CDH5.13快速体验
相对于易用性很差Apache Hadoop,其他商业版Hadoop的性能易用性都有更好的表现,如Cloudera、Hortonworks、MapR以及国产的星环,下面使用CDH(Cloudera Distribution Hadoop)快速体验下。
首先从,从Cloudera官网下载部署好的虚拟机环境https://www.cloudera.com/downloads/quickstart_vms/5-13.html.html,解压后用虚拟机打开,官方推荐至少8G内存2cpu,由于笔记本性能足够,我改为8G内存8cpu启动,虚拟机各种账号密码都是cloudera
打开虚拟机的浏览器访问http://quickstart.cloudera/#/
 点击Get Started以体验
点击Get Started以体验

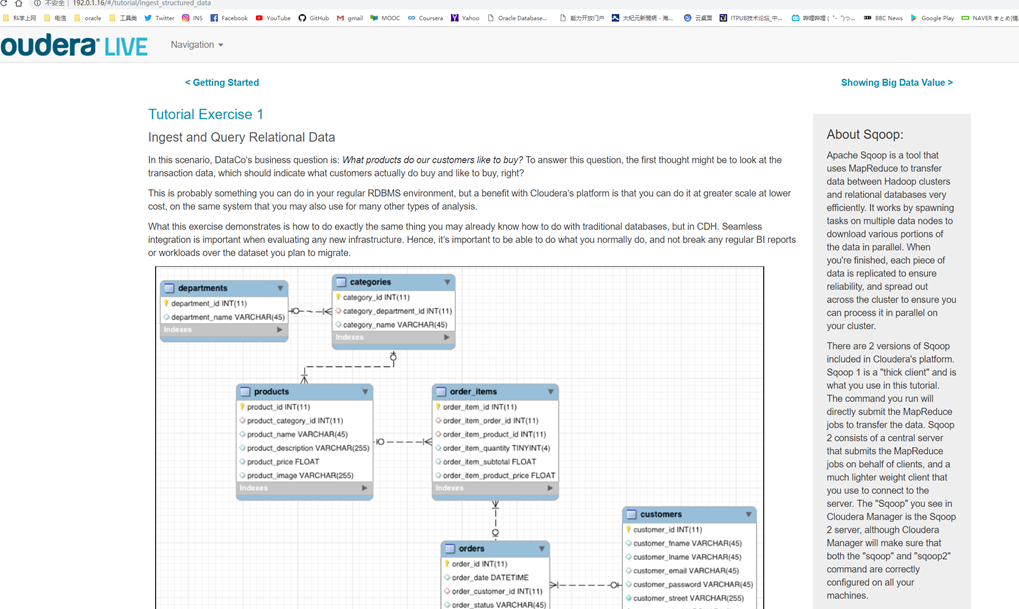
Tutorial Exercise 1:导入、查询关系数据
利用sqoop工具将mysql数据导入HDFS中
[cloudera@quickstart ~]$ sqoop import-all-tables \
> -m 1 \
> --connect jdbc:mysql://quickstart:3306/retail_db \
> --username=retail_dba \
> --password=cloudera \
> --compression-codec=snappy \
> --as-parquetfile \
> --warehouse-dir=/user/hive/warehouse \
> --hive-import
Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
19/04/29 18:31:46 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.13.0
19/04/29 18:31:46 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/04/29 18:31:46 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
19/04/29 18:31:46 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
19/04/29 18:31:46 WARN tool.BaseSqoopTool: It seems that you're doing hive import directly into default (many more lines suppressed) Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=87
CPU time spent (ms)=3690
Physical memory (bytes) snapshot=443174912
Virtual memory (bytes) snapshot=1616969728
Total committed heap usage (bytes)=352845824
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
19/04/29 18:38:27 INFO mapreduce.ImportJobBase: Transferred 46.1328 KB in 85.1717 seconds (554.6442 bytes/sec)
19/04/29 18:38:27 INFO mapreduce.ImportJobBase: Retrieved 1345 records.
