python爬虫系列:三、URLError异常处理
1.URLError
首先解释下URLError可能产生的原因:
- 网络无连接,即本机无法上网
- 连接不到特定的服务器
- 服务器不存在
在代码中,我们需要用try-except语句来包围并捕获相应的异常。

2.HTTPError
HTTPError是URLError的子类,在你利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字”状态码”。
下面将状态码归结如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
HTTPError实例产生后会有一个code属性,这就是是服务器发送的相关错误号。
因为urllib可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
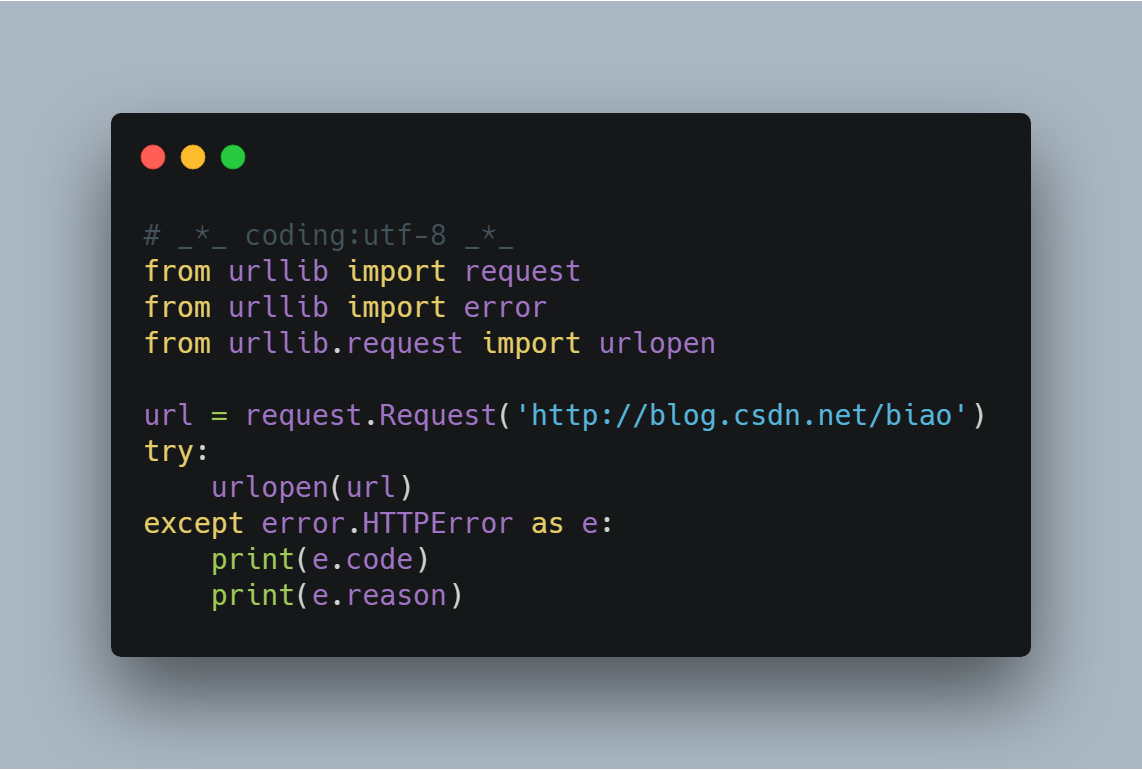
我们知道,HTTPError的父类是URLError,根据编程经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以这么改写
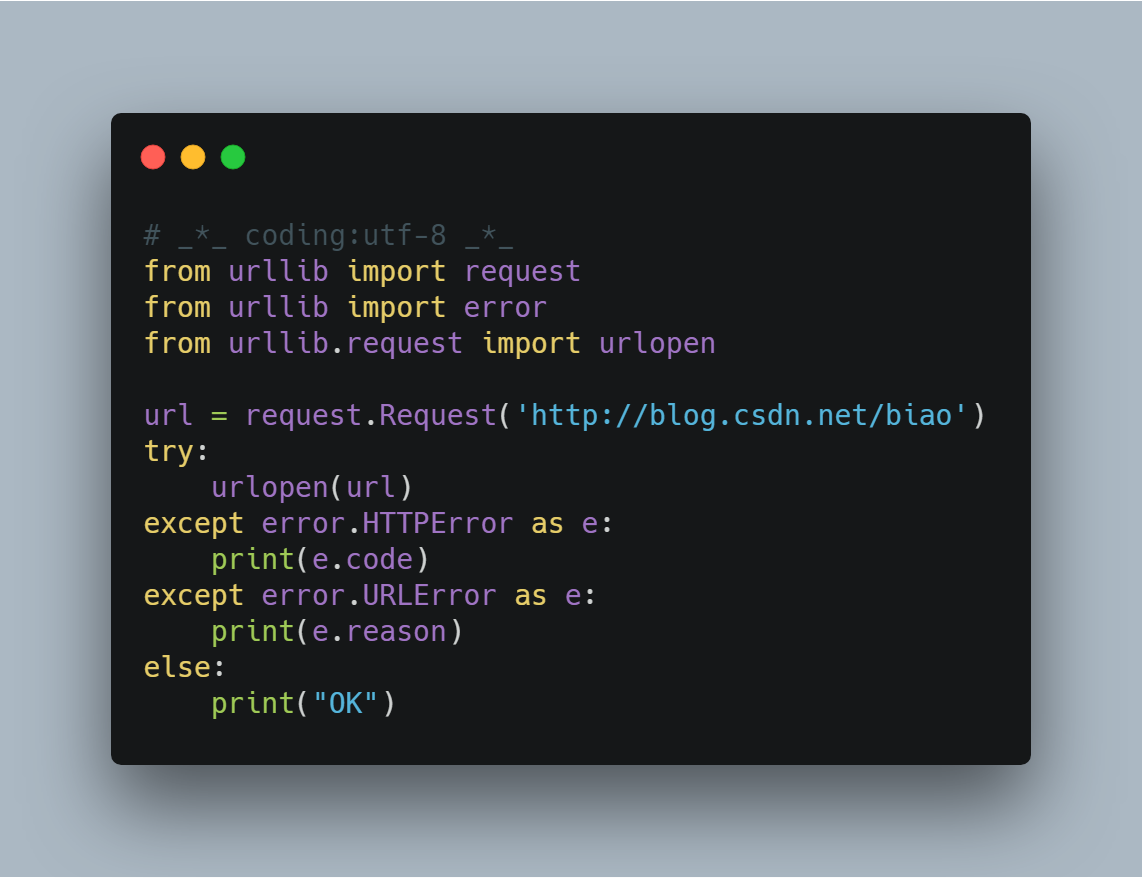
如果捕获到了HTTPError,则输出code,不会再处理URLError异常。如果发生的不是HTTPError,则会去捕获URLError异常,输出错误原因。
另外还可以加入 hasattr属性提前对属性进行判断,代码改写如下
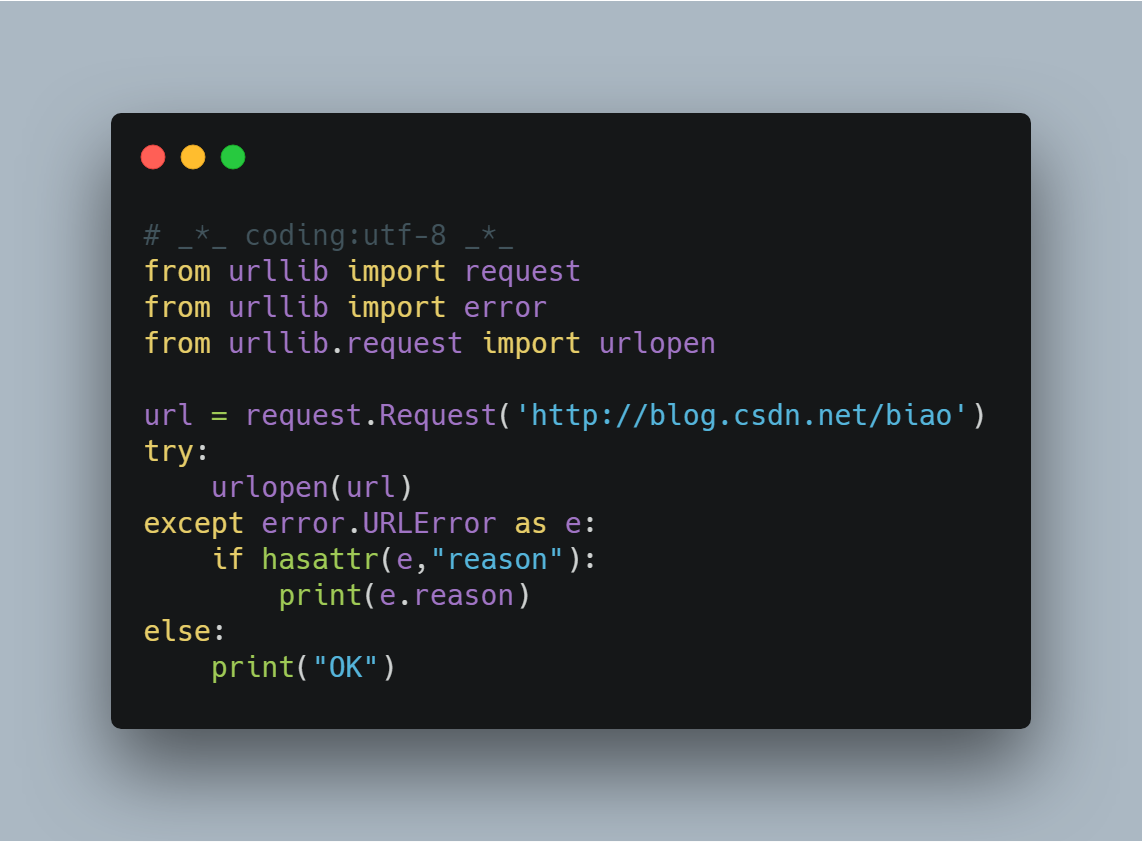
首先对异常的属性进行判断,以免出现属性输出报错的现象。
以上,就是对URLError和HTTPError的相关介绍,以及相应的错误处理办法。
python爬虫系列:三、URLError异常处理的更多相关文章
