TF-IDF词频逆文档频率算法
一.简介
1.RF-IDF【term frequency-inverse document frequency】是一种用于检索与探究的常用加权技术。
2.TF-IDF是一种统计方法,用于评估一个词对于一个文件集或一个语料库中的其中一个文件的重要程度。
3.词的重要性随着它在文件中出现的次数的增加而增加,但同时也会随着它在语料库中出现的频率的升高而降低。
二.词频
指的是某一个给定的词语在一份给定的文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件【同一个词语在文件里可能会比短文件有更高的词频,而不管该词重要与否】。
公式:
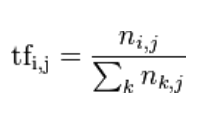
ni,j:是该词在文件dj中出现的次数,而分母则是在文件dj中所有词出现的次数之和。
三.逆文档频率
是一个词普遍重要性的度量。某一个特定词的IDF可以由总文件数目除以包含该词语的文件数据,再将得到的商取对数得到。
公式:
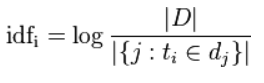
|D|:语料库中的文件总数
|{j:ti€dj}|:包含ti的文件总数
四.TF-IDF
公式:TF-IDF = TF * IDF
特点:某一特定文件内的高频率词语,以及该词语在整个语料库中的低文件频率,可以产生高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
思想:如果某个词或短语在一篇文章中出现的频率TF高,并且在其它文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。
五.代码实现
package big.data.analyse.tfidf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
/**
* Created by zhen on 2019/05/28.
*/
object TF_IDF {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("TF_IDF")
.master("local[2]")
.config("spark.sql.warehouse.dir", "file:///D://warehouse").getOrCreate()
val sc = spark.sparkContext
/**
* 计算TF
*/
val tf = sc.textFile("src/big/data/analyse/tfidf/TF.txt")
.map(row => row.replace(",", " ").replace(".", " ").replace(" ", " ")) // 数据清洗
.flatMap(row => row.split(" ")) // 拆分
.map(row => (row, 1.0))
.reduceByKey(_+_)
val tfSize = tf.map(row => row._2).sum() // 计算总词数
val tfed = tf.map(row => (row._1, row._2 / tfSize.toDouble)) //求词频
println("TF:")
tfed.foreach(println)
/**
* 计算IDF
*/
val idf_0 = tf.map(row => (row._1, 1.0))
println("加载IDF1文件数据。。。")
val idf_1 = sc.textFile("src/big/data/analyse/tfidf/IDF1.txt")
.map(row => row.replace(",", " ").replace(".", " ").replace(" ", " "))
.flatMap(row => row.split(" "))
.map(row => (row, 1.0))
.reduceByKey(_+_)
.map(row => (row._1, 1.0))
println("加载IDF2文件数据。。。")
val idf_2 = sc.textFile("src/big/data/analyse/tfidf/IDF2.txt")
.map(row => row.replace(",", " ").replace(".", " ").replace(" ", " "))
.flatMap(row => row.split(" "))
.map(row => (row, 1.0))
.reduceByKey(_+_)
.map(row => (row._1, 1.0))
/**
* 整合语料库数据
*/
val idf = idf_0.union(idf_1).union(idf_2)
.reduceByKey(_+_)
.map(row => (row._1, 3 / row._2))
println("IDF:")
idf.foreach(println)
/**
* 关联TF和IDF,计算TF-IDF
*/
println("TF-IDF:")
tfed.join(idf).map(row => (row._1, (row._2._1 * row._2._2).formatted("%.4f")))
.foreach(println)
}
}
六.结果
TF:
(GraphX,0.011494252873563218)
(are,0.011494252873563218)
(learning,0.011494252873563218)
(Python,0.011494252873563218)
(provides,0.011494252873563218)
(is,0.022988505747126436)
(Please,0.011494252873563218)
(higher-level,0.011494252873563218)
(general,0.011494252873563218)
(Security,0.034482758620689655)
(R,0.011494252873563218)
(fast,0.011494252873563218)
(SQL,0.022988505747126436)
(Apache,0.011494252873563218)
(Java,0.011494252873563218)
(data,0.011494252873563218)