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/
Found 6 items
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:32 /user/hive/warehouse/categories
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:33 /user/hive/warehouse/customers
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:34 /user/hive/warehouse/departments
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:35 /user/hive/warehouse/order_items
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:36 /user/hive/warehouse/orders
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:38 /user/hive/warehouse/products
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/categories/
Found 3 items
drwxr-xr-x - cloudera supergroup 0 2019-04-29 18:31 /user/hive/warehouse/categories/.metadata
drwxr-xr-x - cloudera supergroup 0 2019-04-29 18:32 /user/hive/warehouse/categories/.signals
-rw-r--r-- 1 cloudera supergroup 1957 2019-04-29 18:32 /user/hive/warehouse/categories/6e701a22-4f74-4623-abd1-965077105fd3.parquet
[cloudera@quickstart ~]$
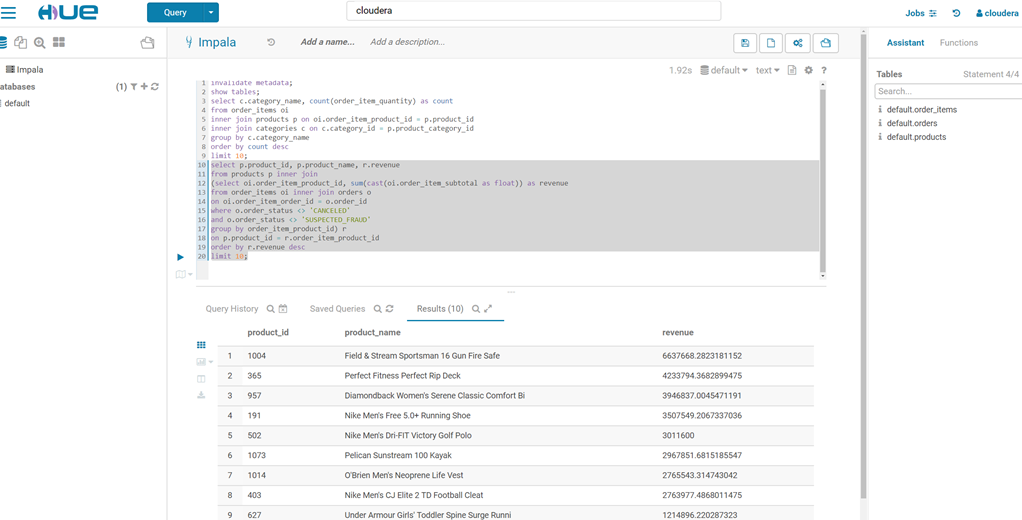
然后访问http://quickstart.cloudera:8888/,来访问表(invalidate metadata;是用来刷新元数据的)
Tutorial Exercise 2 :外部表方式导入访问日志数据到HDFS并查询
通过hive建表
CREATE EXTERNAL TABLE intermediate_access_logs (
ip STRING,
date STRING,
method STRING,
url STRING,
http_version STRING,
code1 STRING,
code2 STRING,
dash STRING,
user_agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex' = '([^ ]*) - - \\[([^\\]]*)\\] "([^\ ]*) ([^\ ]*) ([^\ ]*)" (\\d*) (\\d*) "([^"]*)" "([^"]*)"',
'output.format.string' = "%1$$s %2$$s %3$$s %4$$s %5$$s %6$$s %7$$s %8$$s %9$$s")
LOCATION '/user/hive/warehouse/original_access_logs'; CREATE EXTERNAL TABLE tokenized_access_logs (
ip STRING,
date STRING,
method STRING,
url STRING,
http_version STRING,
code1 STRING,
code2 STRING,
dash STRING,
