认值为
6我们常用
3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。设置为0代表没有限制,范围:[0,∞]max_delta_step:默认
0,我们常用0.这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为
0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。lambda:也称
reg_lambda,默认值为0。权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。这个参数在减少过拟合上很有帮助。
alpha:也称
reg_alpha默认为0,权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
scale_pos_weight:默认为
1在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
学习目标参数
objective [缺省值=reg:linear]
reg:linear– 线性回归reg:logistic– 逻辑回归binary:logistic– 二分类逻辑回归,输出为概率binary:logitraw– 二分类逻辑回归,输出的结果为wTxcount:poisson– 计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7 (used to safeguard optimization)multi:softmax– 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数)multi:softprob– 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率。
eval_metric [缺省值=通过目标函数选择]
rmse: 均方根误差mae: 平均绝对值误差logloss: negative log-likelihooderror: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。 error@t: 不同的划分阈值可以通过 ‘t’进行设置merror: 多分类错误率,计算公式为(wrong cases)/(all cases)mlogloss: 多分类log损失auc: 曲线下的面积ndcg: Normalized Discounted Cumulative Gainmap: 平均正确率
一般来说,我们都会使用xgboost.train(params, dtrain)函数来训练我们的模型。这里的params指的是booster参数。
两种基本的实例
我们要注意的是,在xgboost中想要进行二分类处理的时候,我们仅仅在 objective中设置成 binary,会发现输出仍然是一堆连续的值。这是因为它输出的是模型预测的所有概率中最大的那个值。我们可以后续对这些概率进行条件处理得到最终类别,或者直接调用xgboost中的XGBClassifier()类,但这两种函数的写法不太一样。大家看我下面的例子。
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 导入数据
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:, 0:8]
Y = dataset[:, 8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 设置参数
model = XGBClassifier(max_depth=15,
learning_rate=0.1,
n_estimators=2000,
min_child_weight=5,
max_delta_step=0,
subsample=0.8,
colsample_bytree=0.7,
reg_alpha=0,
reg_lambda=0.4,
scale_pos_weight=0.8,
silent=True,
objective='binary:logistic',
missing=None,
eval_metric='auc',
seed=1440,
gamma=0)
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# 查看准确率
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
以上是xgboost.train()写法,这是xgboost最原始的封装函数。这样训练我们预测输出的是一串连续值,是xgboost在这几个类别上概率最大的概率值。我们如果想要得到我们的分类结果,还需要进行其他操作。
幸运的是,xgboost为了贴合sklearn的使用,比如gridsearch这些实用工具,又开发了XGBoostClassifier()和XGBoostRegression()两个函数。可以更加简单快捷的进行分类和回归处理。注意xgboost的sklearn包没有 feature_importance 这个量度,但是get_fscore()函数有相同的功能。当然,为了和sklearn保持一致,写法也发生变化,具体请看下面代码:
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.datasets import load_breast_cancer
# 二分类解决乳腺癌
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
train_x, valid_x, train_y, valid_y = train_test_split(x, y, test_size=0.333, random_state=0) # 分训练集和验证集
# 这里不需要Dmatrix
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='binary:logistic',
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=1440,
missing=None)
xlf.fit(train_x, train_y, eval_metric='error', verbose=True, eval_set=[(valid_x, valid_y)], early_stopping_rounds=30)
# 这个verbose主要是调节系统输出的,如果设置成10,便是每迭代10次就有输出。
# 注意我们这里eval_metric=‘error’便是准确率。这里面并没有accuracy命名的函数,网上大多例子为auc,我这里特意放了个error。
y_pred = xlf.predict(valid_x, ntree_limit=xlf.best_ntree_limit)
auc_score = roc_auc_score(valid_y, y_pred)
y_pred = xlf.predict(valid_x, ntree_limit=xlf.best_ntree_limit)
# xgboost没有直接使用效果最好的树作为模型的机制,这里采用最大树深限制的方法,目的是获取刚刚early_stopping效果最好的,实测性能可以
auc_score = roc_auc_score(valid_y, y_pred) # 算一下预测结果的roc值
那么我们介绍了这么多,重点就来了:如何又快又好的调参?首先我们需要了解grid search是个什么原理。
GridSearch 简介
这是一种调参手段;穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)
其实这个就跟我们常用的遍历是一样的。建议大家使用sklearn里面的GridSearch函数,简洁速度快。
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import GridSearchCV
cancer = load_breast_cancer()
x = cancer.data[:50]
y = cancer.target[:50]
train_x, valid_x, train_y, valid_y = train_test_split(x, y, test_size=0.333, random_state=0) # 分训练集和验证集
# 这里不需要Dmatrix
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [50, 100, 200, 300, 500],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='binary:logistic',
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=1440,
missing=None)
# 有了gridsearch我们便不需要fit函数
gsearch = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gsearch.fit(train_x, train_y)
print("Best score: %0.3f" % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
#极其耗费时间,电脑没执行完
我们需要注意的是,Grid Search 需要交叉验证支持的。这里的cv=3,是个int数,就代表3-折验证。实际上cv可以是一个对象,也可以是其他类型。分别代表不同的方式验证。具体的大家可看下面这段表述。
Possible inputs for cv are:
None, to use the default 3-fold cross-validation,
integer, to specify the number of folds.