(attack,0.011494252873563218)
(This,0.011494252873563218)
(cluster,0.011494252873563218)
(graph,0.011494252873563218)
(execution,0.011494252873563218)
(MLlib,0.011494252873563218)
(Scala,0.011494252873563218)
(computing,0.011494252873563218)
(downloading,0.011494252873563218)
(Streaming,0.011494252873563218)
(supports,0.022988505747126436)
(engine,0.011494252873563218)
(set,0.011494252873563218)
(running,0.011494252873563218)
(Spark,0.08045977011494253)
(you,0.011494252873563218)
(Overview,0.011494252873563218)
(general-purpose,0.011494252873563218)
(rich,0.011494252873563218)
(APIs,0.011494252873563218)
(vulnerable,0.011494252873563218)
(that,0.011494252873563218)
(a,0.022988505747126436)
(high-level,0.011494252873563218)
(processing,0.022988505747126436)
(OFF,0.011494252873563218)
(before,0.011494252873563218)
(including,0.011494252873563218)
(could,0.011494252873563218)
(optimized,0.011494252873563218)
(in,0.022988505747126436)
(to,0.011494252873563218)
(see,0.011494252873563218)
(graphs,0.011494252873563218)
(of,0.011494252873563218)
(also,0.011494252873563218)
(by,0.022988505747126436)
(structured,0.011494252873563218)
(tools,0.011494252873563218)
(It,0.022988505747126436)
(for,0.034482758620689655)
(mean,0.011494252873563218)
(an,0.011494252873563218)
(machine,0.011494252873563218)
(and,0.06896551724137931)
(system,0.011494252873563218)
(default,0.022988505747126436)
加载IDF1文件数据。。。
加载IDF2文件数据。。。
IDF:
(running,1.5)
(For,3.0)
(visit,3.0)
(The,3.0)
(you,1.0)
(website,1.5)
(than,3.0)
(7,3.0)
(PATH,3.0)
(that,1.0)
(was,1.5)
(a,1.0)
(main,3.0)
(old,3.0)
(high-level,1.5)
(be,1.5)
(quick,3.0)
(processing,1.5)
(could,1.5)
(all,3.0)
(augmenting,3.0)
(optimized,1.5)
(Downloads,3.0)
(follow,3.0)
(applications,3.0)
(classpath,3.0)
(structured,1.5)
(like,1.5)
(along,3.0)
(support,3.0)
(Spark’s,1.5)
(If,3.0)
(but,3.0)
(and,1.0)
(reference,3.0)
(1,3.0)
(g,3.0)
(system,1.5)
(your,3.0)
(10,3.0)
(It’s,3.0)
(are,1.0)
(learning,1.5)
(download,1.5)
(its,3.0)
(After,3.0)
(Building,3.0)
(can,1.5)
(Security,1.5)
(have,3.0)
(runs,3.0)
(6,3.0)
(build,3.0)
(0,1.5)
(SQL,1.0)
(with,1.5)
(locally,3.0)
(projects,3.0)
(their,3.0)
(Get,3.0)
(UNIX-like,3.0)
(This,1.0)
(,1.5)
(first,3.0)
(documentation,3.0)
(Since,3.0)
(still,3.0)
(Downloading,3.0)
(packaged,3.0)
(better,3.0)
(However,3.0)
(switch,3.0)
(hood,3.0)
(Linux,3.0)
(Streaming,1.5)
(supports,1.5)
(PyPI,3.0)
((2,3.0)
(vulnerable,1.5)
(RDD,3.0)
(Dataset,3.0)
(package,3.0)
(this,3.0)
(under,3.0)
(Python,1.0)
(provides,1.0)
(API,1.5)
(higher-level,1.5)
(introduction,3.0)
(Apache,1.5)
(will,1.5)
(Java,1.0)
(2,1.5)
(data,1.5)
(as,3.0)
(YARN,3.0)
(installed,3.0)
(pointing,3.0)
(optimizations,3.0)
(get,3.0)
(cluster,1.5)
(tutorial,3.0)
(graph,1.5)
(easy,3.0)
(execution,1.5)
(MLlib,1.5)
(We,3.0)
(you’d,3.0)
(supported,3.0)
(downloading,1.5)
(shell,3.0)