user_agent STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/hive/warehouse/tokenized_access_logs'; ADD JAR /usr/lib/hive/lib/hive-contrib.jar; INSERT OVERWRITE TABLE tokenized_access_logs SELECT * FROM intermediate_access_logs;
 impala中刷新元数据后访问表
impala中刷新元数据后访问表
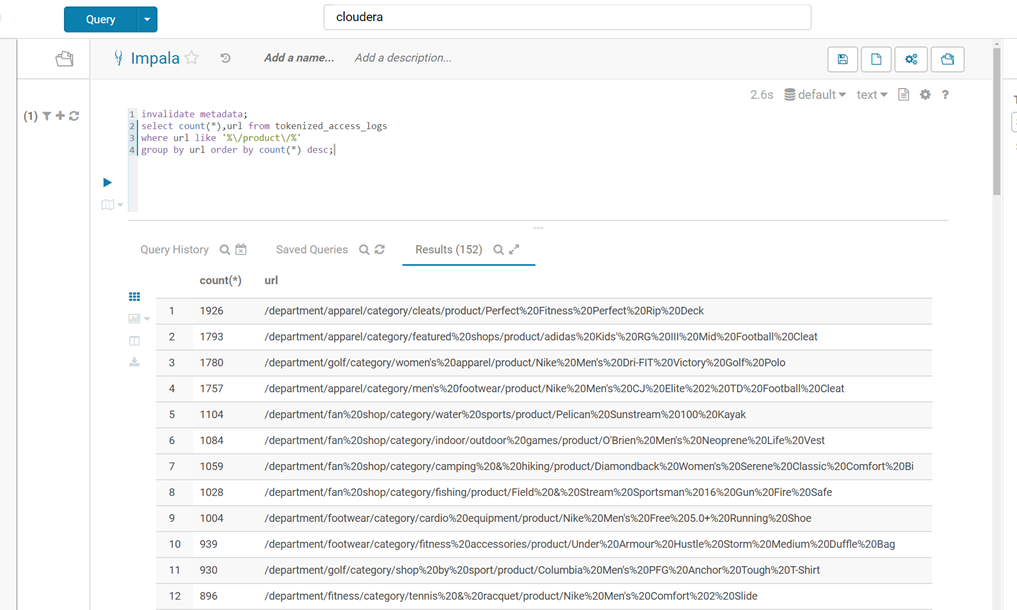
Tutorial Exercise 3:使用spark进行关联分析
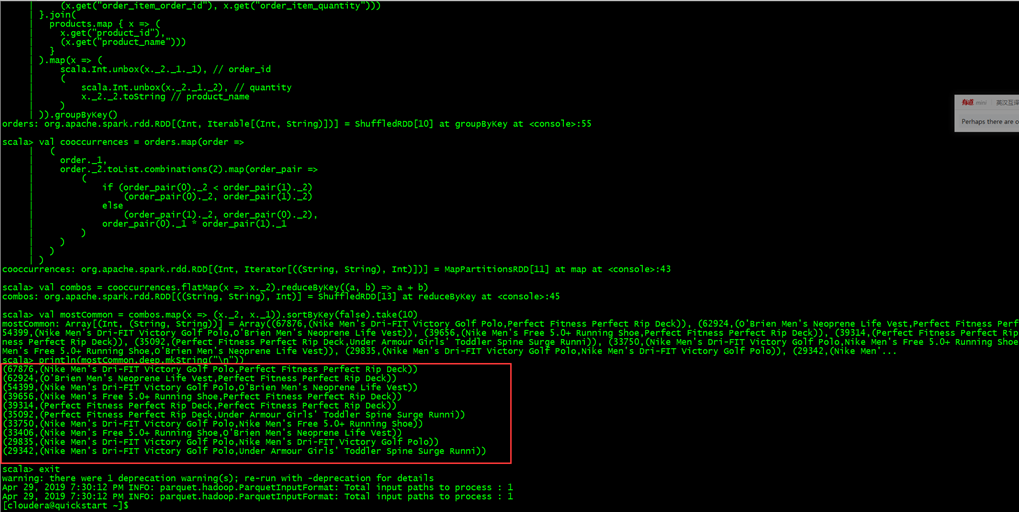
Tutorial Exercise 4:利用flume收集日志,并用solr做全文索引
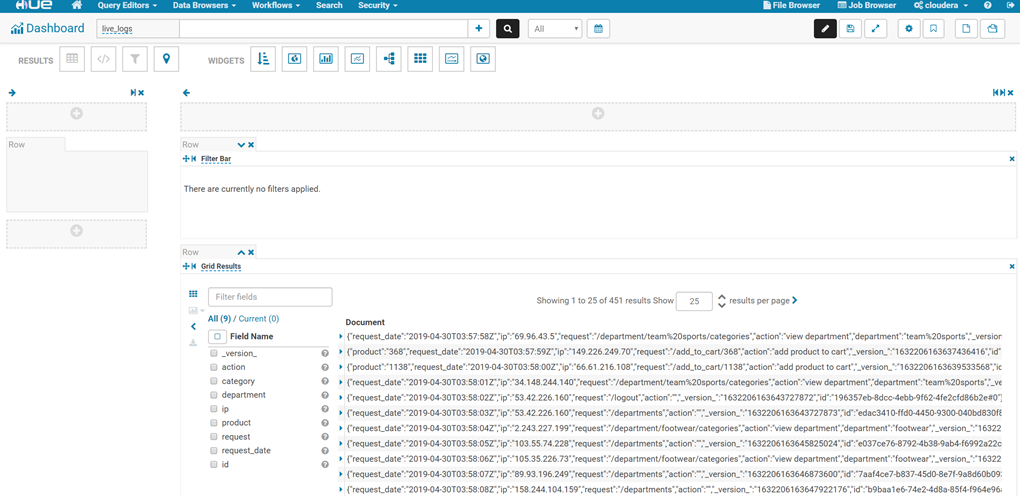
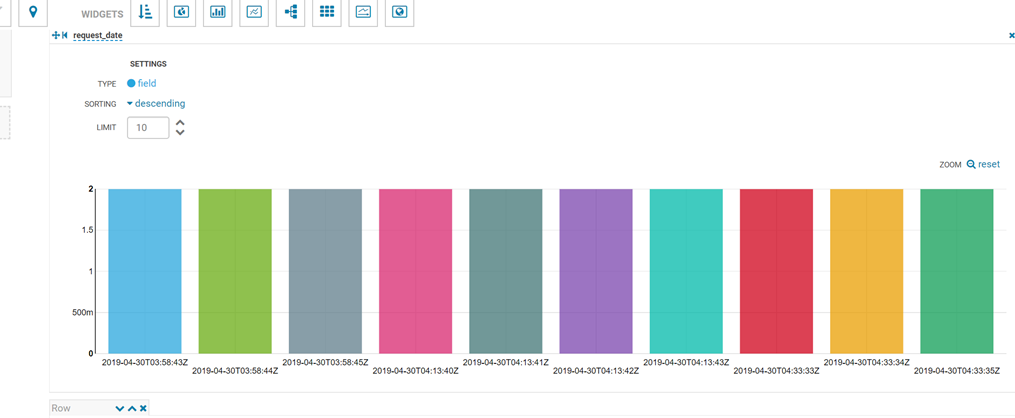
Tutorial Exercise 5:可视化
 Tutorial is over!
Tutorial is over!
CDH5.13快速体验的更多相关文章
- Django之Django快速体验
Django快速体验 前语: 这一节内容是直接快速上手,后面的内容是对内容进行按步解释,如果不想看解析的,可以直接只看这一节的内容. 1.新建项目应用新建项目test1新建应用booktest 2.注 ...
- 图解连接阿里云(一)创建阿里云物联网平台产品和设备,使用MQTT.fx快速体验
1. 打开 https://www.aliyun.com/ 注册账号 2.注册账号登录后点击控制台 3. 在下图1处输入物联网平台,会弹出2处所示物联网平台的入口,点击红色箭头所示处,进入物联网平 ...
- gitbook 入门教程之快速体验
本文主要介绍三种使用 gitbook 的方式,分别是 gitbook 命令行工具,Gitbook Editor 官方编辑器和 gitbook.com 官网. 总体来说,三种途径适合各自不同的人群,找到 ...