- Python爬虫入门:URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 芝麻HTTP:Python爬虫入门之URLError异常处理
1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中,我们需要用try-except语句来包围并捕获相应的异常.下 ...
- 爬虫系列(三) urllib的基本使用
一.urllib 简介 urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门 urllib 中包含四个模块,分别是 request:请求处理模 ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- Python2.x爬虫入门之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: (1)网络无连接,即本机无法上网 (2)连 ...
- python 爬虫系列教程方法总结及推荐
爬虫,是我学习的比较多的,也是比较了解的.打算写一个系列教程,网上搜罗一下,感觉别人写的已经很好了,我没必要重复造轮子了. 爬虫不过就是访问一个页面然后用一些匹配方式把自己需要的东西摘出来. 而访问页 ...
随机推荐
- element-ui 上传图片 后清空 图片 显示
使用element-ui组件,用el-upload上传图片,上传图片后再次打开还是会有原来的图片,想要清空原来上传的图片,只需要在组件上绑定ref,在提交成功后的方法里调用this.$refs.upl ...
- JavaScript 反射和属性赋值!
function Antzone(){ this.webName="蚂蚁部落"; this.age=6; } Antzone.prototype={ address:"青 ...
- Ubuntu下卸载anaconda
转载:https://blog.csdn.net/m0_37407756/article/details/77968724(一)删除整个anaconda目录: 由于Anaconda的安装文件都包含在一 ...
- promise简单实现
function isFunction(fn){ return Object.prototype.toString.call(fn) === '[object Function]'; } let ST ...
- Jmeter做压力测试
1)首先双击bin/jmeter.bat 2)创建Thread Group 3)配置HTTP Request 4)配置Aggregate Report 5)配置并发数和并发时间 6)点击绿色按钮,执行 ...
- 神器之strace
原链接:https://www.jianshu.com/p/33521124bdf2来
- 利用docker搭建RTMP直播流服务器实现直播
一.rtmp服务器搭建 环境: centos 7.* 1.先安装docker(省略) 2.下载docker容器 docker pull alfg/nginx-rtmp 3.运行容器(记得打开防火墙端口 ...
- mysql 开启日志服务
mysql 版本:mysql-5.7 1.在/etc/my.cnf 中添加如下内容: #错误日志: -log-err log-error=/usr/local/mysql--linux-glibc2. ...
- Python学习之路:关于列表(List)复制的那点事
要谈列表的复制,我们就要谈到Python的赋值规则 首先我们创建列表a: a = [1,2,3] 通常我们复制一个元素的方法是这样的: b = a #复制元素的一般方法 print(a) print( ...
- 基于FPGA Manager的Zynq PL程序写入方案
本文主要描述了如何在Linux系统启动以后,在线将bitstream文件更新到ZYNQ PL的过程及方法.相关内容主要译自xilinx-wiki,其中官网给出了两种方法,分别为Device Tree ...