(handful,3.0)
(1+,3.0)
(Users,3.0)
(engine,1.5)
(version,1.5)
(11,3.0)
(set,1.5)
(performance,3.0)
(rich,1.5)
(systems,3.0)
(replaced,3.0)
(Spark,1.0)
(project,3.0)
(Overview,1.5)
(APIs,1.5)
(Mac,3.0)
(or,1.5)
(popular,3.0)
(Support,3.0)
(richer,3.0)
(downloads,3.0)
(OFF,1.5)
(future,3.0)
(detailed,3.0)
(GraphX,1.5)
(removed,3.0)
(4,3.0)
(installation,3.0)
(Please,1.5)
(is,1.0)
(guide,3.0)
(recommend,3.0)
(R,1.5)
(general,1.5)
(JAVA_HOME,3.0)
(fast,1.5)
(include,3.0)
(need,3.0)
(one,3.0)
(attack,1.5)
(how,3.0)
(uses,3.0)
(compatible,3.0)
(information,3.0)
(we,3.0)
(interactive,3.0)
(—,3.0)
(using,1.5)
(Note,1.5)
(7+/3,3.0)
(java,3.0)
(pre-packaged,3.0)
(Scala,1.0)
(any,1.5)
(computing,1.5)
(variable,3.0)
(users,3.0)
(from,1.5)
(has,3.0)
(won’t,3.0)
(through,3.0)
(at,3.0)
(more,3.0)
(3,3.0)
(versions,3.0)
(of,1.0)
(tools,1.5)
(8+,3.0)
(by,1.0)
(mean,1.5)
(RDDs,3.0)
((e,3.0)
(It,1.5)
(for,1.0)
(To,3.0)
(were,3.0)
(both,3.0)
(an,1.0)
(12,3.0)
(which,3.0)
(machine,1.5)
(libraries,3.0)
(introduce,3.0)
(environment,3.0)
((in,3.0)
(programming,3.0)
(See,3.0)
(use,1.5)
(default,1.5)
(the,1.5)
(write,3.0)
(highly,3.0)
(release,3.0)
(Resilient,3.0)
(interface,3.0)
(strongly-typed,3.0)
(about,3.0)
(run,3.0)
(general-purpose,1.5)
(5,3.0)
(Distributed,3.0)
(on,3.0)
(You,3.0)
(source,3.0)
(Scala),3.0)
(show,3.0)
(then,3.0)
(before,1.0)
(including,1.5)
(to,1.0)
(in,1.0)
(client,3.0)
(see,1.5)
(HDFS,1.5)
(graphs,1.5)
(Hadoop’s,3.0)
(also,1.5)
(“Hadoop,3.0)
(binary,3.0)
(x),3.0)
(free”,3.0)
(Maven,3.0)
(coordinates,3.0)
(Windows,3.0)
(deprecated,3.0)
(install,3.0)
((RDD),3.0)
(4+,3.0)
(page,3.0)
(OS),3.0)
(Hadoop,1.5)
TF-IDF:
(you,0.0115)
(that,0.0115)
(a,0.0230)
(high-level,0.0172)
(processing,0.0345)
(could,0.0172)
(optimized,0.0172)
(structured,0.0172)
(and,0.0690)
(system,0.0172)
(are,0.0115)
(learning,0.0172)
(Security,0.0517)
(SQL,0.0230)
(This,0.0115)
(Streaming,0.0172)
(supports,0.0345)
(vulnerable,0.0172)
(Spark,0.0805)
(Overview,0.0172)
(APIs,0.0172)
(OFF,0.0172)
(of,0.0115)
(tools,0.0172)
(by,0.0230)
(mean,0.0172)
(It,0.0345)
(for,0.0345)
(an,0.0115)
(machine,0.0172)
(default,0.0345)
(Python,0.0115)
(provides,0.0115)
(higher-level,0.0172)
(Apache,0.0172)
(GraphX,0.0172)
(Please,0.0172)
(is,0.0230)
(R,0.0172)
(general,0.0172)
(fast,0.0172)
(attack,0.0172)
(Java,0.0115)
(Scala,0.0115)
(computing,0.0172)
(data,0.0172)
(cluster,0.0172)
(graph,0.0172)
(execution,0.0172)
(MLlib,0.0172)
(downloading,0.0172)
(engine,0.0172)
(set,0.0172)
(rich,0.0172)
(general-purpose,0.0172)
(before,0.0115)
(including,0.0172)
(to,0.0115)
(in,0.0230)
(see,0.0172)
(graphs,0.0172)
(also,0.0172) Process finished with exit code 0
TF-IDF词频逆文档频率算法的更多相关文章
- 机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)
TF-idf模型:TF表示的是词频:即这个词在一篇文档中出现的频率 idf表示的是逆文档频率, 即log(文档的个数/1+出现该词的文档个数) 可以看出出现该词的文档个数越小,表示这个词越稀有,在这 ...