- 快速体验 Laravel 自带的注册、登录功能
快速体验 Laravel 自带的注册.登录功能 注册.登录经常是一件很伤脑筋的是,Laravel 提供了解决方案,可以直接使用它.试过之后,感觉真爽! 前提:本地已安装好了 PHP 运行环境.mysq ...
- centos7.5搭建cdh5.13.0
序言 本文集群搭建为三台机器,cdh版本为5.13.0,以下是安装过程中所用到的软件包等,可以自行下载.一.前期准备1.安装环境 系统:centos7.5/最小安装版本/64位 内存:主节点 --&g ...
- hibench 对CDH5.13.1进行基准测试(测试项目hadoop\spark\)HDFS作HA高可靠性
使用CDH 5.13.1部署了HADOOP集群之后,需要进行基准性能测试. 一.hibench 安装 1.安装位置要求. 因为是全量安装,其中有SPARK的测试(SPARK2.0). 安装位置在SPA ...
- 分布式_事务_01_2PC框架raincat快速体验1
一.前言 关于2PC的理论知识请见:分布式_理论_03_2PC 这一节我们来看下github上一个优秀的2PC分布式事务开源框架的快速体验. 二.源码 源码请见: https://github.com ...
- 分布式事务_01_2PC框架raincat快速体验
一.前言 关于2PC的理论知识请见:分布式_理论_03_2PC 这一节我们来看下github上一个优秀的2PC分布式事务开源框架的快速体验. 二.源码 源码请见: https://github.com ...
- Dev 日志 | 文章《快速体验知识图谱 OwnThink》中的技术问题
社区小伙伴反馈在实践文章<使用图数据库 Nebula Graph 数据导入快速体验知识图谱 OwnThink>时,遇到了一些问题,Nebula Graph 将在本文对该文章中出现的问题进行 ...
随机推荐
- python27期day01:变量、常量、注释、PEP8开发规范、数据类型、Python2和Python3的区别、用户输入、流程控制语句、作业题
1.变量:将程序中运行的中间值临时存储起来,以便下次使用. 2.变量命名规范:数字.字母.下划线.建议驼峰体.变量名具有可描述性.不能使用中文和拼音.不能数字开头和使用关键字('and', 'as', ...
- 每天一道Rust-LeetCode(2019-06-05)
每天一道Rust-LeetCode(2019-06-05) 最长回文子串 坚持每天一道题,刷题学习Rust. 接续昨天,最长会问字符串的另一种解法 题目描述 解题过程 //leetcode最快解法 / ...
- leetcode622. 设计循环队列
设计你的循环队列实现. 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环.它也被称为“环形缓冲器”. 循环队列的一个好处是我们可以利用这个队列 ...
- 遍历hashmap 的四种方法
以下列出四种方法 public static void main(String[] args) { Map<String,String> map=new HashMap<String ...
- POJ3630-Phone List-(字典树)
一直没有学字典树,听起来很唬人,闲来无事找一道入门题做做. 字典树:又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种.典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以 ...
- 微信小程序音频背景播放
由于微信小程序官方将音频的样式固定死了,往往再工作中和UI设计师设计出来的样式不符,故一般都采用背景音频播放来实现自定义的UI样式的音频播放,即使用官网API提供的BackgroundAudioMan ...
- iptables学习2
Firewall:工作在主机或网络边缘,对进出的报文按事先定义的规则进行检查, 并且由匹配到的规则进行处理的一组硬件或软件,甚至可能是两者的组合 隔离用户访问,只允许访问指定的服务 通过ADSL ...
- skip connections
deep learning初学者,最近在看一些GAN方面的论文,在生成器中通常会用到skip conections,于是就上网查了一些skip connection的博客,虽然东西都是人家的,但是出于 ...
- Android保存的文件显示到文件管理的最近文件和下载列表中
发现Android开发每搞一个和系统扯上关系的功能都要磨死人,对新手真不友好.运气不好难以快速精准的找到有效的资料
- Arcpy中Geometry类与Array类转换的陷阱
1.现象说明 使用Arcpy.da.searchcursor得到Geometry,将Geometry转换成Array,再从Array转换回Geometry.若Geometry包含内环,这个过程可能导致 ...