An object to be used as a cross-validation generator.
An iterable yielding train/test splits.
cv的可能输入包括:
None,使用默认的3倍交叉验证,
整数,用来指定折叠的次数。
用作交叉验证生成器的对象。
一个可迭代的训练/测试序列进行分割。
XGBoost 重要参数(调参使用)的更多相关文章
- 【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使 ...
- XGBOOST应用及调参示例
该示例所用的数据可从该链接下载,提取码为3y90,数据说明可参考该网页.该示例的“模型调参”这一部分引用了这篇博客的步骤. 数据前处理 导入数据 import pandas as pd import ...
- xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
问题: 用xgboost/gbdt在在调参的时候把树的最大深度调成6就有很高的精度了.但是用DecisionTree/RandomForest的时候需要把树的深度调到15或更高.用RandomFore ...
- xgboost的遗传算法调参
遗传算法适应度的选择: 机器学习的适应度可以是任何性能指标 —准确度,精确度,召回率,F1分数等等.根据适应度值,我们选择表现最佳的父母(“适者生存”),作为幸存的种群. 交配: 存活下来的群体中的父 ...
- XGBoost参数调优完全指南(附Python代码)
XGBoost参数调优完全指南(附Python代码):http://www.2cto.com/kf/201607/528771.html https://www.zhihu.com/question/ ...
- LightGBM调参笔记
本文链接:https://blog.csdn.net/u012735708/article/details/837497031. 概述在竞赛题中,我们知道XGBoost算法非常热门,是很多的比赛的大杀 ...
- LightGBM 调参方法(具体操作)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- xgboost的sklearn接口和原生接口参数详细说明及调参指点
from xgboost import XGBClassifier XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=100,silen ...
- XGBoost和LightGBM的参数以及调参
一.XGBoost参数解释 XGBoost的参数一共分为三类: 通用参数:宏观函数控制. Booster参数:控制每一步的booster(tree/regression).booster参数一般可以调 ...
随机推荐
- 看图轻松理解数据结构与算法系列(NoSQL存储-LSM树) - 全文
<看图轻松理解数据结构和算法>,主要使用图片来描述常见的数据结构和算法,轻松阅读并理解掌握.本系列包括各种堆.各种队列.各种列表.各种树.各种图.各种排序等等几十篇的样子. 关于LSM树 ...
- dbt 集成presto试用
dbt 团队提供了presto 的adapter同时也是一个不错的的参考实现,可以学习 当前dbt presto 对于版本的要求是0.13.1 对于当前最新版本的还不支持,同时需要使用源码安装pip ...
- bootstrap轮播图组件
一.轮播图组件模板(官方文档) <div id="carousel-example-generic" class="carousel slide" dat ...
- 微信小程序搜索框代码组件
search.wxml <view class="header"> <view class="search"> <icon typ ...
- #C++初学记录(动态规划(dynamic programming)例题1 钞票)
浅入动态规划 dynamic programming is a method for solving a complex problem by breaking it down into a coll ...
- SpringBoot dev-tools vjtools dozer热启动类加载器不相同问题
最近使用唯品会的vjtools的BeanMapper进行对象的深度克隆转换DTO/VO这种操作,Spring Boot的dev-tools热启动,需要把vjtools和dozer包都放到spring- ...
- cesium常用设置【转】
https://blog.csdn.net/D_Walker/article/details/82188514 1.加载线上cesium代码<link href="http://ces ...
- Nginx可以做什么?(转载)
本文只针对Nginx在不加载第三方模块的情况能处理哪些事情,由于第三方模块太多所以也介绍不完,当然本文本身也可能介绍的不完整,毕竟只是我个人使用过和了解到过得,欢迎留言交流. Nginx能做什么 —— ...
- Python推荐一整套开发工具
原文:https://sourcery.ai/blog/python-best-practices/ 在开始一个新的Python项目时,很容易不做规划直接进入编码环节.花费少量时间,用最好的工具设置项 ...
- Nginx location wildcard
Module ngx_http_core_modulehttps://nginx.org/en/docs/http/ngx_http_core_module.html#location locatio ...