- Kmeans文档聚类算法实现之python
实现文档聚类的总体思想: 将每个文档的关键词提取,形成一个关键词集合N: 将每个文档向量化,可以参看计算余弦相似度那一章: 给定K个聚类中心,使用Kmeans算法处理向量: 分析每个聚类中心的相关文档 ...
- 相似文档查找算法之 simHash 简介及其 java 实现 - leejun_2005的个人页面 - 开源中国社区
相似文档查找算法之 simHash 简介及其 java 实现 - leejun_2005的个人页面 - 开源中国社区 相似文档查找算法之 simHash 简介及其 java 实现
- 相似文档查找算法之 simHash及其 java 实现
传统的 hash 算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法.产生的两个签名,如果相等,说明原始内容在一定概 率 下是相等的:如果不相等,除了说明原始内容不相等外 ...
- Elasticsearch mapping文档相似性算法
Elasticsearch allows you to configure a scoring algorithm or similarity per field. The similarityset ...
- TF, IDF和TF-IDF
在相似文本的推荐中,可以用TF-IDF来衡量文章之间的相似性. 一.TF(Term Frequency) TF的含义很明显,就是词出现的频率. 公式: 在算文本相似性的时候,可以采用这个思路,如果两篇 ...
- 【Elasticsearch学习】文档搜索全过程
在ES执行分布式搜索时,分布式搜索操作需要分散到所有相关分片,若一个索引有3个主分片,每个主分片有一个副本分片,那么搜索请求会在这6个分片中随机选择3个分片,这3个分片有可能是主分片也可能是副本分片, ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- NLP︱句子级、词语级以及句子-词语之间相似性(相关名称:文档特征、词特征、词权重)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 关于相似性以及文档特征.词特征有太多种说法.弄 ...
随机推荐
- Xamarin.FormsShell基础教程(7)Shell项目关于页面的介绍
Xamarin.FormsShell基础教程(7)Shell项目关于页面的介绍 轻拍标签栏中的About标签,进入关于页面,如图1.8和图1.9所示.它是对应用程序介绍的页面. 该页面源自Views文 ...
- redhat 6安装python 3.7.4报错ModuleNotFoundError: No module named '_ctypes' make: *** [install] Error 1
问题描述: 今天在测试环境中,为了执行脚本,安装下python3命令,在执行make install的时候报错: ModuleNotFoundError: No module named '_ctyp ...
- netstat -lunpt未找到命令
[root@localhost ~]# netstat -lunpt -bash: netstat: 未找到命令 [root@localhost ~]# yum -y install net-tool ...
- sql 连续分组判断 partition by
partition by 会根据分类字段进行排序 加上rownum 可以形成 每组从1开始重新排序 举个例子, 我要根据时间为依据,连续出现合并为一组,统计每组在区间里的次数 ------------ ...
- [Golang] go modules使用
关于go modules的使用外面的教程实在太多了,我这里只讲下我自己使用的三种情形. 准备工作: 1.新建个文件加gomod_test. 2.在这个目录输入命令 go mod init gomod_ ...
- CentOS7 安装Redis和PHP-redis扩展
aemonize yes Redis是一个key-value存储系统,属于我们常说的NoSQL.它遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的AP ...
- XT交易所API
HTTPAPI xt为用户提供了一个简单的而又强大的API,旨在帮助用户快速高效的将xt交易功能整合到自己应用当中. API地址域名地址 域名地址:https://www.xt.com/ 使用说明 使 ...
- WinSCP-windows与Linux之间文件传输
WinSCP是一款Windows下通过使用SSH协议的开源工具,用于连接Linux操作系统,可以上传或者下载文件使用! 开源顾名思义,无需注册,安装即可使用!(安装请自行百度WinSCP) 打开桌面上 ...
- MTCNN代码解读
代码基于bm1682芯片 #include "mtcnn.hpp" #include "utils.hpp" using namespace std; usin ...
- POJ-图论-最短路模板(邻接矩阵)
POJ-图论-最短路模板 一.Floyd算法 刚读入数据时,G为读入的图邻接矩阵,更新后,G[i][j]表示结点i到结点j的最短路径长度 int G[N][N];//二维数组,其初始值即为该图的邻接矩 ...